
蚂蚁金服云原生负责人鲁直 双十一后首次线下分享
引言
Service Mesh 是蚂蚁金服下一代架构的核心,本主题主要分享在蚂蚁金服当前的体量下,我们如何做到在奔跑的火车上换轮子,将现有的 SOA(service-oriented architecture,面向服务的架构)体系快速演进至 Service Mesh 架构。聚焦 RPC 层面的设计和改造方案,本次将分享蚂蚁金服双十一核心应用是如何将现有的微服务体系平滑过渡到 Service Mesh 架构下并降低大促成本。
蚂蚁金服每年双十一大促会面临非常大的流量挑战,在已有 LDC(Logical Data Center,逻辑数据中心,是蚂蚁金服原创的一种“异地多活单元化架构”实现方案)微服务架构下已支撑起弹性扩容能力。
本次分享主要分为 5 部分:
Service Mesh 简介;
为什么要 Service Mesh;
方案落地;
分时调度案例;
思考与未来;
作者简介

黄挺(花名:鲁直):蚂蚁金服云原生负责人 主要 Focus 领域:
SOFAStack 微服务领域;
Service Mesh,Serverless 等云原生领域;
雷志远(花名:碧远):蚂蚁金服 RPC 框架负责人 主要 Focus 领域:
服务框架:SOFARPC(已开源);
Service Mesh:MOSN(已开源);
SOFARPC:https://github.com/sofastack/sofa-rpc
MOSN:https://github.com/sofastack/sofa-mosn
Service Mesh 简介
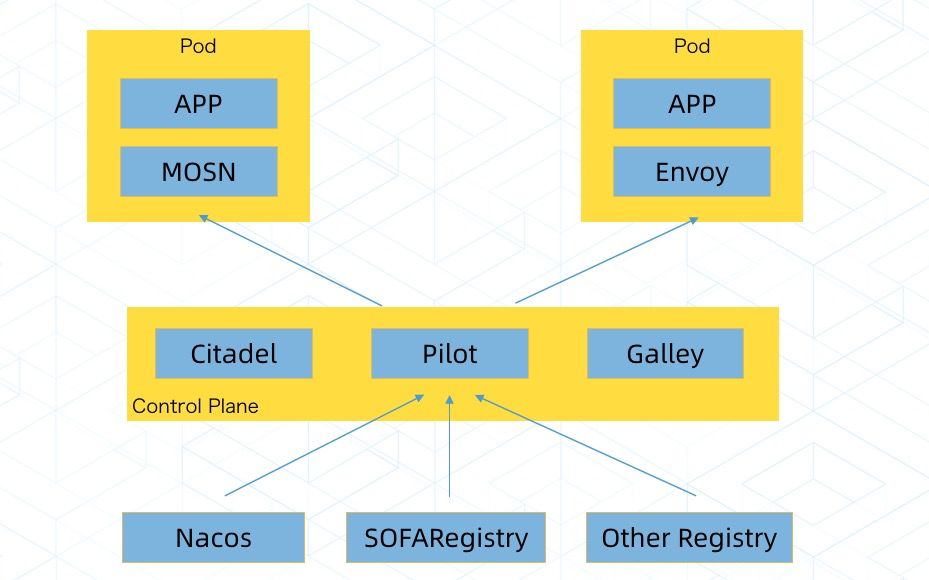
