1 概述
本文概要性地描述了一种企业敏感数据分级分类、采集、识别、分布展示的高效全面的自动化探查方法。
1.1 引言
随着信息技术的迅猛发展,各行各业都高度依赖信息系统,如何保障信息系统的安全,尤其是如何保障体现企业核心价值的数据的安全,成为企业最为关心的事情。企业数据包含着许多用户个人隐私信息、商业敏感数据等,一旦泄漏,会给企业带来巨大的经济损失,并需承担相关法律责任和巨额的违规罚款。因此,如何保障企业用户个人隐私信息、商业敏感数据等的安全,成为企业信息安全工作的重中之重,而首先要做的是找到一种可全面、快速、尽可能不需要人工干预的发现企业用户个人隐私信息、商业敏感数据等分布的探查方法。
1.2 必要性与现状分析
当前,全球数据泄漏事件频发。2019年1月,一桩被称为“Collection#1”的“史上规模最大公共数据泄露事件”遭到了曝光,包含将近7.73亿个独立电子邮件地址、2122万多个独立密码。2019年1月,印度10亿公民身份数据库Aadhaar被曝遭网络攻击,该数据库除了名字、电话号码、邮箱地址等之外还有指纹、虹膜纪录等极度敏感的信息。2018年3月Facebook5000万用户的个人信息遭泄露,因违反隐私法可能面临16亿美元的罚款。2018年12月,万豪酒店数据库被黑,5亿客户数据泄漏。2018年8月,华住旗下多个连锁酒店5亿开房信息数据在暗网出售。2018年6月,圆通10亿条快递数据被在网上兜售。
面对全球数据泄漏事件频发的状况,为了更好地保护公民个人隐私信息,各国相继出台了相关的数据保护法规条例等,其中最为严格的是2018年5月欧盟出台的《通用数据保护条例》(General Data Protection Regulation,简称GDPR),该条例适用于处理欧盟境内利用个人数据的所有组织,一旦违背将面临极其高额的罚款。我国也出台了一系列相关法律法规,包括:《中华人民共和国网络安全法》、《关键信息基础设施保护条例》、《网络数据安全管理办法》、《个人信息和重要数据出境安全评估办法》、《GB/T 35273 个人信息安全规范》、《电信和互联网用户个人信息保护规定》等。
面对频发的数据安全事件和愈来愈严格的数据安全保护要求,企业都已认识到数据安全保护的重要性,但企业首先面临的是不知道自己有哪些敏感数据、都是什么级别什么类型、分布在哪里、无法可视化展示等难题,只有解决这些难题,才能够进一步考虑如何去有针对性地保护这些敏感数据。
1.3 方法概述
本方法首先对所辖范围的数据进行梳理,进行数据分类和分级,然后结合已有的资产探查管理系统和4A系统,自动化采集应用服务器、数据库服务器、运维终端等的数据,采用多种敏感数据识别算法,根据事先定义好的策略,进行敏感数据识别,结合数据分类分级,以数据地图的方式,可视化地展示出敏感数据的分布情况。
2 系统实现
2.1 数据梳理
2.1.1 数据范围及分布
本文将以中国移动集团山东省公司(简称山东移动)网络支撑域系统(O域)相关的系统和数据为例。
