作者 中国农业银行研发中心
吕俊锋 陈宏晓 张诚 秦雷
NLP即自然语言处理,是计算机科学领域与人工智能领域中的一个重要方向,随着不断的发展,自然语言处理技术已经越来越成熟。在银行领域,数据分析大多集中在客户行为分析、营销预测、风险管理等数值分析方面,对于文本处理相对较少。随着AI技术平台的日趋完善,NLP技术在银行领域的应用也逐渐崭露头角。本文将介绍NLP技术在农业银行信用卡风险管理领域的落地应用,包括地址比对验证、高危风险地址库构建场景。
一、相关背景
随着商业银行数字化转型的推动,在业务飞速发展的过程中沉淀了海量数据,因此,加大数据领域探索,深入挖掘海量数据所蕴含的巨大潜在价值,成为当前银行从业人员的共识。
近年来,农业银行大数据体系不断发展,大数据平台汇总的数据逐渐完善,几乎囊括了全行重要系统的数据,因而打破各个系统间的数据壁垒,成为了支撑业务发展的的新引擎。银行业日趋激烈的竞争,也促使业务人员将精力更多地聚焦在数据价值的挖掘上,例如信用卡发卡精准营销预测,使得年新增发卡量两年翻了一番;基于大数据的行内评分模型,使得信用卡新增不良率降低了45%。在这些数据分析挖掘模型落地实施的带动下,业务纷纷转向该领域,期待转型带来的新突破。
在技术的推动下,业务对数据分析挖掘的需求量呈井喷式增长,要求也越来越高,特别是非结构化文本数据的处理需求。以往的数据分析大多集中在客户行为分析、营销预测、风险管理等数值分析方面,对于文本处理相对较少。为了支撑业务对非结构化文本分析的需求,NLP平台应运而生。基于NLP平台,能够使非结构化文本的处理的问题得以高效解决。
二、NLP平台概况
NLP平台引擎承接了行内所有的非结构化文本数据分析挖掘需求,向开发者提供了丰富的算子、训练环境以及运行环境,打通模型从训练、发布到集中运行的全流程。NLP平台架构如图1所示。
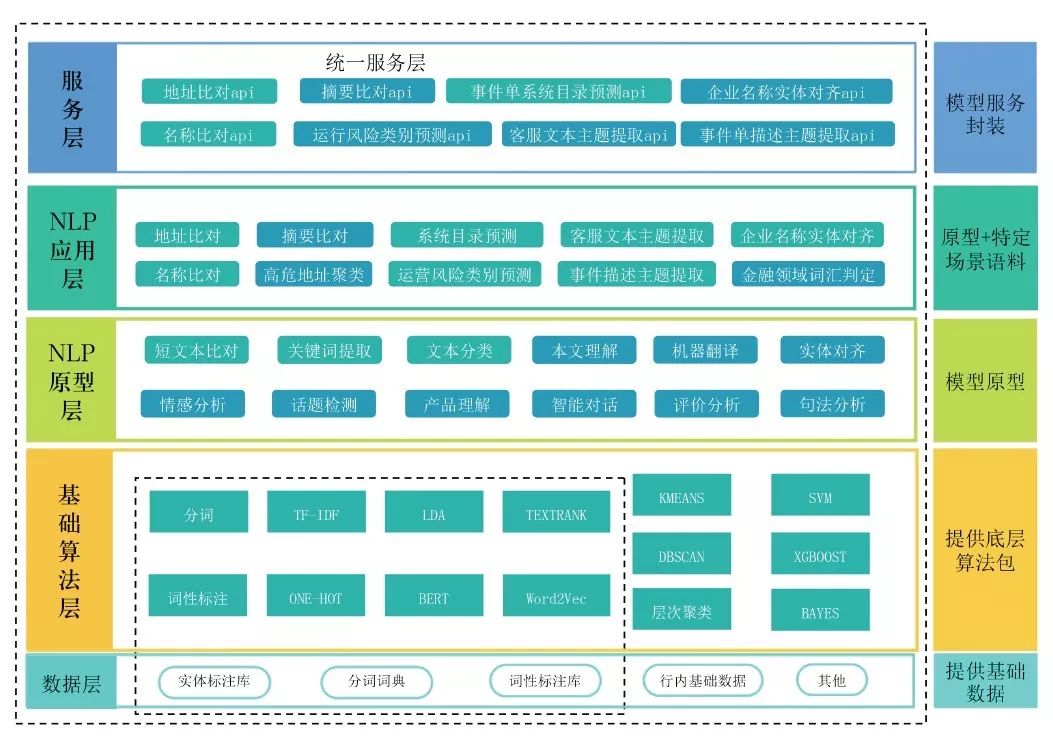
图1 NLP平台架构
NLP引擎由五层构成:
数据层,包含非结构化数据,以及标注的预料库,为模型提供数据来源;
基础算法层,包含分词、词向量算法、词性标注等NLP基础算法;
NLP原型层,对建模过程提取、抽象、封装,形成可复用的步骤以及流程,加速建模过程;
NLP应用层,原型+数据构成了应用层,即在原型的基础上对数据进行训练,形成面向特定领域的应用;
服务层,对应用功能进行封装,形成对外提供服务的API,支持其他应用的接入。
NLP平台五层架构,面向三类客户提供不同服务(如图2所示)。
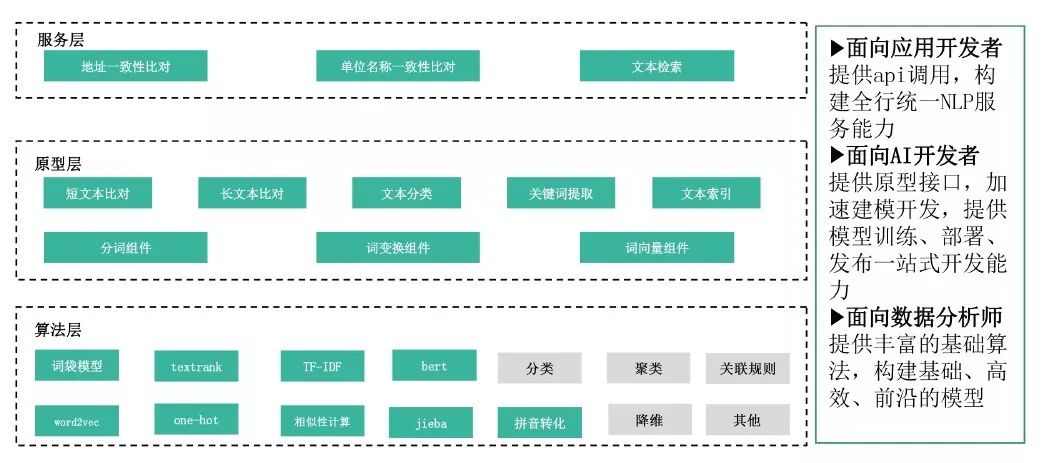
图2 NLP平台提供的三种能力
面向数据分析师提供丰富的基础算法,构建基础、高效、前沿的模型;面向应用开发者,提供原型接口,加速模型开发,提供模型训练、部署、发布一站式开发能力;面向应用系统,提供API调用,构建全行统一的NLP服务能力。
三、应用场景
我们能够标识客户的金融财产,能够预测客户的交易行为,但对于客户的地址信息等非结构化数据的相关分析变得十分困难。实际上,客户的很多行为都隐藏在地址信息中:如客户的风险存在集中性,即存在某一地址区域频繁逾期现象;又如客户存在团办欺诈行为。对此,我们基于NLP技术对地址信息进行了深入的分析挖掘,完成了几个场景的落地实施。
1.地址比对
在银行的业务体系中,特别在审批流程中,需要做大量的文本比对工作,尤其是家庭地址、单位名称。而这些比对现阶段主要依靠人工进行审核,一方面效率低下,另一方面出错率较高。利用NLP技术对文本信息进行模糊比对,能够解决这些问题,从而提升业务审批效率。
在地址信息中,由于填写人并没有按照统一规范进行填写,因而对地址信息进行直接比对效果欠佳。我们先对地址进行预处理,根据省市代号等信息,对数据进行地址层级三级分类(即省、市、区),缩小地址的比对范围。