在讲具体的蚂蚁金服落地之前,想先和大家对齐一下 Service Mesh 的概念和蚂蚁金服对应的产品。这张图大家可能不陌生,这是业界普遍认可的 Service Mesh 架构,对应到蚂蚁金服的 Service Mesh 也分为控制面和数据面,分别叫做 SOFAMesh 和 MOSN,其中 SOFAMesh 后面会以更加开放的姿态参与到 Istio 里面去。
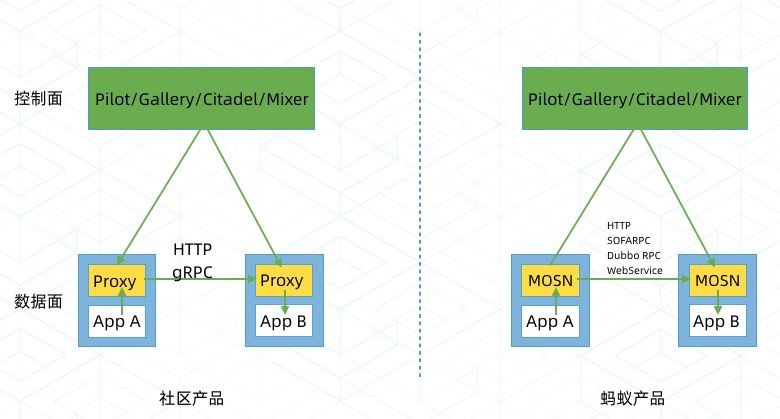
今天我们讲的实践主要集中在 MOSN 上,以下我的分享中提到的主要就是集中在数据面上的落地,这里面大家可以看到,我们有支持 HTTP/SOFARPC/Dubbo/WebService。
为什么我们要 Service Mesh
有了一个初步的了解之后,可能大家都会有这样一个疑问,你们为什么要 Service Mesh,我先给出结论:
因为我们要解决在 SOA 下面,没有解决但亟待解决的:基础架构和业务研发的耦合,以及未来无限的对业务透明的稳定性与高可用相关诉求。
那么接下来,我们一起先看看在没有 Service Mesh 之前的状况。
在没有 Service Mesh 之前,整个 SOFAStack 技术演进的过程中,框架和业务的结合相当紧密,对于一些 RPC 层面的需求,比如流量调度、流量镜像、灰度引流等,是需要在 RPC 层面进行升级开发支持,同时需要业务方来升级对应的中间件版本,这给我们带来了一些困扰和挑战。如图所示:
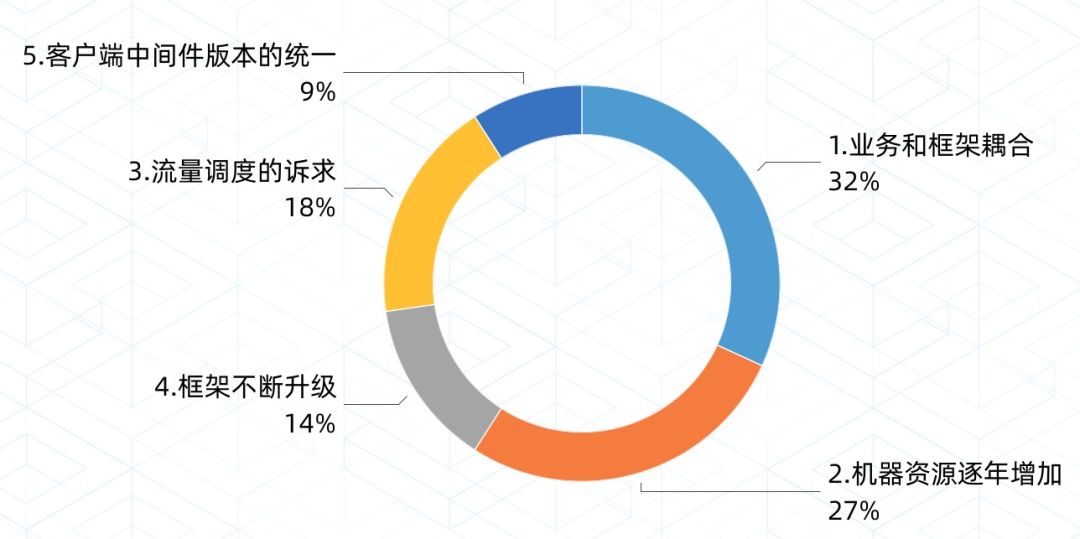
线上客户端框架版本不统一;
业务和框架耦合,升级成本高,很多需求由于在客户端无法推动,需要在服务端做相应的功能,方案不够优雅;
机器逐年增加,如果不增加机器,如何度过双十一;
