
编译 | 王优雅
雷锋网AI掘金志消息,日前,英伟达与伦敦国王学院以及一家法国初创公司Owkin合作,在新成立的伦敦医学影像与人工智能中心中应用了联邦学习技术。
这项技术论文在今年的MICCAI 2019大会上发布,英伟达与伦敦国王学院研究人员在大会上介绍了联邦学习技术的实施细节。
研究人员表示:“联邦学习在无需共享患者数据的情况下,即可实现协作与分散化的神经网络训练。各节点负责训练其自身的本地模型,并定期提交给参数服务器。服务器不断累积并聚合各自的贡献,进而创建一个全局模型,分享给所有节点。”
研究人员进一步解释道,虽然联邦学习可以保证极高的隐私安全性,但通过模型反演,仍可以设法使数据重现。为了帮助提高联盟学习的安全性,研究人员研究试验了使用ε-差分隐私框架的可行性。这个框架是一种正式定义隐私损失的方法,可以借助其强大的隐私保障性来保护患者与机构数据。
据了解,试验是基于取自BraTS 2018数据集的脑肿瘤分割数据实施的。BraTS 2018 数据集包含有285位脑肿瘤患者的MRI扫描结果。
NVIDIA团队解释到,联邦学习有望有效聚合各机构从私有数据中本地习得的知识,从而进一步提高深度模型的准确性、稳健性与通用化能力。
以下为论文详细内容,由AI掘金志学术组编译。关注AI掘金志公众号,在对话框回复关键词“英伟达”,即可获取原文PDF。
摘要
由于医疗数据的隐私规定,在集中数据湖中收集和共享患者数据通常是不可行的。这就给训练机器学习算法带来了挑战,例如深度卷积网络通常需要大量不同的训练示例。联邦学习通过将代码带给患者数据所有者,并且只在他们之间共享中间模型训练的信息,从而避开了这一困难。尽管适当地聚合这些模型可以获得更高精度的模型,但共享的模型可能会间接泄漏本地训练数据。
在本文中,我们探讨了在联邦学习系统中应用微分隐私技术来保护病人数据的可行性。我们在BraTS数据集上应用并评估了用于脑肿瘤分割的实用联邦学习系统。实验结果表明,模型性能与隐私保护成本之间存在一种折衷关系。
1.介绍
深度学习神经网络(DNN)在多种医学应用中都显示出很好的效果,但它高度依赖于训练数据的数量和多样性[11]。在医学成像方面,这构成了一种特殊困难:例如,由于患者数量或病理类型的原因,所需的训练数据可能无法在单个机构中获得。同时,由于医疗数据隐私规定,在集中数据湖中收集和共享患者数据通常是不可行的。
解决此问题的一个最新方法是联邦学习(FL)[7,9]:它允许在不共享患者数据的情况下对DNN进行合作和分布式训练。每个节点都训练自己的本地模型,并定期将其提交给参数服务器。服务器收集并聚合各个节点模型以生成一个全局模型,然后与所有节点共享。
需要注意的是,训练数据对每个节点都是私有的,在学习过程中不会被共享。只共享模型的可训练权重或更新,从而保持患者数据的私密性。因此,FL简洁地解决了许多数据安全挑战,将数据放在需要的地方,并支持多机构协作。
虽然FL可以在隐私方面提供高水平的安全性,但它仍然存在危险,例如通过模型逆推来重建单个训练模型。一种应对措施是在每个节点的训练过程中注入噪声并对更新进行扭曲,以隐藏单个模型节点的贡献并限制训练节点之间共享信息的粒度。[3,1,10]然而,现有的隐私保护研究只关注一般机器学习基准,如MNIST和随机梯度下降算法。
在这项工作中,我们实现并评估实用的联邦学习系统,用于脑肿瘤分割。通过对BraTS 2018的一系列实验,我们证明了医学成像隐私保护技术的可行性。
