优化识别能力和溯源能力
在网络信息技术快速发展的当下,做好网络舆论分析是确保网络舆论信息健康稳定传播的基本前提。
本文通过采集大量新闻报道语料数据,在不依赖任何行业语料的情况下,通过深度学习模型从网络新闻报道中分析出关键词汇与舆论主题并构建关系图谱,最后利用图分析算法对舆论话题之间潜在关系进行挖掘,实现对网络舆论传播路径的深层次分析。
该方法将深度学习技术与图分析技术相结合,在对语义进行分析的同时也兼顾了话题间关系的挖掘,优化了新闻真伪的识别能力和传播路径的溯源能力。
在互联网已经基本普及的当今社会,网络媒体上充斥着各种热点话题,同时也蕴含着大量有价值的信息,舆论话题之间存在着错综复杂的联系。在新兴技术大发展大应用的背景下, 要保护网络舆论阵地和意识形态安全,应积极跟踪对信息内容传播和舆论生态具有重大影响、对新闻传播和舆论动员、社会动员能力有重大变革提升的互联网新技术、新媒体应用、新功能,持续性开展前瞻性分析研究。
当前国内的舆情监测产品基本是使用基于爬虫技术、大数据存储、关键词匹配等方式进行舆情处理,但是其误报率、错报率、延保率等比较高。
虽然可以通过发挥人的主体性,围绕人的感知、理解和判断来优化更正技术造成的失误从而实现人机共生的系统,但是这样无形中加大了分析的成本并且严重影响了实施过程的效率。在网络舆论分析中,常用的数据挖掘技术包括高频词统计、情感聚类、语义消歧等方式。
但是这些方法对行业语料的要求较高,分析的结果往往依赖不断完善的行业语料库。
本文通过引入深度学习的分词技术,解决了网络舆论分析领域缺乏相应行业语料的难题。由于深度学习的分词技术是基于字符标注的方式来实现的,且在分词的过程中能够兼顾上下文的文本语义来判断,所以在分词实现的过程中不需要依赖任何行业语料,得到的分词结果比传统方法要精准很多。
在舆论传播的分析过程中,精准的语义分析能够提高舆论内容的辨识度,构建舆论数据的关系图谱,能够更有效地分析出舆论传播的导向。同时图数据库在关系分析中有着巨大的性能优势,能够快速地分析出各种舆论传播的形式。
这里通过同时使用深度学习方法与图分析方法,将各个模型算法有效结合,充分发挥模型的优势,使得分析过程更为合理、分析结果更为可靠,增强了对舆论传播的过程中新闻真伪的辨别能力和造谣源头的追溯能力。
介绍
本文主要研究的是使用深度学习方法与图分析方法相结合的思路来分析网络舆论的传播, 分词技术采用的是基于字符标注的双向长短期记忆网络模型和条件随机场算法相结合,该分词技术能够大幅度提高分词任务的准确性,为进一步的语义分析打下基础。
对于网络舆论传播分析来说,算法结果的准确性为减少误报和增加可信性提供了保障。相比其他类型的分词方法,基于深度学习的分词算法在分词效果上具有显著的优势,虽然训练模型的速度相对较慢,但是可以通过使用显卡处理器来加速计算过程。
