一、前言
注:本文内容是是笔者尝试从多年的安全分析经验中抽取图相关的内容总结和外延而来,不求全面深入,但求分享切身体会。
人类总是在不停的审视自我和认知世界,计算机科学作为人类思维方式和行为能力的延伸,也是从深度和广度两个方面去求真,求是。从近两年的Gartner的技术曲线来看,机器学习(Machine Learning)和深度学习(Deep Learning)都获得了大量的关注,其中机器学习这项技术在2018年的新兴技术曲线中并未出现,也从侧面体现了机器学习已经得到广泛应用,不再属于新兴技术了。
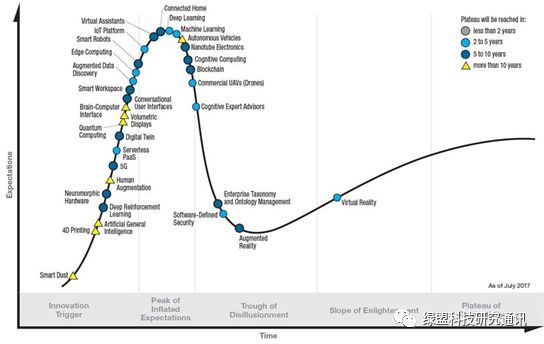
图 1.1 Gartner Hype Cycle for Emerging Technologies 2017[1]

图 1.2 Gartner Hype Cycle for Emerging Technologies 2018[2]
英国的明星安全公司Darktrace在其白皮书写到:“Machine Learning: A Higher Level of Automation”[3],这个对机器学习的定义是笔者目前看来对于机器学习应用前景的最为精确的描述。

图 1.3 Darktrace的机器学习白皮书
如果说现在大火的机器学习和深度学习,是统计学和模式识别在海量历史数据上的深化和优化,那么图挖掘(Graph Mining)和社交网络分析(Social Network Analysis)等图相关的分析方法,则是试图从广度、关联性和网络结构性上去探寻群体性知识和构建知识结构,本质上也是检索、识别和认知的自动化。
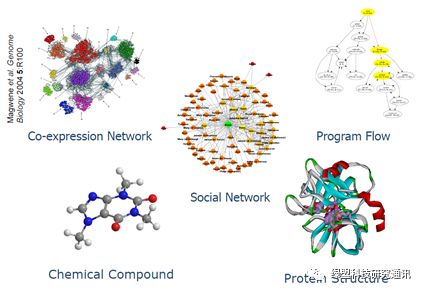
图 1.4 无处不在的图关系[4]
下文则从应用场景、引擎/架构和算法进行总结和分享。
二. 图分析应用场景
图分析的应用场景还是比较丰富的,适用的业务领域网络安全、电信诈骗、金融风控、广告推荐、社交网络和智能机器人等,我们团队也将图计算应用到样本行为、告警分析、UEBA(用户实体行为分析)、DNS分析和攻击团伙分析等安全相关领域。
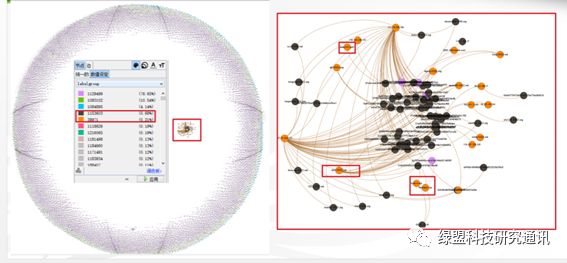
图 2.1 恶意样本网络访问行为的关联性和层次性分析
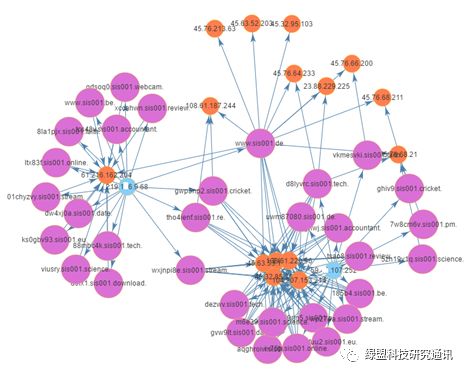
图 2.2 恶意域名、主机、客户端三者的关联图谱分析挖掘
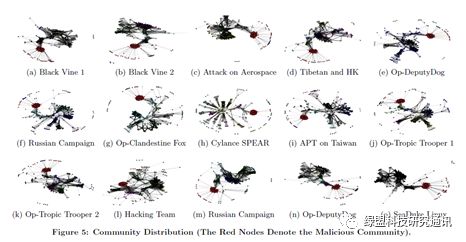
图 2.3 告警关联性分析[HERCULE][5]
三. 图计算引擎/架构概述
针对图计算的框架整体来说还是落在两类中:联机事务处理OLTP(on-line transaction processing)和联机分析处理OLAP(On-Line Analytical Processing),部分主要面向OLTP应用的图数据库也通过自有平台或者引入外部引擎支撑OLAP分析。
OLTP应用主要是由图数据库进行支撑,或者由KV数据库/文档数据库结合上层API进行支撑。图数据库的热门选项[6]主要是Neo4j[7],OrientDB[8]和ArangoDB[9]等,这三家公司在2018年还因为ArangoDB搞的Benchmark的问题来回交锋多次[10][11],大家感兴趣的话可以自己去翻阅。
其余还有一些开源大数据组件结合比较紧密的选择,例如Titan,JanusGraph,HugeGraph。Titan背后整个团队Aurelius在2015年2月份被DataStax(DataStax的核心产品是Apache Cassandra™)收购了后[12],在同年12月份就停止了更新。Titan作为大规模图数据库的领军项目,从开源社区离开后,市场上连续两年缺乏一个较为成熟的开源数据库框架。终于在2017年2月,来自Google Cloud Platform的Misha Brukman创建了JanusGraph,这个项目fork了Titan的核心代码,试图继续用开源的力量延续Titan的传奇,背后也得到了Expero,GRAKN.AI,Hortonworks,IBM和Amazon等商业大佬的加持。IBM还提供了基于JanusGraph的云服务[13]。国内的话,图数据库的生态支持主要来自于互联网大厂和一部分商业公司,360在生产系统里面部署了JanusGraph[14],百度安全也凭着雄厚的技术实力自主研发了全面支持Apache TinkerPop 3框架和Gremlin图查询语言的大型分布式图数据库HugeGraph[15]。还有一些商业图数据库TigerGraph(连百度的搜索关键词hugegraph都买了放广告[16])。此外,还有看见由国内团队使用高速的KV数据库(TiDB)进行图应用的二次开发[17]。总的来说,图数据库还未出现de facto最佳实践和最优选择,各家的Benchmark往往都是针对单台进行测试的,分布式性能横评较少,整体还在一个比较混沌的状态。
