1.引言
2019年11月25日,是人类互联网时代值得纪念的一天,因为负责英国、欧洲、中东和部分中亚地区互联网资源分配的欧洲网络协调中心(RIPE NCC)宣布,全球最后的IPv4地址空间储备池在11月25日UTC+115:35完全耗尽,这意味着没有更多的IPv4地址可以分配给ISP和其他大型网络基础设施提供商[1]。IPv6是IETF(互联网工程任务组,Internet Engineering Task Force)设计的用于替代现行版本IP协议(IPv4)的下一代IP协议,IPv6将IPv4中32位的地址长度扩展到了128位,使用IPv6,可以让全世界的每一粒沙子都能分配到一个IP地址。IPv6凭借充足的网络地址和广阔的创新空间,已经成为实现万物互联,促进生产生活数字化、网络化、智能化发展的关键要素,为我国网络设施升级、技术产业创新、经济社会发展提供了重大契机。2019年4月,工信部发布《关于开展2019年IPv6网络就绪专项行动的通知》[2],以全面提升IPv6用户渗透率和网络流量为出发点,就推动下一代互联网网络就绪提出主要目标、任务举措和保障措施,持续推进IPv6在网络各环节的部署和应用。
随着IPv6地址全面普及,安全漏洞和网络攻击也定会随之而来。从安全防护的角度来说,地址扫描是运营维护人员进行漏洞测试、安全评估等网络系统级别的安全保障的有效工具。相比IPv4地址,IPv6地址具有巨大的地址空间,而且在地址表示、地址配置等方面均有显著不同。因此,就会导致IPv4的遍历的扫描方法和工具变得不可行。目前,国内外对IPv6地址扫描的研究主要集中在以下两个方面:一方面是缩小扫描空间,另一方面是使用算法生成预测地址集。
2.缩小扫描空间
缩小扫描空间方面,本文主要介绍两种方法:基于抽样的地址扫描和挖掘地址结构特征。
2.1 基于抽样的地址扫描
因为活动主机地址的分布状况在不同链路中是各不相同的,根据地址分布的特点,可以考虑IPv6地址均匀分布与非均匀分布两种情况。通过为IPv6地址扫描建立合理的数学模型,对影响其效率的各个因素进行分析,可以找出针对不同网络情况的最佳扫描策略。文献[3](2007)提出了一种基于地址抽样的IPv6地址扫描方法,因为IPv6网络提供了巨大的地址空间,所以活动主机地址的分布通常是非均匀的,此时如果仍然使用随机地址扫描模型(Random address scanning,RAS)来讨论,随机地选择被扫描地址进行扫描,则得不到理想的扫描效率。这里可以使用抽样地址扫描模型(sample address scanning,SAS)来描述扫描过程,引入统计学中的方法,采用整群抽样的思想,先将大地址空间划分为若干个大小相等的子空间区域,对每个区域进行抽样,利用得到的结果对各个区域内含有活动主机的概率进行预测分析、排序,得出拥有活动主机相对较多的区域,然后合理分配扫描资源优先对这些区域进行扫描,从而有效地提高扫描效率。通过对非均匀分布的IPv6地址进行扫描测试,SAS模型比RAS模型扫描时间约节省了80%。但模型中并没有给出关于将大地址空间合理地划分为多少个子区域的计算公式,并且IPv6地址空间是巨大的,就算合理划分了抽样的区域,对各个子区域进行抽样扫描花费的时间也将会是巨大的。