在基础框架准备完成后,对于新功能,不再升级给用户的 API 层是否可行;
流量调拨,灰度引流,蓝绿发布,AB Test 等新的诉求;
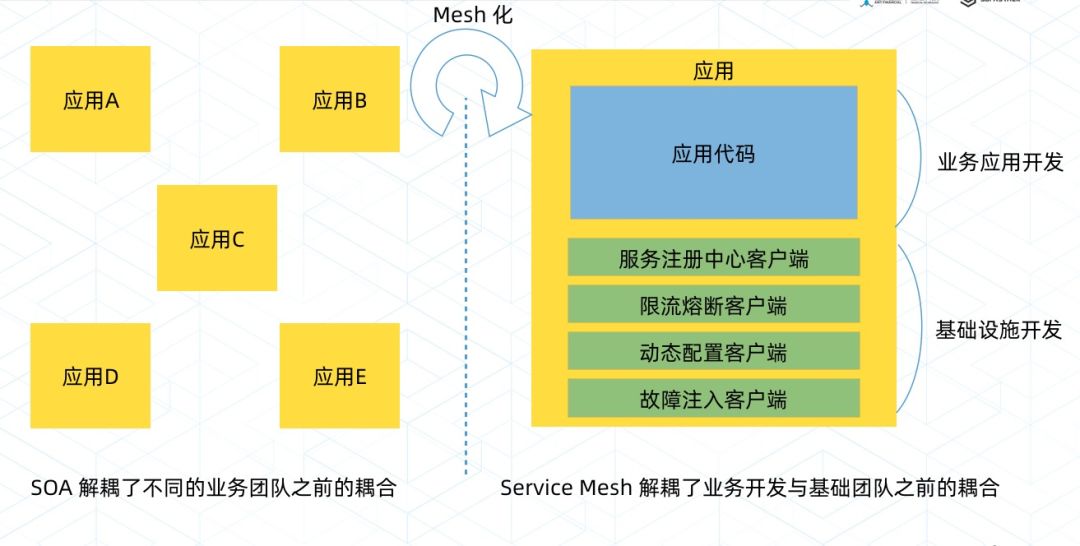
这些都困扰着我们。我们知道在 SOA 的架构下,负责每个服务的团队都可以独立地去负责一个或者多个服务,这些服务的升级维护也不需要其他团队的接入,SOA 其实做到了团队之间可以按照接口的契约来接耦。但是长期以来,基础设施团队需要推动很多事情,都需要业务团队进行紧密的配合,帮忙升级 JAR 包,基础设施团队和业务团队在工作上的耦合非常严重,上面提到的各种问题,包括线上客户端版本的不一致,升级成本高等等,都是这个问题带来的后果。
而 Service Mesh 提供了一种可能性,能够将基础设施下沉,让基础设施团队和业务团队能够解耦,让基础设施和业务都可以更加快步地往前跑。
我们的方案
说了这么多,那我们怎么解决呢?我们经历了这样的选型思考。

总体目标架构
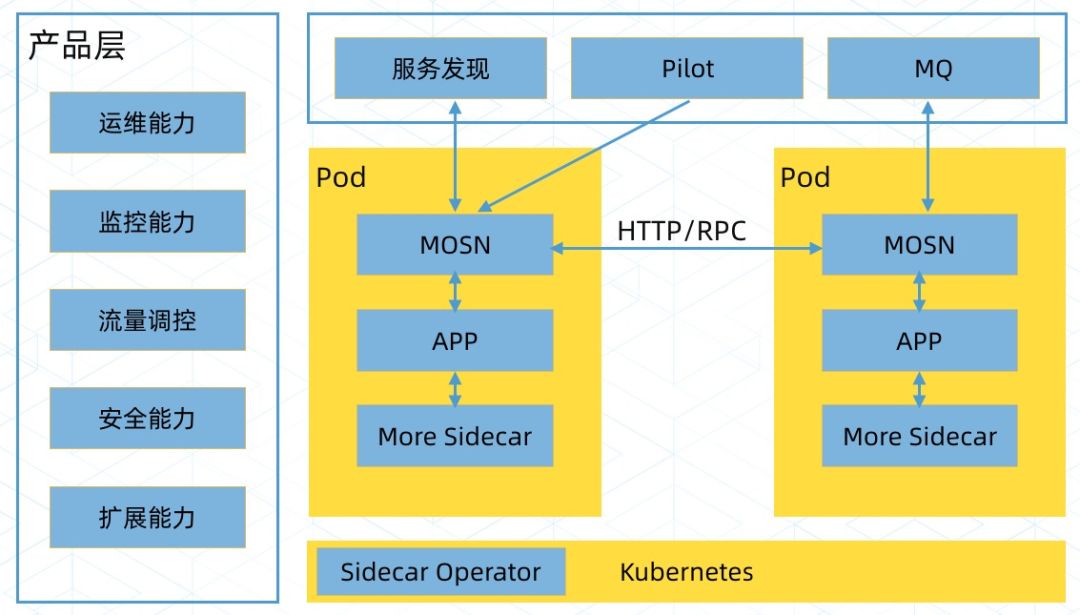
我们的 MOSN 支持了 Pilot、自有服务发现 SOFARegistry 和自有的消息组件,还有一些 DB 的组件。在产品层,提供给开发者不同的能力,包括运维、监控、安全等能力,这个是目前我们的一个线上状态。
SOFARegistry 是蚂蚁金服开源的具有承载海量服务注册和订阅能力的、高可用的服务注册中心,在支付宝/蚂蚁金服的业务发展驱动下,近十年间已经演进至第五代。
SOFARegistry:https://github.com/sofastack/sofa-registry
看上去很美好,要走到这个状态,我们要回答业务的三个灵魂拷问。
