古人云,“鱼,我所欲也,熊掌亦我所欲也;二者不可得兼”。大数据时代,数据挖掘诚可贵,例如各类APP通过收集我们的行为信息进行购买商品与美食预测和推荐,提高用户体验和提升效率;然而,隐私保护价更高,例如敏感的个人信息(姓名、家庭住址和手机号码等)被某些机构收集,为了某种利益被非法贩卖或泄露,定向电信诈骗由此而生,山东徐玉玉案件给社会敲响了警钟。在大数据的应用场景下,在满足数据安全和隐私保护的同时,实现数据的流动和价值的最大化/最优化成为“数据控制者”或“数据处理者”普遍诉求。幸运的是,经过信息技术的发展和革新,“鱼和熊掌兼得”成为可能:数据处理者/控制者不但能收获到那条“鱼”(价值挖掘),也能得到预想的那只“熊掌”(隐私保护)。
在该系列的第一篇中:《浅析数据安全与隐私保护之法规》,介绍了国内外的数据安全与隐私保护相关法规,如欧盟《GDPR》、美国《CCPA》和中国《网安法》。这些法规保护的个人数据(或个人信息)范畴均十分广泛,且具有严格的约束和规范。在法规指导下,如何更好地满足合规,降低法律风险和隐私泄露风险;同时也能满足业务场景需求。目前存在多种关键技术,场景不同,需求不同,对应的技术也自然不同。本文作为《大数据时代下的数据安全》系列的第二篇:场景技术篇,将介绍四种关键技术:数据脱敏、匿名化和差分隐私和同态加密,并对每一种介绍技术的从场景、需求和技术原理等几个维度进行展开。
一、数据脱敏
数据脱敏,也称为数据漂白(英文称为Data Masking或Data Desensitization)。由于其处理高效且应用灵活等优点,是目前工业界处理敏感类数据(个人信息,企业运营、交易等敏感数据)普遍采用的一种技术,在金融、运营商、企业等有广泛应用。广义地讲,人脸图像打码(马赛克)实际也是一种图片脱敏技术:通过部分的屏蔽和模糊化处理以保护“自然人”的隐私。但本文讨论的是传统的(狭义的)脱敏技术——即数据库(结构化数据)的脱敏。
场景
数据库是企业存储、组织以及管理数据的主要方式。几乎所有的业务场景都与数据库或多或少有所关联。在高频访问、查询、处理和计算的复杂环境中,如何保障敏感信息和隐私数据的安全性是关键性问题。对于个人信息使用和处理场景,主要有以测试、培训、数据对外发布、数据分析等为目的场景。举一个测试场景例子。假如小明是测试人员,在进行产品测试过程中,需要使用一些用户个人信息示例数据。如果可以直接访问和下载用户个人信息的原始数据,那么有隐私泄露的风险(他可能将用户个人信息卖给另一家公司)。
为了避免风险,可对所有数据项逐一进行加密。但这引起了一个问题——数据的密文数据杂乱无章,已经失去了测试和验证价值。那么是否可以在数据可用性(Data Utility)和隐私保密性(Privacy Protection)进行折中呢,答案是肯定的。如示意图1中,小明需要访问用户信息数据库,服务器根据小明的权限对数据颗粒度进行管控和脱敏处理,,比如仅保留姓、年龄进行模糊处理(四舍五入)、电话号码屏蔽中间四位。那么小明无法得到准确无误的用户信息,或者猜测次数过多(猜测概率过低)带来的攻击成本不足以支撑小明的攻击动机(铤而走险)。
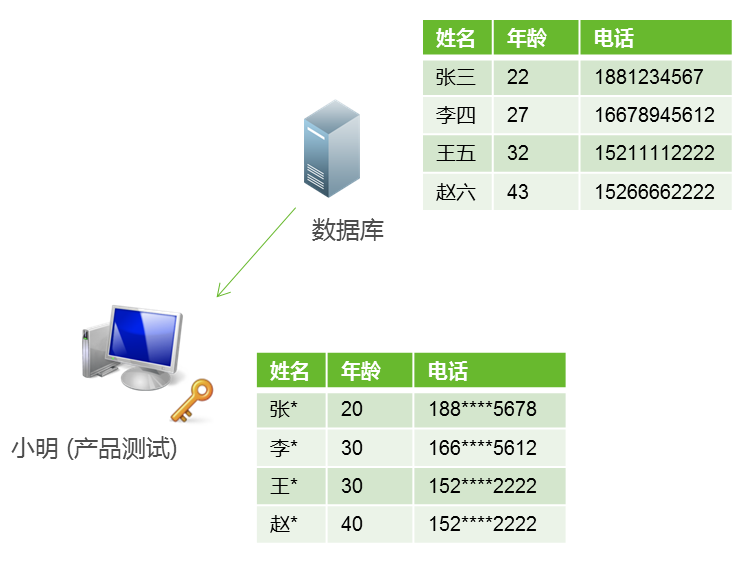
 图1 测试场景:使用脱敏数据
图1 测试场景:使用脱敏数据
需求
