1. 背景:百万级的安全告警
互联网上充斥着各式各样的网络攻击,很多拥有大量网络资产的大中型企业,往往成为黑客的首要攻击目标。因此企业往往会部署多种安全设备。
在这种背景下,企业内部的多种安全防护设备每天会产生大量的安全告警,企业安全运营人员难以对这些安全告警逐一地分析调查,也无法定位出真正高威胁的告警。
如何高效地分析这些安全告警?如何从海量告警中快速定位高优先级的、亟需处理的告警?如何通过蛛丝马迹找到真正高威胁的告警?腾讯御见作为一款SOC(Security Operator Center)产品,接入了企业内部的大量安全告警和事件日志,我们希望它能够帮助企业高效地分析这些安全告警,解决这些实际安全运营的问题。
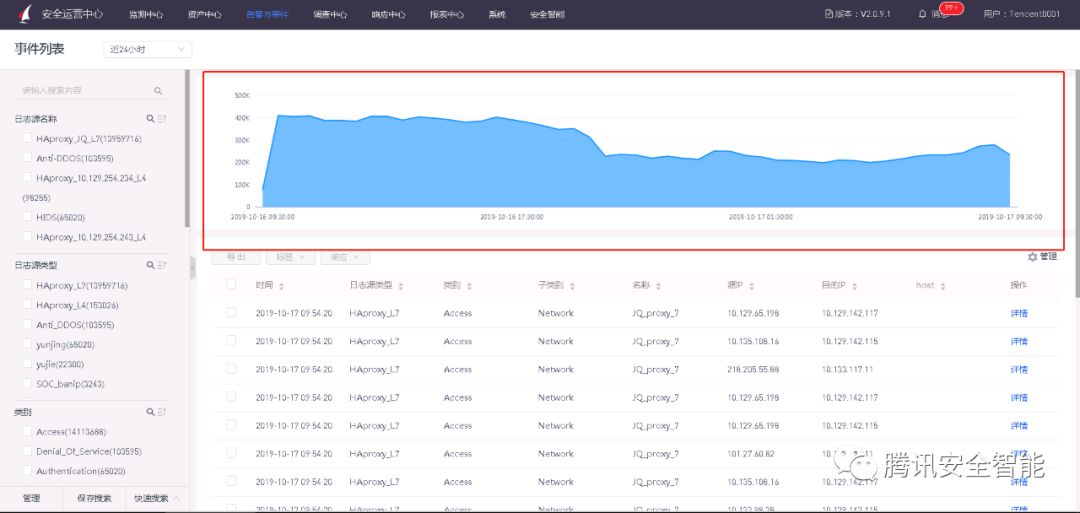
图1 某企业客户的近24小时上报安全事件趋势
2. 初步方案:关联规则
“当你不知道该用什么的时候,就用规则吧。”
为了解决这些问题,最简单直接的方案就是规则,使用规则筛选出高优先级的告警。而规则的制定可以参MITRE ATT&CK或者Kill Chain。
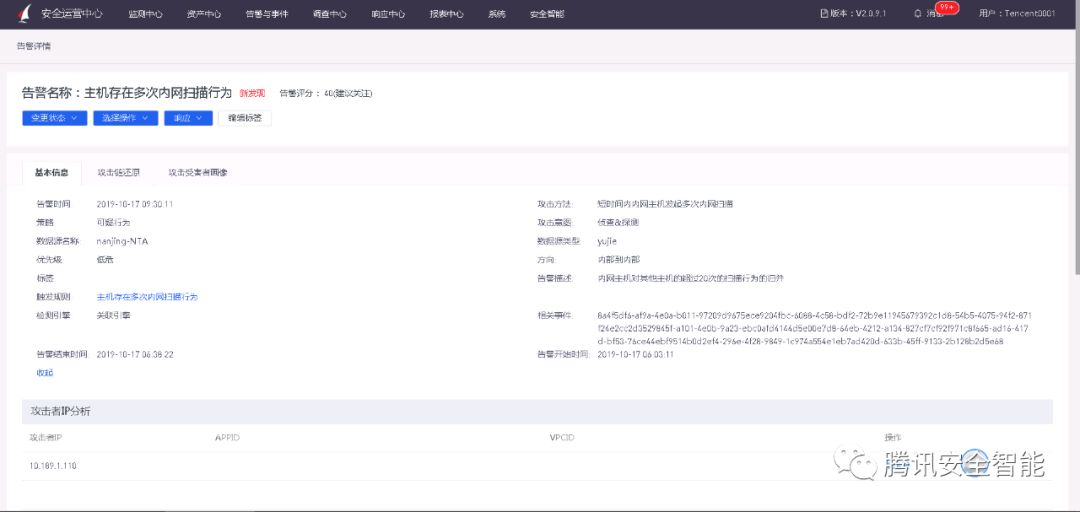
图2 在某企业客户检测到的关联告警1
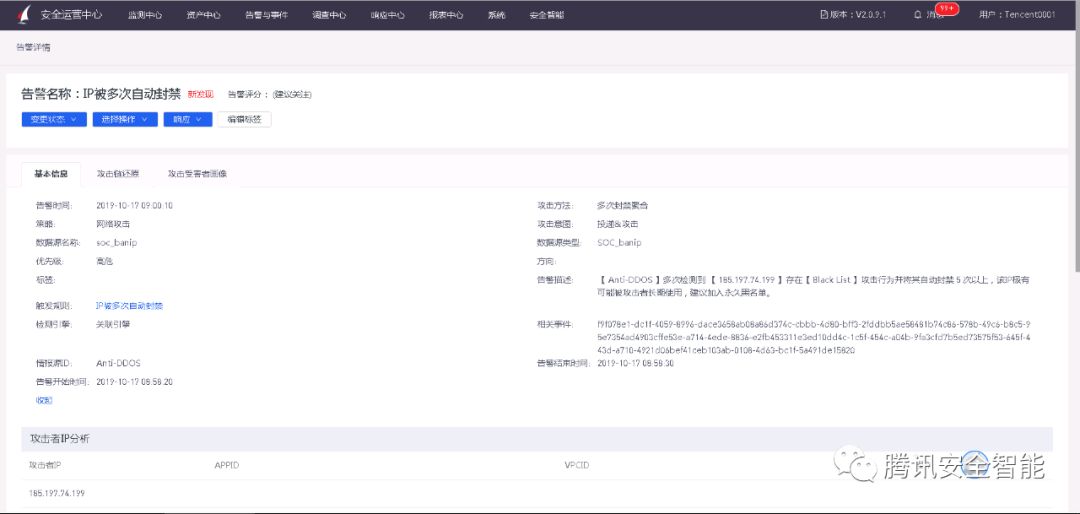
图3 在某企业客户检测到的关联告警2
3. 规则的问题:维护成本高,覆盖不全
“世上的规则系统各不相同,但是规则带来的问题却大多一样。”