网络支撑域系统(O域)的系统包括:话务网管系统、数据网管系统、传输网管系统、电子运维系统(EOMS)、无线网优平台、资源管理系统、故障管理系统、性能管理系统、自动拨测系统、自动路测系统等。
信令/DPI系统的系统包括:统一DPI系统、信令监测系统、上网日志留存系统、数据业务监测与分析系统、WLAN日志留存系统、LTE信令监测系统等。
网络支撑域系统(O域)的数据包括:性能数据、MR数据、日志数据(分平台)、资源数据、告警数据、工单数据、拨测数据、路测数据等。
信令/DPI系统的数据包括:Mc口XDR、2/3G信令面XDR、2/3G用户面XDR、LTE信令面XDR、LTE用户面XDR、省网出口XDR、IDC出口XDR、省网网间出口XDR、骨干网网间出口XDR等。
2.1.2 中国移动数据分类分级
2.1.2.1 中国移动数据分类
根据中国移动内部管理和对外开放场景的特点,可将其内部B域系统、O域系统、M域系统、信令DPI系统、业务管理平台等数据整合分为四大类。
(一) 用户身份相关数据(A类)
●用户身份和标识信息:自然人身份标识、网络身份标识、用户基本资料、实体身份证明、用户私密资料
●用户网络身份鉴权信息:密码及关联信息
(二) 用户服务内容数据(B类)
●服务内容和资料数据:服务内容数据、联系人信息
(三) 用户服务衍生数据(C类)
●用户服务使用数据:业务订购关系、服务记录和日志、消费信息和账单、位置数据、违规记录数据
●设备信息:设备标识、设备资料
(四) 企业运营管理数据(D类)
●企业管理数据:企业内部核心管理数据、企业内部重要管理数据、企业内部一般管理数据、市场核心经营类数据、市场重要经营类数据、市场一般经营类数据、企业公开披露信息、企业上报信息
●业务运营数据:重要业务运营服务数据、一般业务运营服务数据、公开业务运营服务数据、数字内容业务运营数据
●网络运维数据:网络设备及IT系统密码及关联信息、核心网络设备及IT系统资源数据、重要网络设备及IT系统资源数据、一般网络设备及IT系统资源数据、公开网络设备及IT系统资源数据、公开网络设备及IT系统支撑据
●合作伙伴数据:渠道基础数据、CP/SP基础数据
2.1.2.2 中国移动数据分级
数据分级依据以下原则:
●各级界限明确原则:数据分级是按照数据敏感程度进行划分;
●就高不就低原则:如果同一批数据中各属性或字段的分级不同,需要按照定级最高的属性或字段的级别一并实施安全管控,即“就高不就低”。
参照《电信和互联网服务用户个人信息保护分级指南》和《中国移动通信集团公司商业密码保护实施办法》,中国移动根据敏感程度不同,将数据划分为四级。
(一) 第4级 极敏感级
●A类:实体身份证明、用户私密资料、用户密码及关联信息
●D类:企业内部核心管理数据、市场核心经营类数据、网络设备及IT系统密码及关联信息、核心网络设备及IT系统资源类数据
(二) 第3级 敏感级
●A类:自然人身份标识、网络身份标识、用户基本资料、服务内容数据、联系人信息、服务记录和日志、位置数据