个人信息或其他敏感信息的处理,必须满足两个要求:
1.数据保密性(Data confidentiality):对于个人信息,称为隐私保密性(Privacy Protection)。需要保证潜在的攻击者无法逆推出准确的敏感信息,对于一些关键信息无法获取。
2.数据可用性(Data Utility):保证被处理后的数据,仍然保持某些统计特性或可分辨性,在某些业务场景中是可用的。
这两个指标是一对矛盾。如何调节与平衡:哪些数据字段需要加强保密?哪些字段可以暴露更多信息?屏蔽多少信息可达安全/应用?这些需要分析和研究具体应用场景,再一步细化两个指标需求(场景需求的定制化)。比如某一个APP的业务场景,需要统计和分析APP用户的年龄分布,为了保护用户隐私,需进行处理和失真,但需尽可能保留年龄字段的统计分布。如何达到呢?下面即将介绍。
技术原理
数据脱敏是解决上述需求的关键技术。所谓脱敏,是对敏感数据通过替换、失真等变换降低数据的敏感度,同时保留一定的可用性、统计性特征。为了达到这个目标,有一系列的方法/策略可以使用。以下表格列举一些典型的脱敏方法/策略。具体使用哪种脱敏方法,需要根据业务场景,如数据的使用目的、以及脱敏级别等需求去选择和调整。如上述统计APP用户年龄分布的例子,可使用重排的方法保证数据的统计分布。
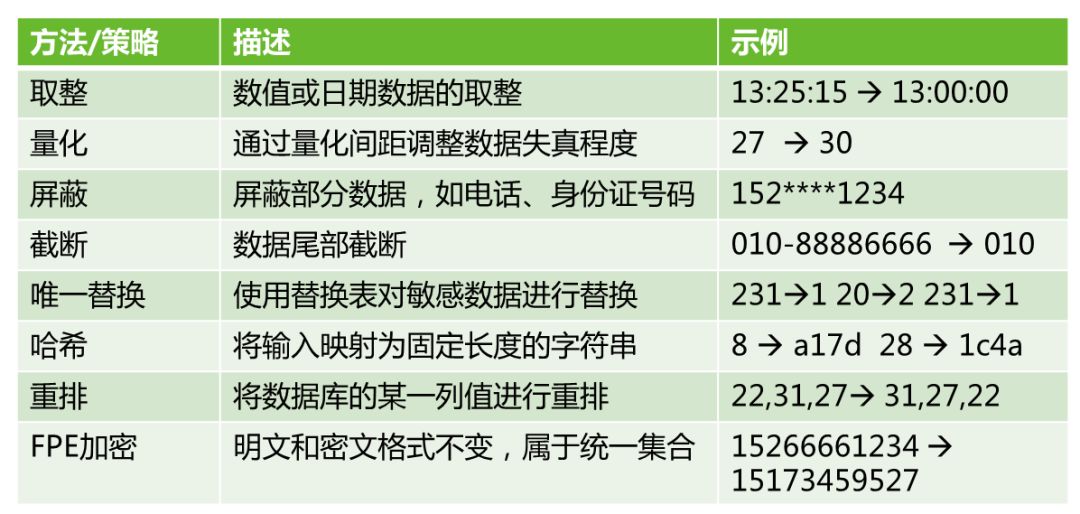
图2 常见脱敏方法/策略
其中,保留格式加密(Format-Preserving Encryption,FPE)是一种特殊的加密方式,其输出的密文格式仍然与明文相同。比如中国联通手机号15266661234,通过FPE加密可以实现仍然输出的是联通手机号15173459527。FPE加密应用时,需考虑格式及分段约束,这与一般的对称分组加密不同。为了规范FPE技术实施,美国NIST发布了FF1标准算法,可用于保险号、银行卡号、社保卡号等数字标识符的加密与脱敏。
应用
按照使用场景,可将脱敏分为静态脱敏(Static Data Masking, SDM)、动态脱敏(Dynamic Data Masking, DDM),本文介绍是前者。静态脱敏一般用于非生产环境中(测试、统计分析等),当敏感数据从生产环境转移到非生产环境时,这些原始数据需要进行统一的脱敏处理,然后可以直接使用这些脱敏数据;动态脱敏一般用于生产环境中,在访问敏感数据当时进行脱敏,根据访问需求和用户权限进行“更小颗粒度”的管控和脱敏。一般来说,动态脱敏实现更为复杂。脱敏在多个安全公司已经实现了应用,IBM,Informatica公司是比较著名的代表。
二、匿名化
匿名化技术(Anonymization)可以实现个人信息记录的匿名,理想情况下无法识别到具体的“自然人”。主要有两个应用方向:个人信息的数据库发布或挖掘(Privacy Preserving Data Publishing,PPDP,或Privacy Preserving Data Mining, PPDM)。
场景
