未来的人类如何与机器人交流?我们既需要机器人模仿人类的语气、表情、动作,同样也需要机器人能理解我们。
搜狗AI正在朝着这一步迈进:由人类说一段话,AI根据唇形和语音准确识别内容。最近搜狗与清华天工研究院合作,在语音和唇语的多模态识别方面取得了重大成果。
相关论文《基于模态注意力的端到端音视觉语音识别》已经发表在今年的学术会议ICASSP上。
ICASSP是全世界最大的,也是最全面的信号处理及其应用方面的顶级会议,是IEEE的一个重要的年度会议,对于信号处理方面的学术人士有着重要意义。
5月12日至17日,在英国布莱顿举办的学术会议上,搜狗的研究人员汇报了他们的研究成果,显示了搜狗在语音识别、多模态识别领域的技术领先性和原创实力。
语音+唇语识别
随着语音识别的快速发展,纯粹靠声音的识别技术越来越成熟,识别准确率达到98%以上,很多公司,包括搜狗在内都推出了成熟的产品,比如搜狗输入法语音输入和搜狗智能录音笔等。
但是纯粹依靠语音的识别方式存在一个缺陷,就是无法在嘈杂环境下仍然保持较高的识别准确率。
通常当语音环境比较安静时,语音识别的准确率会比较高,但当语音环境较为嘈杂时,语音识别的准确率会明显下降。
而视觉的识别方法不受环境声音的影响,人在嘈杂环境下,听不清对方讲话时,会自然的盯紧讲话者的嘴巴,大致明白讲话者的意思。实际上听力障碍人士,正是通过讲话者的唇语进行交流的。
搜狗研究人员想到,如果让AI也能把这两种方法结合起来,就能提高语音识别的准确率。
早在2017年年底,搜狗就已经发布了一个唇语识别的初步成果,是业内首家公开展示唇语识别的公司。但当时的准确率仅有50%~60%,限制了它的实际应用,而且搜狗语音和唇语的技术也一直是分开做的。
经过一年多的发展,唇语识别技术已经有了很大的提升,搜狗团队开始考虑将听觉与视觉两种识别的模式融合起来,即所谓的“多模态”识别,这是搜狗唇语识别继乌镇互联网大会发布后的新突破。
原理简介
但多模态识别不是简单的把音频和视频的识别叠加起来,在这个过程中,研究人员需要克服两个难题。
1、音频和视频帧率不同
声音和视觉特征是两种本质上差异很大的模态,而且原始帧速率通常不一样,音频为每秒100帧,而视频为每秒24帧。
采用直接拼接的方法会造成信息损失,使得听觉特征在模型训练过程中起到主导作用,造成模型训练难收敛,视觉信息对听觉信息的提升有限。
2、如何选择音频和视频的贡献比例
在安静的情况下应该是语音占主导,在嘈杂环境下一定是视频占主导。如何根据不同的环境选择二者的比例。
