本文作者:lorenzwang ,腾讯 TEG 安全工程师
常见的中文 NLP 下游任务一般都是以分词作为起点(以 transformer 为核心的算法除外),对每个词取 embedding,作为模型的输入。不过在黑灰产领域,这种处理方法有一个问题:大量的黑话/黑词对于下游任务非常有效,但却不在通用的词典中,导致分词器无法准确切分出对应的词。比如,今年 315 晚会曝光的“714 ”,再比如“口子”。以及本人参加新人培训时讲师提的一些 00 后常用词,“扩列”, “暖说说”。
笔者所在的防水墙团队整合了多源异质数据,在黑产人群识别、威胁渗透、黑产对抗等场景具备行业领先的能力。作为黑灰产能力建立的基础,行话/黑词的识别显得至关重要。本文将介绍一些我们在新词发现及一词多义上的解决方案。
1 新词发现
新词发现方法较多,本文将介绍一种比较简单且有效的新词发现方案:自由度+凝固度。
我们首先来定义一个问题:
怎样的字符可以组成一个中文语义下的“词”
1.1 具有比较丰富的上文、下文
词作为中文一个基本的语义单元,具备一个比较显著的特征:可以比较灵活的应用到不同场景中。比如说“机器学习”这个词,上下文均可以搭配很多动词和名词,“学习人工智能知识”, “从事人工智能行业”, “选修人工智能课程”,“基于人工智能 xx”,“人工智能赋予了 xx”, “人工智能识别了 xx”,“人工智能实现了 xx”。但是对于“人工智”这个词来说,上文依然可以搭配很多词语,可是下文基本上只能搭配“能”了。
再比如笔者的家乡:临沂。“住在临沂”,“建设大美临沂”, “临沂煎饼”, “临沂机场”都存在丰富的上文、下文,但是对于“沂”(友情提示:yi, 二声),下文可以接“煎饼”, “机场”, “人”,但是上文则大概率只有“临”,以及其他几个很少的字。
写到这里,各位读者可以自己自己考虑下一些常用词是否符合这一点。
上文和下文的丰富程度可以用信息熵来度量:
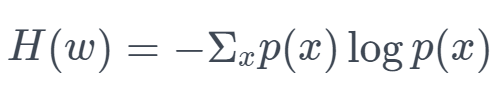
熵是一种表示信息量的指标,熵越高意味着不确定越高,越难以预测