●D类:企业内部重要管理数据、市场重要经营类数据、企业上报信息、重要业务运营服务数据、重要网络设备及IT系统资源类数据、渠道基础数据、CP/SP基础数据
(三) 第2级 较敏感级
●C类:消费信息和账单、终端设备标识、终端设备资料
●D类:企业内部一般管理数据、市场一般经营类数据、一般业务运营服务数据、一般网络设备及IT系统资源类数据、网络设备及IT系统支撑数据
(四) 第1级 低敏感级
●C类:业务订购关系、违规记录数据
●D类:企业公开披露信息、业务运营服务数据、数字内容业务运营数据、公开网络设备及IT系统资源类数据
2.1.3 数据梳理、分级、分类
中国移动对数据进行了大的分类分级,但具体到敏感数据发现,还需要更进一步地进行敏感数据识别算法可以进行识别的更具体的数据梳理、分级、分类。

2.1.3.1 数据梳理
企业对自己所拥有的数据并没有完整的认识,存在以下问题:
1.由于企业各部门业务的独立性和多部门之间业务的重叠性,造成具体实施分类分级的多数员工对现有数据该分入何类,很难做出明确判断。
2.针对已经存在的海量历史数据,由于负责分类员工的知识和经验局限,通常很难根据部门业务特征和具体内容,使用人工鉴别方式将数据划分入适用的类别。
3.即使企业已经规范了关键数据类别,通过人工鉴别方式将海量数据逐一对应到不同类别中,其消耗的时间和财务成本也是明显过于高昂而无法实现。
企业需要对自己拥有的数据进行梳理。如下图1所示,是数据梳理、分级、分类的流程图。
数据梳理的工作流程:
●步骤1:指定待梳理数据。
●步骤2:先对该路径下的数据进行文本内容提取,然后利用中文分词、停用词过滤等数据清洗技术对提取到的文本内容进行数据清洗,最后利用特征工程技术(比如LDA主题模型、Word2vec词向量)自动提取语义特征。然后选择自动聚类算法(比如K-means聚类算法、基于密度峰值得聚类算法),对待梳理数据进行自动聚类,得到X(X>0)个带数字标签的数据类别。
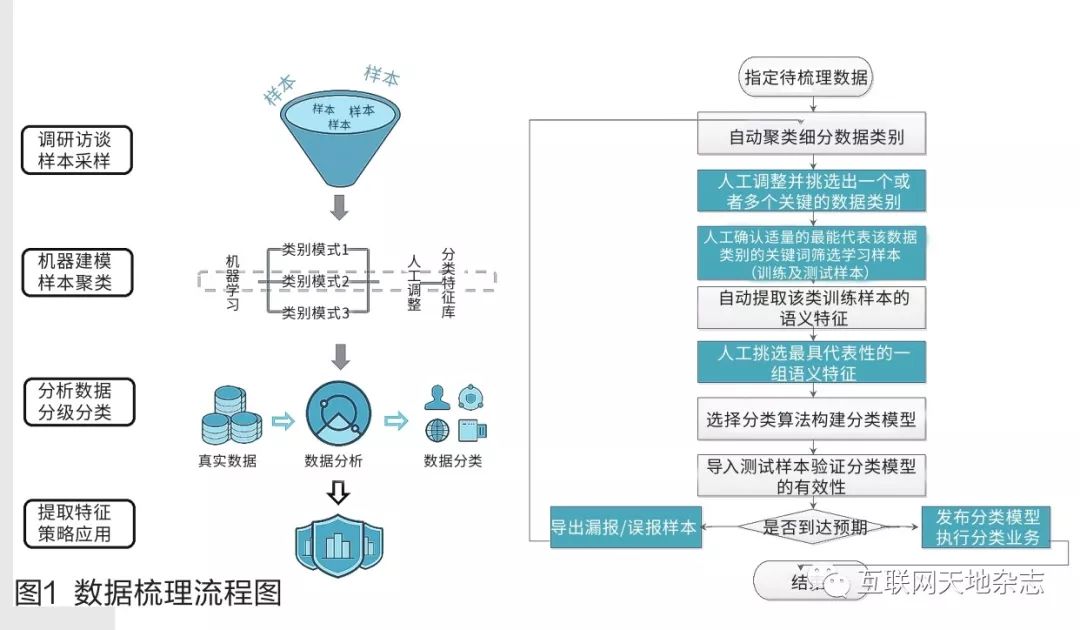
图1 数据梳理流程图
●步骤3:聚类完成后,接着采取人工观察文件名或文件内容的方式判断聚类结果的准确性,通过修改聚类别类数参数、移动文件或者合并类别等人工操作调整聚类结果直至最优,最终得到Y个数据类别(Y <=X),然后依据所表达的主题修改Y个数据类别的标签名称为文字标签,最后由客户确认其一个或者多个关键业务数据类别,对每个关键业务数据类别均收集适量的符合此类别的数据样本。
●步骤4:操作人员与客户确认适量的最能代表该类数据的关键词,通过该关键词利用关键字模式匹配技术筛选出那些包含最多关键词且关键词出现次数最多的文件作为该类别的典型的学习样本,将学习样本等分为训练样本和测试样本。
●步骤5:对该类训练样本进行文本内容提取,然后利用中文分词、停用词过滤等数据清洗技术对提取到的文本内容进行数据清洗,最后利用特征工程技术(比如利用词频逆文档频率TFIDF、卡方统计量、互信息量MI、信息增益IG进行语义特征的提并利用TF-IDF进行语义特征的表示、LDA主题模型、Word2vec词向量)自动提取出该类学习样本的语义特征。