在舆论分析领域,算法性能是一个非常重要的指标,只有快速地得出模型结果,才能更好地对事件关系的分析提供帮助。显卡处理器称为 GPU,它是专为执行复杂的数学和几何计算而设计的,这些计算能够极大地提高深度学习算法的训练速度。
所以调用 GPU 来对双向长短期记忆网络模型进行加速,能够在保障该算法结果准确性的同时提升模型的训练速度,从而弥补该算法在性能上的不足。
图分析方法是一个使用图的结构进行关系分析的方法,它使用节点、边和属性来表示和存储数据。通过明确地列出数据节点之间的依赖关系,图分析方法可以简单快速地检索难以在关系型数据库中建模的复杂层次结构。
对于挖掘事件之间的关系,图分析方法不需要构建大量的模型特征,展现了比传统机器学习算法在文本分析中更强大的优势。
同时,对比传统的关系型数据库,图分析方法所使用的图数据库在深层次遍历的任务中性能强悍,结合已具备的大量图分析算法,更适合寻找节点与节点之间潜在的联系,从而能够深层次地挖掘舆论传播的途径。具体思路如图 1 所示。
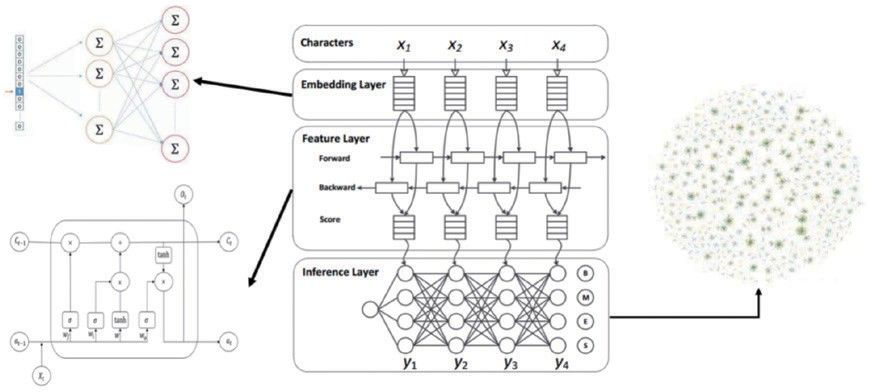
图 1 自然语言处理与图分析相结合的模型思路
方法
网络舆论传播分析旨在从海量的媒体新闻报道中挖掘出其中的舆论话题并找出舆论话题传播的形式。
首先利用分词技术将原始语料进行分词处理;
然后通过得到的关键词筛选出相关报道中的主题句,
再将主题句关联到对应的舆论话题;
最后利用图分析技术深入挖掘各个舆论话题之间的潜在联系。
模型主要分为三个部分:
(1)关键词提取:对原始语料进行数据清洗,剔除其中的非中文字符,然后通过调用GPU 来加速双向长短期记忆网络模型对语料进行分词,将分词的结果进行重要性筛选,最终筛选出每篇新闻报道的 Top N 关键词。
(2)话题句筛选:通过词嵌入方法对每篇报道的关键词进行词嵌入处理,并将关键词作为节点,词与词之间的余弦相似度作为边的权重构建一个无向有权图,然后利用中心度算法计算出每篇报道中的话题句。
(3)舆论传播分析:将各个话题句关联到对应的舆论话题,通过词嵌入技术计算关键词之间的相似度之后,将不同舆论话题之间的关键词相似度求和作为两个舆论话题之间的联系程度。以舆论话题为节点构建无向有权图,通过社区发现算法找到相关联的舆论话题。
2.1关键词筛选
关键词的筛选首先利用深度学习分词技术将原始语料进行分词处理,然后对舆论新闻报道关键词进行提取,主要分为三个步骤:文本数据的预处理、文本分词以及关键词筛选。
2.1.1原始语料数据的预处理
数据预处理旨在剔除非中文字符和序列标注。由于这里要做的是中文语料的分词,所以在使用分词模型之前,需要剔除标点、数字、字母以及乱码等非中文字符。这样做的好处是能够让模型所使用的文本语料减少干扰字符, 提高模型输出结果的准确性。
数据预处理的另一个目标是序列标注,具体做法就是将一个中文句子中的每一个字符都标记成包含 BIO 标注集的序列串,进而得到该句子的划分。BIO 标注集将每个元素标注为 “B-X”“I-X”或者“O”三类标签。
