语音识别系统现在不仅可以识别出「你说了什么」,而且可以在多人对话情境中准确识别出「是谁在说话」了。在最近公布的一项研究中,谷歌的最新说话人分类系统(speaker diarization system)将多人语音分类识别的错误率从 20% 降到了 2%,获得了十倍的性能提升。
识别「谁说了什么」,也就是「说话人分类」任务是自动理解人类对话音频的关键步骤。例如,在一个医生与患者的对话中,「患者」在回答医生的问题(「你经常服用心脏病药物吗?」)时说了「Yes」,这和医生用反问的语气说「Yes?」的含义截然不同。
传统的说话人分类(SD)系统分为两步,第一步是检测声谱中的变化,从而确定说话人何时发生切换;第二步是识别对话中的每个说话人。这一基本的多步方法几乎已有 20 多年的历史,而在此期间,只有说话人切换检测得到了提升。
在最新的一项研究中,谷歌公布了他们在说话人分类模型上取得的新进展。他们提出了一种基于 RNN-T 的说话人分类系统,将说话人分类错词率从 20% 降到了 2%,性能提升了十倍。
这一提升得益于 RNN-T 模型的最新进展,它为谷歌的新系统提供了一个适当的架构,能够克服之前说话人分类模型的一些局限。谷歌在一篇名为《Joint Speech Recognition and Speaker Diarization via Sequence Transduction》的论文中展示了这项研究,并将在 2019 年 Interspeech 大会上进行展示。
论文链接:https://arxiv.org/pdf/1907.05337.pdf
传统的说活人分类系统有哪些局限
传统的说话人分类系统依赖人声在声学上的差异来区分对话中的不同说话人。男人和女人的声音比较容易区分,他们的音高(pitch)存在很大差异,使用简单的声学模型就能加以区分,而且可以一步完成,音高相似的说话人则要通过以下几个步骤进行区分:
首先,基于检测到的语音特征,一个变化检测算法将对话均匀地分割成若干片段,希望每个片段只包含一个说话人。
接下来,使用深度学习模型将来自每个说话人的声音片段映射为一个嵌入向量。
在最后一步的聚类过程中,将这些嵌入聚集在一起,以便在一场对话中跟踪同一个说话人。
在实践中,说话人分类系统与自动语音识别(ASR)系统并行,结合两个系统的输出给识别出的词打上标签。
