文章导读:此报告从数据隐私保护的变革出发,探讨人工智能时代数据使用面临的新规则和新挑战,分析数据隐私安全保护问题,提出数据安全多方机器学习的解决方案——联邦学习,聚焦其概念、分类、研究现状和可应用领域,总结了当前国内知名企业对于联邦学习的研究进展,分析联邦学习的未来发展趋势,为联邦学习在各行业研究发展提供参考。

作者:王健宗,平安科技联邦学习技术部总经理,深圳市金融智能机器人研究中心常务副主任,中国人工智能开源软件发展联盟副理事长,平安科技副总工程师,资深人工智能总监,平安深度学习平台和AutoML平台总设计师,美国佛罗里达大学人工智能博士后,深圳市领军人才,高级工程师。现任中国计算机学会大数据专家委员会委员、高级会员、YOCSEF深圳副主席,曾任美国莱斯大学电子与计算机工程系研究员,专注于联邦学习和人工智能在金融、保险、投资、医疗等领域的研发工作,发表深度学习、云计算、大数据等领域国际论文30余篇,以及专利100多项。多届国内知名大数据人工智能和联邦学习会议出品人。
一、数据隐私保护的新规则
随着信息时代算力的不断增加,人工智能的广泛应用,人类进入了第四次工业革命——智能革命。随着信息技术的快速发展,硬件设备和数据的广泛利用为人工智能发展提供了广阔的应用空间和广泛的应用条件。在利用数据进行机器学习建模的环境中,企业和个人具备了过往无法比拟的计算能力和数据应用优势。每个企业都拥有敏感数据:商业秘密、知识产权、关键业务信息、业务合作伙伴信息和客户信息。企业根据公司政策、法规要求和行业标准保护所有此类数据,这些数据带来巨大价值的同时,也存在传输储存方面符合法律法规,进行安全和隐私保护方面的难题。从2014年以来,数据泄漏问题开始得到公众关注,每年都有大量数据隐私泄露事件发生,数据使用的合法性和使用界限开始成为各行业关心的问题。
2018年5月25日,欧盟正式生效《通用数据保护条例》(General Data Protection Regulation,GDPR)。作为欧盟最严格的数据保护条例,该法规要求处理个人数据的组织经营者用清晰明确的语言描述用户协议,允许用户执行数据被遗忘的权利,用户可以要求经营者删除其个人数据并停止利用其数据进行建模。该法规强调机器学习模型必须具有可解释性,随之一系列公司由于对数据的使用不符合法律规范成为法案下第一批被告者。2019年4月,《互联网个人信息安全保护指南》正式发布。对于个人信息的共享和转让行为进行了明确规定。进一步加强了个人信息安全保护措施。2019年5月,国家互联网信息办公室会同相关部门研究起草了《数据安全管理办法(征求意见稿)》,旨在加强对数据处理使用和数据安全监督管理的要求。包括“应明确数据安全要求和责任,督促监督第三方应用运营者加强数据安全管理。第三方应用发生数据安全事件对用户造成损失的,网络运营者应当承担部分或全部责任,除非网络运营者能够证明无过错。”等数据安全管理办法,对于数据的安全使用和隐私保护提出明确意见和要求。2017年起实施的《中华人民共和国网络安全法》和《中华人民共和国民法总则》也要求:“网络运营者不得泄露、篡改、毁坏其收集的个人信息,并且与第三方进行数据交易时需确保拟定的合同明确约定拟交易数据的范围和数据保护义务。” 明确指出对于用户数据的收集必须公开、透明。企业、机构在没有用户授权的情况下,不能私自交换数据。法律条例对于人工智能传统的数据处理建模模式形成了极大挑战。在一个需要互联共享的信息共享环境下,如何在符合法律法规的用户数据隐私安全条件下,进行多方数据资源的利用,成为了各企业利用数据时中面临的重要问题。
二、人工智能时代面临的新挑战