其中,“B-X”表示此元素所在的片段属于 X 类型并且此元素在此片段的开头,“I-X”表示此元素所在的片 段属于X类型并且此元素在此片段的中间位置, “O”表示不属于任何类型。
2.1.2文本分词技术的应用
文本分词就是将连续的字序列按照一定的规范重新组合成词序列的过程,在自然语言处理技术中,分词是一个基础的环节。通过准确的分词技术,能够把长文本分解成大量的词语,再结合词嵌入的技术为每个词语构建词向量表示,最终才能够作为文本分析模型的输入。
网络舆论传播分析原始语料包含大量舆情领域的专业术语,同时,由于舆论传播分析是基于大量的新闻报道进行的,模型要处理的语料库规模庞大。
所以舆论传播分析的分析方法需要同时具备特殊领域的适用性和海量数据的快速处理能力。基于深度学习的分词方法正好满足这一要求,由于深度学习分词技术是基于神经网络来实现的,大量的模型训练能够大幅度提高特殊领域的分词效果。通过使用真实数据实验证明,当训练语料库足够大时,深度学习技术实现的分词结果要高于传统的分词方法。
本文使用的是双向长短期记忆网络模型(LSTM)和条件随机场算法(CRF)相结合的分词方法,在模型的训练过程中选择调用GPU 的方法来加速计算。LSTM 模型的全称是Long Short-Term Memory, 它是 RNN(Recurrent Neural Network)的一种。
在对中文语料进行分词时,结合上下文的分词方法通常能够达到更好的分词效果。普通的神经网络模型中输入之间不会进行计算,所以无法将上文的模型信息与下文的模型信息结合起来。
为了能够结合上下文的内容来进行分词任务,这里使用循环神经网络 RNN 来实现。RNN 的网络结构会对前面的信息进行记忆并应用于当前输出的计算中,模型中隐藏层之间的节点是有连接的,并且隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。
单向的 RNN 网络只能考虑上文的信息来分析当前的内容,为了能够同时结合上文和下文的信息,需要在原有的网络基础上添加一条反向的运算把输入的序列反转,重新按照 RNN 的方式计算一遍输出,最终的结果为正向 RNN 的结果与反向 RNN 的结果的堆叠。
因为每一个传递给后面神经元的值都包含了前面所有时刻的输入信息,所以理论上双向 RNN 网络能够考虑到上下文的信息。但是 RNN 很难完美地处理具有长期依赖的信息。
为了能够解决较长序列的依赖问题,尤其是对于文本分析领域,往往需要完整地考虑到一整个句子的内容,所以本文采用了 RNN 网络的改进模型 LSTM。LSTM 由于其设计的特点,可以更好地捕捉到较长距离的依赖关系 , 非常适合用于对时序数据的建模,如文本数据。双向 LSTM 是由前向 LSTM 与后向LSTM 组合而成,是为了能够在自然语言处理任务中结合上下文信息来进行序列标注。
2.1.3目标关键词的筛选