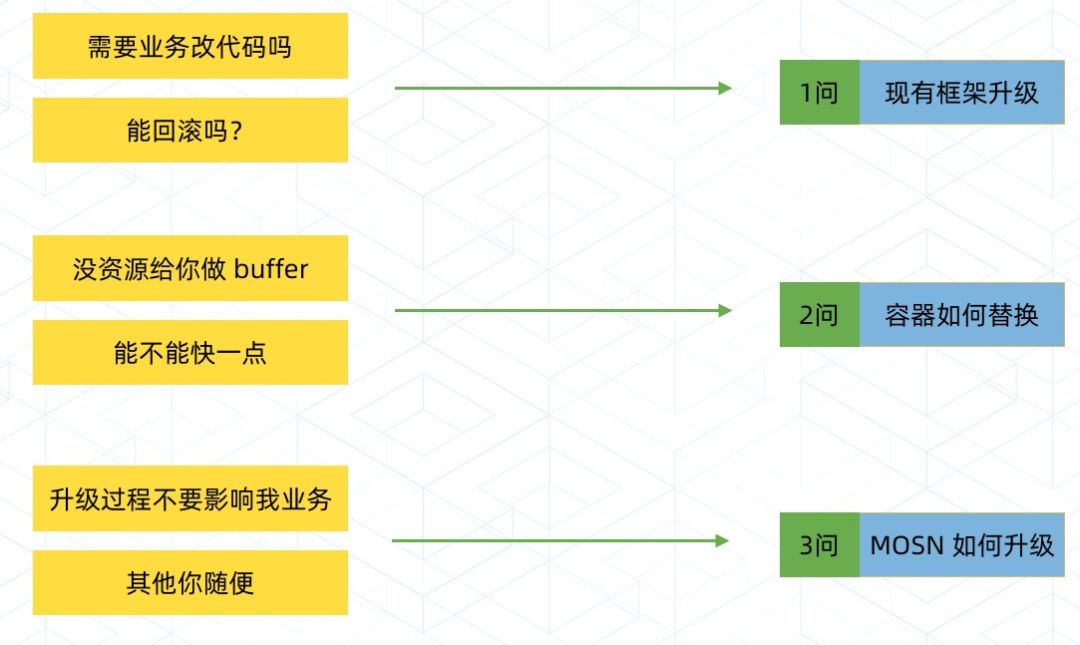
这三个问题后面,分别对应着业务的几大诉求,大家做过基础框架的应该比较有感触。
框架升级方案
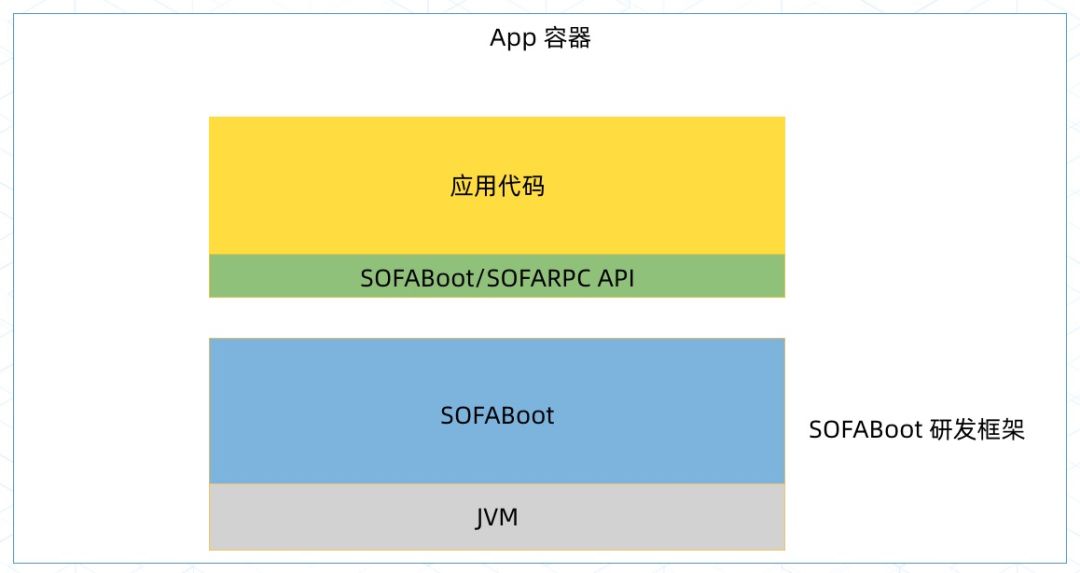
准备开始升级之后,我们要分析目前我们的线上情况,而我们现在线上的情况,应用代码和框架有一定程度的解耦,用户面向的是一个 API,最终代码会被打包在 SOFABoot 中运行起来。
SOFABoot 是蚂蚁金服开源的基于 Spring Boot 的研发框架,它在 Spring Boot 的基础上,提供了诸如 Readiness Check,类隔离,日志空间隔离等能力。在增强了 Spring Boot 的同时,SOFABoot 提供了让用户可以在 Spring Boot 中非常方便地使用 SOFA 中间件的能力。
SOFABoot:https://github.com/sofastack/sofa-boot
那么,我们就可以在风险评估可控的情况下,直接升级底层的 SOFABoot。在这里,我们的 RPC 会检测一些信息,来确定当前 Pod 是否需要开启 MOSN 的能力。然后我们完成如下的步骤。

我们通过检测 PaaS 传递的容器标识,知道自己是否开启了 MOSN,则将发布和订阅给 MOSN,然后调用不再寻址,直接完成调用。
可以看到,通过批量的运维操作,我们直接修改了线上的 SOFABoot 版本,以此来直接使得现有的应用具备了 MOSN 的能力。有些同学可能会问,那你一直这么做不行吗?不行,因为这个操作是要配合流量关闭等操作来运行的,也不具备平滑升级的能力,而且直接和业务代码强相关,不适合长期操作。