OLAP应用框架基本上都是基于Google三驾马车之一Pregel[18]的实现,就主要Giraph[19],PowerGraph[20],GraphX[21]这几个选择。Apache Giraph是2012年开始的,该项目由于底层并行框架是基于Apache Hadoop的MapReduce框架来实现的,在Spark流行之后也不如GraphX有活力了。Facebook一直是Giraph的拥趸,其研究团队在2016年发布了一份报告[22],比较了Giraph和GraphX在他们的应用场景下的性能,总的来说,GraphX 不足以支持他们图处理负载的扩展性和性能需要,但GraphX的易用性更好。Facebook的应用场景往往都是几百亿的边规模,一般公司或研究者往往遇不到,因而在更多场景下用户可能向易用性妥协。

图 3.1 PageRank (左)和Connected Components (右)在GraphX和Giraph中的性能比较
PowerGraph就比较有意思了,如果查阅资料的话,会发现PowerGraph和GraphX都有同一个人:Joseph E. Gonzalez,现在是UC Berkeley的助理教授,同时还是Turi Inc.(原来的GraphLab)公司的联合创始人。在2010年到2012年间,Y Low,J Gonzalez和C Guestrin经常在一起发论文。后来C Guestrin成了GraphLab的CEO(现在是Senior Director of AI and Machine Learning at Apple,以及Amazon Professor of Machine Learning at University of Washington),J Gonzalez是联合创始人,Y Low是首席架构师。J Gonzalez在2012年8月博士毕业之后就去UC Berkeley 的AMPLab当博士后,搞Spark的GraphX去了。

图 3.2 Joseph E. Gonzalez的研究及合作者关键词
从上面的词语图大概也能看出他的研究脉络,从并行,分布式起家,解决图计算中的核心消息传递模型和并行框架,然后扩展到其他机器学习领域,非常硬核。这位大神在12年在Carnegie Mellon University提出了底层基于C++和MPI并行的支持异步计算的PowerGraph框架,框架支持同步并行(MapReduce)和异步并行,相当于是Pregel的加强版实现了。转眼两年后到Berkeley去实现了GraphX。PowerGraph之前还存活的时候用过,得益于底层实现机制,比Giraph和GraphX快得不是一星半点。
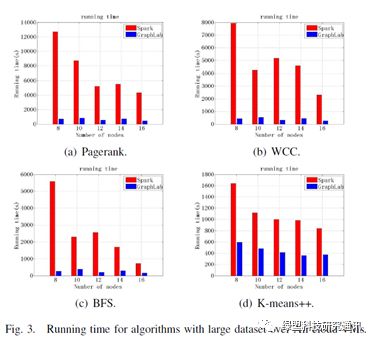
图 3.3 GraphLab和Spark的分布式性能比较[23]

图 3.4 GraphLab和GraphX的分布式性能比较[24]
Joseph E. Gonzalez 等人创建了GraphLab公司,一大产品就是GraphLab机器学习框架,PowerGraph后来成为GraphLab一个主要的底层框架。GraphLab一开始是一个开源项目,但它的同名母公司在接受了两轮投资之后,该项目由原来的开源项目变成了一个付费试用的项目。GraphLab公司的网址也经历了两轮更换,第一次从graphlab.org也变成了dato.com,后来更名为turi.com。Turi Inc.在2016年的时候被苹果公司收购后,PowerGraph在同年7月份之后便不再更新了。
GraphX虽然没办法避免MapReduce框架在迭代计算中的局限性,但得益于Spark的全数据流程分析能力、内存计算和数据血缘能力,获得了长久的生命力,也是现在应用最为广泛的OLAP图计算框架。

图 3.5 MapReduce在迭代计算中的局限性[25]