2.2 挖掘地址特征扫描
虽然IPv6地址空间巨大,但是地址分配是具有一定的规律性的,RFC3587[4]等文档描述了地址结构和分配方法,研究人员可利用上述文档分析IPv6地址结构特征来缩小扫描空间。文献(2006)采用多个数据集对IPv6地址进行了分析通过对一定量的地址进行统计,结果发现70%以上的主机应用的是无状态自动配置(SLAAC, stateless address autoconfiguration)地址类型和内嵌IPv4地址类型,70%的路由器使用的是低位地址类型。这样就会使得IPv6网络中主机的扫描范围大大缩小,这对IPv6网络扫描提供了一个重要参考。根据IPv6地址分布存在的规律,文献[6](2016)列出了许多利用地址分布特征来缩小IPv6地址扫描范围的方法,例如虚拟机地址、低位地址和EUI-64地址等扫描方法。利用地址特征的扫描方法虽然简单、有效且具有可操作性,但是其缺点也十分明显,例如仅能适用于发现属于标准的格式之内的网络地址,而对于临时分配地址、复杂的手动配置地址等情况,有效的扫描就无法完全实现。为了能够更有效地扫描和处理IPv6临时地址,需要对IPv6地址的规律进行更深的挖掘与研究。
3. 通过种子集生成预测地址集
目前研究论文比较多IPv6地址扫描方法是通过地址集生成可能存活的预测目标集,来扩展可能存活的地址空间。而这种方法首先需要收集一些高质量的种子集。那么,接下来就介绍一些IPv6种子集的来源。
3.1 IPv6种子集来源
Hitlist[9]目前是在IPv6地址积累比较多的开源数据集,文献[10](2018)中就介绍Hitlist中的IPv6地址公开的数据来源途径。各个途径获得的数据情况如图1所示:
域名列表(Domain lists):通过公开的域名集合获取获得IPv6地址。比如Zone files,恶意域名情报等
DNS转发(Forward DNS, FDNS):Rapid7中的转发域名集合
CA证书提取(Certificate Transparency, CT):在TLS的CA证书中提取的域名
比特币节点(Bitcoin node address, Bitnodes):比特币节点的IPv6地址
RIPE Atlas(NCC)[11]:提取RIPE Atlas中的traceroutes产生的IPv6地址
Scamper[12]:使用Scamper工具探测获得的IPv6地址
论文中还介绍了各个IPv6地址源的AS分布情况,如图2所示。CA证书提取和域名列表得到的IPv6地址分布的AS比较集中,属于非均匀分布。分布最为均匀的是在RIPE Atlas中得到的地址。
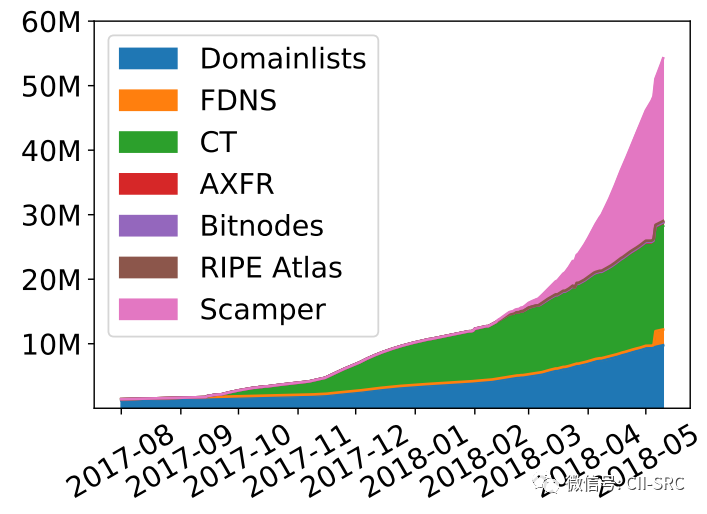
图1 IPv6地址存活数量
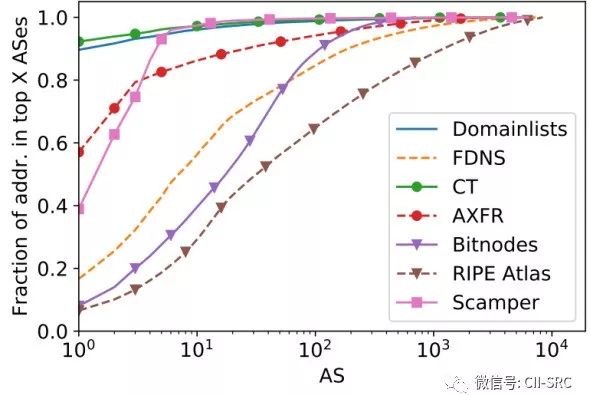
图2 不同数据源IPv6地址AS分布情况