这里我们来详细回答一下,为什么不采用社区的流量劫持方案?
主要原因是一方面 iptables 在规则配置较多时,性能下滑严重。另一个更为重要的方面是它的管控性和可观测性不好,出了问题比较难排查。蚂蚁金服在引入 Service Mesh 的时候,就是以全站落地为目标的,而不是简单的“玩具”,所以我们对性能和运维方面的要求非常高,特别是造成业务有损或者资源利用率下降的情况,都是不能接受的。
容器替换方案
解决了刚刚提到的第一个难题,也只是解决了可以做,而并不能做得好,更没有做得快,面对线上数十万带着流量的业务容器, 我们如何立刻开始实现这些容器的快速稳定接入?
这么大的量,按照传统的替换接入显然是很耗接入成本的事情,于是我们选择了原地接入,我们可以来看下两者的区别:

在之前,我们做一些升级操作都需要有一定的资源 Buffer,然后批量的进行操作,替换 Buffer 的不断移动,来完成升级的操作。这就要求 PaaS 层留有非常多的 Buffer,但是在双十一的情况下,我们要求不增加机器,并且为了一个接入 MOSN 的操作,反而需要更多的钱来买资源,这岂不是背离了我们的初衷。有人可能会问,不是还是增加了内存和 CPU 吗?这是提高了 CPU 利用率,以前业务的 CPU 利用率很低,并且这是一个类似超卖的方案,看上去分配了,实际上基本没增加。
可以看到, 通过 PaaS 层,我们的 Operator 操作直接在现有容器中注入,并原地重启,在容器级别完成升级。升级完成后,这个 Pod 就具备了 MOSN 的能力。
MOSN 升级方案
在快速接入的问题完成后,我们要面临第二个问题。由于是大规模的容器,所以 MOSN 在开发过程中势必会存在一些问题,出现问题时该如何升级?要知道线上几十万容器要升级一个组件的难度是很大的,因此,在版本初期我们就考虑到 MOSN 升级的方案。