一个经典的场景,是医疗信息公开场景。医疗信息涉及患者个人信息以及疾病隐私,十分敏感;但对于保险行业的定价、以及数学科学家对疾病因素等各项研究,这些数据具有巨大的价值所在。为了保护患者的身份和隐私,让人很容易想到的是删除身份有关信息,即去标识化(De-identification)。关于此,一个经典案例,美国马萨诸塞州发布了医疗患者信息数据库(DB1),去掉患者的姓名和地址信息,仅保留患者的{ZIP, Birthday, Sex, Diagnosis,…}信息。另外有另一个可获得的数据库(DB2),是州选民的登记表,包括选民的{ZIP, Birthday, Sex, Name, Address,…}详细个人信息。攻击者将这两个数据库的同属性段{ ZIP, Birthday, Sex}进行链接和匹配操作,可以恢复出大部分选民的医疗健康信息,从而导致选民的医疗隐私数据被泄露[1]。
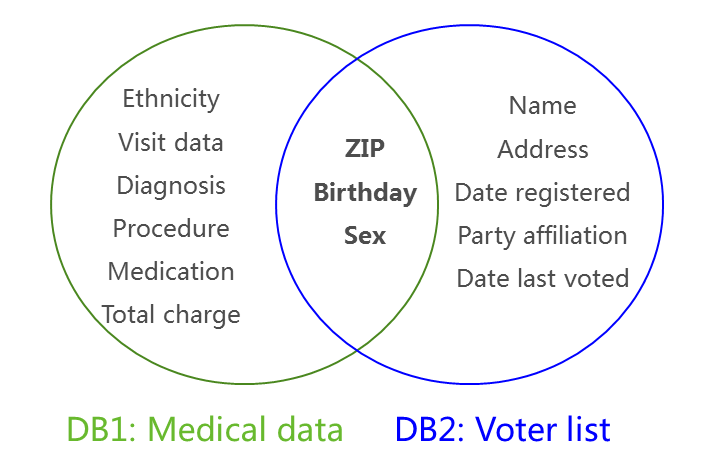
图3 链接攻击:两个数据库的链接
需求
1.无法重识别(De-identification):通俗地讲,如何使得发布数据库的任意一条记录的隐私属性(疾病记录、薪资等)不能对应到某一个“自然人”。
2.数据可用性(Data Utility):尽可能保留数据的使用价值,最小化数据失真程度,满足一些基本或复杂的数据分析与挖掘。
技术原理
为了满足以上需求,一般使用匿名化技术(Anonymization)。在学术研究上,最早由美国学者Sweeney提出,设计了K匿名化模型(K-Anonymity)[1]。即通过对个人信息数据库的匿名化处理,可以使得除隐私属性外,其他属性组合相同的值至少有K个记录。为了展示匿名化过程,下图给出了关于薪资的个人信息匿名化的例子。
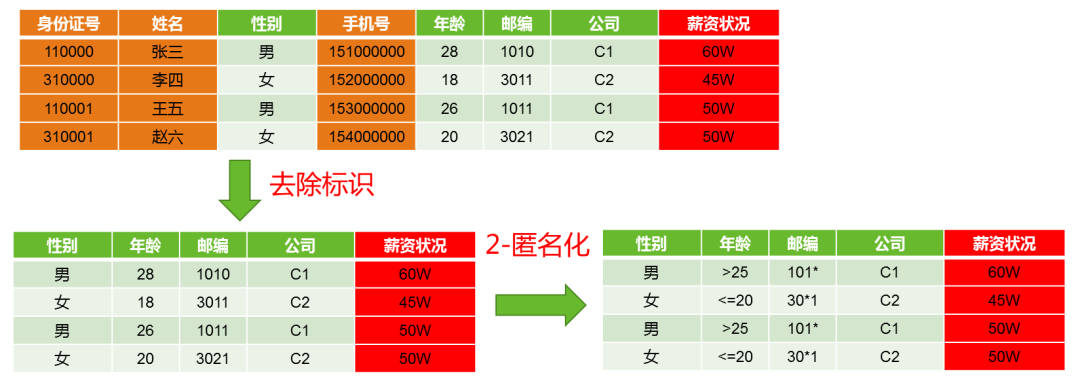
图4 2-匿名化示例:保护薪资隐私信息
对于大尺寸的数据表,如何实现K-匿名化的目标呢?这是算法实现和复杂度优化的问题,目前有基于泛化树和基于聚类的匿名化实现方法。除K-匿名化外,还发展和衍生出了(α, k)-匿名 ((α, k)–Anonymity)[2]、L-多样性 (L-Diversity)[3] 和T-接近性 (T-closeness)[4]模型。在具体应用时,需要根据业务场景(隐私保护程度和数据使用目的)进行选择。
概念辨析
需辨别的是,匿名化(Anonymization)、假名化(Pseudonymization)、去标识化(De-identification)三个概念有些联系,但不尽相同,却常常被混为一谈。
1.假名化(Pseudonymization):将身份属性的值重新命名,如将数据库的名字属性值通过一个姓名表进行映射,通常这个过程是可逆。该方法可以基本完好保存个人数据的属性,但重识别风险非常高。一般需要通过法规、协议等进行约束不合规行为保证隐私的安全性。
2.去标识化(De-identification):将一些直接标识符删除,如上表所示,去掉身份证号、姓名和手机号等标识符,从而降低重识别可能性。严格来说,根据攻击者的能力,仍然有潜在的重识别风险,见图3。
3.匿名化(Anonymization):通过匿名化处理,攻击者无法实现“重识别”数据库的某一条个人信息记录对应的人,即切断“自然人”身份属性与隐私属性的关联。
一般来说,这三种方法对数据可用性依次降低,但隐私保密性越来越高。
三、差分隐私
