人脸识别是一个历史悠久的模式识别问题,大量研究人员付出了巨大努力,提出了各种方法来不断推动其前进。
本文提纲挈领的介绍了一些经典和最近的方法,希望起到抛砖引玉的作用。未来人脸识别在准确度速度提升、模型轻量化、大规模数据集等方面仍需要更深入的研究。
问题及背景
1、人脸识别流程
人脸识别主要是指利用分析比较人脸视觉特征信息进行身份鉴别的计算机技术。从算法角度讲目前主流的方法包括:人脸检测,特征点检测,人脸对齐,特征提取,特征检索/比对等步骤。
人脸检测是指找出各人脸在图像中的空间位置,然后需要对检测出的人脸进行对齐等归一化的预处理操作。之后需要提取人脸的特征,来进行人脸比对和海量人脸搜索。
人脸特征的鲁棒性对结果的准确率有很大的影响,学术界和工业界在这个领域已经进行了多年的研究,本文主要从特征提取这个核心任务方面介绍人脸识别的最新进展。
2、人脸识别的模式及评价方法
人脸识别主要分为1:1验证 (face verification)模式和1:N检索 (face identification)模式。
1:1验证模式是给定2张人脸图片,算法进行比较并判断是否为同一人脸的过程,其主要应用有“刷脸”登录、支付等。

图1 人脸1:1验证
1:N检索则是在海量的人像数据库中找出当前用户的人脸数据并进行匹配,主要应用场景有安防等。

图2 人脸1:N检索
在1:1场景中误接受即将两个不同的人判断为同一人是一种严重的错误,所以需要将误接受率FAR(False Accept Rate)控制在一定程度如十万分之一或者百万分之一以下。
人脸识别受年龄、化妆、角度、光照、姿势、模糊、非同源照片等各种内部外部因素的影响,以及如何在识别亿级人脸,都是很有挑战性的工作,所以如何学习泛化特征,如何提高准确率,也是各科研人员几十年来不断追求的目标。
3、人脸识别的数据
得益于学术研究的开放性,目前有很多人脸识别的数据集,如LFW(Labeled Face in the Wild)等,而且近几年规模也是逐渐扩大,比如微软亚洲研究院收集整理的MS-Celeb-1M数据集有10万个名人的人脸,每人有约100张照片。一些常用的数据集及其规模如下图所示:

图3 人脸公开数据集
人脸识别方法
1、传统方法
经典的人脸识别方法主要有基于Eigenface或者LBP(Local Binary Pattern)等人工特征加分类器的方法。基于人工的特征对识别有所帮助,但是在实际应用中效果仍然有待提升。进入深度学习时代之后,人脸识别也有了飞速的发展。
2、基于深度学习的方法
1.DeepID系列方法
在DeepID[1,2]中两张图片分别通过深度卷积神经网络学习特征向量,然后拼接的特征向量通过一个分类器来判断是否属于同一人脸。其流程如图4所示:

图4 DeepID人脸识别算法流程
该方法主要有两个损失函数:一个是分类损失,一个是验证损失。
分类损失是人脸属于某个分类的交叉熵损失:
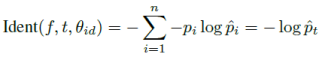
*pi 为真实标签,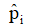 为网络分类的后验概率。
为网络分类的后验概率。
验证损失是特征向量A跟特征向量B之间距离的损失,其表示形式为:
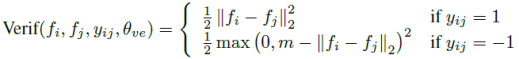
*其中fi为人脸特征向量,m为一个可调的距离参数,控制向量之间距离。
在实际训练中,DeepID也用了比前人工作大很多的数据集,CelebFaces+有10177人,202599张图片。
8700人训练DeepID,1477人训练Joint Bayesian分类器。同时也使用了多尺度多区块的方法,将人脸分成不同大小的区域训练不同的网络,多个网络的融合取得了当时最好的效果。

图5 多区域多尺度人脸
2. 三元损失函数
在这之后谷歌公司的研究人员将验证损失进行了扩展,在FaceNet[3]的论文里面提出了三元损失函数(Triplet Loss),其数学形式如下:
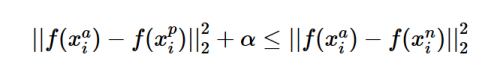
三元损失函数主要通过选取一个参考样本 ,以及跟参考样本同一分类的正样本
,以及跟参考样本同一分类的正样本 ,不同分类的负样本
,不同分类的负样本 这样一个三元组来求得损失。
这样一个三元组来求得损失。
以此来确保参考样本和正样本之间的距离加上一个边距 之后仍要小于参考样本和负样本之间的距离。
之后仍要小于参考样本和负样本之间的距离。
其示意图如图6所示:
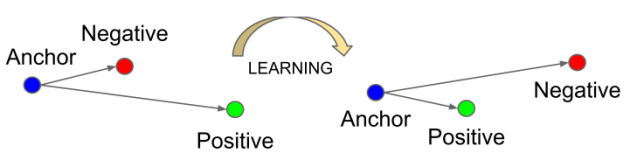
图6 三元组之间的距离
3. 基于边界损失函数
近年来基于边界损失函数的方法取得了很大的进展,比如将Megaface赛事的准确率一度提高到了98%。基于边界的损失函数是对通常的交叉熵损失函数的改进,通常的交叉熵损失函数为:
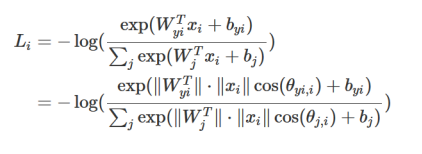
此时类与类之间的决策平面由两个参数W和b决定,如论文[4]所示:如果我们增加约束,使得 ,可得修改过的损失函数为:
,可得修改过的损失函数为:
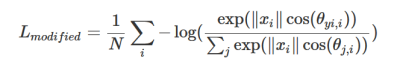
如果我们在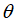 上面乘以一个大于1的系数m,变成:
上面乘以一个大于1的系数m,变成:
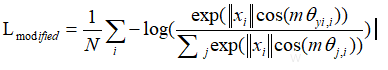
如图7(b)所示不仅可以放大类间距离,还使得类内的距离变小。通常的交叉熵损失函数只解决了分类问题,但人脸识别不是一个单纯的分类,而是需要学习人脸特征使得--类间距离越大,类内距离越小越好。