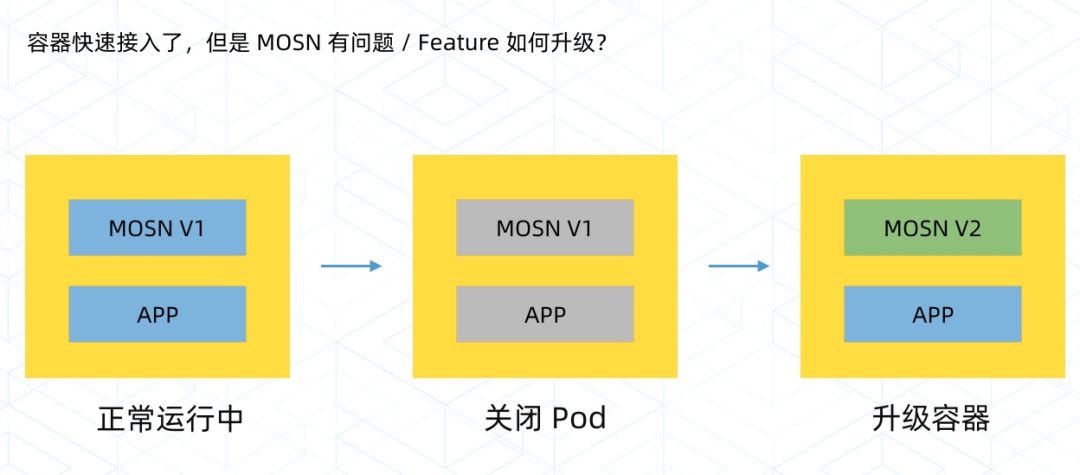
能想到最简单的方法,就是销毁容器,然后用新的来重建。但是在容器数量很多的时候,这种运维成本是不可接受的。如果销毁容器重建的速度不够快,就可能会影响业务的容量,造成业务故障。因此,我们在 MOSN 层面和 PaaS 一起,开发了无损流量升级的方案。
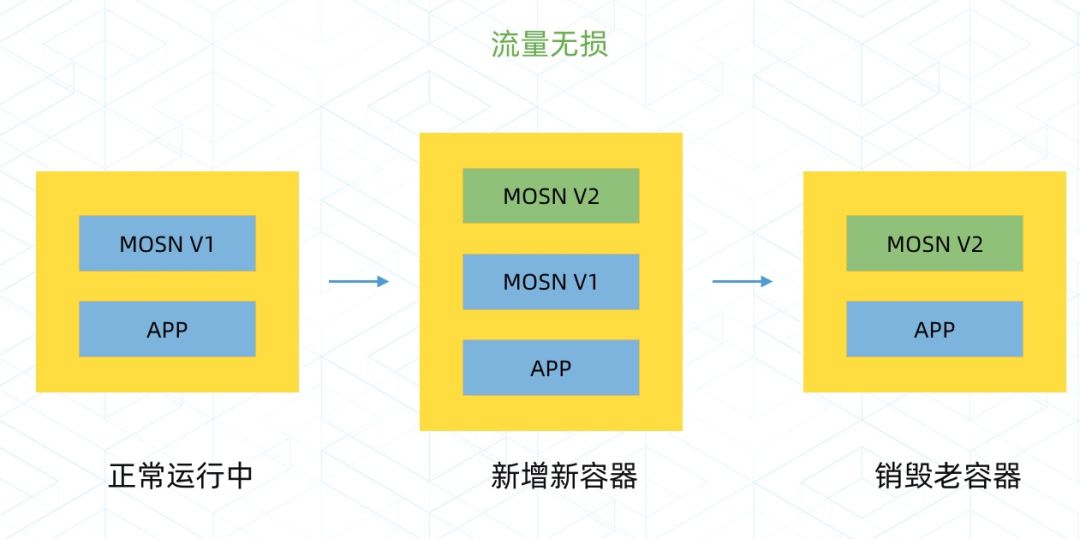
在这个方案中,MOSN 会感知自己的状态,新的 MOSN 启动会通过共享卷的 Domain Socket 来检测是否已有老的 MOSN 在运行,如果有,则通知原有 MOSN 进行平滑升级操作。
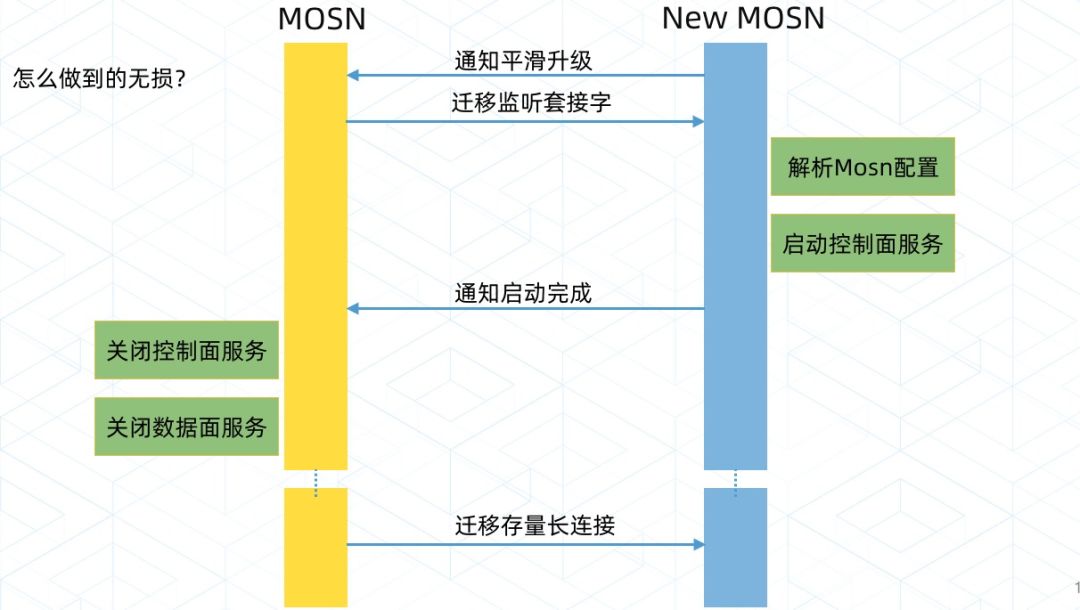
具体来说,MOSN 启动的时候查看同 Pod 是否有运行的 MOSN (通过共享卷的 Domain Socket),如果存在,需要进入如下流程:
New MOSN 通知 Old MOSN,进入平滑升级流程;
Old MOSN 把服务的 Listen Fd 传递给 New MOSN,New MOSN 接收 Fd 之后启动, 此时 Old 和 New MOSN 都正常提供服务;
然后 New MOSN 通知 Old MOSN,关闭 Listen Fd,然后开始迁移存量的长链接;
Old MOSN 迁移完成, 销毁容器;
这样,我们就能做到,线上做任意的 MOSN 版本升级,而不影响老的业务,这个过程中的技术细节,不做过多介绍,之后本公众号会有更详细的分享文章。
分时调度案例
技术的变革通常不是技术本身的诉求,一定是业务的诉求,是场景的诉求。没有人会为了升级而升级,为了革新而革新,通常是技术受业务驱动,也反过来驱动业务。