差分隐私(Differential Privacy, DP)具有严格的数学模型,无需先验知识的假设,安全性级别可量化可证明。是近年来学术界隐私保护研究热点之一,同时,一些企业应用将差分隐私技术应用到数据采集场景中。
场景
一个典型的场景:统计数据库开放,比如某家医院提供医疗信息统计数据接口,某一天张三去医院看病,攻击者在张三去之前(第一次)查询统计数据接口,显示糖尿病患者是人数是99人,去之后攻击者再次查询,显示糖尿病患者是100人。那么攻击者推断,张三一定患病。该例子应用到了背景(先验)知识和差分攻击思想。
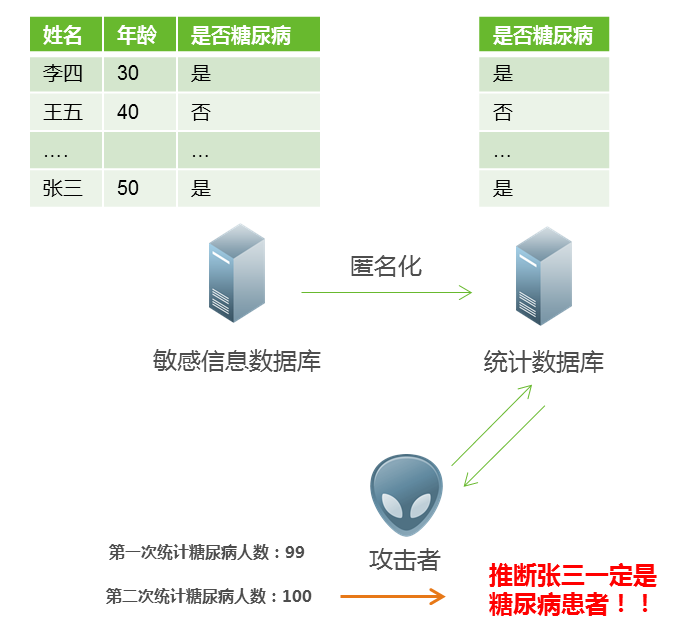
图5 攻击场景:应用背景知识和差分攻击获取隐私信息
需求
上述场景要求设计一种算法:即使攻击者拥有一定背景知识(先验知识),攻击者查询公开数据库,只能获得全局统计信息(可能存在一定误差),无法精确到某一个具体的记录(“自然人”的记录)
技术原理
为了这个需求,差分隐私技术(Differential Privacy, DP)应运而生。这项技术最早由微软研究者Dwork 在2011年提出[5]。DP可以确保数据库插入或删除一条记录不会对查询或统计结果造成显著影响,数学化描述如下:
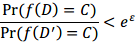
 和
和 分别指相邻的数据集(差别只有一条记录),
分别指相邻的数据集(差别只有一条记录),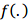 是某种DP算法,它对于任意的输出
是某种DP算法,它对于任意的输出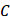 ,两个数据集输出的概率几乎接近(小于
,两个数据集输出的概率几乎接近(小于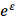 )那么称为满足
)那么称为满足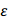 隐私。如何实现这个目标呢?一般来说,通过在查询结果加入噪声(如Laplace噪声),使得查询结果在一定范围内失真,并且保持两个相邻数据库概率分布几乎相同。那么DP方法可以抵抗差分攻击引起的隐私泄露。比如上述场景,第一次查询结果是99个,第二次查询
隐私。如何实现这个目标呢?一般来说,通过在查询结果加入噪声(如Laplace噪声),使得查询结果在一定范围内失真,并且保持两个相邻数据库概率分布几乎相同。那么DP方法可以抵抗差分攻击引起的隐私泄露。比如上述场景,第一次查询结果是99个,第二次查询 概率为 结果为99个,
概率为 结果为99个,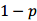 的概率结果是100个,那么攻击者无法准确地确认张三是否患病。
的概率结果是100个,那么攻击者无法准确地确认张三是否患病。
应用
以上介绍的是中心化的差分隐私 (Centralized Differential Privacy ,CDP)。随着研究的进展,出现了本地差分隐私(Local Differential Privacy, LDP)。LDP在用户侧进行,服务器无法获得真实的隐私信息,其核心思想是随机化算法,即每一个采集的数据都加入了噪声。若采集的数据足够多,那么得到相对准确的统计分布。LDP的原理注定它十分适用于用户隐私数据的采集。一些IT公司开始应用该项技术,比如iPhone使用LDP技术用户隐私,在可获得统计行为的同时,避免用户隐私的泄露。如图3是iPhone手机提供的说明例子(感兴趣读者可去手机查找和研究)[6],每一个用户的表情加入了噪声,是不准确的,但经过大量用户的频率统计,是相对准确的;Google也进行类似的应用,通过Chrome浏览器使用LDP技术采集用户行为统计数据。

