Gartner认为,到2020年,超过60%的企业将无法有效解密HTTPS流量,从而无法有效检测出具有针对性的网络恶意软件。
一、背景
随着Internet网络和在线应用的迅速发展,为了确保通信安全和隐私,越来越多的网络流量被加密,然而,攻击者也可以通过这种方式来隐藏自己的信息和行踪。
一方面,DGA技术和Fast-flux技术的出现,使攻击者可以有效隐藏自己的域名和IP特征;另一方面,传统的安全防护功能需要分析通信数据来识别异常,但是当攻击流量与加密流量混合在一起时,传统流量检测方法的检测性能难以保证。也就是说,如果我们没有办法从域名或ip层面去检测,还可以从明文数据层面检测,但是数据也被加密了。

(图片来源于网络,侵删)
二、现状
恶意加密流量的识别和检测一直是行业的一个难点和痛点,虽然有进展,但总体来说还处于探索和研究阶段。目前主流的攻击检测手段有两种,解密后检测和不解密检测。
业界网关设备主要使用解密流量的方法检测攻击。首先,这种解密再重新加密的方法会消耗大量的资源,降低设备的总体性能,吞吐量、网络延迟等都会受到影响,虽然可以使用专用芯片来加速这些任务,但是成本很高;其次,解密流量违反了加密的初衷,即使在网络安全设备上立即对流量重新加密,这些信息也可能通过日志文件泄漏或存储在本地临时文件中,这将带给攻击者可乘之机;最后,对通信数据的监控会受到复杂的隐私法律法规的限制。
目前也出现了不解密进行流量检测的解决方案,比如思科团队提出了支持无需解密并可视化的加密网络流数据安全分析方案Stealthwatch,以解决通过第三方解密加密超文本协议https进行流量安全检测带来的数据泄露、资源消耗以及网络性能下降等问题。
三、Joy
Joy是Cisco开源的加密流量分析系统的前期预研项目,用于从实时网络流量或pcap文件中提取数据特征,使用类似于IPFIX或Netflow的面向流的模型,然后用JSON表示这些数据特征,它还包含可以应用于这些数据文件的分析工具。
传统的特征提取方式大多聚焦在数据包大小和一些与时间有关的参数上,Joy解析加密连接的初始数据包,充分利用未加密字段,比如当处于客户端向服务器端索要并验证公钥、以及双方协商生成“对话密钥”的握手阶段,除发生少量的随机数密钥外,该阶段大部分通信都是明文。Joy利用现有NetFlow架构,从加密包中提取四个主要数据元素:
1.数据包长度和时间序列:表示流的前几个包的每个包的应用程序负载的长度(字节数),以及这些包的到达间隔时间;
2.字节分布:表示一个特定字节值出现在流中数据包的有效负载中的概率,可以使用计数器数组计算流的字节分布;
3.TLS特有的特征:TLS握手由几个消息组成,这些消息包含有趣的、未加密的元数据,如选择的密码套件列表、TLS版本和客户机的公钥长度等;
4.初始数据包:用于从流的第一个数据包中获取数据包内容,其中包含从IP头开始的实际有效负载,可以提取有趣的数据,比如HTTP URL、DNS主机名/地址和其他数据元素等。
以下Joy的安装步骤基于Ubuntu 16.04 + python3环境,其他环境请移步https://github.com/cisco/joy/wiki/Building。
unzip joy-master.zipcd joy-master/sudo apt-get install build-essential libssl-dev libpcap-dev libcurl4-openssl-devsudo ./configure --enable-gzipsudo make clean;sudo makesudo ./install_joy/install-sh四、加密流量识别原型
流量分类是网络安全领域中至关重要的任务,往往是对网络异常流量进行检测的第一步,我们通过对加密流量提取特征并进行模型训练的方式,尝试探索一种应对不同场景去识别和检测加密流量的方法。
代理是加密通信服务的一个例子,作为安全访问和绕过审查去访问地理上被锁定的服务的方法,现在变得越来越流行,我们针对加密代理场景,收集了一些代理数据,然后使用Joy进行处理,并训练模型形成加密流量识别原型。
1数据集
我们收集了四种类型的流量,包含1132627条白流量、30782条shadowsocks流量、2898条v2ray流量、96198条tor流量,这里数据量的单位是数据包利用Joy处理之后流的数量。
为了得到加密流量识别原型,将整个数据集分为训练集、验证集和测试集三部分,其中数据集的20%用于模型测试,剩下80%的数据集中分出20%用于模型验证,其余80%用于模型训练,最后具体的数据集分布为:train dataset有808003条,val dataset有202001条,test dataset有252501条。
给每种类型的数据打上标签,进行有监督训练,“0”代表白流量、“2”代表shadowsocks、“3”代表v2ray、“4”代表tor。
2提取特征与预处理
调用Joy提取数据包原始特征,经过处理后提取出五种主要的数据元素,包含近千维特征,分别是:
1.数据流元特征
2.数据包包长序列
3.数据包时间间隔特征
4.数据包字节分布特征
5.数据包TLS特征
3模型训练测试
使用LightGBM作为流量识别分类模型,迭代74次遇到Early Stopping,如图1所示。
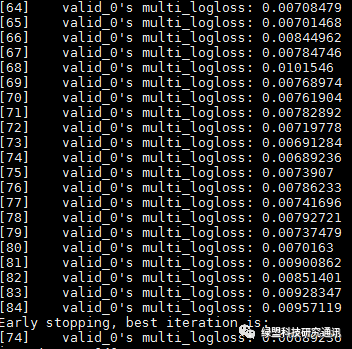

