“深度伪造”(deepfakes)——混合了“深度学习”和“虚假”这两个关键词的新型虚假内容,正在网络上快速蔓延。目前,借助人工智能技术对素材的修改或者再生,深度虚假不仅包括了假视频和假图片,还包括假音频。
“深度伪造”这一词起源于2017年12月,一个匿名用户在Reddit上自称“deepfakes”。借助深度学习算法,他将色情内容中的演员用斯佳丽约翰逊、盖尔加朵等名人进行了替换。虽然随后他就被Reddit封杀,但是在其他平台上快速出现了一大波模仿者。专家们推测,目前大约有10000个deepfake视频在网络世界流传,并且这一数字还将继续增长。

名为“deepfakes”的用户还曾分享自己将尼古拉斯凯奇换脸成川普的过程
Medium专栏作家Tom Van de Weghe对这一现象感到警觉。他认为我们已经进入了新的假新闻时代,视频、图像、音频的深度伪造,将进一步削弱公众对新闻业的信任,并将进一步地破坏民主。
为了更好地研究这一现象,他申请了斯坦福大学的John S.KnightJournalismFellowship新闻奖学金项目。在斯坦福,Tom邀请深度学习专家、计算机科学学生和访学交流的记者一起讨论与深度伪造相关的话题,这个不定期的讨论小组最终发展成了名为Deepfake Research Team(DRT)的研究团队。

Deepfake Research Team成员进行讨论
这个跨学科的小组正在研究人工智能及其对新闻业的影响,他们希望通过聚焦于当下日趋难辨的深度伪造问题,来帮助新闻业应对来自技术的更多挑战。
虽然距离真正的解决方案还很遥远,但从目前的研究中,他们总结了五条重要的经验,既包括了对当下深度伪造问题的现状描述,也包括了对未来解决之道的构想:
更低的门槛 更难的检验
每个普通人都有可能成为deepfake的“猎物”
Deepfakes具有两面性
区块链或将帮助解决deepfakes问题
编辑室:像侦探一样应对deepfakes
deepfakes现状:紧急且严峻
更低的制作门槛 更难的异常检验
与两年前相比,开发“合成内容”(synthetic media)的技术正在变得更加普遍和更容易使用。即使没有太多的机器学习的知识,任何人也都可能创建出深度伪造内容。在Github上搜索开发deepfakes的免费软件,搜索结果有超过100个之多。
Deepfake采用了生成式对抗网络(GANs)技术,通过不断地训练来提高算法复制、拟合真实图景的准确性。这种技术就像是一场猫和老鼠的游戏。一个被称为“创造者(generator)”的网络根据真实的图像数据生成假内容,另一个被称为“鉴别者(discriminator)”的网络从事着区分真实内容和虚假内容的工作。一个生产“谎言”,一个辨别“谎言”,这个迭代过程一直持续到创造者成功欺骗鉴别者为止。
从这个过程来看,要想生成一个deepfake视频,需要强大的计算机算力和时间。不过,即使你的GPU很差或者没有时间也没关系,在网络上你可以快捷方便地定制一个deepfake视频,例如在Youtube上,租用相关的处理器只需20美元。
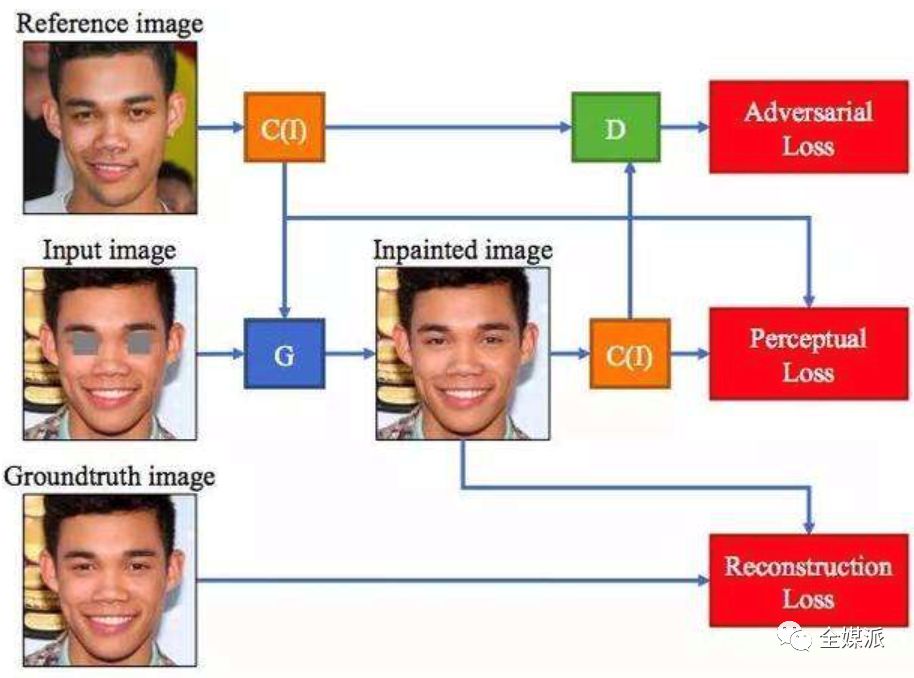
利用生成式对抗网络制造deepfake
制作成本在降低,不幸的是目前还没有商业上可用于检测deepfakes的工具。任何技术解决方案都将是一场不断升级的军备竞赛,制造deepfake的技术很快就能更新、超越最新的检测技术。
在DRT中,小组成员开放式地分享着各类解决方案。一个有趣的想法是,“以彼之矛攻彼之盾”,利用和deepfake相同的深度学习技术来进行检验工具的开发。比如Deepfake自动化检测工具Sherlock AI,这是一个整合卷积模型,可以在视频中寻找异常数据信息。开发者表示,这一工具可以达到97%的检验精度。