在对地址进行划分后,对地址进行切词,将地址细分为单词进行比较。现在的主流分词采用N-gram法、隐马尔科夫模型、最大熵模型以及条件随机场等模型,一般而言直接切分效果不会理想。因而我们引用了开源地址库以及常用停用词库,以此提升分词的准确性。此外,考虑到地址会经常出现错别字的情况,最后我们会将词转换成拼音以消除错别字的干扰。分词优化过程如图3所示。
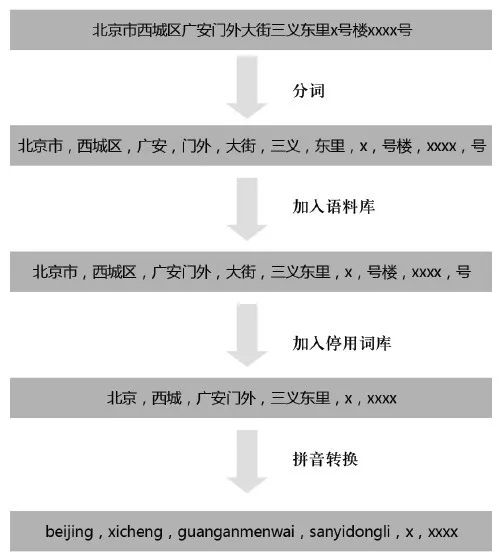
图3 分词优化过程
在分词之后,会对其进行向量化并计算其相似性。我们通过比对one-hot、tf-idf、Word2Vec多种向量化表示,以及余弦相似性、Jaccard、BM25计算相似性,并评估适用于我行,数据效果最好的方式。地址比对流程如图4所示。
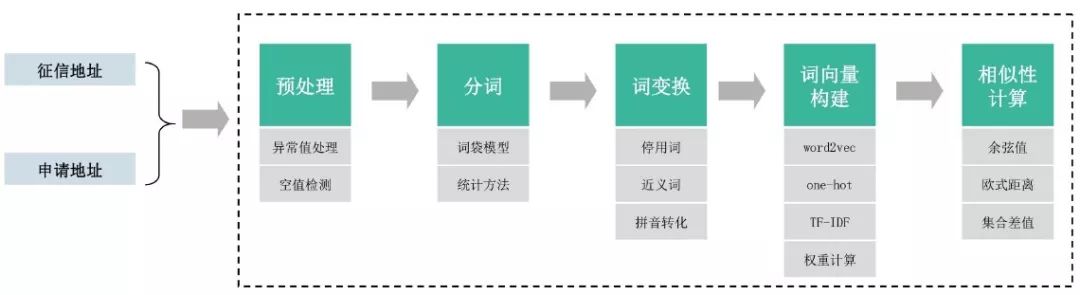
图4 地址比对流程
为了验证比对的准确性,我们对将近12000对地址进了人工标注,根据地址对的相近程度标注了5个层级:一致、大体一致、模糊、无法确定、不一致(见表1)。
表1 地址比对验证结果
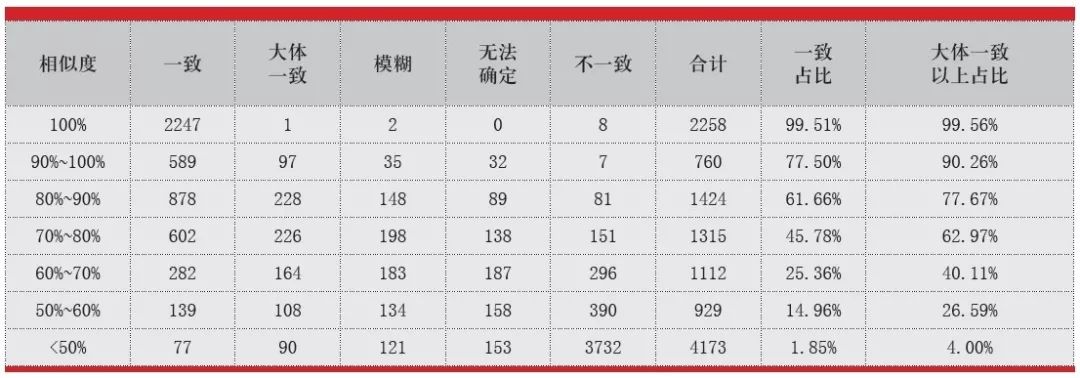
通过比对实际跑出的结果与标注的结果,人工标注为大体一致与一致的与相似度90%以上高度重合,准确率97.2%(加权),人工标注为模糊、无法确定、不一致的与相似度在50%以下的高度重合,准确率为96%。相似度在90%以上以及相似度在50%覆盖了六成客户,可认为目前60%以上的地址比对工作可以通过自动化的比对流程来实现。
目前该应用已经应用在信用卡调查审批环节,是农业银行首个自主研发并投产应用的NLP模型,模型准确率达80%以上,填补了农业银行地址比对工具的空白。
目前地址比对功能已接入信用卡贷前准入流程,对每日数万笔的信用卡申请进件进行地址信息异常变动监测,为后续的针对性风控处置提供了业务参考。
2.高危地址库生成
对信用卡历史逾期客户进行分析,可以知道风险具有集中性,即大部分的逾期客户都集中在少量的地址区域中,所以客户的地址属性在很大程度上反映了客户的风险等级。以城市为单位、以地址区域为维度进行风险监控,能够极好地预测客户的风险。这个问题最关键就是如何找出高危地址区域。高危地址区域指该地址区域内逾期的客户数,当该区域的地址逾期客户数达到一定的数据,我们就认为该地址是高危地址区域。
