随着《网络安全法》《信息安全技术、个人信息安全规范》等法律法规和技术规范的发布实施,数据采集行为需要经过个人信息主体同意这一基本原则得到了大家的充分认可和较好的落实。但随着数据产业的持续发展,个人信息主体和数据实际控制者相分离的情况越来越普遍,从而产生了个人信息控制者这一概念。与此同时,近年来,各种便民app越来越多,查违章、查社保、查征信、办贷款,不一而足。在采集公民个人信息的过程中,这些app无疑都获得了用户个人的授权,但要完成整个服务流程,却还要从社保系统、征信系统、友商平台等个人信息的实际控制者处获取相应的数据。从个人信息控制者处获取数据的主流途径有两种:一种是通过商业合作进行数据交易或互换,另一种则是利用爬虫直接爬取。爬取数据由于其效率高、成本低的特点,受到了企业的广泛青睐,但在其高效低价的背后,却隐藏着极高的法律风险。
目前,我国各互联网公司都会通过用户服务协议或者隐私政策等方式声明用户对于自己的账户仅具有使用权,而且这种模式也得到了司法实践的确认。

图1,由左到右分别是微信、抖音、淘宝用户协议
在这种权属背景下,数据抓取者仅依据用户本人的授权便进行数据抓取,难免会遇到法律纠纷。而从现有的判例来看,在此类纠纷中,司法机关倾向于保护数据控制者的利益,数据抓取者胜诉的可能性极低。在淘宝诉美景公司一案中,法院全面认可了淘宝的数据控制者地位和数据产品相关权益,认定美景公司的数据共享行为构成不正当竞争并向淘宝公司赔偿经济损失200万元。
而失财事小,刑事案件缠身则将对公司及高管产生重大影响。在没有充分授权的情况下进入计算机系统,这一行为完全就符合刑法第285条非法获取计算机信息系统罪关于侵入的定义。同时,如果爬虫工具还具备利用IP代理、伪装UA、AI识别等技术手段突破对方反爬措施的功能,则不仅会被认定为具有侵入的故意,视情节还有可能构成“提供侵入、非法控制计算机信息系统程序、工具罪”。
视频导购app秀淘的技术人员宋某、侯某利用网页爬虫技术来获取今日头条的视频数据,被北京市海淀区人民法院以“非法获取计算机信息系统数据罪”定罪。此案例中,宋某、侯某二人仅伪造了UA(useragent的缩写,意思就是“用户身份”)来绕过今日头条的反爬措施,爬取Web端视频即被认定为符合刑法意义上的侵入行为。
在技术认定标准较低的同时,非法获取计算机信息系统数据罪的入罪标准也相对较低,这也是爬取行为容易入刑的原因之一。爬取方仅需要达到违法所得5000元以上或造成对方损失10000元以上的标准,被爬取方为反爬取采取的技术升级措施、加班费等均可以认定为经济损失。此外,很多政府网站或中小网站由于带宽有限,爬虫工具造成的瞬时流量高峰有可能引发服务器过载,其经济损失非常容易达到起刑标准。
除非法获取计算机信息系统罪外,侵犯公民个人信息罪也是数据爬取极易触犯的罪名。由于授权不充分,数据爬取方的行为极易被认为属于窃取,而社保信息、交易信息、财产信息等都属于个人敏感信息,受到刑法第253条(侵犯公民个人信息罪)的保护。与非法获取计算机信息系统罪相同,为了保护公民个人信息,国家给该罪名设置了很低的入罪门槛,相关公司或个人只要非法获取50条征信信息、财产信息或500条交易信息便构成该罪。
综合来看,数据爬取合规的前提是明确数据权属并获得有关各方的充分授权。即用户首先向数据抓取者发起请求并授权,数据抓取者向数据实际控制者发起请求,数据实际控制者向用户核实,数据实际控制者向数据抓取者授权并提供数据。经过这样的“三步走”才能形成一个授权闭环。
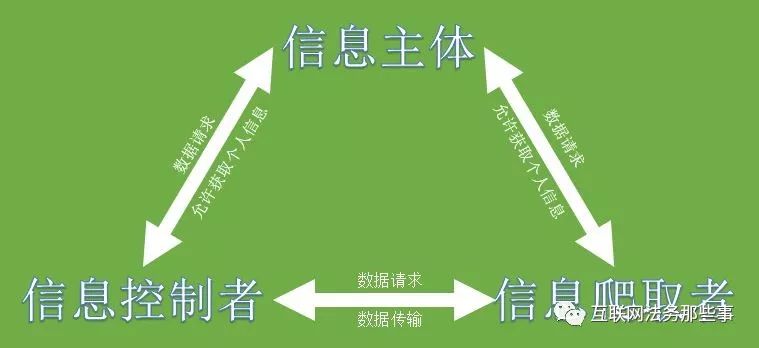
图2,三步授权示意
因此,数据爬取方在爬取数据前一定要对自己所爬取数据的性质和有关各方的地位进行充分的事前调查,并通过各种合法途径获得数据主体、数据控制者的充分授权。只有这样才能保证自身的安全性和商业模式的可持续性,将各类法律风险降到最低。
声明:本文来自互联网法务那些事,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