图6 iPhone使用本地差分隐私技术:采集用户表情信息
四、同态加密
同态加密不同于传统的加密,它是应对新的安全场景出现的一项新型密码技术。它的出现,颠覆了人们对密码算法认知。使得密文处理和操作,包括检索、统计、甚至AI任务都成为可能。
场景
假设创业公司C拥有一批数据量大且夹杂个人信息的数据,需要多方进行共享和处理。为了降低成本,他选择使用廉价的不可信第三方平台:公有云。但为了保障传输和存储过程的数据安全,公司员工C1在数据上传前,对数据进行了加密,再将得到的密文数据上传到共有云。公司员工C2,需在共有云上执行一个数据分析和统计的任务。
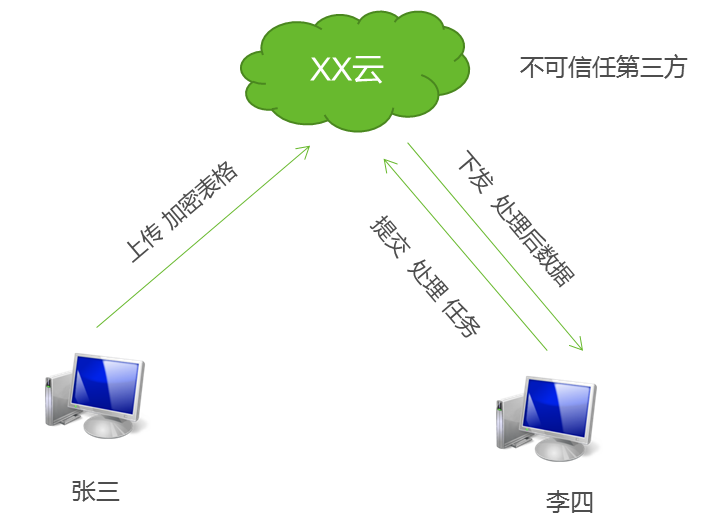
图7 云平台的安全计算场景
需求
以上的场景可提炼出两个需求:
1. 安全需求:除了公司C员工可解密数据外,其他人包括第三方平台无法解密和查看数据,即需要保障个人隐私数据的安全性;
2. 处理需求:存储在第三方平台的密文数据,仍然可以进行基本运算(加减乘除)、统计、分析和检索等操作。处理后的密文数据,返回给公司C的员工,得到结果和预期是一致的。
技术原理
同态加密满足上述需求的一项关键的技术之一。假设是两个明文,是加密函数,那么其存在以下性质,
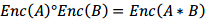
该性质在数学上称为同态性。通俗地讲,在密文域进行操作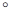 相当于在明文域进行
相当于在明文域进行 操作。这种性质使得密文域的数据处理、分析或检索等成为可能。如下示意图所示,假设员工C1上传两个密文数据
操作。这种性质使得密文域的数据处理、分析或检索等成为可能。如下示意图所示,假设员工C1上传两个密文数据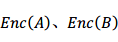 (对应两个明文数据)到不可信的云平台中,员工C2提交两个明文数据的任务,那么云计算平台对应执行密文的操作是:
(对应两个明文数据)到不可信的云平台中,员工C2提交两个明文数据的任务,那么云计算平台对应执行密文的操作是: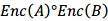 。从始至终,云平台一直没有接触到相关的明文信息,从而防止了第三方窃取导致的隐私数据泄露。
。从始至终,云平台一直没有接触到相关的明文信息,从而防止了第三方窃取导致的隐私数据泄露。

图8 同态加密在云平台的应用
应用
同态加密过程需要消耗大量的计算资源。但目前开始有一些开始朝向应用发展:同态加密逐步开展了标准化进程;另外创业公司Duality在定制服务器通过同态加密,实现隐私保护与AI任务等应用,可参考链接《Duality:基于同态加密的数据分析和隐私保护方案》。
五、小结