地址的逾期客户数反映了这个地址的风险级别,当该地址的逾期客户数到达一定的数量,我们就可以认为该地址是高危地址。地址是个精确概念,而地址范围是个区域概念,实际上,评估一个地址区域的风险程度更具备代表性,因此高危地址库就是找出高危地址区域。
我们整理了国家邮编库,该库对地址进行了五级分类。五级标准地址库见表2。我们将地址基于五级标准分类进行初步分类,以某省的3个城市为例见表3。
表2 五级标准地址库样例
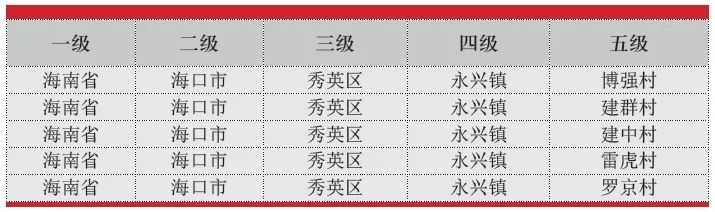
表3 某省初步聚类结果

绝大部分的地址都能够匹配到区级别(第三级),达到了95%以上,区级别以下匹配度准确度为85%,仍有15%的地址无法正确划分,需要进一步进行划分。
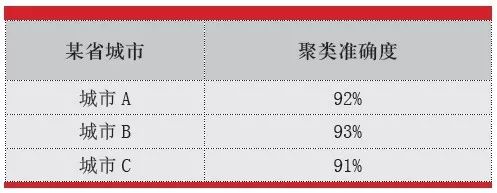
经过上一步将地址划分到区级别,现对分到同一个区下的地址进行进一步聚类。采用Kmeans、DBScan以及层次聚类方式进行进一步细分。我们对最终的结果进行了抽样统计。随机抽取10000个地址,统计聚类错误的数量占比,进而得到每个城市聚类的准确度。聚类错误的数量占比=地址非所在类别的数量/总地址数量。以聚类的准确度作为评价聚类效果的指标。我们通过综合评估聚类算法的效率、轮廓系数以及聚类效果,最终选择KMEANS算法。聚类的准确度有了显著的提高,且各个类的分布更加均衡(见表4)。
表4 某省最终聚类结果
高危地址库生成流程如图5所示。
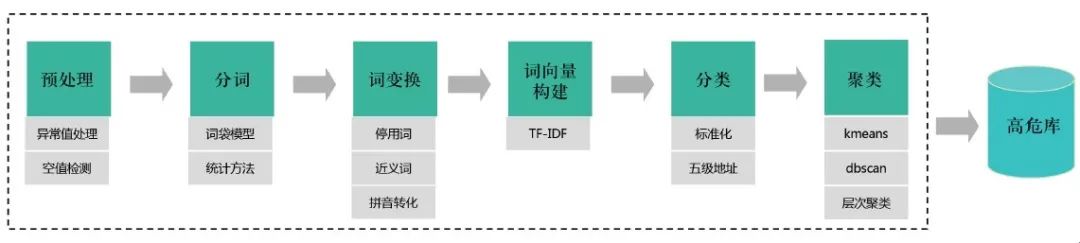
图5 高危地址库生成流程
我们以上述聚类结果为单位进行分析,即以地址片区为单位,将之看成一个整体进行分析,剔出数量少的地址区域,统计地址区块的风险逾期情况。生成的数据包含城市名、地址数量、聚类后地址数量、聚类包含平均地址数、逾期占比、风险集中度等情况。
