当前个人信息塑造了个人的虚拟形象,更有着显著的财产和资源属性,在个人隐私、财产利益、信息安全、经济发展等诸多方面都产生了深刻的影响,因此保护个人信息至关重要。2017年6月1日,《中华人民共和国网络安全法》正式施行,其中第四十一条明确规定“网络运营者不得收集与其提供的服务无关的个人信息,不得违反法律、行政法规的规定和双方的约定收集、使用个人信息,并应当依照法律、行政法规的规定和与用户的约定,处理其保存的个人信息”。明确了保护个人信息在我国的法律地位。那么如何在保护个人信息安全的情况下,提高企业的生产效率,不仅关系到客户的切身利益和安全,也关系到企业的未来和发展。
本文主要对个人信息去标识化进行简要介绍,内容包括:1)定义;2)去标识化过程;3)去标识化技术;4)去标识化与匿名化的区别;5)去标识化与脱敏的区别。
(一)定义
去标识化(de-identification),有时也称为“去标识化过程(de-identification process)”是指去除一组识别属性(identifying attribute)与数据主体(data principal)之间关联的过程。
个人信息去标识化(personal information de-identification ),是指通过对个人信息的技术处理,使其在不借助额外信息的情况下,无法识别个人信息主体(subject)的过程。个人信息去标识化的核心是利用技术手段,断开和个人信息主体的关联。
(二)去标识化过程
去标识化过程通常分为四个步骤,分别是确定目标、识别标识、处理标识和验证批准,而监控审查则贯穿于整个过程,如下图所示:
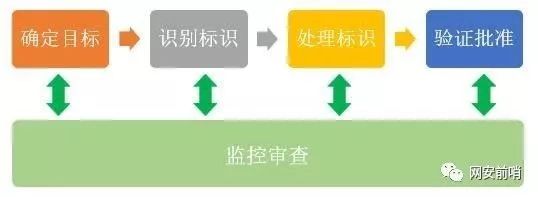
步骤1:确定目标
确定目标是前提,主要包括确定个人信息去标识化的对象、设定目标和制定计划。确定个人信息去标识化对象的核心任务是确定个人信息的范围,最好根据法律法规、组织要求、业务需求、和数据用途等要素确定哪些个人信息属于去标识化的对象;设定目标应考虑个人信息重标识风险与个人信息有效性之间的平衡,且设定各自的阈值;制定计划包括去标识化的目的、对象、操作人员、实施方案和进度安排等。
步骤2:识别标识
识别标识是基础,包括查表识别法、规则判定法和人工分析法。查表识别法指预先建立个人信息的元数据表格,将待识别个人信息的各个属性名称或字段名称,逐个与个人信息元数据表中记录进行对比;规则判定法是指通过建立自动化程序,分析个人信息规律,从中自动发现需要去标识化的标识符;人工分析法是通过人工发现和确定需要去标识化的标识符。
步骤3:处理标识
处理标识是核心,分为预处理、选择模型技术、实施去标识化三个阶段。预处理是在对个人信息正式实施去标识化前的准备过程。预处理是对个人信息进行变化,使其有利于后期进行处理;选择模型技术主要是根据个人信息类型和业务特性选择去标识化的技术;实施去标识化是根据已选择的去标识化技术,对个人信息进行操作。
步骤4:验证审批
验证审批是保障,个人信息去标识化后需进行验证,以确保生成的个人信息在重标识风险和数据有用性方面都符合确定目标阶段的阈值。在验证满足目标过程中,需要对个人信息去标识化后重标识风险进行评估,并与预期可接受风险阈值进行比较,如果超出风险阈值,需继续进行调整直到满足要求。
通用步骤:监控审查
监控审计是关键,是监控审查应渗透到去标识化过程的每个阶段,对去标识化处理过程相应的操作行为进行监控,操作日志进行记录,同时应对每一阶段去标识化的效果要持续监控,以达到预期目标。
(三)去标识化技术
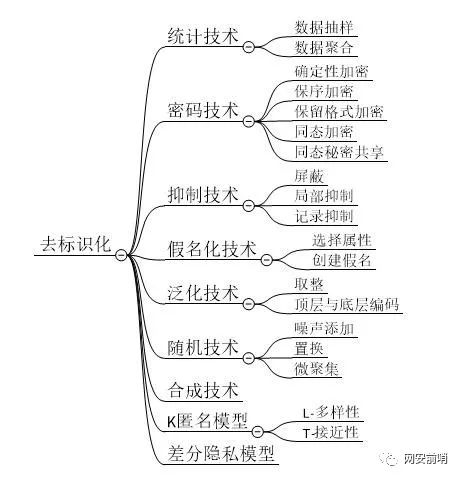