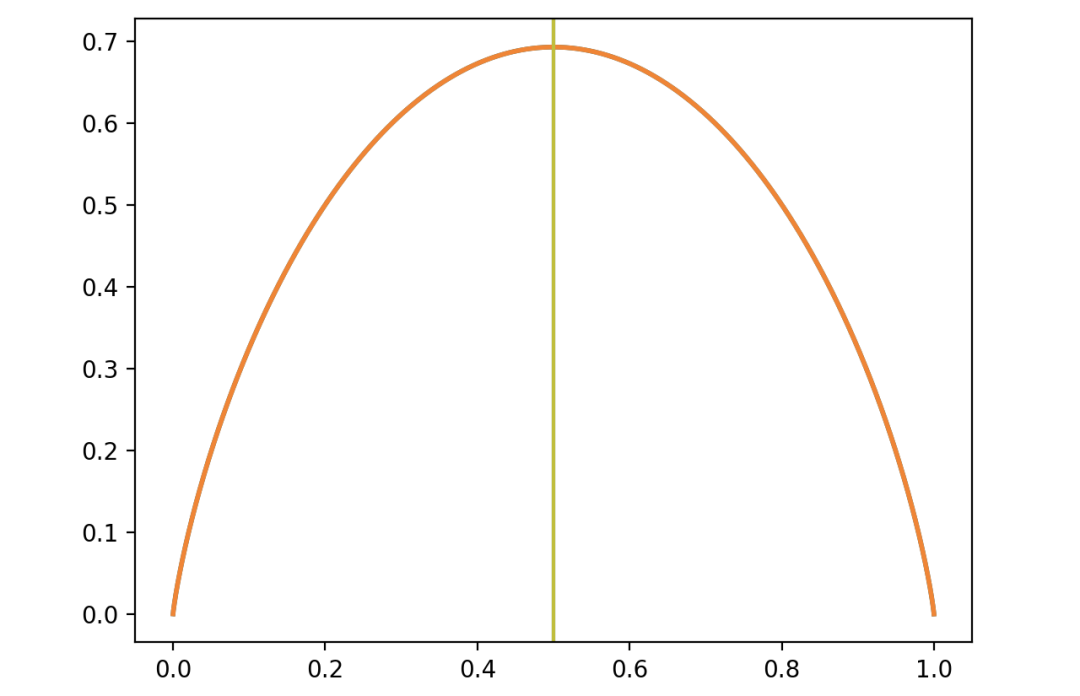
让我们用一个实际的例子来感受下。假设我们有一个硬币,每次抛起来之后正面向上的概率为 x, x  range(0, 1, 0.1):
range(0, 1, 0.1):
x取值与熵的关系
从图中可以看出,当正面向上的概率 x=0 或 x=1 时,熵=0,因此此时随便抛一次硬币我们都可以准确的预测到正面是否朝上。熵的最大值发生在 x=0.5 处,x=0.5 时我们预测准下一次抛硬币时正面向上的概率最小。
对应到词的上文和下文,对于那些上文(下文)不丰富的词来说,我们可以比较大概率的预测准词的上文或下文,比如“珠穆朗”这个词,它的下文大概率是“玛”, 比如“沂”这个词,它的上文大概率是“临”,对于“珠穆朗”,我们称它的右信息熵比较小(信息熵越小,则确定性越高),对于“沂”这个词,我们称它的左信息熵比较小(信息熵越小,确定性越高)。
词的上文和下文越丰富,则其左信息熵(右信息熵)越大。一般来说,我们取左右信息熵中的最小值(考虑下这是为什么)。
1.2 词的内部凝聚度要足够高
上面提到说对于一个合格的词语而言,需要具有丰富的上下文(不然就没必要作为一个基本的不可划分的语义单元了),但满足了这一点就可以了嘛?让我们来看一个例子。
小明在学校看了小红的演唱会
其中,“在学校”几乎百搭,“的演唱会”也是,不信来看:
xx/在学校/xx:他在学校经常捣乱、美术展在学校美术馆举办
xx/的演唱会/xx:周杰伦的演唱会棒极了、成功的演唱会太难了
但是“在学校”和“的演唱会”很明显不是我们直觉上的词,为什么会出现这种情况?因为“在”和“的”在中文中出现的太频繁了(“的太频繁”是不是也符合拥有丰富的上文、下文这一点?)
很明显,合格的词不仅要在外部有丰富的上文、下文,其本身内部也要满足一定的条件。上面我们讲过,词是一个基本的语义单元,意味着一般情况下不应该继续细分了,这也就意味着词内部要比较稳固或者内部凝固程度比较高。稳固意味着不可分,不可分如何衡量?