在阿里经济体下,在淘宝直播,实时红包,蚂蚁森林,各种活动的不断扩张中,给技术带了复杂的场景考验。
这个时候,业务同学往往想的是什么?我的量快撑不住了,我的代码已经最优化了,我要扩容加机器,而更多的机器则对应付出更多的成本。面对这样的情况,我们觉得应用 Service Mesh 是一个很好的解法,通过和 JVM、系统部的配合,利用进阶的分时调度实现灵活的资源调度,不加机器,也可以在资源调度下有更好的效果。
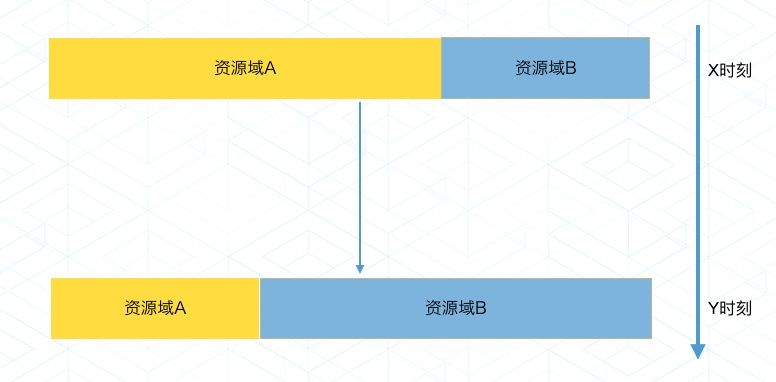
首先,我们假设有两个大的资源池的资源需求情况,可以看到在 X 点的时候,资源域 A 需要更多的资源,Y 点的时候,资源域 B 需要更多的资源,总量不得增加。那当然,我们就希望能借调机器,就像下面这样,请大家看左图。

在这个方案中, 我们需要先释放资源,销毁进程,然后开始重建资源,启动资源域 B 的资源。这个过程对于大量的机器是很重的,而且变更就是风险,关键时候做这种变更,很有可能带来衍生影响。
而在 MOSN 中,我们有了新的解法。如右图所示,有一部分资源一直通过超卖,运行着两种应用,但是 X 点的时候,对于资源域 A,我们通过 MOSN 来将流量全部转走,应用的 CPU 和内存就被限制到非常低的情况,大概保留 1% 的能力。这样操作,机器依然可以预热,进程也不停。
在这里,我们可以看这张图。
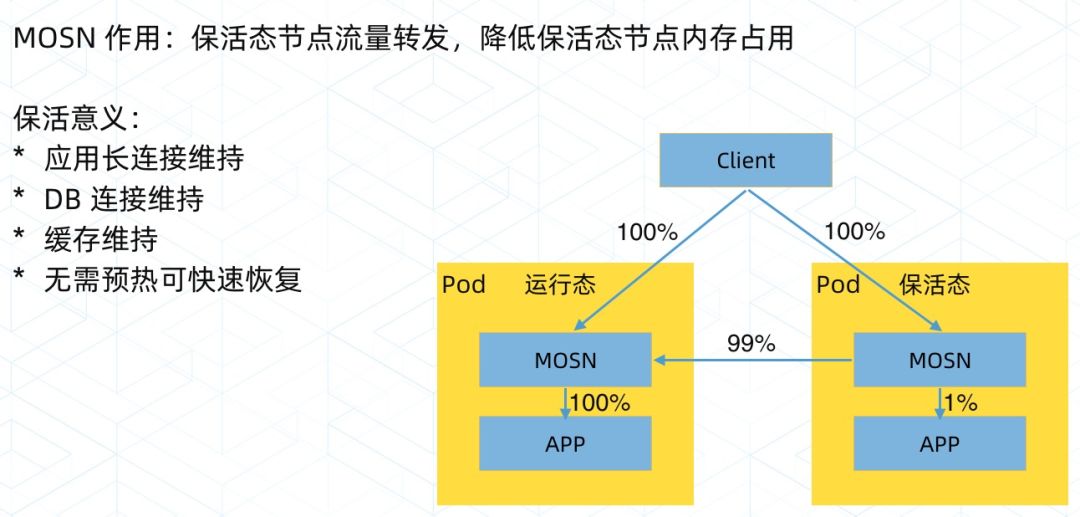
在需要比较大的资源调度时,我们推送一把开关,则资源限制打开,包活状态取消。资源域 B 瞬间可以满血复活,而资源域 A 此时进入上一个状态,CPU 和内存被限制。在这里,MOSN 以一个极低的资源占用完成流量保活的能力,使得资源的快速借调成为可能。