我们的主要贡献是:(1)尽我们所知,实现并评估第一个用于医学图像分析的隐私保护联邦学习系统;(2)比较和对比联合平均算法处理基于动量的优化和不平衡训练节点的各个方面;(3)对稀疏向量技术进行了实证研究,以获得一个较强的微分隐私保证。
2.方法
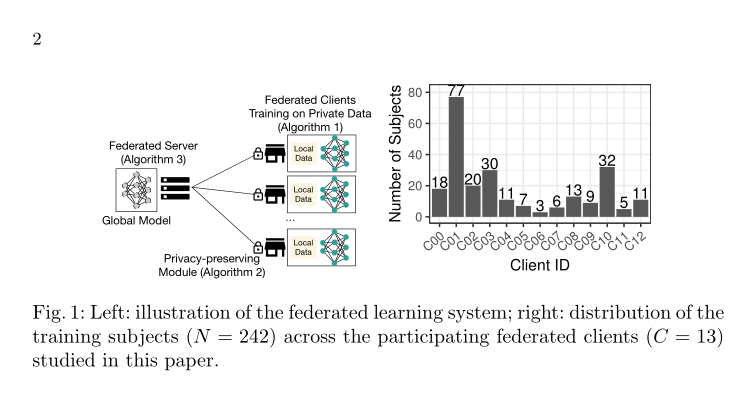
我们使用联合平均算法研究基于客户端-服务器架构(如图1(左)所示)的FL系统[7],其中集中服务器维护全局DNN模型并协调客户端的局部随机梯度下降(SGD)更新。本节介绍客户端模型训练过程、服务器端模型聚合过程以及部署在客户端的隐私保护模块。
2.1客户端模型训练过程
我们假设每个联合客户端都有一个固定的本地数据集和合适的计算资源来运行小批量SGD更新。客户端也共享相同的DNN结构和损失函数。训练程序详见 Algorithm 1图中。在联合训练t轮中,通过从服务器读取全局模型参数w(t)初始化本地模型,并通过运行多次SGD迭代将其更新为w(l,t)。在固定次数的迭代n(本地)之后,将模型差异△w(t)与聚合服务器共享。
医学图像的DNN通常采用基于动量的SGD进行训练。在优化过程中引入基于动量的梯度,在计算当前步骤时将上一步SGD步骤纳入计算。它有助于加速训练,减少振荡。我们探索了在FL中处理这些步骤的设计选择。在我们提出的过程(Algorithm1;以ADAM Optimiser[5]为例)中,我们在每轮联合训练开始时(第3行;表示为m.restart)重新初始化每个客户端的基于动量的梯度。
由于本地模型参数是从聚合其他客户端信息的全局模型参数初始化的,因此重新启动操作有效地清除了可能干扰训练过程的客户端本地状态。经验性的与以下两种方式进行比较(a)客户端在不共享的情况下保留一组本地动量变量;表示为baseline m;(b)将动量变量视为模型的一部分,即变量在本地更新并由服务器聚合(表示为m.aggregation)。虽然m.aggregation在理论上是合理的[12],但它需要将动量变量传送到服务器。这增加了通信开销和数据安全风险。

2.2客户端隐私保护模型
客户端被设计为对共享的数据进行完全控制,并且本地训练数据永远不会离开客户端的站点。不过,像参考文献[4]中这样的模型逆推侵袭可以从更新的△w(t) 或者联合训练中的全局模型w(t)提取中出病人隐私信息。我们采用选择性参数更新和稀疏向量技术(SVT)来提供对间接性数据泄漏的强大保护。
选择性参数更新:客户端训练结束时的完整模型可能会过拟合,并记忆了本地训练示例。共享此模型会带来暴露训练数据的风险。选择性参数共享方法限制客户端共享的信息量。这是通过(1)只上传△w(t)k的一部分:如果abs(wi)大于阈值τ(t)k,则共享△w(t)k的分量wi;(2)通过将值剪裁到固定范围[-γ,γ]来进一步替换△w(t)k来实现的。这里abs(x)表示x的绝对值;τ(t)k是通过计算abs(△w(t)k)的百分位数来选择的;γ独立于特定的训练数据,并且可以在训练前通过一个小型的公共可用验证集来选择。梯度剪裁作为一种模型正则化方法也被广泛应用,以防止模型过拟合。
微分隐私模型:利用SVT可以进一步改善选择性参数共享,使其具有很强的微分隐私保证。Algorithm 2描述了wi选择和共享被打乱分量的过程。直观地说,共享wi的每一个查询都是由Laplacian机制控制的,而不是简单地对abs(△w(t)k)进行阈值化并共享分量wi。这是首先通过比较剪接及加入噪声的abs(wi)和噪声阈值τ(t)+Lap(s/ε2)(第8行,Algorithm 2),然后仅共享噪声结果(wi+Lap(qs/ε3),γ)(如果满足阈值条件)。这里Lap(x)表示从由x参数化的laplace分布中采样的随机变量;clip(x,γ)表示x的剪裁到[-γ,γ]的范围内;s表示在这种情况下由γ限定的联合梯度的灵敏度。重复选择程序,直到释放△w(t)k的q分数。此过程满足(ε1+ε2+ε3)-差异隐私。