在应用深度学习模型对原始语料进行分词处理之后,每篇新闻报道都被分成了大量的词语。这些词语中有些是与它所在的新闻报道主题相关联的,而也有一些属于通用词汇与实际报道的主题关联性较弱。
所以在进行文本分词之后,需要对所得到的分词集合进行筛选,剔除无意义的词语,保留能够关联到主题的关键词。
关键词提取就是一项从海量词语中提取出关键性词语的技术,通过提取出每篇语料的关键词,能够有效地减少后期模型的计算量并且减少数据噪声。
本文使用的关键词提取技术是一种统计方法 TF-IDF(Term Frequency-Inverse Document Frequency, 词频—逆文件频率),该方法的作用是评估一个词汇对于它所在文本的重要程度。
词汇的重要性随着它所在文本中出现的次数成正比增加,随着它在语料库中出现的频率成反比下降。当一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少 , 就越能够代表该文章。
首先需要计算的是给定的词语在该文本中出现的次数,因为同一个词语无论是否重要,其在长文件里可能会比短文件里有更高的词频,所以这里对次数进行归一化处理,将词频除以文章总词数以防止其偏向于较长的文件。
计算词频的公式如 (1) 式所示,其中表示在某一类中词条 w 出现的次数,N 表示该类中所有的词条数目。
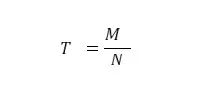
在有些情况下,词频比较大的通用词对分析文章的主题意义不大,而出现频率较少的词才能够表达文章的主题 , 所以单纯使用词频来判断一个词汇的重要性是不合适的。这里设计了一个权重,使得一个单词预测主题的能力越强则权重越大,反之则权重越小。
由总文本数目除以包含该词语文本的数目,再将得到的商进行取对数得到。计算公式如 (2) 式所示,其中 a 表示语料库的文档总数,表示包含词条 w 的文档数,分母之所以要加 1 是为了避免分母为 0。
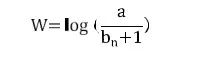
通过结合使用 (1) 式与 (2) 式的值,能够精准筛选出所需要的关键词,具体如 (3) 式所示:
通过上述算法计算各词在对应文章中的重要程度,然后提取每篇文章中权重值较大的前50 个词,最终汇总,统计词频,按词频降序提取前 1500 个词,就得到了所需要的重要关键词。具体思路如图 2 所示。
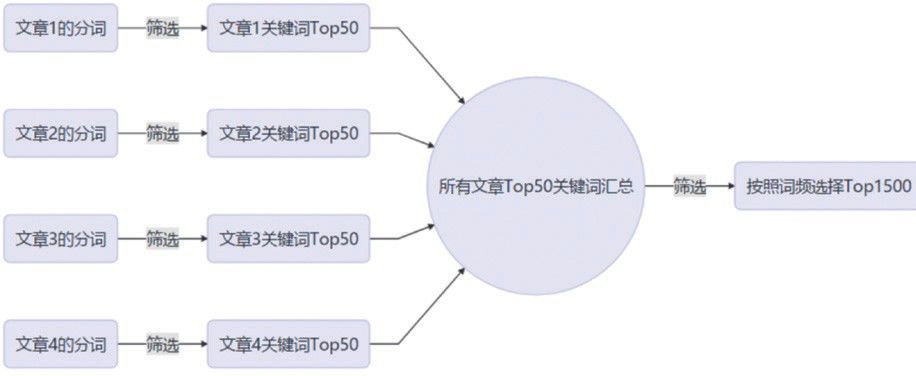
图 2 文本语料关键词的提取方法
2.2话题句提取
在分析舆论传播的过程中,网络新闻的语义分析可以通过话题句的提取来进行。话题句提取顾名思义,就是找出一篇文章中最能表达文章主题的中心句,旨在通过一句话来简要概括一篇文章的主要内容。
通过对一篇舆论语料进行话题句提取能够准确地反映出该语料所归属的话题,同时也能够对相关话题的内容进行扩展。所以在网络舆论传播分析过程中,话题句提取是一个非常重要的环节。