我们对 Service Mesh 的思考与未来
Service Mesh 在蚂蚁金服经过 2 年的沉淀,最终经过双十一的检验。在双十一,我们覆盖了数百个双十一交易核心链路,MOSN 注入的容器数量达到了数十万,双十一当天处理的 QPS 达到了几千万,平均处理 RT<0.2 ms,MOSN 本身在大促中间完成了数十次的在线升级,基本上达到了我们的预期,初步完成了基础设施和业务的第一步的分离,见证了 Mesh 化之后基础设施的迭代速度。
不论何种架构,软件工程没有银弹。架构设计与方案落地总是一种平衡与取舍,目前还有一些 Gap 需要我们继续努力,但是我们相信,云原生是远方也是未来,经过我们两年的探索和实践,我们也积累了丰富的经验。
我们相信,Service Mesh 可能会是云原生下最接近“银弹”的那一颗,未来 Service Mesh 会成为云原生下微服务的标准解决方案,接下来蚂蚁金服将和阿里集团一起深度参与到 Istio 社区中去,一起和社区把 Istio 打造成 Service Mesh 的事实标准。
今天的分享就到这里,感谢大家。如果有想交流更多的,欢迎参与到社区里来,寻找新技术带来更多业务价值,也欢迎加入我们。
SOFAStack:https://github.com/sofastack
本次分享 PPT 以及回顾视频地址:
https://tech.antfin.com/community/activities/985/review/949
声明:本文来自金融级分布式架构,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
