背景
出于中通业务场景的特殊性,我们需要大量的回刷7-15天的数据,如果全部用离线抽取的方式,会给业务系统带来巨大压力,所以利用Hbaserowkey更新的特性,来存储业务数据的历史更新,每天ETL的任务需要大量从Hbase拉取数据,ETL任务需要扫描过滤近百亿数据。
传统的方案是采用的方案是HBaseStorageHandler,利用HBaseStorageHandler把hbase的表映射到hive中去,然后ETL抽取到hive的一个新表中。而这个任务对hbase region server的海量请求会给hbase集群的regionserver带来了很大的压力,时常会导致region server负载告警。凌晨也是离线任务的髙峰期,这个拉取数据的任务消耗了大量集群资源,这不但影响了hbase的作业,也影响了集群其他任务的运行。
为了解决这个问题,通过查看hbase和hive的源码,在社区中寻找支持,发现并没有对这种任务需求的支持和优化。经过调研和探索,最终利用Hbase的SnapshotScanMR这种底层特性,在我们的大数据平台上开发了一种新的任务类型,完美的解决了这种任务对集群带来的负面影响。
旧的方案以及带来的问题
之前在背景中也交代了之前的历史方案是使用HBaseStorageHandler,并在这个方案带来了大量的问题,那么为什么这个方案 HBaseStorageHandler会导致大量的性能问题呢?
首先是 HBaseStorageHandler 底层实际上调用的是 Hbase scan中的 TableScanMR API。
为了让大家更好的理解为什么TableScanMR会带来性能问题,我们这里先讲解下TableScanMR的底层原理,以及它带来的问题。
TableScanMR原理上主要实现了ScanAPI的并行化,将scan按照region边界进行切分。
原理图如下:
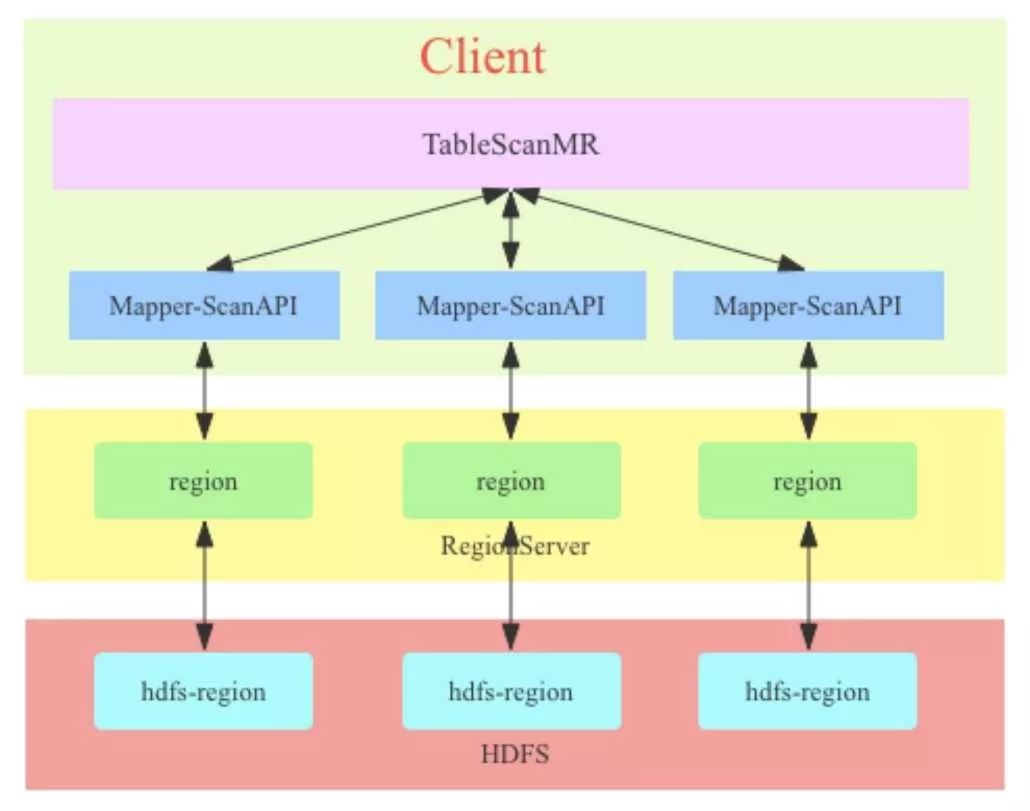
TableScanMR会将scan请求根据目标region的分界进行分解,分解成多个sub-scan。假如scan是全表扫描,那这张表有多少region,就会将这个 scan分解成多个sub-scan,每个sub-scan的startkey和stopkey就是region的startkey和stopkey。(默认切分规则是一个region —个map )而这里的每部分sub-scan由于都是发送next请求到region server,而一次next请求仅可以请求100行数据或者返回结果集总大小不超过2M,服务器端接收到next请求之后就开始从BlockCache、HFile以及memcache中一行一行进行扫描,扫描的行数达到100行之后就返回给客户端,客户端将这100条数据缓存到内存并返回一条给上层业务。