人工智能领域,往往需要足量数据进行机器学习来产生良好的建模效果。《AI.未来》中的观点认为:“当电脑的运算能力和工程师的能力达到一定的门槛水准之后,数据量的多寡就成为决定算法整体效能与精准度的关键所在。”能否掌握足量优质的数据,决定了人工智能训练效果的优劣。在实际工业环境中,仅仅一家企业难以只利用自身数据推测用户多元化多平台的消费习惯。为了更精准的做出决策,需要充分利用信息资源。市场开始要求大规模数据平台使用多种情况下的最佳训练效果。然而许多企业训练方拥有的数据量不足,规模与质量不完备。数据来源不够,导致机器学习系统效果不理想。
不同的网站、研究者、广告商和商业机构想要将彼此的数据汇总或者统一整理进行训练,传统的处理模式之一是将不同源数据整合,形成聚合数据库,虽然聚合数据库能实现对多个独立的数据库进行相互操作,但过程中存在各单元数据库的交互过程,面临着交互过程中的安全风险,无法保证隐私安全的后果。另外,实际情况下,数据源往往分布在企业和个人,相互独立隔阂,形成了一个个阻碍技术发展的“数据孤岛”。多方数据间无法联通带来更多行业效益。当前避免集中式存储数据,并可以从多源不互通的数据中创造新的价值。在保护隐私安全条件下,利用多方数据资源来驱动机器学习优化,成为了当前亟待解决的新挑战。正是由于这些严格的法规以及行业本身发展面临的障碍,人工智能技术反而可以用新技术找到其升级发展的契机。在满足数据隐私、安全和监管要求的前提下,设计一个机器学习框架,让人工智能系统能够更加高效、准确地共同使用各自的数据,这将成为人工智能安全保护时代的新机遇。
三、数据安全新曙光——联邦学习
1. 联邦学习的概念
解决上述挑战,满足隐私保护和信息安全的联邦学习技术可以成为解决方案。联邦学习是隐私保护下的算法优化可实现路径和保护数据安全的“数据孤岛问题”的解决方案。联邦学习允许从跨数据所有者分布的数据中构建集合模型,提供了跨企业的数据使用方式和模型构建蓝图,适用于B2B和B2C等业务,可被广泛应用于各种领域,实现各个企业的自有数据不出本地,只通过加密机制下的参数交换,不违反数据隐私法规地建立优化机器学习模型。在保护数据隐私安全,合法合规要求前提下,达成机器学习效果的强化,将人工智能重点从以AI基础算法为中心转移到以保障安全隐私的大数据架构为中心。
2016年,Google AI研究人员首次提出用于训练深度学习网络的联邦学习。谷歌尝试建立数百万安卓设备之间的联邦模型,用于移动设备分散数据训练,解决隐私保护问题。2019年2月,Google发布实现了全球首个产品级的超大规模移动端分布式机器学习系统,能够在数千万部手机的安卓键盘上运行联邦学习算法,谷歌的研究主要侧重于在移动终端上运行的联合平均算法。
多个数据拥有方想要共同训练模型,传统做法是将数据整合到一方进行训练,但是这样无法保证数据隐私和传输过程的安全性。相对于以往的分布式机器学习方式,联邦学习具有以下特征:数据不脱离本地;参与者利用自身拥有的数据训练全局模型;每个参与方都参与学习过程;模型损失可控;训练过程中考虑隐私和安全。参与各方能够在不披露底层数据和底层数据的加密形态的前提下共建模型,使联邦学习成为未来安全多方机器学习的新曙光。
2. 联邦学习的分类
2.1 从联合方式分类
联合方式上,可以将联邦学习分为单方和多方两种方式。单方联邦学习是指从一个实体进行分布式内容抓取和系统管理。模型以联合的方式训练在所有客户端设备中具有相同结构的数据上。大多数情况下每个数据点对于设备或用户唯一。例如,应用程序通过单方联邦学习为个人用户推荐音乐的推荐引擎。多方联邦学习则需要两个或多个组织或特许经营商组成联盟。在其各自的数据集上训练共享模型。例如,多家银行可以培训一种通用的强大欺诈检测模型,而无需相互分享敏感的客户数据。
2.2 从用户和用户特征结构分类
参与各方的数据结构和参数通常相似但不必相同,根据不同的数据的特征分布形式,如同数据库原理中的数据特征分布状态,联邦学习又分为三种不同处理方式:横向、纵向和迁移。参与方们的数据集具有高度重叠的特征维度,样本重叠较小时,称为横向联邦学习。参与方们的数据集具有高度重叠的样本纬度,特征维度重叠较小时,使用方法称为纵向联邦学习。如果参与方们数据集在样本和特征维度上都没有足够的重叠,则使用联邦迁移学习。