搜狗的做法是 “基于注意力的编码器解码器”。在这个框架下,分别使用两个神经网络编码器对输入的不同模态的序列进行逐层特征抽取,得到高层特征表达。然后,由解码器分别对不同模态的特征表达进行注意力计算,得到声音和视觉模态信息中对应于当前解码时刻的上下文向量(context vector)。不同模态的上下文向量经由模态间的注意力自动对不同模态的信息进行融合,并输入到输出层得到解码输出。
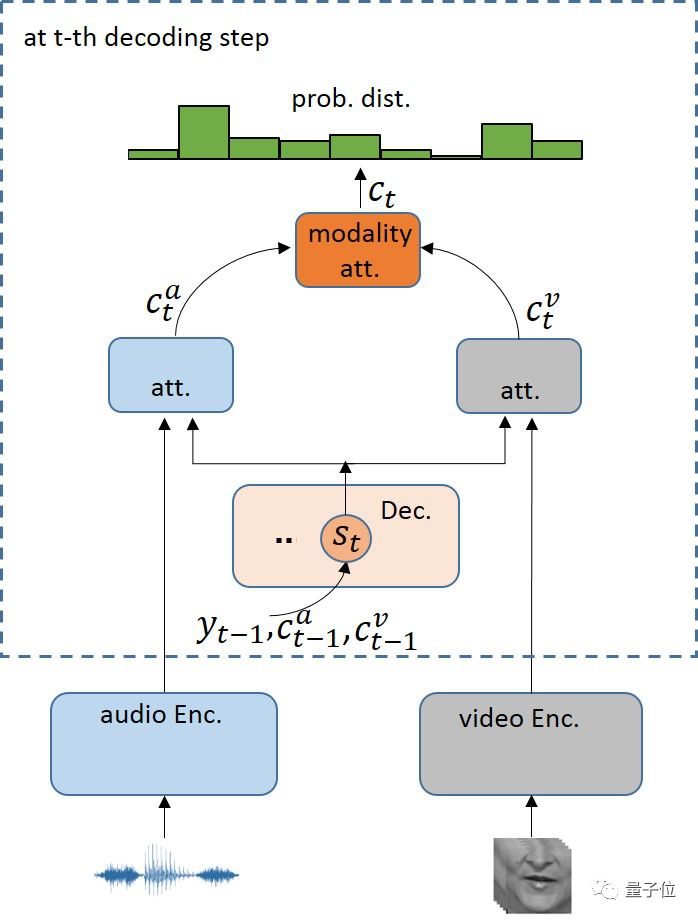
可见在编解码框架下,由于融合的是不同模态的context vector,而不是对原始特征或者编码器输出的高层特征进行直接融合,解决了不同模态的特征长度不同的问题。
同时,这种模态注意力(Modality Attention)依据不同模态各自的重要程度计算出相应的融合系数,反应了不同模态在当前解码时刻的不同贡献度,可以随着不同解码时刻的不同信噪比等得到不同的模态融合权重,得到更加鲁棒的融合信息。
搜狗从去年6月开始立项,10月就完成并投递了论文,在这个过程中,融合模型的设计是其中最困难的一步,研究人员周盼介绍说,他们在这个问题上花费了大约一半的时间。
实验结果证实了搜狗努力获得的回报。在信噪比为0dB(信号与噪声大小相当)时,搜狗的多模态识别将准确率提高了30%。
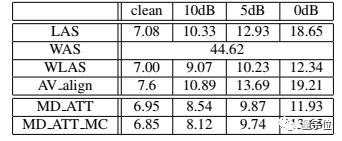
而且模型在不同噪声下,体现出了对语音和视频两种不同模态间的依赖。随着噪声的提升,模型在融合音视觉时,对视觉信息的依赖比例在逐渐提升。
0dB信噪比时,视频的注意力权重接近40%,高于语音清晰环境中35.9%的比例。

应用前景
现场,搜狗像我们展示了一段Demo,模拟了各种嘈杂环境下的多模态识别。

在模拟乘坐地铁的环境中,可以看到无论是单独的语音识别和唇语识别都无法正确还原原来的语句,但是二者结合起来,就可以正确识别出“北京今天天气怎么样”这句话。
语音交互技术中心首席科学家陈伟还特别指出,视频识别还能根据唇形识别语句在何处结束,也提高了在嘈杂环境下识别的准确率。
这么实用的功能何时才能用上呢?陈伟预计,多模态语音识别将在搜狗的手机输入法中集成,目前搜狗还在和车厂合作通过车内的麦克风、摄像头做出更准确的语音识别。
输入法走向对话、搜索走向问答,是搜狗一项长期战略。未来视频识别的场景会越来越多,所以搜狗认为多模态识别是NLP研究发展的一个必然的趋势。
当然,在搜狗畅想的未来中,多模态识别的终极形态就是与AI分身的结合。
声明:本文来自量子位,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