经过修改的损失函数直接优化了特征的距离和决策平面,使得效果超越了普通的方法。Cosface、Arcface[5] 也在论文里面对损失函数进行了改进,使得识别效果各有提升。各方法在经典数据集LFW上的结果如表1所示。
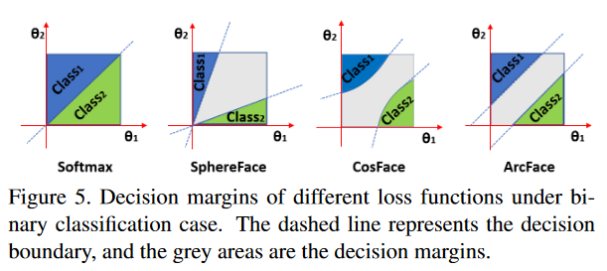
图7 不同损失函数的决策边界
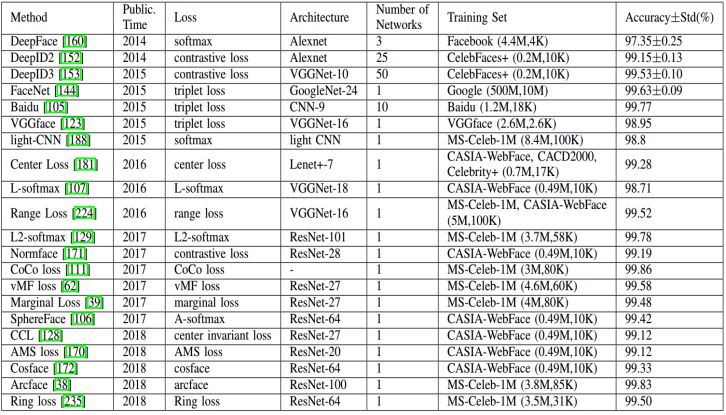
表1 各方法在LFW的准确率
大规模人脸检索方法
1、暴力检索
人脸检索用到的主要技术是向量之间求距离。假设人脸特征向量的维度是D,用普通的方法计算其跟某人脸库中所有向量的余弦距离(假设特征向量已经归一化)的公式为:

测试集矩阵P的大小为1*D,人脸库矩阵C的大小为N*D, 时间复杂度为O(N*D)。如果N的数量非常大,几百万或者上亿,这个过程会变得非常慢,所以如何在海量特征向量中找到最接近的,就需要用到近似检索。
2、近似检索
近似检索主要由法国学者Herve Jegou在Product Quantization for Nearest Neighbor Search[4]中提出,主要分为两步。第一步为粗量化,第二步为乘积量化。
乘积量化是指将原始向量分为m个子向量,如果选择 这样的参数,相当于用
这样的参数,相当于用 来表示原始向量,这样就大大降低了存储空间。
来表示原始向量,这样就大大降低了存储空间。
乘积量化如图9所示:
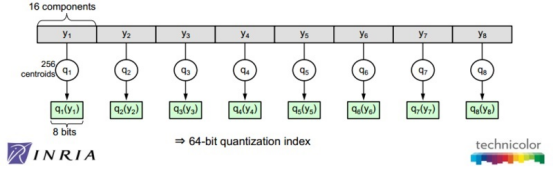
图9 乘积量化示意图
粗量化是指在原始的向量空间中,基于kmeans聚类出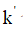 个簇。
个簇。
论文建议,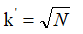 用簇的中心来代表该向量。
用簇的中心来代表该向量。
聚类之后查找准确率必然会下降,为了提高准确率和减少信息损失,论文中先计算了每个数据与其量化中心的残差,然后对残差做乘积量化达到效率和准确的提升。
此时检索的时间复杂度为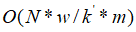 ,近似检索的一个c++/python实现参见。
,近似检索的一个c++/python实现参见。
来源:
https://github.com/facebookresearch/faiss
参考文献:
[1] Deep learning face representation from predicting 10,000 classes CVPR2014
[2] Deep learning face representation by joint identification-verification NIPS 2014
[3] FaceNet: A Unified Embedding for Face Recognition and Clustering CVPR2015
[4] SphereFace: Deep Hypersphere Embedding for Face Recognition CVPR 2017
[5] ArcFace: Additive Angular Margin Loss for Deep Face Recognition CVPR 2019
[6] Product Quantization for Nearest Neighbor Search, PAMI 2011
投稿 | 内容标签团队
声明:本文来自OPPO大数据,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