2.3服务器端模型聚合
服务器分布一个全局模型,并在每个联合轮次接收来自所有客户端的同步更新(Algorithm 3)。不同的客户端可能有不同数量的本地迭代用于生成△w(t)k,因此客户端的贡献可以是不同训练速度下的SGD更新。很重要的一点是要求客户端提供一个n(local),并在聚合它们时对贡献进行加权(第9行,Algorithm 3)。在部分模型共享的情况下,利用△w(t)k的稀疏特性来减少通信开销是将来需要做的工作。

3.实验
本节介绍了实验配置,包括每个FL系统使用的常见超参数。
数据准备:BraTs 2018数据集包含285例脑肿瘤患者的多参数术前MRI扫描。每个受试者用四种方式扫描,即:(1)T1加权,(2)T1加权增强,(3)T2加权,(4)T2液体衰减反转恢复(T2-FLAIR)。扫描结果被配准到相同的解剖模板上,重新取样到1×1×1 mm3的空间分辨率,并剥离颅骨。每个受试者数据还有经验丰富的神经放射学专家的像素级标注,标注出“整个肿瘤”、“肿瘤核心”和“增强肿瘤”。有关数据采集和注释协议的详细信息,请参阅Bakas等人。这个已完全标注的肿瘤分割数据集以前用于评估机器学习算法的标准,并且是公开的。我们选择使用它来评估具有多模态和多分类分割任务的FL算法。对于客户端本地训练,我们采用了最先进的训练方法,最初是作为Nvidia Clara Train SDK3的一部分设计和实施的,用于数据集中训练。
为了在受试者中测试模型泛化能力,我们将数据集随机分成一个模型训练集(n=242名患者)和一个验证测试集(n=43名被试)。这些扫描图像是从13个具有不同设备和成像协议的机构采集的,从而导致图像特征分布的不均匀性。为了使我们的联合训练更真实,我们进一步将训练集分为13个不相交的子集,这些子集根据图像数据的来源和分配给每个联合客户端。这种设置对FL算法来说是一个挑战,因为(1)每个联合客户端只处理来自单一机构的数据,与数据集中训练相比,该机构可能会遭受更严重的域转移和过拟合问题;(2)它反映了数据集的高度不平衡性(如Fig1所示)。最大的机构拥有的训练数据是最小机构的25倍。
联合模型配置:FL的评估过程与卷积网络结构的选择是垂直的。在不失通用性的前提下,我们选择Myronenko[8]提出的分割骨干作为底层联合训练模型,对所有实验使用相同的局部训练超参数集:网络的输入图像窗口大小为224×224×128像素,第一卷积层的空间丢弃率为0.2。与[8]类似,我们使用ADAM Optimiser将soft Dice loss 最小化,学习率为10-4,批量大小为1,β1为0.9,β2为0.999,l2重量衰减系数为10-5。对于所有联合训练,我们将联合训练轮次的数量设置为300,每个联合训练轮次中每个客户端运行两个本地epoch。本地epoch被定义为每个客户端“看到”其本地训练数据一次。在每个epoch的开始,在联合训练中,数据被本地打乱后给每个客户端。为了比较模型的收敛性,我们还做了600个epoch的数据集中的训练作为参考基准。
在计算代价方面,分割模型的参数约为1.2×106;使用nvidia tesla v100 gpu进行的训练迭代大约需要0.85s。