上层业务不断一条一条获取扫描数据,TableScanMR任务会不断发送next请求到HBase服务器,因此当数据量很大的时候,由于scan的next返回条数的限制,加上mr任务的并发scan,会造成一段时间内海量的对regionserver的请求,对资源占用比较严重。这些请求就造成了本文开头叙述的 影响集群稳定,影响hbase的读写和集群中其他任务的执行。
我们的解决方案:hbase to hive Bysnapshot
通过上面的上面的描述相信大家了解了 TableScanMR的缺陷,因此我们在自己的大数据平台上开发出了新的任务类型hbase2hiveBySnapshot, 完美的解决了这个问题。
我们的任务首先对需要导出到hive的表做一个快照,解析用户的输入条件,比如过滤条件和表名等,然后开始利用SnapshotScanMR的自定义inputFormat在内部把每个hregion的hfile作为一个map的输入,并按照表的大小来划分reduce数,接着在reduce中按照用户的条件过滤数据,最终完成后落到hdfs,按用户的输入导入到hive对应的表和分区。
经过测试,新的任务解决了HBaseStorageHandler带来的性能问题,对hbaseregion server完全没有任何压力,并且任务执行时间缩短了一半,相 比之前,资源利用率降低,集群的稳定性也得到了提升。
那么为什么我们的新任务能解决原来的性能问题呢?首先原来任务的SnapshotScanMR扫描于原始表对应的snapshot(快照)之上(更准确来说根据 snapshot restore出来的hfile),TableScanMR扫描于原始表,并发大量的Scan API至Ijregion server。而SnapshotScanMR直接会在客户端打开 region扫描HDFS上的文件,不需要发送Scan请求给RegionServer,从而绕过RegionServer在客户端直接扫描HDFS上的文件。
原理图如下:
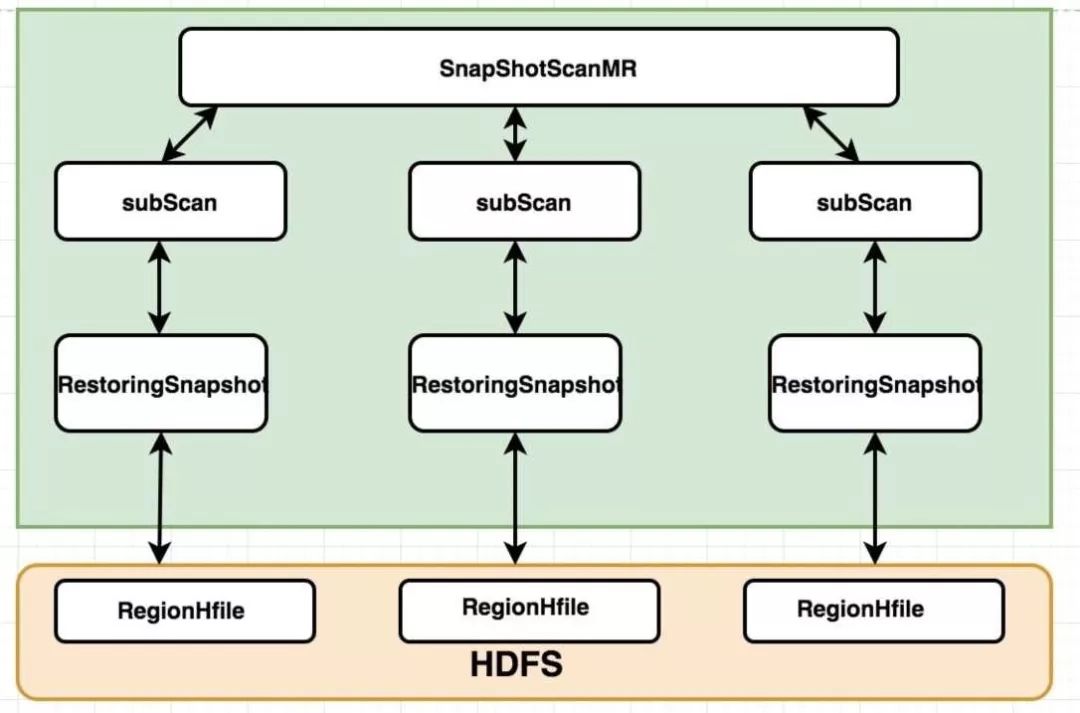
这样做的好处是减小对RegionServer的影响。SnapshotScanMR这种绕过RegionServer的实现方式最大限度的减小了对集群中其他业务的影响。极大的提升了扫描效率。并且经过测试,我们的新的任务相比之前在扫描效率上会有2倍的性能提升。
目前这个任务还有很多不足之处可以继续提升,比如底层支持filter,跳过对没有数据的hFile的操作, 支持更灵活的任务切分(region切分到支持用户自定义分片),也欢迎大家多提意见,共同交流。
声明:本文来自科技中通,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