对于话题句提取任务,传统的方法使用的是“词频”来实现,通过计算文章中关键词的出现频率找到文章的中心句子以此来生成文章主题句。但是这种方法没有考虑到词汇的词性,词汇的近义词、反义词等诸多因素。
一篇新闻报道中包含了大量的句子,同样地,每个句子中也包含了多个单词。将每个句子作为一个节点,句子之间的单词相似度之和作为两个句子的关联程度,那么每篇语料都能够构成一个以句子为节点、以句子之间的关联程度为边的无向有权图。
通过知识图谱中的中心度算法就能够快速找到该图中最重要的一个节点,该节点所代表的句子即为当前语料的话题句。如图 3 所示,本文首先使用词嵌入的方法来计算关键词之间的相似度,然后通过中心度算法来寻找最佳话题句。
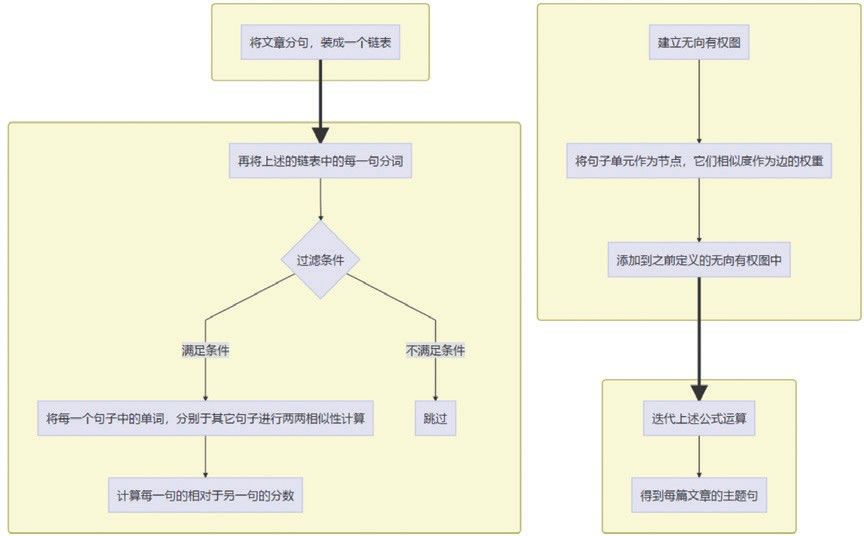
图 3 文本语料主题句的提取流程
2.2.1词嵌入处理
为了能够分析出一篇预料中各个句子之间的关联程度,需要通过其包含的关键词来进行计算。而关键词作为中文字符无法进行量化计算,所以需要通过词嵌入技术将所有的关键词嵌入到实数的向量空间来实现关键词之间关联程度的计算。词嵌入是自然语言处理技术中语言模型与表征学习技术的统称。
它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。
Word2Vec 方法是词嵌入技术的一种,主要包含了 Skip-grams 模型和 CBOW 模型,它们都是用来训练以重新建构语言学之词文本的浅层神经网络。网络以词表现并且需猜测相邻位置的输入词,在 word2vec中词袋模型假设下,词的顺序是不重要的。
当模型训练完成之后, word2vec 方法可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
在给出中心单词的情况下,可以通过计算在给定单词的条件下其他单词出现的概率来预测它的上下文单词。在进行模型训练之前,需要对每个词语进行one-hot 编码,将每个单词表示成一个向量来表示,该向量的维度是词汇表中单词的数量。
一个单词在词汇表中的索引位置决定了其 one-hot 向量中对应行的元素为 1, 其他行元素则为 0。有了单词的 one-hot 向量之后就能够构建出单词矩阵,单词矩阵是所有单词的词向量的集合。这里需要用到两个单词矩阵,一个是目标单词的词向量组成的矩阵 W。
另外一个矩阵是由除掉目标单词外的其他单词的词向量的转置组成的矩阵 W"。在模型训练的过程中,首先计算目标单词的词向量,然后使用其他单词矩阵W" 与目标单词向量相乘,相当于和词汇表中的所有词向量的转置都分别求内积,其结果组成了一个新的向量。
最后把得到的相似度矩阵代入softmax 公式,就得到了一个满足概率分布的矩阵。该矩阵中的数值就是模型的目标,代表了在给定单词的条件下其他单词出现的概率。
2.2.2构建无向有权图