先说结论,我们用(点间)互信息衡量词内部的凝聚程度:
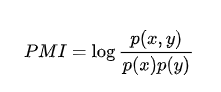
公式最右边是 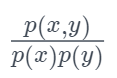 , 假如 x 和 y 完全独立,
, 假如 x 和 y 完全独立,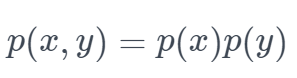 ,上面公式=0。
,上面公式=0。
假如有一篇介绍临沂的文章,总共有 100 个字,其中,临沂出现 1 次,临出现一次,沂出现一次,那么 p(临,沂)=1/100, p(临)=1/100,p(沂)=1/100,
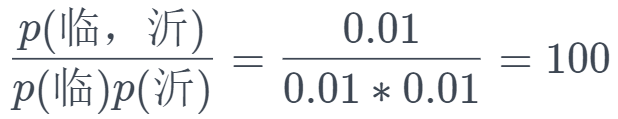
我们可以看到“临沂”这个词内部还是比较稳固的,向心力比较强,离心力很小
1.3 总结
基于上述两点,我们可以得出如下结论:词之所以成词,其外部需要有比较丰富的上文和下文,其内部要足够稳固一般不可再分。
因此我们可以设计如下指标:

基于文本选取合适的 score,也可以分别取左熵,右熵,PMI 的阈值对词进行筛选。
1.4 新词发现流程
生成候选词
这一步我们将文本按字分割后拼接为二元组,三元组,…,k 元组(一般 k <= 5),如“新词发现及一词多义的解决方案”对应的二元组有:[“新词”, “词发”, “发现”, “现及”, “及一”, “一词”, “词多”, “多义”, “义的”, “的解”, “解决”, “决方”, “方案”]。
在这一步如果采用现有的分词工具进行分词会导致很多词可能在这一步就被拆分开了,对应的词后续无法被识别到。
候选词得分计算
针对上述的每一个词,我们都计算对应的 score 或者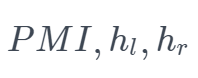 ,然后基于特定的阈值进行筛选即可得到新词。
,然后基于特定的阈值进行筛选即可得到新词。
将新词加入到分词器的词典中
将通过上述步骤得到的词加入到分词器的词典中,如在 jieba 中采用如下方式:
jieba.add_word("德玛西亚")后续采用这个分词器进行分词时,相应的新词
计算得到每个词的 embedding vector
可以采用诸如 word2vec, glove, bert 之类的任意算法
基于种子黑词,计算新词(或所有词)与种子黑词的相似度,筛选得到黑词
比如种子词选取毒品,最终发现“溜冰”这个原本看似人畜无害的词与毒品相关的种子词相似程度均很高,即可推测自己发现了一个该领域的新词。
2 一词多义
首先让我们来看一下例子:
溜冰
对于那些天真无邪的同学来说,溜冰就是在冰上溜来溜去。
对于那些了解世事的同学来说,溜冰就是在冰上溜来溜去。
只不过,「此冰非彼冰,此溜也非彼溜」 。
和 714 、扩列、暖说说这种需要新词发现才能识别的新词不同(严格来说现在扩列已经成为通用词了),溜冰是现有的词,只是在特定的场景下意义发生了变化。如下面两句:
周末和小伙伴一起去溜冰
周末和小伙伴在出租屋溜冰
nlp 任务的输入一般是词的 emb vector, 上一步完成新词发现保证黑词/行话能够被正常发现后我们可以对分词后的文本进行嵌入。
word2vec 生成的静态词嵌入无法解决一词多义问题,BERT 等虽然可以解决一词多义,但是对于单纯的新词发现任务/黑词扩散等任务来说显得有点多此一举了。因此我们在这个 bert 已经大杀四方的时候选择了尝试 ELMo.
2.1 什么是静态词向量
静态词向量的生成过程:训练 language model,将 language model 中预测的 hidden state 作为 word 的表示。给定 N 个 tokens 的序列(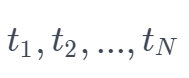 ),前向 language model 就是基于前 k-1 个输入序列去预测第 k 个位置的 token,训练目标即:
),前向 language model 就是基于前 k-1 个输入序列去预测第 k 个位置的 token,训练目标即:

像常见的 word2vec, glove 生成的都是静态词向量。但是比较反常识的是,word2vec,glove 这些对每个词都会生成一个确定的 emb vector。
对于前面我们提到的“溜冰”,不同语境下很明显其 vec 应该不同
2.2 ELMo 的解决方式
ELMo 不再得到词的确定的 emb vec, 而是得到一个训练好的 language model(以下用 LM 代指,切记不是 likelihood maximization)。这个 LM 会基于给定的上下文“动态的”生成每个词的嵌入。
这里再啰嗦几句。
从结果上看,我们最终生成的 emb vec 肯定是常量而不是随机量。
这里的动态指的是每次输入不同的 context,嵌入都会不同,从过程上看嵌入是动态的。ELMo 本身是个根据上下文对 emb 动态调整的思路。
所以,ELMo 采用了典型的两阶段过程,第一阶段利用语言模型进行预训练,第二阶段是在做下游任务时,从预训练语言模型中提取对应单词的 emb 作为新特征补充道下游任务中。
上文之所以写这些是因为,我们刚开始具体在用 ELMo 的时候,忽略了第一和第二阶段,以为可以直接把第一阶段训练得到的语言模型中的单词的 emb 拿出来作为 ELMo 的产出,实际不是的。第一阶段训练完毕后,虽然每个单词也有一个 emb,但是这个 emb 只是一个中间产物,直接拿来用效果会差到难以想象(痛彻心扉!!)