图数据库包括Titan,JanusGraph和Hugegraph,也都可以外接Spark进行OLAP批量图计算任务。
那么根据上文和本人未花太多时间收集到的片面信息,就可以画出下面这个图计算框架,底层存储/计算框架和厂商之间的关系图谱。

图 3.6 图计算框架,底层框架和厂商之间的关系
四. 图算法概述
图算法的分类有很多。Neo4j在他们写的书《Graph Algorithms: Practical Examples in Apache Spark and Neo4j》[26]里面将图算法分为三类:路径搜寻(Pathfinding),中心性评估(Centrality),社区发现(Community Detection)。图评估类算法和社区发现类算法是笔者关注的两类算法,下文仅从这两类进行介绍。
1 社区发现类算法
1.1 Connected Component
Connected Component算法可以称作连通子图算法,用于无向图中,即意图寻找这样的一些社群,社群与社群之间毫无联系,社群内部任意两个体存可达关系。该算法的时间复杂度是O(V + E),V是节点数量,E是边的数量。下面这个图就存在三个连通子图(Component)。
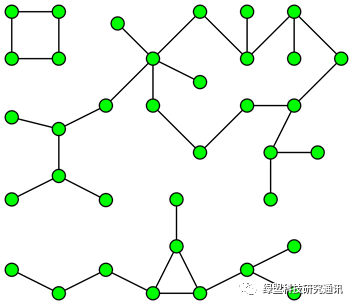
图 4.1 存在三个连通子图的图[27]
哈佛大学心理学教授斯坦利·米尔格拉姆于1967年根据这个概念做过一次连锁信实验,尝试证明平均只需要6步就可以联系任何两个互不相识的美国人[28]。后世的人们将这个理论称作是“六度空间理论”或“六度分隔理论”。微软的研究人员 Jure Leskovec 和 Eric Horvitz过滤2006年某个单一月份的MSN简讯,利用2.4亿使用者的300亿通讯息进行比对,结果发现任何使用者只要透过平均6.6人就可以和全数据库的1,800百亿组配对产生关连。48%的使用者在6次以内可以产生关连,而高达78%的使用者在7次以内可以产生关连[29]。Facebook也根据社交网络数据进行测量,测量结果的均值是3.57人[30],意味着每个人与其他人间隔为3.57人。这一系列研究从事实和数据层面告诉人们似乎世界并不大,个人观点和影响有希望影响更多的人,这也是“六度空间”理论在保险和直销行业里应用甚广的原因。
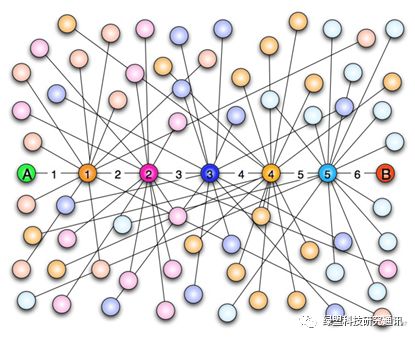
图 4.2 著名的六度空间理论[31]
六度空间理论没有考虑沟通成本,Connected Component也没有考虑边权值和实体角色,这就造成Connected Component发现的社群过大。在日常的DNS分析中,如果将域名和IP的解析关系形成关系图谱,会发现大量的域名和IP被分到最大的Component里面,可能的原因包括域名曾经解析到热门的CDN IP上,或多个域名解析到相同的IP集合中。各地运营商也有可能将不存活的域名的解析请求导向自身的网址导航页,导致大量的DGA域名也会指向这种IP。
因此,Connected Component往往作为分析图结构的初步方法,能够快速得到图中相互绝缘的群体,但不适合对社群结构的精细化分析或层次结构的分析。
1.2 Label Propagation
Label Propagation也称作标签传播算法(LPA),由Raghavan等人在2007年于论文《Near linear time algorithm to detect community structures in large-scale networks》[32]中提出。这个算法试图让稠密连接的顶点组在一个唯一的标签上达成一致,进而将这些标签相同的组定义为一个社区。

图 4.3 LPA的算法流程示例图[33]
这是一个迭代的计算过程且不保证收敛,大体的思路就是每个人都看看自己的邻居都在什么社区内,看看频率最高的社区是啥,如果和自己当前的社区不一样,就把这个最高频社区当成是自己的社区,然后告诉邻居,周而复始,直到对于所有人,邻居们告诉自己的高频社区和自己当前的社区是一样的,算法结束。所以说对于这个算法,计算复杂度是O(kE),k是迭代的次数,E是边的数量。大家的经验是这个迭代的次数大概是5次就能近似收敛,以实现精度和性能的平衡,能发现这个数字和六度分隔理论里面的数字也差不多。这种说不清楚的经验值往往称之为“炼丹术”。在《Spark GraphX实战》中,也给出了一个LPA不收敛的例子,如下图所示。在实际应用中,不收敛其实并不常常意味着未达到目的。能看到下图中,从第2步开始,社区分类就已经得到结果了。