●步骤6:操作人员在所有被自动提取出的语义特征中,挑选最具代表性的一组语义特征。
●步骤7:指定分类算法(比如基于机器学习的KNN、朴素贝叶斯、决策树、随机森林、SVM支持向量机,以及基于深度学习的字符集卷积神经网络Text-CNN或者Char-CNN)对该类最具代表性的语义特征建立分类模型(若操作人员挑选了多种关键数据类别,则对各个类别执行上述步骤5-6操作)。
●步骤8:导入测试样本利用得到的分类模型进行分类,将实际分类结果与预期结果进行比较验证上述模型的有效性(采用检出率、准确率及F1综合指数等评价标准),无效则执行步骤9操作,反之则执行步骤10操作。
●步骤9:剔除漏报或者误报学习样本,重复执行步骤2-8,进行聚类、关键词筛选、语义特征提取及筛选、建立分类模型,验证分类模型有效性直至模型到预期目标。
●步骤10:将指定类型数据的分类模型发布,执行数据分类业务。
2.1.3.2 数据分级分类
数据分级分类规则生成如下图示,可根据企业实际情况,从标准制定、准备样本数据、规则生成三个方面进行,如下图2所示。
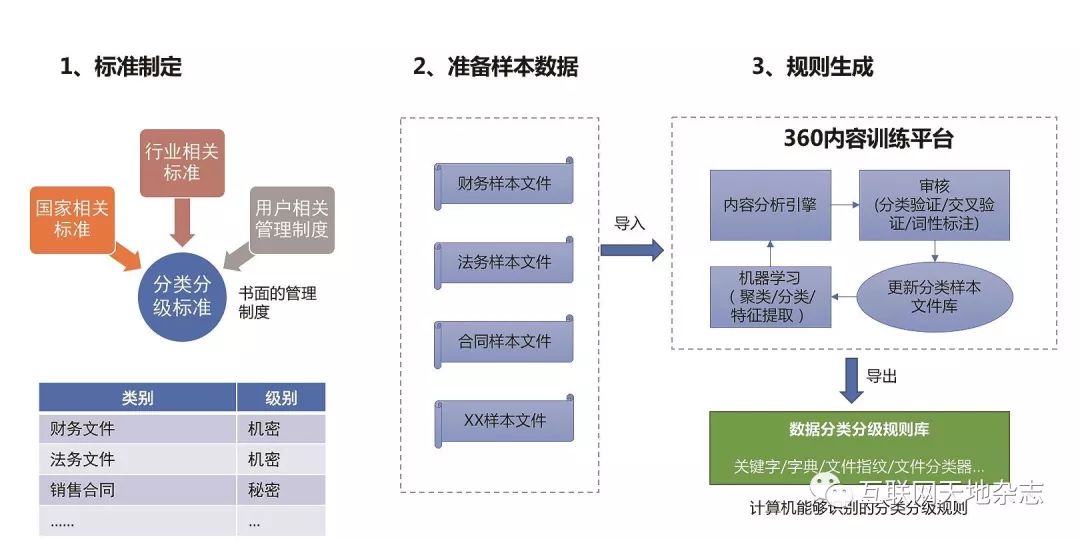
图2 数据分级分类规则生成过程图
2.2 数据采集
数据采集,首先通过已有的资产探查管理系统获取需要采集数据的应用服务器、数据库服务器、运维终端等的资产信息,然后从4A平台获取其账号密码,自动登录采集所需要的文件、文档、图片、数据库、图像、二进制文件等数据。
●文件格式
支持对常见办公类软件的格式分析及数据还原,可以实现多达上千种文件格式的自动识别,支持的文件类型包括:
1)Office文件(Word/Excel/Powerpoint);
2)PDF文件;
3)TXT文件;
4)WPS文件(文件/图表/PPT);
5)图纸文件(AutoCAD/Solidworks/UG/ProE/Catia…);
6)程序文件(C/Java/PHP/Python/Perl…);
7)压缩文件(WinZip/WinRAR/360压缩…);
8)保护文件(office启用文件保护,加密的压缩文件)
●OCR(光学字符识别)
集成了业内领先的光学字符识别引擎,能够识别并提取各类图形文件中的文本数据,现阶段被重点应用于图像文字提取、公章、红头公文等数据的识别。支持的图像文件格式包括:JPEG/JPEG2000/GIF/BMP/PCX/PNG/TIFF。
2.2.1 应用服务器数据采集
对FTP、共享目录形式的文件服务器、Exchange邮件服务器、以及其他应用服务器进行数据采集。
2.2.2 数据库服务器数据采集
对Oracle、MSSQL、Mysql、PostgreSQL,Access、DB2、Informix、Sybase等主流数据库进行数据采集。
2.2.3 运维终端数据采集
对运维终端上存储的各种形式的文件、文档、图片、图像、二进制文件等进行数据采集。
2.3 数据预处理