3. 隐私保护下的技术工具
参与方们在参与联邦学习的过程中需要使用工具来进行数据的隐私保护。联邦学习的主要的工具包括安全多方计算,同态加密,私密共享和差分隐私。参与方们可以利用安全多方计算保证信息层面的数据安全。安全多方计算成本较高,为降低数据传输成本,参与方们可能需要在降低对数据安全的要求来提高训练的效率。
同态加密能够对所有数据进行加密处理,参与方们接收到的是密文,使攻击者无法推理出原始数据信息,保障数据层面的安全。在实际应用中,为了提高计算效率,参与方们一般采用半同态加密,半同态加密可以使用加法和乘法进行同态加密。
差分隐私可以用于参与方本地数据信息安全的保护,通过在参与方各自的原始数据上不断加噪音来减弱任意一方数据对于整体数据的影响。其缺点在于牺牲训练效果,过多的噪音会降低模型训练的效果,参与方们在使用差分隐私时需要在数据安全和准确度上进行取舍。
四、联邦学习的现状和发展
1.联邦学习的框架和标准化制定
联邦学习的技术框架建设方面。谷歌首先提出开源的离散数据联邦学习应用框架TensorFlow Federated (TFF)。TensorFlow Federated主要支持利用如今数量众多的移动智能终端设备和边缘端计算设备的计算能力,保证数据不离开本地的同时训练本地机器学习模型,通过Google开发的Federated Averaging 算法,即使在较差的通信环境下,也能实现保密、高效、高质量的模型汇总和迭代流程,且移动端和边缘端用户体验上不做任何牺牲和妥协。目前Google已经将联邦学习应用在移动设备键盘输入预测上。
在学术研究与行业应用上,腾讯发起的中国首家互联网银行——微众银行正在积极探索。在国际人工智能专家、微众银行首席人工智能官杨强教授带领下的AI 团队开源了首个联邦学习“FATE(FederatedAI Technology Enabler)” 工业框架,作为安全计算框架支持联合AI生态系统,该框架可以实现基于同态加密和多方计算的安全计算协议,在信贷风控、客户权益定价、监管科技等领域推出了相应的商用方案。微众银行与瑞士再保险公司达成合作,共同研究“联邦学习”在再保险领域的应用。在杨强教授担任标准制定工作组主席的带领下,微众银行发起“IEEE联邦学习标准项目”,成为国际上首个针对人工智能协同技术框架订立标准的项目,旨在共同制定联邦学习标准形式的具体形式和内容,达成行业合作,共同推动联邦学习在各行业领域的进一步发展。
目前,联邦学习的国际标准化工作正在进行,随着 6月15日IEEE联邦学习基础架构与应用标准工作组的第二次会议在美国洛杉矶的召开。海内外13家来自科技、金融、教育、医疗等不同行业的知名研究机构及企业从多角度探讨联邦学习技术的应用案例,对联邦学习标准草案的制定提出建设性意见,该标准草案预计在一年内出台,意味着将为立法和监管提供更多技术依据。
2.国内联邦学习平台产业化建设
联邦学习技术作为机器学习和数据结合的推动者,将推动各行业人工智能技术平台的应用发展,目前各企业已经开始在业务方面开展联邦学习在产业方面的技术平台建设工作。
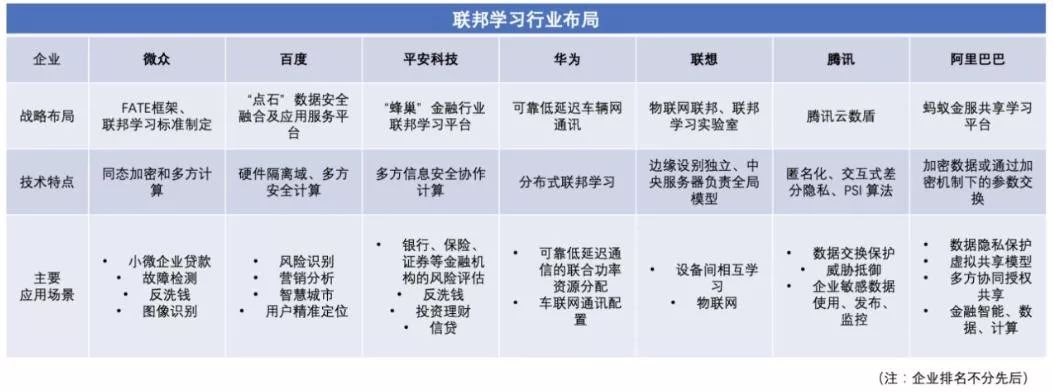
百度基于数据本地和云端隔离技术,采用安全数据融合以及多方联邦学习技术,推出“点石”数据安全融合及应用服务平台。提供安全数据集合、灵活建模、快速服务部署等服务,基于硬件隔离域、多方安全计算的技术能力,支持多场景的数据安全计算。“点石”利用安全方案解决数据打通难与应用成本高等问题。提供减少企业损失的风险识别,帮助企业有效识别在信用卡、贷款、在线支付等场景中的违约、欺诈等潜在风险,帮助企业对销售线索进行甄别与拓展,优化企业营销策略。“点石”的联邦学习应用场景主要是风险识别和营销分析。该平台与清华大学达成合作,利用联邦学习对接政府客户,帮助智慧城市建设。在风控模型建立方面,与狮桥公司合作,协同客户本地训练,结合大数据联合建模平台进行数据融合与分析建模。