图 4.4 《Spark GraphX实战》中LPA不收敛的例子[34]
1.3 Louvain算法
Louvain算法是在2008年,由天主教鲁汶大学(University of Louvain)的研究者在论文《Fast unfolding of communities in large networks》[35]中提出,也有人将这个算法称作Fast unfolding算法。该算法的目标是找到整个网络的模块度(Modularity)最高的划分方法,模块度是一种度量社区划分优劣的标准,模块度值越大,说明社区划分的效果越好。网上也有同学将这个算法的原理讲述得比较清楚了,在这里的就不再详述其原理细节了[36],希望能够用比较浅显的文字描述清楚该算法的核心目标和应用。
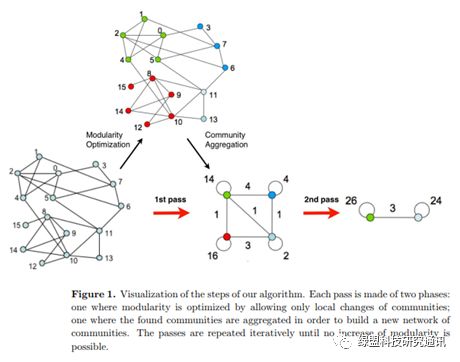
图 4.5 Louvain算法中的关键两个步骤
Louvain算法主要分为两个步骤:
在第一个阶段中,该算法遍历网络中的每个节点。对于每个节点,将其从当前社区中移除,并替换它到其邻居的社区中。然后针对每个邻居节点,计算移动后全图的模块性变化,如果这些模块性变化都没有正向变大,则节点将保留在当前社区中。如果某些移动导致模块性正向变大,则节点将移动到模块性正向改变最大的社区。对每个节点重复这个过程,直到任意一个节点替换到邻居节点所在的社区中不会产生任何社区分配更改。
第二阶段使用在上个阶段中发现的社区,来定义一个新的粗粒度网络(coarse-grained network)。在这个网络中,新发现的社区是节点。两个社区的节点存在关系,其权重是每个社区较低层节点之间关系权重的总和。
然后就是重复第一阶段过程和第二阶段过程。在每一轮迭代中,通过将第一阶段(社区重新分配阶段)应用于粗粒度图,我们发现了基于粗粒度图的第二层社区,粗粒度图的每个节点其实上一轮的一个社区。然后,应用第二阶段流程,相当于在层次结构中的更高级别定义一个新的粗粒度图。我们一直这样做,直到第一阶段过程没有产生任何重新分配。这时,重复应用第一个阶段和第二阶段将不会产生模块度提升,整个迭代过程就完成了。
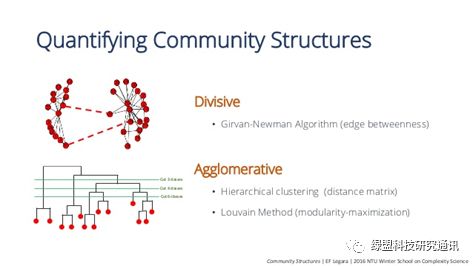
图 4.6 聚类层次[37]
从上面的算法描述可以看出,Louvain算法相当于图计算中的层次聚类,从每轮迭代的结果我们也能获取网络拓扑中的层次结构,这个过程是无监督的。图分析很重要的一点就是能通过关系计算辅助可视化,层次结构的提取有助于我们加深社团结构。利用Louvain算法,数据分析人员只需要关注权重的设置,也就是图分析里面的特征工程,最终结合层次结构和模块度输出期望的聚类结果。至于算法复杂度,尽管准确度模块度最优化是NP-hard的,在大多数情况下,Louvain算法复杂度是线性的O(n log n)[38]。
2图评估类算法
图的度量方式有很多种[39][40],笔者比较喜欢SparklingGraph[41]针对应用对象的评估类别进行划分,分别是对节点,边和图进行评估,更加实用。因此,下文尝试从这三个角度介绍三个评估目标的方法集合。
2.1 节点评估类
节点的评估大体有7种,都是从不同侧面定量计算节点的重要程度,周围邻居的状况以及在整体网络中的角色:
Closeness centrality:测量一个节点与其余节点的距离特性,其值为一个节点与其余节点的最短距离之和的倒数;
Eigenvector centrality:测量给定节点在网络中的重要性。
HITS:该算法会给每个节点两个属性:Hub(枢纽性)和Authority性(权威性),该算法由Kleinberg在1997年在论文《Hubs, Authorities, and Communities》[42]提出,和PageRank一样,是链接分析中非常基础且重要的算法。在链接分析领域中,“Authority”页面,是指与某个领域或者某个话题相关的高质量网页,比如搜索引擎领域,Google和百度首页即该领域的高质量网页,比如视频领域,优酷和土豆首页即该领域的高质量网页。所谓“Hub”页面,指的是包含了很多指向高质量“Authority”页面链接的网页,比如hao123首页可以认为是一个典型的高质量“Hub”网页[43]。
Degree centrality:这个就是基础图论里面的节点的度分析,每个节点都可以计算其出度、入度和度。