本文不赘述 ELMo 的理论,下面两部分将分别讲述 ELMo 的预训练和实际应用。
2.3 ELMo 第一阶段 -- ELMo 预训练
先上源码,步骤:
新词发现及分词并训练 w2v 词向量,得到词向量 emb,语料 corpus 和词表 vocab
修改代码
训练模型,vocab_embedding.hdf5
得到 model weights
2.3.1 新词发现及分词部分
类比我们在本文第一部分的工作,先进行新词发现,将发现的新词加入到分词的词表,进行分词操作。
1)词向量部分
伪代码:
for item in new_words:
jieba.add_word(item)
stopwords = ...
df_mid = df.rdd.flatMap(lambda x: jieba.lcut(x)).toDF(["sentence"])
w2v = Word2Vec(vectorSize = , inputCol = "sentence")
model = w2v.fit(df_mid)
word_df = model.getVectors()
上面操作可以得到词的 w2v 词向量。由于后续词表需要按词频从高到低排列,并且词表中的词需要和词向量中的嵌入向量一一对应,因此这里得到嵌入词向量之后,需要把词向量文件按照词频从大到小进行排序。
词向量文件开头第一行分别是词数和词向量维度,形式如下:
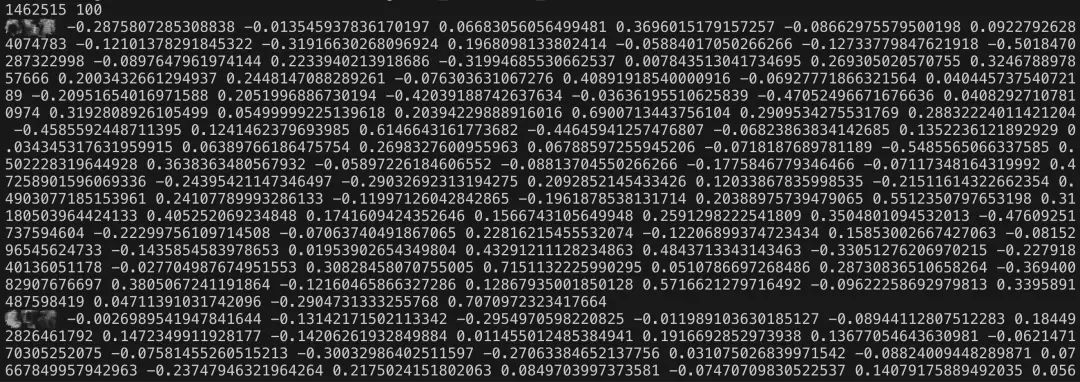
图中全部的分隔符都是空格,不是"\t"
2)语料。corpus 是分词后的语料,每一行是一个 string, 用空格分隔:


3)词表。得到词向量部分对应的词,词需要按照在语料中的词频从高到低排列。鉴于我们在 1)中已经把词向量按照词频排序了,这里只需要把词拿出来单纯保存即可。
词表开头必须是<S\>, </S\>, <UNK\>,且大小写敏感,形式如下:

1)和 3)部分的代码如下:
with open("trans_data/word_vectors","r", encoding="utf-8") as f:
with open("trans_data/vectors.txt", "w", encoding="utf-8") as fout:
fout.write(str(word_count) + " " + str(dim) + "\n")
with open("trans_data/vocab.txt", "w", encoding="utf-8") as fvocab:
fvocab.write("<S>")
fvocab.write("\n")
fvocab.write("</S>")
fvocab.write("\n")
fvocab.write("<UNK>")
fvocab.write("\n")
for line in f:
x = line.split("\t")
tmp = x[1]
tmp = tmp.strip("")
tmp = tmp.lstrip("[")
tmp = tmp.rstrip("]\n")
tmp = tmp.replace(",", " ")
vocab.append(x[0])
item = x[0] + " " + tmp + "\n"
fout.write(item)
fvocab.write(x[0] + "\n")
2.3.2 修改代码
├── bilm # 模型文件目录
│ ├── __init__.py
│ ├── data.py # 数据准备入口
│ ├── elmo.py # 加总elmo不同层得到输出
│ ├── model.py # 双向语言模型结构文件
│ └── training.py # 模型架构
├── bin # 训练文件目录
│ ├── dump_weights.py
│ ├── restart.py
│ ├── run_test.py
│ └── train_elmo.py # 训练入口
├── test
│ ├── test_data.py
│ ├── test_elmo.py
│ ├── test_model.py
│ └── test_training.py
└── usage_token.py # 示例