关联规则确实可以筛选出高优先级的安全事件,帮助安全运营人员及时发现和处置高威胁告警。但是规则带来了新的问题:
1. 规则的维护成本非常高,需要投入大量人力进行更新和修改;
2. 即使投入大量人力运营规则,但是仍然会存在规则覆盖不全的新场景。
有没有一种方法,能够对规则进行补充甚至替代呢?
4. 提升方案:无监督异常检测发现新威胁
正如前文所述,绝大部分告警都是使用自动化工具发起的尝试性攻击,真正高威胁的攻击相对是比较少的。对于常见的普遍攻击行为,使用规则也可以很好地进行覆盖。另一方面,安全方面的标注样本获取成本非常高。因此我们尝试使用无监督异常检测,发现新的高威胁告警。
PS. 在算法中,我们需要对安全设备上报的告警进行预处理,包括做一些格式转换和字段映射,预处理之后的告警在我们这里称为event,下文全部以event代替告警。
4.1 业界方案
业界已存在的方案通常对单个event计算feature,随后对一个IP(可以是攻击者,也可以是受害者)的event序列进行聚合得到一个event序列特征矩阵,通过autoencoder构造一维向量,然后使用One-class SVM异常检测模型找到异常event [1]。
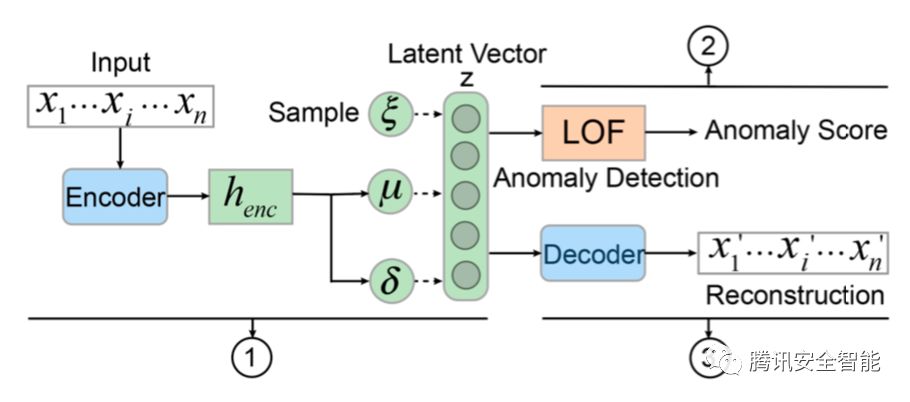
图4 业界安全告警异常检测方案
4.2 我们的方案:异常事件序列挖掘
在业界方法的基础上,我们得到了新的告警分析方案,主要分为4步:
1. 事件子序列生成
2. 子序列特征提取
3. 子序列异常检测