Neighborhood Connectivity:这个度量值是邻居节点的度的均值。
Vertex Embeddedness:这个度量方式是指,对于一个节点,它的所有邻居的邻居和自己的邻居的重合个数,除以邻居的邻居和自己的邻居的并集的个数,最后加总后,再除以自己邻居的个数。最后衡量的,简言之,其实是我认识的人是不是我邻居都认识。值越大,说明,这个节点位于一个互关联越强的网络中。
Local Clustering Coefficient:和Vertex Embeddedness类似,也是衡量邻居之间的紧密程度。
2.2 边评估类
SparklingGraph实现了两种边评估算法:
一个是Common Neighbours,即看两个节点的邻居重合个数;
另外一个是Adamic/Adar,这个度量源于2009年在Springer上发表的论文《Predicting missing links via local information》[44],可以看做是衡量共同邻居数量的另外一个版本,只是给予越孤僻(邻居越少越孤僻)的邻居更高的权重
2.3 聚类评估类
模块度评估(Modularity):Modularity其实在上文中也讲述了它在聚类算法中应用,可以有不同的实现方式,通常值位于-1到1之中,如果值越靠近1,说明图存在比较强的社群特性。如果是靠近0的话,就近似于没有社群特性。
Freeman’s network centrality:该度量方式则是衡量一个网络中,节点的出入度有多不同。在一个星型网络中,这种评估方式得到的值为1。
五. 总结
本篇文章东拼西凑,尝试着梳理从图分析的愿景,应用场景,实现引擎和算法应用等几个方面,给出自己不成熟的归纳和意见。对笔者而言,是一次阶段性的总结,希望也能帮助各位看官明晰图应用场景和算法功效,提升实战落地的位置感。
参考链接:
[1].https://www.researchgate.net/publication/324137011_On_the_Development_of_Intelligent_Railway_Information_and_Safety_Systems_An_Overview_of_Current_Research/figures?lo=1
[2].https://www.gartner.com/smarterwithgartner/5-trends-emerge-in-gartner-hype-cycle-for-emerging-technologies-2018/
[3].https://www.ciosummits.com/Online_Asset_Darktrace_Whitepaper-Machine_Learning.pdf
[4].https://www.ethz.ch/content/dam/ethz/special-interest/bsse/borgwardt-lab/documents/slides/CA10_GraphMining.pdf
[5].https://www.cs.purdue.edu/homes/dxu/pubs/HERCULE.pdf
[6].https://www.g2.com/categories/graph-databases
[7].https://neo4j.com/
[8].https://orientdb.com/
[9].https://www.arangodb.com/
[10].https://www.arangodb.com/2018/02/how-we-wronged-neo4j-postgresql-update-arangodb-benchmark-2018/
[11].https://orientdb.com/category/benchmark/
[12].https://www.datastax.com/2015/02/datastax-acquires-aurelius-the-experts-behind-titandb
[13].https://cloud.ibm.com/catalog/services/compose-for-janusgraph
[14].https://janusgraph.org/
[15].https://hugegraph.github.io