最重要的几个文件是 bilm/training.py, bin/train_elmo.py
1)修改训练参数 bin/train_elmo.py

实际应用主要修改以下参数:
1.batch_size
2.epoch
3.n_gpus and cuda_visible_devices
4.n_train_tokens
5.projection_dim,决定了elmo输出向量的维度
2)修改 bilm/training.py 中的 LanguageModel 类
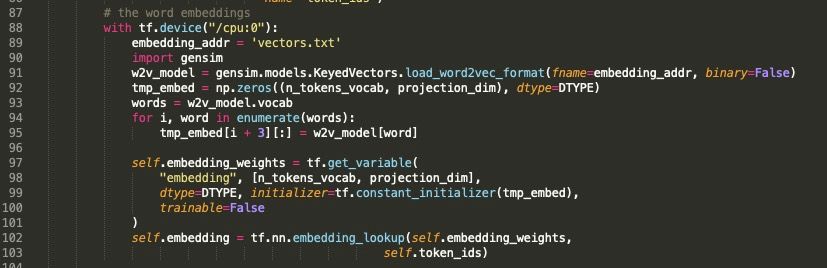
将上面生成的词的 w2v 向量通过initializer = tf.constant_initializer(tmp_embed)传进去,随后通过 embedding_lookup 查表对应到批次内的词
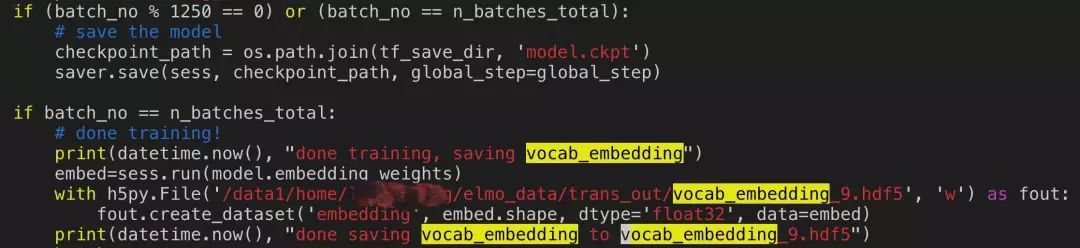
3)保存 embedding 用于第二阶段
4)输出训练 loss
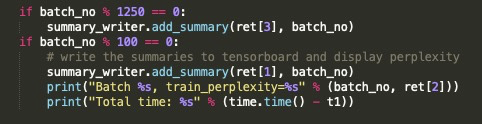
初始代码中并未输出每个 batch 对应的 loss,导致开始的时候无法判断模型是否收敛,毕竟简单的解决方案是周期性的在日志中打印 train_perplexity
5)打印更多信息
原始代码并未输出详细的训练信息,建议在一些关键步骤上打印相应信息,后续调优等操作可以有的放矢。

2.3.3 训练模型,得到 vocab_embedding.hdf5
nohup python3 -u bin/train_elmo.py \--train_prefix="/data/home/xxxx/elmo_data/trans_data/corpus.txt" \--vocab_file /data/home/xxxx/elmo_data/trans_data/vocab.txt \--save_dir /data/home/xxxx/bilm-tf/output_dir > /data/home/xxxx/bilm-tf/output_dir/bilm_out.txt 2>&1 &
其中,
nohup: 退出 shell 不退出进程train_elmo.py: 主程序入口train_prefix: 语料路径vocab_file: 词表路径save_dir: 训练日志、checkpoint、options.json 输出路径
输出文件如下:

不过,训练完之后我们还得到了一个最重要的输出:vocab_embedding.hdfs(参见 2.3.2 中的第三部分)
2.3.4 得到 weights.hdf5
上面一步计算得到了 ckpt 文件,下面进一步得到 model weights
nohup python3 -u bin/dump_weights.py \--save_dir /data1/home/xxxx/bilm-tf/output_dir \--outfile /data1/home/xxxx/elmo_data/trans_out/weights.hdf5 > /data1/home/xxxx/elmo_data/trans_out/bilm_out_weights.txt 2>&1 &
save_dir: 上面保存 ckpt 的路径
outfile: model weights 输出路径
2.3.5 总结
vocab_embedding 是 vocab 的一个初始嵌入,不是 ELMo 的最终输出!不是 ELMo 的最终输出!不是 ELMo 的最终输出!
weights.hdf5 是 language model 的系数
有了:
vocab_embedding.hdf5
weights.hdf5
options.json
就可以把 ELMo 用起来了!
BTW:训练过程中,总共有 93246334 条语料(文本比较短,且对分词后的文本进行了过滤,平均文本长度大概在 10 个词),峰值 cpu 占用 50g,4 张 Tesla K40m 跑 80 个 epoch 需要 10 个小时。
2.4 ELMo 第二阶段 -- 得到语料的 ELMo embedding
2.4.1 训练代码及过程