金融应用领域方面,平安集团的高科技内核——平安科技公司正在研发建立全球首个面向金融行业的联邦学习平台“蜂巢”。平安科技利用联邦学习技术,设计面向数据强监管的金融业多态多任务学习模型。“蜂巢”能够应用于多方信息的安全协作计算,满足银行和金融机构的风险评估、反洗钱、投顾、投研、信贷、保险和监管等多场景应用需求。减少人力成本和打通数据的成本,提高数据使用在机器学习过程中的转化率。平安科技将推动学界和工业界的积极探索,携手金融行业共同建立“联邦学习+互联网+监督”的联邦大数据平台,打破金融行业孤岛,联合各企业以及政府机构,进一步推动联邦学习在金融产业的快速发展。
3.联邦学习与物联网的融合
物联网(IoT)生态环境中,联邦学习可以用于人工智能模型的分散训练。目前国内多家企业正在致力于研发联邦学习在物联网领域的应用解决方案。
在通信分配应用方面,华为数字算法实验室利用联邦学习原理解决车联网中可靠低延迟通信的联合功率和资源分配问题,在概率排队延迟方面最小化车辆用户的网络功耗。利用联邦学习技术,华为数字算法实验室提出了一种分布式学习机制,车辆用户在道路单位的帮助下能够在本地学习网络范围队列,而不实时共享队列长度估计尾部分布。这种方法能高精度判断学习网络中的车联网队列分布,减少车载队列长度,优化资源配置。
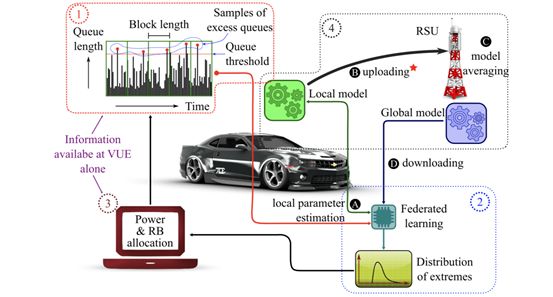
车辆用户和道路单位间利用联邦学习进行模型交换
(图源:Distributed Federated Learningfor Ultra-Reliable Low-Latency Vehicular Communications)
联想在去中心化人工智能和联邦学习的实际应用场景上,专注与硬件技术的结合,从各种来源聚合生成本地模型并允许物联网相互学习。每个边缘设备的数据独立用于学习创建本地模型。本地模型聚合将中央服务器转换为全局模型,再分发返回边缘设备,令所有边缘设备都可以从收集和处理的信息中受益,在不同场景下,利用联邦学习使物联网设备或传感器能够相互学习。联想正在与波兰云数据解决方案公司ByteLAKE合作,开展联邦学习和边缘计算环境系统构建。

联邦学习允许物联网各设备间联合学习
(图源:Federated Learning: DecentralizedAI Whitepaper Lenovo,ByteLAKE)
4.对多方安全计算的积极探索
在数据隐私保护的研究应用方面,基于多方安全计算技术,腾讯开展AI创新实践,推出“腾讯云数盾”。数盾以数据安全治理为核心,构建了可用于外部攻击防护、数据交换保护、内部防泄露等全流程的数据安全保护方案,用于帮助企业数据安全建设。数盾通过使用匿名化、差分隐私、安全多方计算架构等方式,在数据使用安全的基础上,平衡隐私保护与数据挖掘价值,符合对于数据使用和共享环境中的合规需求。
阿里巴巴于四年前开始研究共享学习技术,研发蚂蚁金服共享学习平台,主要思想和联邦学习相同,基于数据安全和隐私保护,在多个参与方之间通过共享加密数据或加密机制下的参数交换与优化,进行机器学习,作为虚拟的共享模型的产品平台。蚂蚁金服共享学习平台本着数据共享建模方案不泄露用户隐私且符合数据安全保护的原则实现了数据的多方协同和授权共享,得到更准确高效的模型和决策,进一步释放数据价值。
五、联邦学习的未来