Neural Hash的工作原理
斯坦福大学计算机科学系的学生Nikhil Cheera和Rohan Suri开发了Neural Hash来应对这一问题。Neural Hash能对内容生成不可擦除的数字水印。恶意攻击者可以修改视频、扭曲音频、交换他人的脸等,但无论他们做了怎样的修改,数字签名都不会被抹去,而这一签名始终指向未经修改的原始内容。
你也可能成为“猎物”
到目前为止,deepfakes主要针对像奥巴马,川普这样的名人。名人之所以受到假视频作者的欢迎,是因为这些人物往往有大量方便获取的在线数据。

但是,随着照片视频等数据在社交媒体上的大量使用和传播,每个人都有可能成为潜在的攻击目标。更糟糕的是,随着技术的发展,在未来,制作一个deepfake将不需要大量的原始数据素材,也许一张图片就足够创建一个视频。
三星人工智能研究中心的专家已经成功进行了这类实验。他们开发了一种从非常小的数据集中创建“活肖像”的方法,比如根据《蒙娜丽莎》这样一幅图片生成出人物小动画。

Samsung AI Centery仅用一张照片就能生成玛丽莲梦露的动画视频
有理由担心,新闻编辑室,尤其是记者可能成为deepfakes创造者的主要目标。作为公共人物,记者、主播都有大量可用的数据集,并且让这些人物丢脸、失信,对公共社会有着更大的破坏。这样的实际案例在比利时和印度都有发生。
Deepfakes的双刃
Deepfake的许多核心技术来源于学术界,随后才被利用和滥用。在DRT(Deepfake Research Team)的讨论中,有学者认为不能一概抹杀deepfake。作为故事、内容新的创建工具,它也具有积极的一面。
一个可能的应用是电影制作公司可以利用这项技术进行配音。比如英国综合公司正在利用人工智能技术将演员的嘴部动作同步到新的对话轨道上,从而让演员嘴形和外语配音演员的声音实现更好的契合。在弗罗里达州的一家艺术博物馆里,萨尔瓦多·达利被deepdake所“复活”,现在,游客可以和他一起自拍。

在人工智能等技术让深度伪造成为谎言、攻击武器的背后,还有新技术的进步。以Topaz Lab的Gigapixel AI为例。这是一款基于GANs(生成式对抗网络)的工具,可以将分辨率非常低的图像增强为高分辨率图像,这为旧数字图像的清晰化带来了巨大可能。
当然,我们也不能忘记这项技术也可以用来增强摄像镜头的模糊画质,这有可能对我们的隐私构成威胁,也可能被专制政权所滥用。
解决方案
利用区块链反向追溯
区块链可能是解决deepfakes的有效方式。
区块链是记录互联网数据的全新方式,它能够在去中心化、分散的分布式记账中提供稳定、不可篡改的数据信息。这也许能够重新恢复人们对视频内容的信任。
为了提供安全可靠的历史数据追踪工具,在斯坦福,DRT小组探索开发了区块链程序Vidprov,尝试通过追踪视频内容的来源出处为视频内容提供真实性证明。

Vidprov可以追踪视频的多个编辑版本,每个视频片段都被检验是否与母视频存在智能合约关联。如果无法追踪到母视频,那就表面无法信任该数字视频内容。利用Vidprov,可以帮助用户确定视频是否可追踪到可信、信誉良好的来源,从而打击deepfakes。
编辑室:做好准备
虽然技术解决方案似乎曙光在前,但是在当下,记者们必须依靠自身的各种技能来对deepfakes进行主观判断。
新闻编辑室应开展如何应对这些deepfakes的相关培训,从而帮助记者进行内容检验。
这些基本的培训要点包括:
视频或音频是否存在不一致?
能相信这些信息来源吗?
能找到确切或者完整的视音频吗?
如何检查地理位置等其他元数据?

在现实情境中,编辑室面临的最大威胁不是deepfakes,而是所谓的shallowfakes,比如贴错标签、错误剪辑的视音频内容。但是Deepfakes带来的危险是真实的。他们可以被用来制造数字野火,可以混淆视听,可以移花接木。
那些不发达的社区尤其容易受到deepfakes的攻击。在这些社区中,社会信任本就很低,人们更容易受阴谋论的影响。如果可共享的deepfakes肆虐在这些空间,将进一步削弱对新闻业的信任,给社会带来严重破坏。

现在,大家都在担心2020年总统大选将为deepfakes提供一个更大的“舞台”,但是我们不能静待这种悲剧的发生。进一步提高对deepfakes的认识,为公众媒介素养做好升级准备,在问题升级为真正的灾难前找到好的对策,我们可做的还有很多。
声明:本文来自全媒派,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