源码中的 usage_token.py 是 ELMo 第二阶段的示例,不过例子并不好,可以基于这个示例进行改写。下面提供一个伪代码:
import tensorflow as tfimport osimport numpy as npfrom bilm import TokenBatcher, BidirectionalLanguageModel, weight_layers, dump_token_embeddings# 根据实际情况进行修改vocab_file = "/data/home/xxxx/elmo_data/trans_data/vocab4.txt"options_file = "/data/home/xxxx/bilm-tf/output_dir/options.json"weight_file = "/data/home/xxxx/elmo_data/trans_out/weights_8.hdf5"token_embedding_file = "/data/home/xxxx/elmo_data/trans_out/vocab_embedding_8.hdf5"tokenized_context = [["吸毒", "溜冰", "贩毒", "吸毒", "贩毒", "吸毒", "毒品", "吸毒"],["定期", "组织", "吸毒", "活动", "贩毒", "制毒", "毒品", "情况", "溜冰", "吸毒"],["星期天", "中午", "组队", "体育场", "文化宫", "溜冰", "热爱", "轮滑", "溜友", "踊跃报名", "参加"]]
# Create a TokenBatcher to map text to token ids.batcher = TokenBatcher(vocab_file)# Input placeholders to the biLM.context_token_ids = tf.placeholder("int32", shape=(None, None))# Build the biLM graph.bilm = BidirectionalLanguageModel(options_file,weight_file,use_character_inputs=False,embedding_weight_file=token_embedding_file)# Get ops to compute the LM embeddings.context_embeddings_op = bilm(context_token_ids)elmo_context_output = weight_layers("output", context_embeddings_op, l2_coef=0.0)with tf.Session() as sess:# It is necessary to initialize variables once before running inference.sess.run(tf.global_variables_initializer())# Create batches of data.context_ids = batcher.batch_sentences(tokenized_context)# Compute ELMo representations (here for the output).elmo_context_output_ = sess.run(elmo_context_output["weighted_op"],feed_dict={context_token_ids: context_ids})print("elmo_context_ouput_:")print(elmo_context_output_.shape)print(elmo_context_output_)# ------------------------elmo_context_output才是elmo真正的输出------------------------------## sentences similaritiesd1, d2, d3 = elmo_context_output_.shape# d1 = 3, d2 = 11, d3 = 