两个向量之间的相似度可以通过计算它们的余弦值来得到。两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为 1;两个向量夹角为 90°时,余弦相似度的值为 0;两个向量指向完全相反的方向时,余弦相似度的值为 -1。这一结果是与向量的长度无关的,仅仅与向量的指向方向相关。
余弦相似度通常用于正空间,因此给出的值为 0 到 1 之间。给定两个属性向量 A 和 B,其余弦相似性 θ 是由点积和向量长度给出的,如 (4) 式所示:
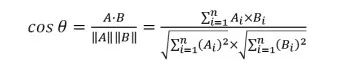
有了关键词之间的相似度之后,可以进一步通过关键词来计算两个句子之间的关联程度。在对一篇语料进行文本分词之后,该语料中的每个句子也会被分解成多个单词的形式。由上文中提取关键词的方法可知,对于不包含任何一个关键词的句子,往往是大量通用词汇所组成,其与文章所表现的主题关联程度较低。
所以一个包含关键词的句子与一个不包含关键词的句子之间的关联程度可以忽略不计。而对于两个都包含关键词的语句,可以将它们所包含的关键词两两求相似度最后求和的结果作为它们之间的关联程度。
对于每篇语料来说,将其中包含的所有句子作为节点,句子与句子之间的关联度作为有权边,能够构建一个无向有权图。在这个图中,包含关键词的句子之间相互连接,构成了一个联通子图,而不包含关键词的句子成为了孤立点。在将所有的语料数据导入图数据库中之后,每一篇语料都会对应一个联通子图和若干孤立点。那么找出文章主题句的任务就转化为寻找每个联通子图中的最重要节点。
2.2.3话题句提取
话题句的提取使用的是中心度算法,在图分析的过程中,中心度算法的目标是为了确定网络中某个顶点对于总体的重要性。该算法可分为接近中心度算法(Closeness Centrality)和中介中心度算法(Betweenness Centrality)。中心度算法测量每个顶点对于每个其他顶点的影响力。
该影响力是递归方式定义的:一个顶点的影响力基于引用它的其他顶点的影响力。如果引用某个顶点的其他顶点越多或引用该顶点的其他顶点具有更高的影响力,则该顶点的影响力更大 。
通过定义一个可以在任何规模的文件集合中计算得出的统计值 WS,每个链接都指向该集合中的某个特定文件。在初次计算前,总概率将被均分到每个文件上,使得集合中的每个文件被访问的概率都是相同的。
接下来在重复多次的迭代计算中,算法将根据集合的实际情况不断调整 WS 值,使得其越来越接近最真实的理论值。
定义一个统计量 WS,如 (5) 式所示:
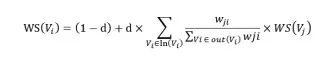
其中,d 为阻尼系数,取值范围为 0 到 1, 代表从图中某一特定点指向其他任一点的概率, 一般取值为 0.85。通过一定的迭代次数,最终不同的节点会有不同的 WS 值,WS 值高的句子单元就是该篇文章的主题句。