去识别技术(de-identification technique)是一种用于变换数据集的方法,其目的是减少数据与特定数据主体相关联的程度。目前常用的去标识化技术主要有:统计技术(Statistical tools)、密码技术(Cryptographic tools)、抑制技术(Suppression techniques)、假名化技术(Pseudonymization techniques)、泛化技术(Generalization techniques)、随机技术(Randomization techniques)、合成技术(Synthetic data)、K匿名模型(K-anonymity model)和差分隐私模型(Differential privacy model)。每种技术下面又包含不同的方法,具体如下图所示:
(四)去标识化与匿名化的区别
匿名化(anonymization),是指个人信息不可复原的处理过程,处理之后个人信息控制者不能直接或间接的再次识别个人信息。去标识化和匿名化都是个人隐私安全的技术防护手段,主要区别是去标识化后的信息也属于个人信息,如果与其他额外信息结合,可以识别个人信息主体,通常也称为重标识(re-identification);匿名化后的信息不属于个人信息,且无法与额外信息结合识别出个人信息主体。
(五)去标识化与脱敏的区别
脱敏(desensitization)这个词最早出现在医学用语,是用于治疗特定过敏原所致I型超敏反应的方法,而信息安全中的脱敏(redaction)来源于ISO/IEC 27038 Information technology -- Security techniques -- Specification for digital redaction(信息技术安全技术 数字化修订详述),译为永久去除文档中的信息。通常所说的数据脱敏(data redaction),是指对某些敏感信息通过脱敏规则进行变形,实现敏感隐私数据的可靠保护。
目前业界对信息安全中的去标识化和脱敏没有明显的区分,他们的核心都是通过技术手段对标识信息或敏感数据进行处理,实现对敏感信息数据的保护。通常脱敏的范围则更大,某种意义上包含去标识化,去标识化是隐私安全的技术手段,脱敏是数据安全的技术手段,而隐私安全是在数据安全基础之上对个人敏感信息的安全防护。去标识化作用的对象主要是标识信息,脱敏作用的对象主要是敏感数据,一般而言,个人信息说去标识化,不说脱敏。
参考文献
[1]. 《信息安全技术 个人信息安全规范》(GB/T 35273-2017)
[2]. 《信息安全技术 个人信息去标识化指南指南》(征求意见稿)
[3]. ISO/IEC 20889: 2018 Privacy enhancing data de-identification terminology and classification of techniques. Part 3: Terms and definitions.
[4]. ISO/IEC 27038 Information technology -- Security techniques -- Specification for digital redaction. Part 2: Terms and definitions.
[5]. ISO/IEC 29100 Information technology -- Security techniques –Privacy framework. Part 2: Terms and definitions.
张旭刚,5年信息安全工作经验,目前专注并擅长电子银行安全评估、网络安全等级保护、个人信息保护咨询等方向,主导及参与了30多家国有银行、全国股份制银行、城商行、外资银行、民营银行的信息安全咨询和评估项目,在银行业信息科技风险、个人信息保护咨询、金融行业等级保护等领域有着丰富的实践经验。在国家级期刊发表论文2篇,出版金融行业信息安全相关专著1本,参与制定金融行业信息安全标准1项.
作者邮箱:zhangxugang@cfca.com.cn,欢迎大家提出宝贵建议。
声明:本文来自网安前哨,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