4. 检测结果投票(ensemble)
4.2.1 事件子序列生成
对每个IP的安全事件进行聚合,生成事件序列,作为异常检测的样本。具体生成方式为:给定时间区间和滑动时间窗口(如:1.0h),对日志中的安全事件根据源IP或者目的IP的发生时间进行排序,以最小时间戳为起点,当时间区间内的事件个数大于给定最小值的序列即生成为一个事件序列,当前起点时间向后滑动一个事件窗口,继续生成事件序列,直到循环结束。
4.2.2 子序列特征提取
得到事件序列样本之后,计算每个事件序列的统计特征,通过计算统计特征,可以将每个IP某段时间发生的安全事件转化为一个特征向量。
4.2.3 子序列异常检测
得到特征向量之后再进行异常检测并不复杂,常用的无监督异常检测算法都可以使用。在我们的方案中,经过实验和多种尝试,最终使用了四种不同的异常检测算法:
• EllipticEnvelope
• OneClassSVM
• Isolation Forest
• Robust Covariance
对于这些算法的具体原理和实现,不是我们的重点,这里不做过多介绍。
4.2.4 检测结果投票
算法的最后一步是做模型集成,对于多个异常检测模型的预测结果,进行投票,只保留得分top k的事件序列。这样就从原始的大量的告警中筛选出了异常的告警片段。
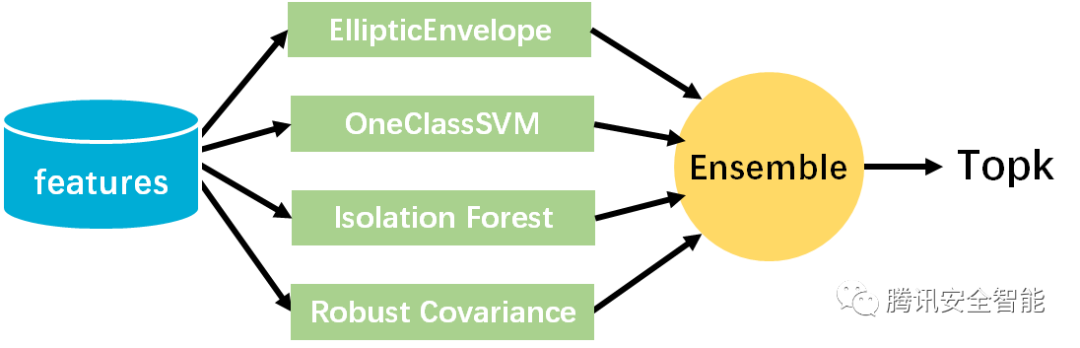
图5 异常事件序列挖掘算法结构
5.异常检测算法的问题:我凭什么相信你
“算法听起来不错,但是结果我们都看不懂,我凭什么相信你?”