2.3舆论传播分析
在舆论传播分析的过程中,将原始语料进行分词处理并提取能够反映事件线索的关键词之后,通过结合舆论话题的关键词能够分析其所归属的类别。如果将一个舆论话题作为一个节点,那么一个话题类别就是多个节点所组成的一个集合。
舆论话题与话题之间的关联程度可以转化为话题与关键词之间的关联程度,在得到话题间的关联程度之后就可以利用图分析方法来完成舆论传播分析的任务。
2.3.1构建舆论话题关系图
与话题句提取方法类似,本文对网络舆论传播分析所使用的方法也是图分析。首先需要构建出一个包含所有舆论话题节点的图,其中节点类型包含两类:舆论话题和关键词。舆论话题节点代表的是新闻报道中所提到的话题名称,关键词节点代表的是前文中提取出来的关键词。
因为所有的关键词都是从舆论话题报道的语料中提取出来的,所以这里构建出来的图只包含舆论话题与关键词的无向边。边的权重由所连接的关键词与所连接的舆论话题报道语料中所有关键词相似度的最大值,计算如 (6) 式所示,其中表示事件语料中关键词 i 与所连接的关键词 j 的相似度,n 表示事件 j 包含的关键词总数。
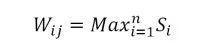
2.3.2舆论传播分析
在构建完成舆论话题与关键词的无向有权图之后,当指定一个舆论话题之后就可以通过遍历算法来寻找与某个舆论话题关联程度较高的一连串其他舆论话题,从而达到连点成线的目的。假设给定舆论话题编号为 A,那么就可以将事件 A 作为起始点开始遍历。
在A 节点的一步邻居节点之内,对比所有到邻居节点的边的权重, 权重越大表示两事件之间的关联程度越大。选择权重最大的邻居节点之后,继续遍历该邻居节点的一步邻居节点,同样选择权重最大的节点继续迭代遍历。当权重的大小低于某个阈值时停止迭代,将所有遍历过的节点从原图中提取出来就构成了一个连串的话题。
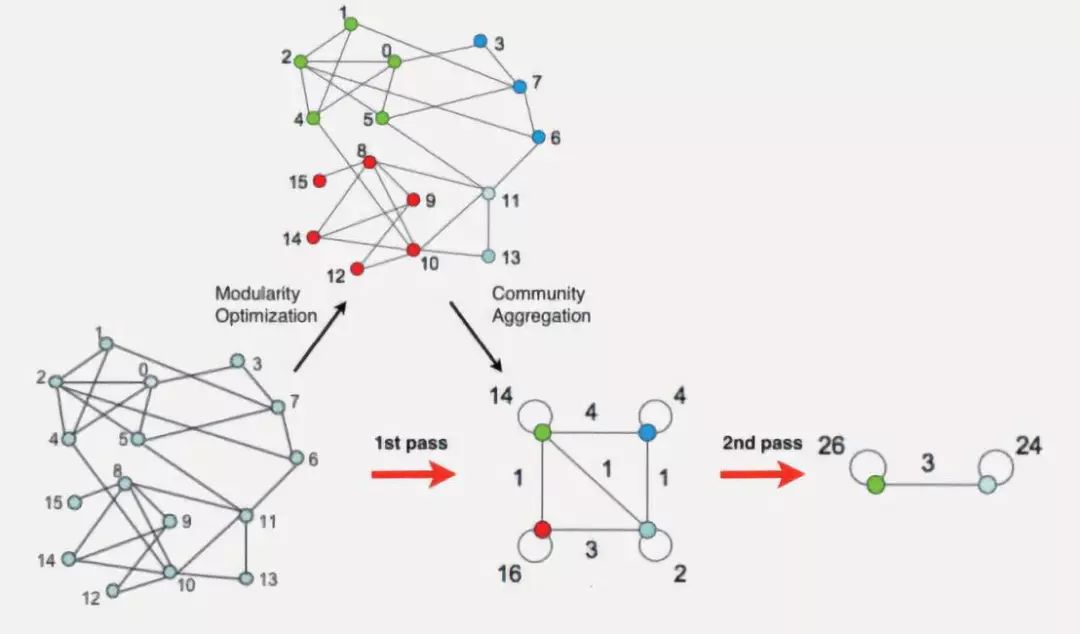
图 4 对复杂网络结构进行群体划分的方法
为了能够更加深入地挖掘舆论话题之间的潜在联系,需要用到前文中所提取出来的话题句。由于每个舆论话题都被提取出来一个话题句,而每一个话题句都能对应到一类话题,所以可以根据话题句所对应的话题来给每个舆论话题打上话题标签。
为了能够分析舆论话题之间的潜在关系,首先需要把前文中的舆论话题与关键词的无向有权图简化为只包含舆论话题节点的无向有权图。简化方法是将两个事件之间所有连接的关键词权重之和作为新的边的权重。
因为每个舆论话题已经有了话题标签,所以可以通过更新舆论话题的标签来改变它所归属的话题。如图 4 所示,如果某个顶点的大多数相邻顶点都带有群体标签 X,那么它也应该将自己标记为X的成员。该算法从每一个顶点开始运行,且每个顶点最初都有自己的唯一标签。
然后,基于上述逻辑不停地更新标签。而且关键点在于更新标签的顺序是随机的。高效的性能使得该算法十分适合大型的复杂关系网络。在最终的结果中,归属相同话题的舆论会被划分到一类,而归属不同话题的舆论则被相互区别开来。