我们采集到的数据会存在有缺失值、重复值等,在使用之前需要进行数据预处理。数据预处理没有标准的流程,通常针对不同的任务和数据集属性的不同而不同。数据预处理的常用流程为:去除唯一属性、处理缺失值、属性编码、数据标准化 正则化、特征选择、主成分分析。
2.4 敏感数据识别
2.4.1 基础识别技术
采用高效的单模及多模关键字匹配算法,支持多种模式的关键字匹配场景:
1)支持各种字符集编码数据的关键字匹配;
2)支持单个或者多个关键字匹配;
3)支持带’*’和’?’通配符的关键字匹配;
4)支持不区分大小写匹配;
5)支持邻近关键字匹配,通过定义某一跨度范围内的关键字对等,达到减少误报;
6)支持关键字词典匹配,通过对词典中的各个关键字赋予不同的权重值(可以是正值和负值),将各个关键字匹配次数乘以权重值的总和与阈值做计较,作为是否触发策略的依据。
2.4.1.1 正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个字符串是否含有某种子串、将匹配的子串替换或者从某个字符串中取出符合某个条件的子串等。
敏感数据往往具有一些特征,表现为一些特定字符及这些特定字符的组合,这可以用正则表达式来标识与识别。
支持PCRE等常见语法规则的正则表达式。
2.4.1.2 数据标识符
基于国家和行业对一些敏感数据(如:身份证号、银行卡号等)所提供的标准校验机制,来识别和判断敏感数据的真实性与可用性,这些数据标识符具有特定用处、特定格式、特定校验方式。
2.4.1.3 自定义脚本
对于一些数据标识符的匹配能力满足不了的敏感数据,用户可以基于敏感数据的特点,按照自定义脚本的模板自行设置校验规则,比如保险单号等。
2.4.2 指纹识别技术
2.4.2.1 结构化数据指纹
结构化数据指纹算法,将待检测的数据与数据库中的表、CSV或者Excel等结构化存储的数据源之间进行精确匹配,判断其是否通过全部拷贝、部分拷贝、或乱序拷贝将敏感信息从数据源泄漏出去,从而给企业造成严重的经济损失。
算法原理:
1)给定任意结构化数据源T,其中T包含C列字段,R行记录。C中每列的数据类型具有普遍代表性,可能是数字、日期,也可能是文字,但不存在二进制数据类型。给定任意一篇含有文本内容的待检测文件D,如何快速高效判断出D中是否包含了T中任意r(r <= R)行中任意c(c <= C)列的内容。
2)对给定结构化数据源T中指定列下的各行数据生成指纹特征库,并以此指纹特征库来判断待检文件D中是否存在于T中特定列相匹配的数据。
如下图3所示,是结构化数据指纹索引结构图。
如下图4所示,是结构化数据指纹匹配结果示例图。当邮件里同时出现员工姓名、编号、工资时,已包含敏感信息,需要拦截。
2.4.2.2 非结构化数据指纹
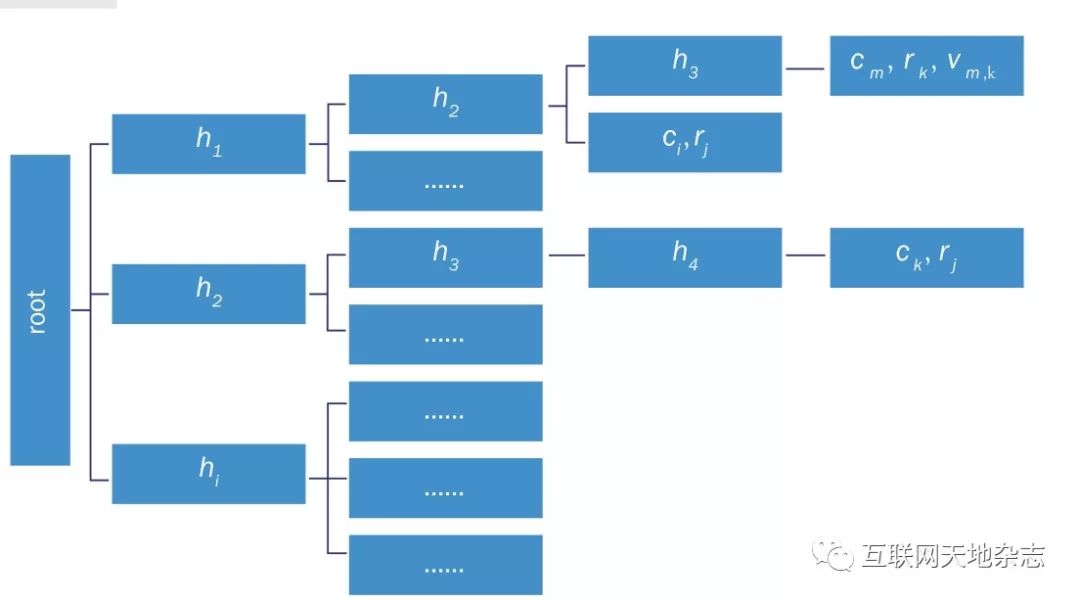
图3 结构化数据指纹索引结构图
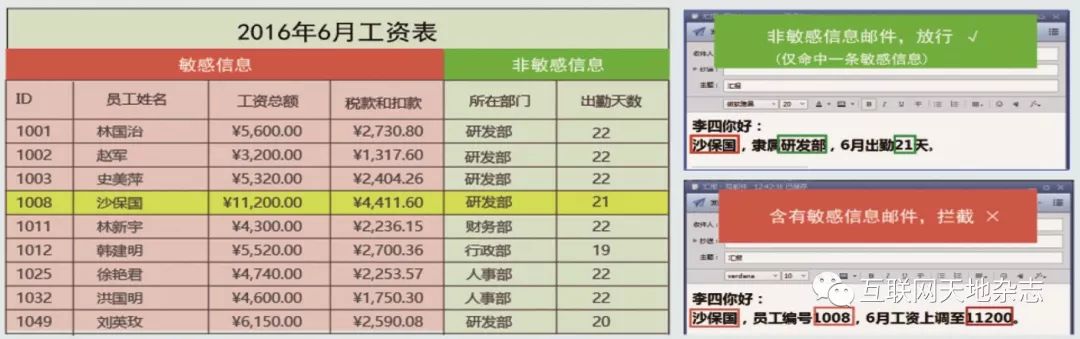
图4 结构化数据指纹匹配结果示例图