[16].https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=hugegraph&rsv_pq=b493ad65000fdba3&rsv_t=3ff7aXxfITsQVk%2FPMO2BACfxHqnPOWJaLeOtKfZ%2FRMn3FrZyVvZPh9NZXwg&rqlang=cn&rsv_enter=1&rsv_n=2&rsv_sug3=8&rsv_sug1=5&rsv_sug7=101
[17].https://zhuanlan.zhihu.com/p/31474454
[18].http://dl.acm.org/citation.cfm?id=1807184
[19].https://github.com/apache/giraph
[20].https://www.usenix.org/node/170825
[21].https://www.usenix.org/node/186217
[22].https://code.fb.com/core-data/a-comparison-of-state-of-the-art-graph-processing-systems/
[23].https://ieeexplore.ieee.org/document/7474329
[24].https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-gonzalez.pdf
[25].http://cloud.berkeley.edu/data/graphlab.pptx
[26].https://neo4j.com/graph-algorithms-book/
[27].https://en.wikipedia.org/wiki/Component_(graph_theory)
[28].https://zh.wikipedia.org/wiki/%E5%85%AD%E5%BA%A6%E5%88%86%E9%9A%94%E7%90%86%E8%AE%BA
[29].http://erichorvitz.com/Leskovec_Horvitz_worldwide_buzz.pdf
[30].https://research.fb.com/three-and-a-half-degrees-of-separation/
[31].https://zh.wikipedia.org/wiki/File:Six_degrees_of_separation.png
[32].https://arxiv.org/abs/0709.2938
[33].https://neo4j.com/graph-algorithms-book/
[34].https://book.douban.com/subject/27004653/
[35].https://arxiv.org/pdf/0803.0476.pdf
[36].https://blog.csdn.net/google19890102/article/details/48660239
[37].https://www.slideshare.net/ErikaFilleLegara/community-detection-with-networkx-59540229
[38].https://perso.uclouvain.be/vincent.blondel/research/louvain.html
[39].http://braph.org/manual/graph-measures/
[40].https://reference.wolfram.com/language/guide/GraphMeasures.html
[41].https://sparkling-graph.readthedocs.io/en/latest/measures.html
[42].https://dl.acm.org/citation.cfm?id=345982
[43].https://blog.csdn.net/hguisu/article/details/8013489
[44].http://link.springer.com/article/10.1140/epjb/e2009-00335-8
声明:本文来自绿盟科技研究通讯,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