如图 5 所示,图中橙色节点表示的是舆论节点, 绿色节点表示的是话题句节点,灰色节点表示的是关键词节点,深蓝色节点表示的是共有关键词节点,通过图分析算法能够找到与主题相近的舆论话题并将它们清晰地展示出来。
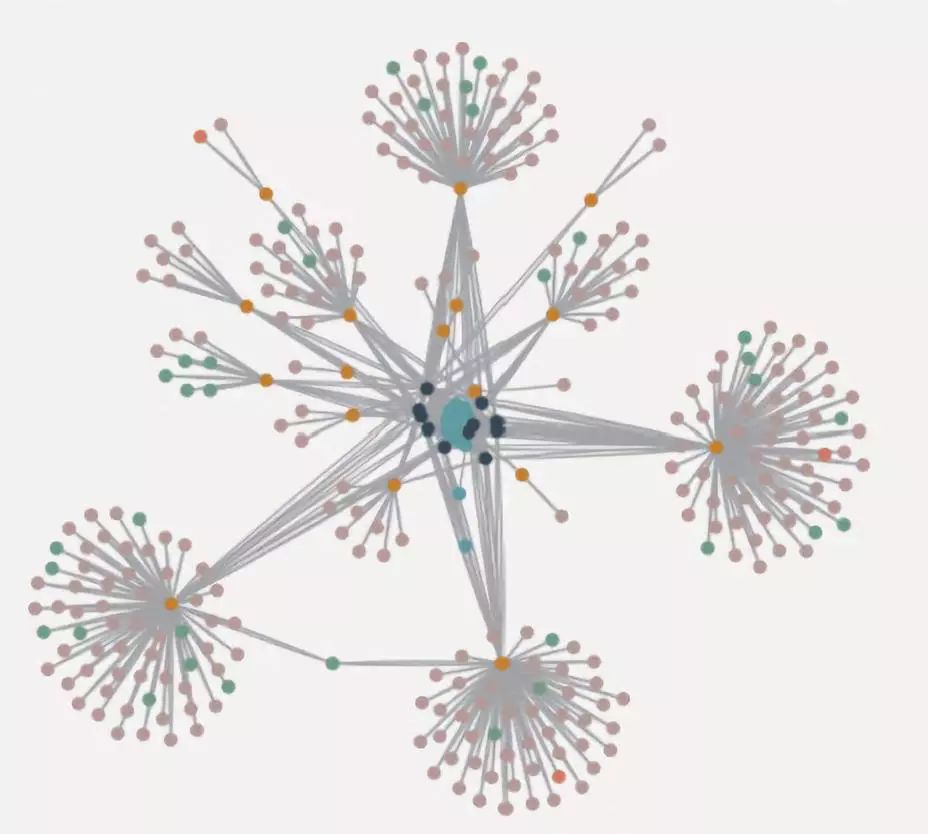
图 5 图分析方法在舆论话题分析中的部分节点展示
在对采集到的网络中大量新闻报道语料数据进行分析的实验结果表明,与传统的方法相比, 通过 GPU 加速计算的双向 LSTM+CRF 模型有了显著的性能提升,通过使用某一机构给出的 2000 个关键词及相应的新闻文本数据来进行实验分析,相对于传统的分词技术,双向LSTM+CRF 模型语义分析的准确度得到大幅度的提升,该模型不依赖现成的行业语料使得分析过程更为合理。
在网络舆论传播分析中,传统方法的语义分析效果往往依赖特定的行业语料。但是本文采取的是基于字符标注的分析方法, 通过对大量的新闻报道语料数据进行实验证明,双向 LSTM 方法在舆情分析领域中不使用现有词典的效果更好,对比效果如表 1 所示:
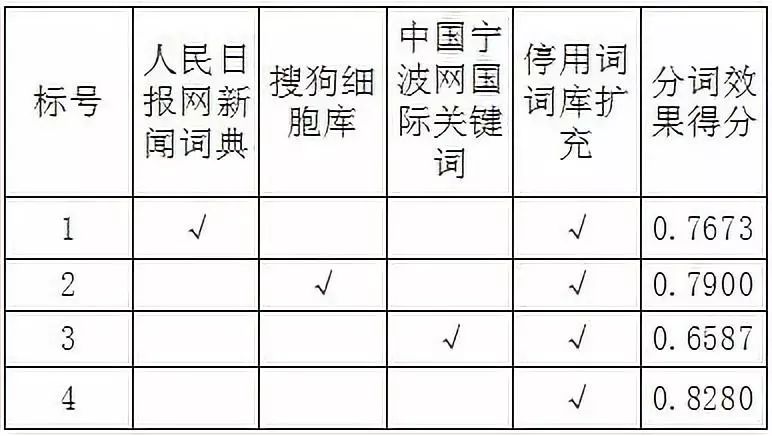
表 1 双向 LSTM+CRF 模型语义分析与传统分析效果对比
图分析方法在网络舆论传播分析中,能够挖掘出舆论话题之间深层次的联系,话题节点之间通过有权边连接也让模型的输出结果具备更强的可解释性。图 6 表示的是关于舆论传播路径的溯源示意图,通过图分析的方法能够从某一个给定的舆论节点出发进行深度遍历,寻找到具有强关联的其他舆论节点。
特别地,通过结合使用深度学习技术和图分析技术,能够通过图的方式来展现文本处理的结果,提升了可视化的效果。

图 6 舆论传播路径的溯源示意图
人工智能技术和大数据分析技术在相关行业内能够促成信息的精准投放。我们的方法可以有效降低模型的误报率,加快舆论传播分析速度,提升分析结果的可信度和可视化效果。通过对虚假新闻、骚扰广告、黄赌毒等违法犯罪信息进行甄别和溯源,能够有效防范重大信息安全问题和意识形态渗透隐患。
在面对海量的信息时,可以根据舆论传播知识图谱的分析结果,对已经阅读相关虚假信息的用户,定向推送辟谣信息,实现精准辟谣。此外,在应对虚假新闻方面,通过图分析方法中的遍历算法能够深度追溯到该新闻的根源。
徐明,上海观安创新研究院工程师,研究方向为大数据安全技术、网络安全。
魏国富, 上海观安创新研究院副院长, 研究方向为大数据安全技术、网络安全、数据安全。
殷钱安,上海观安创新研究院总监,研究方向为数据安全、网络安全、新技术新应用安全监管。
选自《信息安全与通信保密》2019年第十期
声明:本文来自信息安全与通信保密杂志社,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