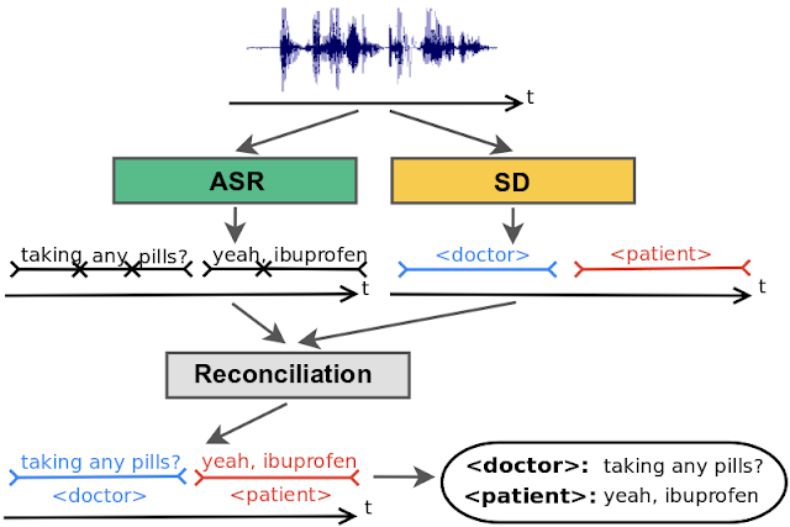
传统的说话人分类系统在声学领域进行说话人标签推理,然后将标签覆盖在由单独的 ASR 系统生成的单词上。
这一方法存在诸多局限,已经阻碍了这一领域的发展。
第一,对话需要被分割成片段,而且每个片段只包含一个人的声音。否则,嵌入就无法准确表征说话人。但在实践中,变化检测算法并不完备,导致分割出的片段包含多个人声;
第二,聚类阶段需要知道说话人的数量,而且这一阶段对输入的准确性非常敏感;
第三,聚类阶段需要在用于估计语音特征的片段大小和所需的模型准确度之间进行艰难的权衡。片段越长,语音特征质量越高,因为模型拥有更多与说话人相关的信息。这就造成模型可能将简短的插入语归入错误的说话人,由此产生非常严重的后果,如在临床、金融语境下,肯定和否定回答都需要被准确追踪;
最后,传统的说话人分类系统没有一个简单的机制来利用在许多自然对话中特别突出的语言线索。例如,「你吃这个药多长时间了?」在临床对话场景中最有可能是医护人员说的。类似地,「我们需要什么时候交作业?」很可能是学生而不是老师说的。语言线索也会为说话人转换提供信号,如在一个问题之后。
为了克服以上缺陷,谷歌一直在致力于改进人声分类系统,如去年 11 月发布的利用监督学习的精确在线说话人分类系统。在那项工作中,RNN 的隐藏状态追踪说话人,克服了聚类阶段的缺陷。本文提出的系统则采用了不同的方法并结合了语言线索。
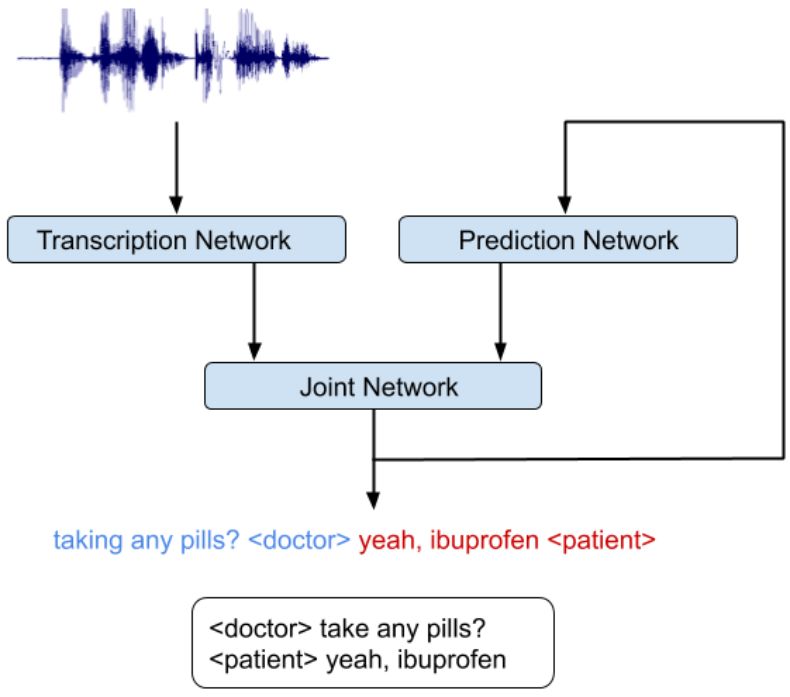
谷歌新系统:集成语音识别和说话人分类
在这项最新发布的工作中,研究者开发出一个简单的新型模型,该模型不仅实现了声音和语言线索的无缝结合,而且将说话人分类和语音识别集成到同一个系统中。相较于同类别单一的识别系统,该集成模型不会大幅度降低语音识别的性能。
研究中最重要的一点是他们认识到 RNN-T 架构非常适用于集成声音和语言线索。RNN-T 模型包含以下三种不同的网络:(1)转录网络(或称编码器),其作用是将声帧映射到一个延迟表征中;(2)预测网络,其作用是基于先前的目标标签预测接下来的目标标签;(3)联合网络,其作用是整合前两个网络的输出,并在该时间步上生成一组输出标签的概率分布。