模型评估:我们使用三种肿瘤区域和所有测试对象的平均Dice score来测量模型在测试集上的分割性能。对于FL系统,我们公布联合客户端之间共享的全局模型的性能。
隐私保护模块设置:选择性参数更新模块有两个系统参数:模型q的分数和梯度限幅值γ。我们通过改变两者来测试模型性能。对于微分隐私模块,我们根据文献[6]将γ固定为10-4,灵敏度s固定为2γ,以及ε2 to(2qs)2/3ε1。下一节将介绍通过改变q、ε1和ε3而获得的模型性能。
4. 结果
联合VS数据集中训练:将FL系统与Fig.2(左)中的数据集中训练进行比较。在不共享客户数据的情况下,我们提出的FL程序可以获得不错的分割性能。从训练时间上看,数据集中模型在约300个训练时段收敛,FL模型训练在约600个训练时段收敛。在我们的实验中,使用Nvidia Tesla V100 GPU进行数据集中训练(n=242)的时间为0.85s×242=205.70s/epoch。FL训练时间由最慢的客户端(n=77)决定,它需要0.85s×77=65.45s再加上用于客户端-服务器通信的少量时间。
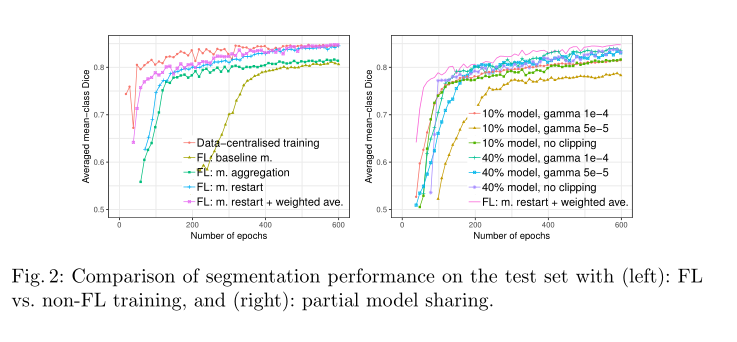
动量重启和权值平均:Fig.2(左)中也比较了FL程序的变体。对于处理动量变量,在每一轮联合循环中重新启动它们的效果优于所有其他变量。这表明(1)每一个客户端维护一组独立的动量变量会减慢联合模型的收敛速度;(2)平均每个客户端的动量变量会提高baseline m的收敛速度,但仍然得出比集中数据更差的全局模型。在服务器端,模型参数的加权平均优于简单的模型平均。这表明加权版本可以处理跨客户端的不平衡本地训练迭代次数。
局部模型共享:Fig.2(右)通过改变要共享的模型的比例和梯度剪切值来比较局部模型共享。这个数字表明,共享更大比例的模型可以获得更好的性能。局部模型共享不影响模型的收敛速度,当客户端共享整个模型的40%时,性能下降几乎可以忽略不计。对梯度进行剪裁有时可以提高模型性能。但是,需要仔细调整该值。
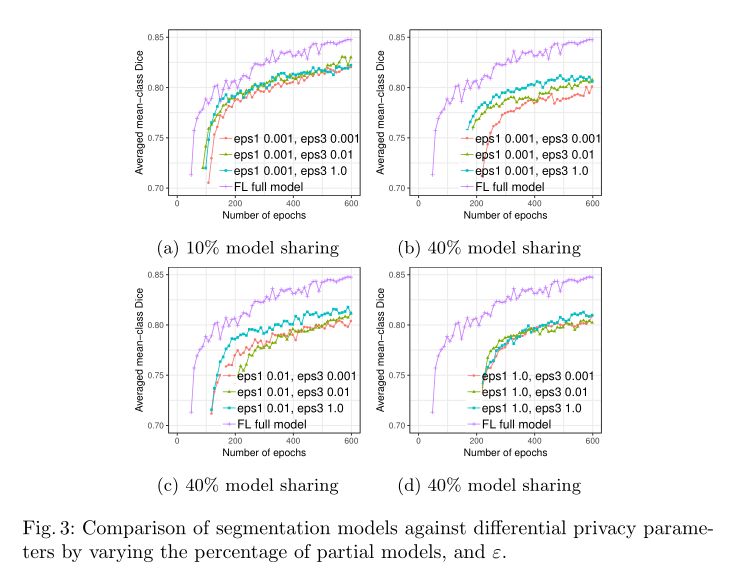
微分隐私模型:通过改变微分隐私(DP)参数的模型性能如Fig.3所示。正如预期的那样,DP保护和模型性能之间存在权衡。在相同的DP设置下,共享10%模型比共享40%模型表现出更好的性能。这是因为总的隐私成本ε是由训练过程中增加的噪声量和共享的参数数共同定义的。通过固定每个参数DP成本,共享较少的变量具有更少的总体DP成本,从而获得更好的模型性能。
5. 结论
我们提出了一个用于脑肿瘤分割的联邦学习系统,探索了联合模型共享的各个实际应用方面,重点研究如何保护患者数据隐私。虽然提供了强大的差异性隐私保护措施,但隐私成本分配是保守的。在未来,我们将探索用于医学图像分析任务的微分隐私SGD算法(如参考文献[1])。
参考文献
1. Abadi, M., et al.: Deep Learning with Differential Privacy. ACM SIGSAC Conference on Computer and Communications Security pp. 308–318 (2016)
2. Bakas, S., et al.: Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge. arXiv:1811.02629 (2018)