128, d2=所有sentences中最大长度# 维度128 = projection_dim * 2(因为elmo会把前向和后向语言模型concat起来,所以最终生成的维度是128)group_vector_output = np.array([]).reshape(0, 128)for i in range(d1):tmp_vec_out = np.sum(elmo_context_output_[i, :, :], axis=0) # 把每个句子中所有token的emb加总起来sentence_vector_output = np.vstack([sentence_vector_output, tmp_vec_out])print(str(i)+"th sentence_vector_output: ")print(sentence_vector_output)print("output result")# 接下来计算三个句子间的similaritiesfor i in range(d1):vec1 = sentence_vector_output[i, :]for j in range(i+1, d1):vec2 = sentence_vector_output[j, :]num = vec1.dot(vec2.T)denom = np.linalg.norm(vec1) * np.linalg.norm(vec2)cos = num / denomprint(str(i)+ " " + str(j) + " " + str(cos))# 接下来计算三个句子中“溜冰”这个单词的相似度# elmo_context_output_[0, 1, :]对应第一个句子中的第2个token,# elmo_context_output_[1, 8, :]对应第二个句子中的第9个token,# elmo_context_output_[2, 5, :]对应第三个句子中的第6个token,# 正好分别对应着各自句子中溜冰的位置print("0 1")num = elmo_context_output_[0, 1, :].dot(elmo_context_output_[1, 8, :].T)denom = np.linalg.norm(elmo_context_output_[0, 1, :]) * np.linalg.norm(elmo_context_output_[1, 8, :])print (num / denom)print("1 2")num = elmo_context_output_[1, 8, :].dot(elmo_context_output_[2, 5, :].T)denom = np.linalg.norm(elmo_context_output_[1, 8, :]) * np.linalg.norm(elmo_context_output_[2, 5, :])print(num / denom)print("0 2")num = elmo_context_output_[0, 1, :].dot(elmo_context_output_[2, 5, :].T)denom = np.linalg.norm(elmo_context_output_[0, 1, :]) * np.linalg.norm(elmo_context_output_[2, 5, :])print(num / denom)
输出:
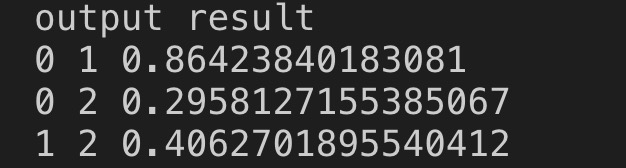
上图表示的是三个句子两两之间的相似度:

上图表示的是三个句子中溜冰之间的相似度,可以看出第一和第二个句子中的溜冰相似度最高,1 和 3, 2 和 3 中溜冰的相似度都会低一些,初步看符合我们的预期。
假如上述代码为 sen2vec.py,这一步只需要运行
python3 sen2vec.py2.4.2 小结
实际应用中可以把候选文本都过一遍 elmo,将生成的 emb 存到 hadoop 表里面,随时调用效率会比较高。
另外可搭配上述新词发现使用,效果更佳。
Reference:
声明:本文来自腾讯技术工程,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