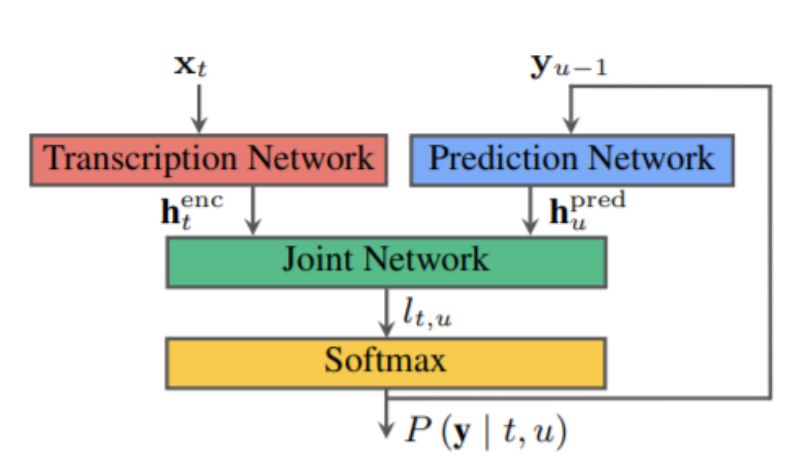
注意,RNN-T 架构中存在一个反馈回路,其中先前识别出的单词作为输入反馈回来,并且 RNN-T 模型能够整合语言线索,如问题的结尾。
这一集成语音识别和说话人分类的系统可以同时推断出谁在什么时候说了什么。由于损失函数的计算需要运行前向-后向算法,包括输入和输出序列的所有可能对齐,所以在 GPU 或 TPU 等加速器上训练 RNN-T 模型并非易事。不过,这一问题最近在前向-后向算法的 TPU 友好型实现中得到了解决,将该问题重新定义为一种矩阵乘法序列。研究者还利用了 TensorFlow 中 RNN-T 损失的一种高效实现,从而使得模型开发能够快速迭代,并且训练了一个非常深的网络。
这一集成模型可以像语音识别系统一样训练。训练参考的数据包括说话人的语音转录以及区分说话人的标签。例如「作业什么时候上交?」<学生>,「我希望你在明天上课前提交,」<老师>。当使用音频和相应的参考转录文本示例训练模型,使用者可以输入更多对话录音并获得类似形式的输出。
谷歌的分析表明,RNN-T 系统的性能提升会影响所有类型的错误率,包括说话人快速转换、断字、语音重叠时错误的说话人识别以及低质音频。此外,与传统系统相比,RNN-T 系统在对话中表现出了相对稳定的性能,每次对话的平均错误率方差显著减小。
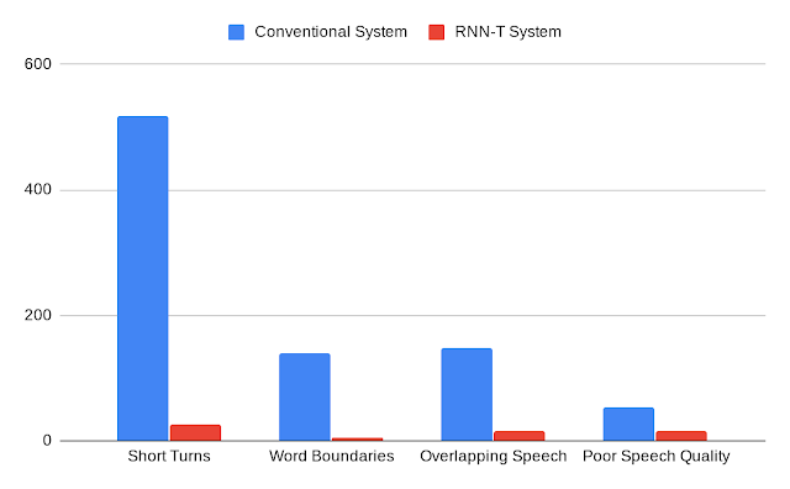
传统系统与 RNN-T 系统的错误率比较,由人类注释评分。
此外,该集成模型可以预测生成更多易阅读的 ASR 转录所需的标签。例如,研究人员已经成功通过匹配训练数据中的标点符号和大写提升了转录的水平。目前的输出较先前的模型错误更少,这些模型都经过单独的训练,并会在 ASR 之后作为后处理步骤加入流程。
该模型现已成为谷歌「理解医疗对话项目」的标准组成部分,并在其他非医疗语音服务中得到了更广泛的应用。
原文链接:https://ai.googleblog.com/2019/08/joint-speech-recognition-and-speaker.html
声明:本文来自机器之心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