但是在使用实际数据测试后,又出现了新的问题。对于关联规则匹配到的告警,安全运营人员可以根据命中的规则,很容易知道这条告警为什么需要优先关注和处理;但是对于异常事件序列挖掘算法得到的告警,安全运营人员只能知道这些告警是异常,但不知道为什么会异常,不知道该从哪些角度进行处理和调查。
一方面,对于实际使用的甲方企业安全运营人员来说,算法是一个黑盒,他们并不了解其中的细节和处理流程,以及为什么会得到这个结果,不了解产生了不信任;另一方面,安全问题相对其他问题来说具有更高的风险,犯错成本很高,既会浪费人力去进行排查分析,又可能会对正常业务造成影响。
综合这两个因素,我们需要对异常检测的结果进行解释,尽量告诉用户,为什么会把这些告警筛选出来,它们到底哪里值得关注。
6.无监督异常检测的可解释性
为了对于异常事件序列检测得到的异常序列样本进行解释,我们采用的方法是计算样本的每个特征的异常分数,找到显著异常的特征,从而解释“为什么我们认为这个样本是异常的”。在这里异常分数使用z-score。
具体操作方法如下:计算这些样本在每个特征上的z-score,将z-score作为该特征的重要性,最后按照特征重要性对特征进行排序,选出重要性Top 3且满足阈值的特征,作为该样本异常的解释。完整的计算逻辑如下图:
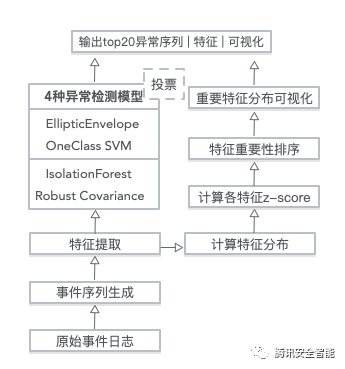
图6 完整异常事件序列检测方案示意
通过这种方法对每个异常event序列进行解释,输出对应的异常特征和描述,安全运营人员可以根据异常特征对序列进行筛选,快速定位到真正的高威胁告警。
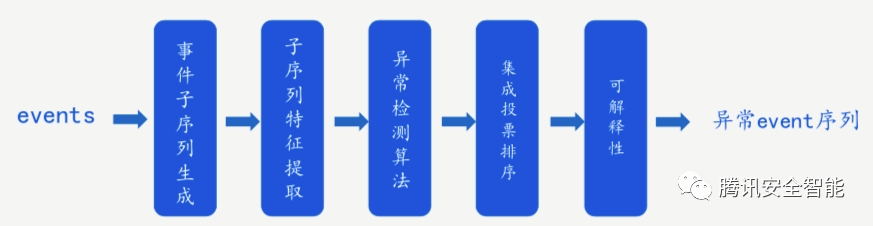
图7 异常事件序列检测方案流程示意
7.结语:一个未完成的故事
通过关联规则+异常事件序列挖掘的配合,御见实现了从海量的告警中找到真正高威胁或者高优先级的告警的目标。当然目前的方案还有不足之处,例如找到的异常告警的类型有限,严重依赖统计特征等等。我们还在尝试更多方案,希望能够真正帮助企业提高安全运营效率,降低安全风险。
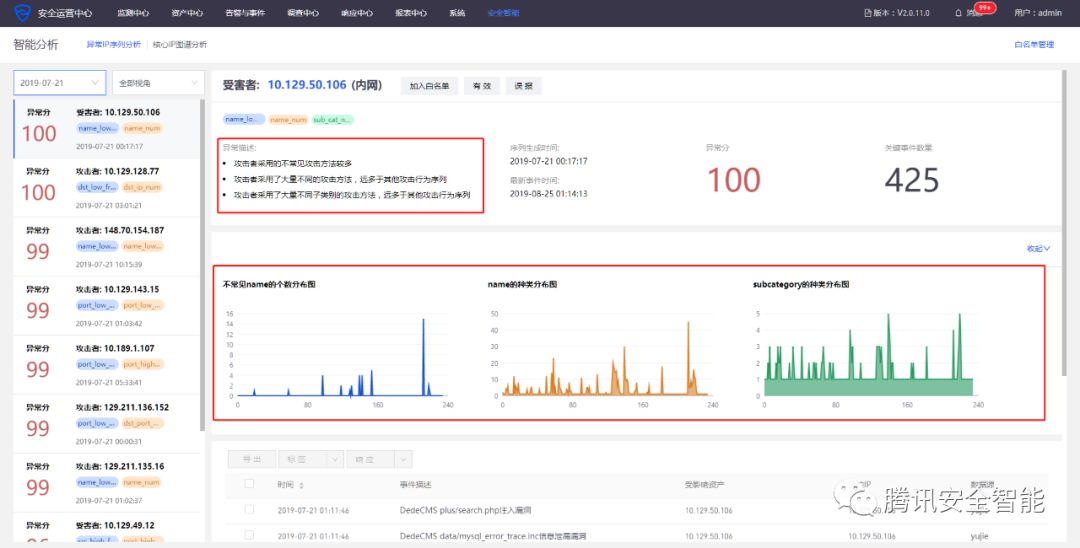
图8 异常事件序列挖掘在产品中的落地
参考文献
1. Guo, S., Jin, Z., Chen, Q.,Gotz, D., Zha, H. and Cao, N., 2019. Visual Anomaly Detection in Event SequenceData. arXiv preprint arXiv:1906.10896.
2. Shashanka, Madhu, Min-Yi Shen,and Jisheng Wang. "User and entity behavior analytics for enterprisesecurity." 2016 IEEE InternationalConference on Big Data (Big Data). IEEE, 2016.
3. Micenková, Barbora. Outlier Detection and Explanation for DomainExperts. Diss. Department Office Computer Science, Aarhus University, 2015.
(王泉、赵瑞辉)
声明:本文来自腾讯安全智能,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