3. Geyer, R.C., Klein, T., Nabi, M.: Differentially private federated learning: A client level perspective. arXiv:1712.07557 (2017)
4. Hitaj, B., Ateniese, G., Perez-Cruz, F.: Deep models under the GAN: information leakage from collaborative deep learning. In: SIGSAC. pp. 603–618. ACM (2017)
5. Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization.
arXiv:1412.6980 (2014)
6. Lyu, M., Su, D., Li, N.: Understanding the sparse vector technique for differential privacy. Proceedings of the VLDB Endowment 10(6), 637–648 (2017)
7. McMahan, H.B., et al.: Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv:1602.05629 [cs] (Feb 2016)
8. Myronenko, A.: 3D MRI brain tumor segmentation using autoencoder regularization. In: International MICCAI Brainlesion Workshop. pp. 311–320 (2018)
9. Sheller, M.J., et al.: Multi-institutional deep learning modeling without sharing patient data: A feasibility study on brain tumor segmentation. In: MICCAI Brain-lesion Workshop. pp. 92–104 (2018)
10. Shokri, R., Shmatikov, V.: Privacy-Preserving Deep Learning. In: ACM SIGSAC Conference on Computer and Communications Security. pp. 1310–1321 (2015)
11. Sun, C., Shrivastava, A., Singh, S., Gupta, A.: Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. arXiv:1707.02968 [cs] (Jul 2017)
12. Yu, H., Jin, R., Yang, S.: On the linear speedup analysis of communication efficient momentum sgd for distributed non-convex optimization. arXiv:1905.03817 (2019)
下载链接:
https://arxiv.org/pdf/1910.00962.pdf
声明:本文来自AI掘金志,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