仍以某省城市A为例,城市A的各个区的风险逾期具备显著的集中性,即各个区出现逾期的地址片区仅占总地址片区的8%。这些地址片区具有较强的风险区分能力,能够非常好地反映客户的风险等级,因而对这些地址进行提取,形成高危风险库,与新申请的客户地址进行匹配,从而识别客户风险。
高危地址库服务对外服务流程如图6所示。对这些风险库进行存储,采用分词后建立索引并存储(基于ElasticSearch),利用模糊比对技术对风险库中的数据进行实时检索。对于一笔新申请,可通过实时查询是否命中高危库,在贷前进行风险识别。

图6 高危地址库服务对外服务流程
目前,该应用也应用在了信用卡调查审批环节。通过对高危风险地址库的有效拦截,显著提升了农业银行信用卡风险管理水平。
四、展望
通过对NLP技术的探索,我们完成了农业银行日前首个自主研发的NLP应用项目的落地投产。该项目有效地提升了农业银行信用卡风险管理水平与反欺诈能力,为农业银行AI自研之路奠定了良好的基础。
后续,我们将继续探索NLP技术的研究,形成探索、开发、训练、投产、后评价全流程体系,以支持全行的NLP服务,打造面向全行的NLP引擎,推动NLP引擎向着组件化、原型化、服务化、平台化的建设目标迈进。
(1)组件化:不断丰富基础层算法模型,依托AI平台,向资深数据分析人员提供最新、最全的原生组件。
(2)原型化:自上而下,对已实现场景进行提炼,对算法进行组装与封装,沉淀形成资产,面向应用开发人员提供原型,避免重复造车,提高应用开发效率。
(3)服务化:将服务能力API化,为全行应用系统提供统一实时、批量服务能力,高效实现系统接入。
(4)平台化:依托AI平台,向开发人员提供多层次、全方位、流程式、一站式开发部署服务。
《中国金融电脑》2019年第 11 期
声明:本文来自中国金融电脑,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