大数据时代,隐私保护诚可贵,数据挖掘价更高。根据实际应用场景,处理和平衡数据可用性(Data Utility) 和隐私保密性(Privacy Protection),是大数据时代下的数据安全的关键性问题之一。在保留一定的数据可用性、统计性等基础上,通过失真等变换实现降低数据敏感度——数据脱敏;通过“去识别化”实现隐私保护——匿名化;通过加噪来抵抗差分攻击——差分隐私;甚至将个人敏感信息直接加密,然后在密文数据上直接统计与机器学习——同态加密。
然而,其中一些技术在具体的场景落地时,仍然面临着诸多挑战,如数据可用性和隐私保护如何实现自适应调节;高维、大数据集的效率问题如何优化等是值得深入研究的问题。
笔者将“大数据时代下的数据安全”该主题分成三篇文章分别进行介绍:法律法规篇、技术场景篇、实践体系篇,本文是这个系列中的第二篇:技术场景篇。接下来我们将陆续发表其他两篇。本文提供只是一个引子和简介,希望能起到抛砖引玉的作用,与各位专家或数据安全爱好者共同探讨与分享有趣的话题。
参考资料:
[1].Sweeney L. K-anonymity: A model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-based Systems, 2002,10(5):557-570.
[2].Wong R C, Li J, Fu A W, et al. (α, k)-anonymity: An enhanced kanonymity model for privacy-preserving data publishing [C]. The 12thACM SIGKDD International Conference on Knowledge Discovery andData Mining, Philadelphia, PA, USA, August 20-23, 2006.
[3].l-diversity:Pri-vacy beyondk-anonymity. Machanavajjhala A,Gehrke J,Kifer D,et al. Proceedings of the 22th International Conference on Data Engineering . 2006
[4].Li N H, Li T C, Venkatasubramanian S. t-Closeness-privacy beyond kanonymity and l -diversity [C]. IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, April 15-20, 2007: 106-115.
[5].Dwork C. Differential privacy[J]. Encyclopedia of Cryptography and Security, 2011: 338-340.
[6].https://www.apple.com/privacy/docs/Differential_Privacy_Overview
声明:本文来自绿盟科技研究通讯,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