对想要进行联合机器学习的各参与方,联邦学习具有保护隐私和多方本地数据安全的极大优势。避免集中式存储数据,安全合规地从多源不互通的数据中创造新的价值,充分利用各方数据资源,优化机器学习训练结果,学习参与方可以在联合形成协同合作的联邦大数据环境,形成联邦学习生态。联邦学习生态可以视为一个多种数据来源合作产生的,基于联邦学习原理协同规范的,用于联邦学习过程的无共享多方数据集群环境。用户、方案提供商、服务商、运营商以及生态链上游厂商融入到一个大环境,提供优化服务,真正达到联邦学习的资源融合作用。对金融、互联网、通信、零售、交通运输、工业生产等行业提供计算服务支持。我们可以从以下四方面窥探联邦学习的未来。
1. 丰富的数据资源是联邦学习最大的金矿。原本分散在各规模企业的数据,通过联邦学习生态达成,可以发挥其自身作用,有了更好的用武之地。例如在精准营销方面,通过机器学习建模,把顾客群体细分,对每个群体,量体裁衣地采取相应对策。利用整合各方有用资源,构造更好的机器学习效果,以此产生利益价值。利用“联邦学习+人工智能”真正的赋能大数据并反哺个人和企业业务,用数据和科学提升业务效益。
2. 打破传统企业机构的数据边界,利用联邦学习提升智能化效果。改变过去商务智能和政府仅仅依靠机构内部数据的局面。协同各企业机构,达成优化合作,降低各机构间的交易摩擦成本和数据风险,提升机器学习的准确性和更新的及时性。在智慧城市、智慧医疗、智慧金融、企业数据联盟等方面提出新的使用方向。
3. 更了解市场,发现用户需求并将联邦学习产业应用落地。从市场业务挖掘数据使用场景,找出联邦学习在市场环境中的使用场景及应用范围,结合目前个人和机构的使用需求,利用联邦学习环境,提供丰富的资源,强化机器学习效果,辅助加速各产业智能化。
4. 达成各行业联手,共建全行业的联邦学习生态。联邦学习的出现已经开始改变大数据在各行各业的应用方式,联邦大数据生态的构建也离不开学界和工业界的共同探索和推动,使用联邦学习技术的各方应当携手,联合制定数据联邦行业规范,促成多方联邦数据协议,达成标准化、协同化、规范化的联邦学习环境。
在信息流通日益渗透到企业和个人的今天,联邦学习将逐渐成为金融、保险、投资、医疗等众多行业领域实现商业价值和隐私安全保护的最佳途径,其应用将在各行业全面展开,联邦学习的新纪元已经到来。
参考文献
《数据安全管理办法(征求意见稿)》- 中华人民共和国司法部 - 中国政府法制信息网《中华人民共和国网络安全法-中国证监会
《大数据安全白皮书》-中国信息通信研究院安全研究所 2018
TensorFlow Federated: Machine Learning onDecentralized Data. available on: https://www.tensorflow.org/federated
Federated Learning. White Paper V1.0.WeBank, Shenzhen, China. WeBank AI Group
编者评点
本文作者王健宗博士是资深的人工智能专家,主持多项商业领域的人工智能和联邦学习项目开发,特别是在联邦学习领域,其有丰富的实践经验和独到的见解,是国内联邦学习领域的领军人物之一。在本文中,作者专注于人工智能领域遇到得数据隐私保护问题,介绍了联邦学习的发展现状、面临的挑战及未来发展趋势。首先,作者介绍了数据隐私保护所面临的严峻现实问题及各国的应对措施,分析了人工智能时代数据隐私保护所面临的挑战;其次,介绍了联邦学习的概念、分类及其所用到的技术工具;然后,阐述并分析了联邦学习的现状和发展,包括联邦学习的框架和标准化制定、国内联邦学习平台产业化建设、物联网与物联网的融合、对多方安全计算的积极探索;最后,总结了联邦学习的未来。

马学彬 《联数》责任编委 CCF大数据专家委员会通讯委员 内蒙古大学副教授
文章来源:本文系于《联数》首次发表。
投稿和合作请联系邮箱:bigdata@ccf.org.cn
声明:本文来自中国计算机学会大数据专家委,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