大部分敏感数据都存储在非结构化文档中,如项目设计文档、源代码、工程图纸、宏观经济报告、金融报告等。这些敏感信息都是企业的重要资产信息,需要防止这些文档通过全部拷贝、部分拷贝、或乱序拷贝被泄漏出去,给企业造成严重的经济损失。
算法原理:非结构化数据指纹是通过某种选取策略对文本块进行hash生成的,而特定的指纹序列可以用来表示文档的内容特征。进行匹配时,通过对待匹配数据提取出的指纹特征与指纹库中的指纹进行比较可以计算出文档之间的相似度,从而识别出是否有敏感文档被泄漏。
优点:
1) 当包含的敏感信息大于检测长度时,能准确检测到该敏感信息。
2)提取指纹算法应具有伸缩性,对于不同大小的文档应该提取不同数目的指纹。
3)提取指纹算法应该不依赖于指纹在文本中的全局位置(即位置无关性)。
非结构化数据指纹的生成过程如下图5所示。
进一步细化的处理过程如下图6所示。
经过非结构化数据指纹找出的论文抄袭图示如下图7所示。
2.4.2.3 图像指纹
图像指纹匹配:将待检测的图像,提取轮廓特征后,与储存的样本图像特征进行相似度匹配,并判断其是否源自样本图像库,如下图8所示。
技术要点:利用图像处理技术提取图像的轮廓特征,并对特征进行矢量化编码;使用相似度匹配技术对特征库进行查询匹配。即使图像被缩放、部分裁剪、添加水印、改变明亮度,也能够很好的匹配。
图像指纹识别步骤(以头像选择为例):
1)计算一组特点图像的图像指纹,然后将这些图像指纹存入数据库中
2)当用户上传一个新的客户资料中的头像时,将其与数据库中的图像指纹进行对比。如果发现数据库中任意一个头像指纹与该用户上传的图像符合,管理员将会阻止用户上传该图像作为自己的头像。
3)依次类推,识别出色情图片,根据色情图片的指纹创建一个收集色情图片指纹的数据库,用来防止用户上传色情图片。
2.4.2.4 二进制数据指纹
针对可执行文件、动态库文件等没法提取出内容的数据,通过MD5生成摘要,即“二进制数字指纹”。针对一组恶意可执行文件、动态库文件等,计算出其二进制数据指纹,形成二进制数据指纹库,当发现有可疑的可执行文件、动态库文件等时,计算出其二进制数据指纹,与已有的二进制数据指纹库进行比对,判断是否为恶意可执行文件、动态库文件等。
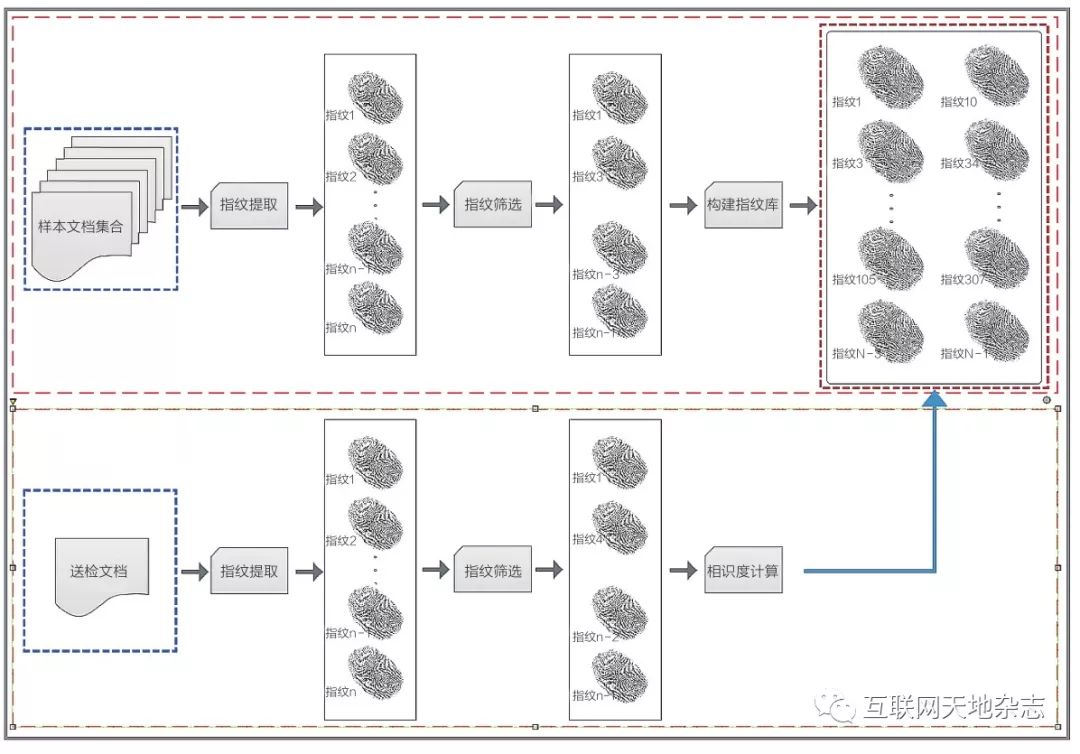
图5 非结构化数据指纹生成过程示意图
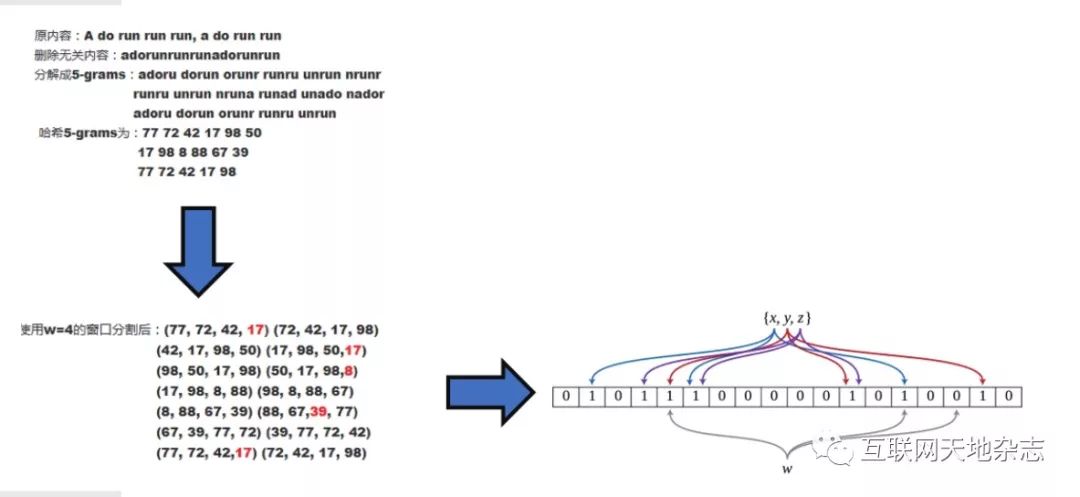
图6 非结构化数据指纹处理过程示意图

图7 经非结构化数据指纹找出的论文抄袭图示
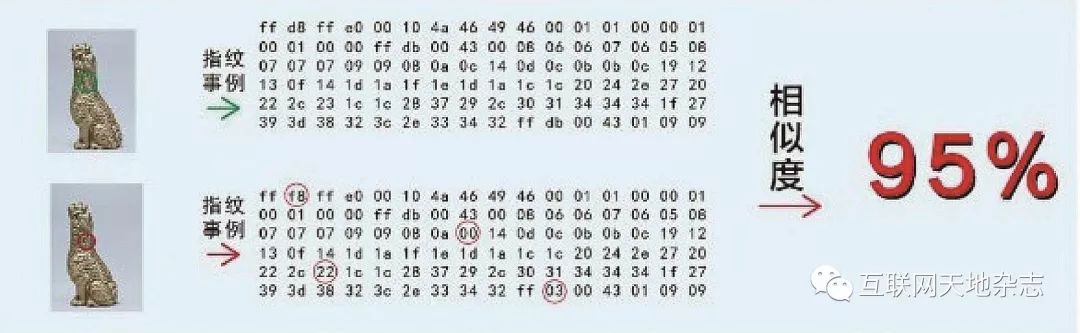
图8 图像指纹示例
2.4.3 智能学习技术
2.4.3.1 机器学习
机器学习算法是可以从数据中学习并从中改进的算法,无需人工干预。学习任务可能包括将输入映射到输出,在未标记的数据中学习隐藏的结构,或者“基于实例的学习”,其中通过将新实例与来自存储在存储器中的训练数据的实例进行比较来为新实例生成类标签。