图1 迭代过程
将训练好的模型保存下来,在测试集上进行测试,结果如图2所示。可以看出,总体准确率和召回率均达到99.9%,准确率较低的是数据量较少的v2ray类别。

图2 测试结果
4特征可视化
用原始近千维特征,看看哪些特征在起作用,如图3所示,展示了重要程度较高的特征,column列表示特征所在的维度,importance列表示特征重要程度,数值越大,重要程度越高,按降序排列。可以看出,对于分类最重要的特征是第204维,其次是第0、1、3、2等维度的特征。
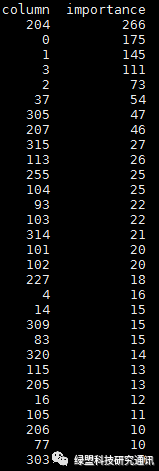
图3 特征重要性排序
将部分特征重要程度进行可视化,对应每个维度代表的具体特征,如图4所示,横坐标表示特征所在的维度,纵坐标表示特征重要程度,按照颜色区分每一类特征,黑色代表数据流元特征,红色代表数据包包长序列,蓝色代表数据包时间间隔特征,绿色代表数据包字节分布特征,黄色代表数据包TLS特征,可以看出,提取的特征对加密代理识别分类都发挥着不同程度的作用。

5小结
通过上述实验结果可以看出,我们提取的特征对不同代理流量具有较好的区分度,其中一些特征在流量识别中扮演了非常重要的角色,最终对加密代理的分类也表现出较高的准确率和召回率,已经在解决加密流量识别的问题上迈出成功的一步。当然,加密流量识别还有别的应用场景,比如恶意软件识别、应用识别、协议识别等,这些都等着我们一步一步去进行探索。
五、模型选择
机器学习方法与输入特征的选择高度相关,此外,数据集的大小也影响模型的选择。例如,当数据集很小的时候,深度学习方法是不合适的。假设数据集很大,下面描述三个常用的输入特征和相应的合适模型:
1.时间序列+报头:由于时间序列特性几乎不受加密的影响,因此被广泛应用于各种应用程序和数据集。前几个包(从10到30个包)足以在许多数据集中进行分类,经典的ML算法和MLP模型在表示输入维数的包数较小时表现得很好,对于数量较大的数据包,CNN和LSTM更准确。一般来说,深度模型的计算复杂度和训练时间都高于经典的机器学习算法。
2.Payload+报头:在当前加密的流量中,包含握手信息的前几个数据包通常是未加密的,并且已经成功地用于分类。由于输入的高维性(负载中有大量字节),传统的ML方法和MLP可能并不能很好地工作,但是通常CNN或LSTM却具有高精度。除了有效负载信息外,时间序列特性也有助于提高精度,但这几乎不会改变输入维度或模型的选择。
3.统计特征:例如数据包的包长、时间间隔等,利用统计特征作为输入的维度是有限的,大多使用经典的ML方法,在极少数情况下也使用MLP来实现。一般来说,根据数据集和统计特征的选择,利用前10到180个数据包的统计特征可能就足以进行分类。虽然统计特征可以让我们基于经典的机器学习算法构建一个更简单的分类器,但它可能不适合在线快速分类,因为它需要捕获足够多的数据包才能从流中获得可靠的统计特征。
参考链接:
[1].https://github.com/cisco/joy
[2].https://www.aqniu.com/tools-tech/45207.html
[3].https://www.aqniu.com/tools-tech/31233.html
参考文献:
[1].Identifying Encrypted Malware Traffic with Contextual Flow Data
[2.]Deep Learning for Encrypted Traffic Classification: An Overview
声明:本文来自绿盟科技研究通讯,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