有三种机器学习算法:
1)监督学习:
监督学习可以理解为:使用标记的训练数据来学习从输入变量(X)到输出变量(Y)的映射函数。
Y = f(X)
监督学习问题可以有两种类型:
分类:预测输出变量处于类别形式的给定样本的结果。例如男性和女性,病态和健康等标签。
回归:预测给定样本的输出变量的实值结果。例子包括表示降雨量和人的身高的实值标签。
线性回归、Logistic回归、CART、朴素贝叶斯、KNN都是监督学习。

目前机器学习带来的经济价值全部来自监督学习。
2)无监督学习:
无监督学习问题只有输入变量(X),但没有相应的输出变量。它使用无标签的训练数据来模拟数据的基本结构。
无监督学习问题可以有三种类型:
●关联:发现数据集合中的相关数据共现的概率。它广泛用于市场篮子分析。例如:如果顾客购买面包,他有80%的可能购买鸡蛋。
●群集:对样本进行分组,使得同一个群集内的对象彼此之间的关系比另一个群集中的对象更为相似。
●维度降低:维度降低意味着减少数据集的变量数量,同时确保重要的信息仍然传达。可以使用特征提取方法和特征选择方法来完成维度降低。特征选择选择原始变量的一个子集。特征提取执行从高维空间到低维空间的数据转换。例如:PCA算法是一种特征提取方法。
Apriori、K-means、PCA是无监督学习的例子。
3)强化学习:
强化学习是一种机器学习算法,它允许代理根据当前状态决定最佳的下一个动作。
强化算法通常通过反复试验来学习最佳行为。它们通常用于机器人的训练,机器人可以通过在碰到障碍物后接收负面反馈来学习避免碰撞。
2.4.3.2 深度语义分析
深度语义分析技术是通过自然语言处理(NLP),结合语义分析模型进行语义分析。自然语言处理是语义分析的基础,主要包括分词、词性标注、关键短语提取、文本自动摘要等一系列的方法,结合词向量分析、主题模型、深度神经网络以及文本分类等技术来实现深度语义分析。如下图9所示,是深度语义分析图示。
2.4.3.3 关键字自动抽取
关键词是表达文档主题意义的最小单位。关键词自动抽取技术则是一种识别有意义且具有代表性片段或词汇(即关键词)的自动化技术。关键词自动抽取在文本挖掘领域被称为关键词抽取,信息检索领域则通常被称为自动标引。随着研究的不断深入,越来越多的方法都运用到了关键词自动抽取之中,如概率统计、机器学习、语义分析等。
2.4.3.4 文档自动摘要
文档自动摘要是利用计算机按照某类应用自动地将文本或文本集合转换成简短摘要的一种信息压缩技术。
文档摘要分类如下图10所示。
三种文档摘要方法:
●抽取式摘要:直接从原文中抽取已有的句子组成摘要
●压缩式摘要:抽取并简化原文中的重要句子构成文摘
●理解式摘要:改写或重新组织原文内容形成最终文摘
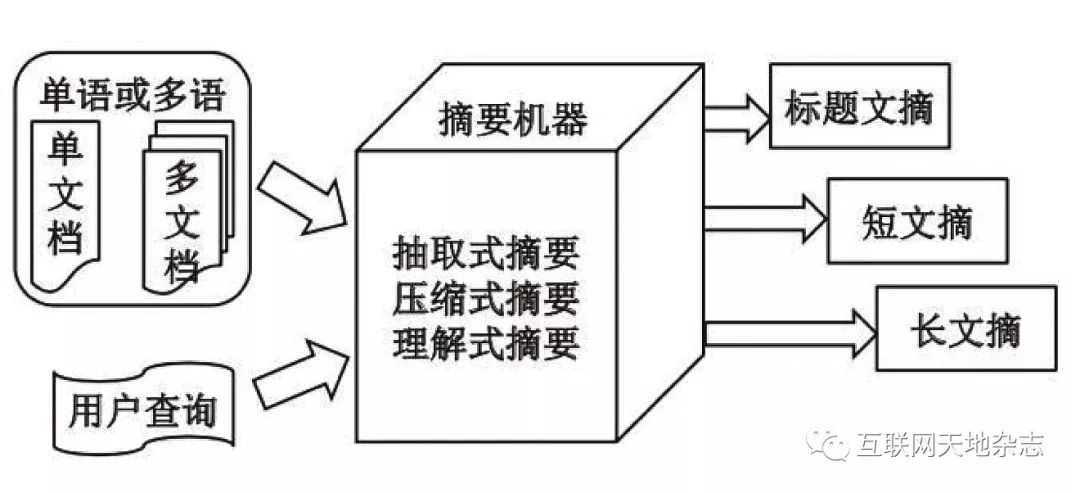
图10 文档摘要分类图示

图11 OCR光学字符识别示例
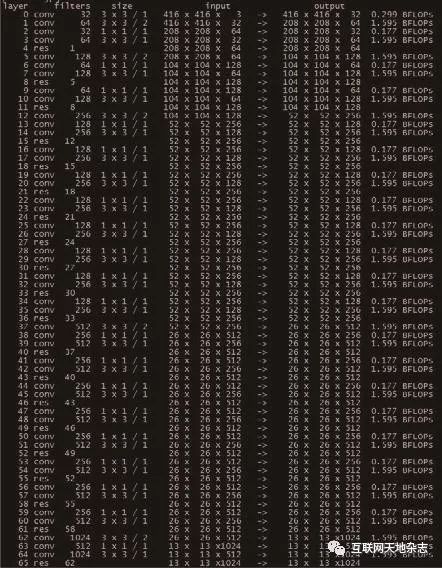
图12 CNN神经网络模型结构图

图13 红头文件检测示例
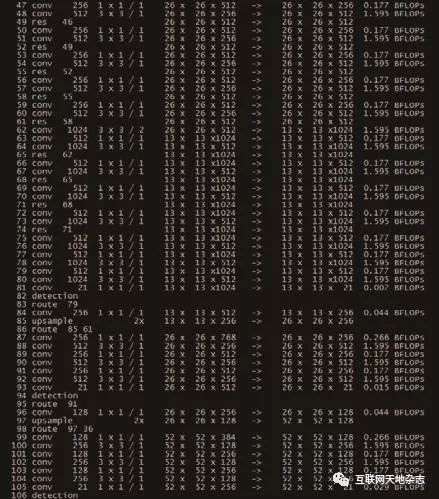
图14 CNN神经网络模型结构图

图15 低质量图片多图章目标检测示例
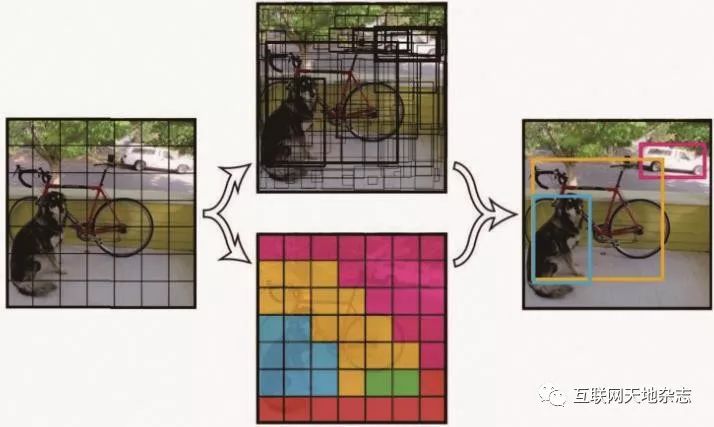
图16 目标检测算法过程图

图17 目标检测算法结果图
2.4.4 图像识别技术
2.4.4.1 OCR光学字符识别
系统集成了业内领先的图像识别系统,能够识别并提取各类图形文件中的文本数据,现阶段被重点应用于公章、红头公文等数据的识别。支持的图像文件格式包括:JPEG/JPEG2000/GIF/BMP/PCX/PNG/TIFF等,如下图11所示。
2.4.4.2 公章与红头文件识别
●图章、红头文件检测
模型选择yolov3,模型结构如下图12、13、14、15所示,网络结构比之一般CNN加入了大量的shortcut以应对在深层网络中浅层特征消失的问题,同时模型基于三组大小不同的mask构建了三个输出层,使得模型可以检测的目标大小更为多样。
●目标检测
图章及公文的识别是基于经典的目标检测算法YOLO v3。
YOLO算法采用卷积神经网络结构进行图像分类。
YOLO算法的中心思想是将输入的图像归一化后分成S x S个格子,若某物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。每个格子预测B个bounding box及其置信度,以及C个类别概率。bounding box信息(x, y, w, h)为物体的中心位置相对格子位置的偏移及宽度和高度。置信度反映是否包含物体以及包含物体情况下位置的准确性,如下图16、17所示。
2.4.4.3 拍照和截图水印识别
选取待识别图像的所有水印候选区域,通过深度卷积神经网络分类器对每个水印候选区域进行水印识别,判断待识别图像是否为带水印图像,实现带水印图像的识别。
2.5 敏感数据分布
2.5.1 敏感数据分级、分类
对所有检测出的敏感数据,根据之前数据分级分类方法进行级别和类别的归类。
2.5.2 敏感数据地图
根据敏感数据的不同级别、不同类别,以检测范围内的地图(根据检测范围不同,地图可能是地图,也可能是企业的网络图等)方式可视化展示敏感数据的分布情况。
2.6 总结
本文从数据梳理分级分类、数据采集、数据预处理、敏感数据识别、敏感数据分布几个方面,阐述了一种高效全面的敏感数据分布自动化探查方法。该方法利用已有的资产探查管理系统和4A系统自动化采集数据;采用包括基础识别技术、指纹识别技术、智能学习技术和图像识别技术在内的多种识别算法识别敏感数据;然后根据敏感数据的分级和分类,以敏感数据地图的方式可视化展示敏感数据分布。
原文刊载于《互联网天地》2019年5期,作者:鲁彪、王自亮、温晓、王勇,单位:中国移动通信集团山东有限公司
声明:本文来自互联网天地杂志,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