3.2 基于地址关联规则的扫描方法
文献[7](2017)提出了结合地址关联关系来发现IPv6地址的方法。根据数据挖掘关联规则的定义,将IPv6地址关联规则初步定义为符合IPv6地址特征的地址集中不同的有效IPv6地址之间的关联关系。IPv6地址关联规则就是找到IPv6地址之间的关联关系,得到相应的关联规则。关联规则的核心思想就是将128位地址中的后64位接口标识符中的每1个bit位看作一个实验项,设定阈值T,通过发现项与项以及多项之间的潜在关联规则,在扫描出的众多模式中,如果存在相关联的bit项位数大于等于64-T的,那么我们就可以设定为该条模式是在IPv6地址中频繁存在的。通过找到地址间的规则,从而达到缩小IPv6地址扫描空间的目的。文献[8](2018)对文献[7]中的关联规则的扫描方法进一步应用,将IPv6地址特性与关联规则方法相结合,提出了一种基于模式的IPv6地址扫描检测算法。具体的流程如3所示。通过对Alexa Top Million 的AAAA记录进行扫描实验,结果表明该方法能够减少IPv6地址的有效地址空间,并且能够更有效地实现IPv6地址扫描和地址生成。
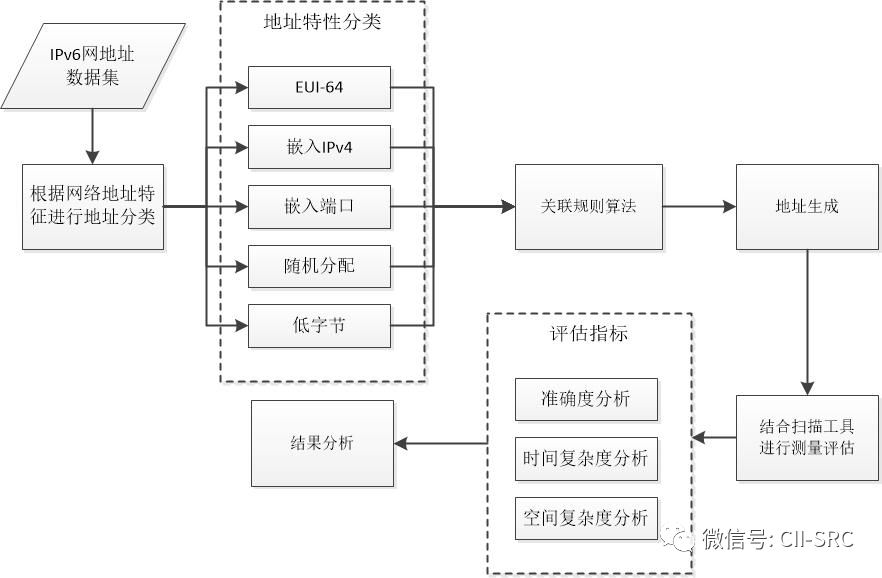
图3 基于模式的IPv6地址扫描流程
3.3 基于熵值挖掘地址特征
通过“熵”值可以对随机变量的不可预测性、分布进行度量。文献[13](2016)设计了一个系统Entropy/IP[14],该系统首先对已知IPv6地址集中各个地址的熵进行计算,再通过DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚类算法对IPv6地址进行分段,使用各地址的熵值情况来挖掘互联网上IPv6地址的结构特征。这种算法可以很好地对IPv6地址集的地址规律进行发现,并且输入种子集合后该系统可以完全自动化的生成预测集。
IPv6地址位熵计算过程:
地址位(16进制)X取值集合为{0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f},共有16种可能的情况发生,
事件 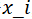 ,
, 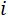 ∈(1,16)概率为
∈(1,16)概率为 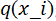 那么每个地址位熵
那么每个地址位熵 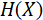 为:
为:
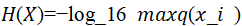
越小,地址位取值数量越少。
以一个地址集为例,介绍基于熵值生成预测地址集的过程[15]:
首先,通过公式计算地址集中每个地址位的熵值。如果地址位取值是变化频繁的,那么对应的熵值就会很高,如果熵值为零,整个数据集中该地址位取值不变。数据集的地址位熵值与分段情况图4所示。
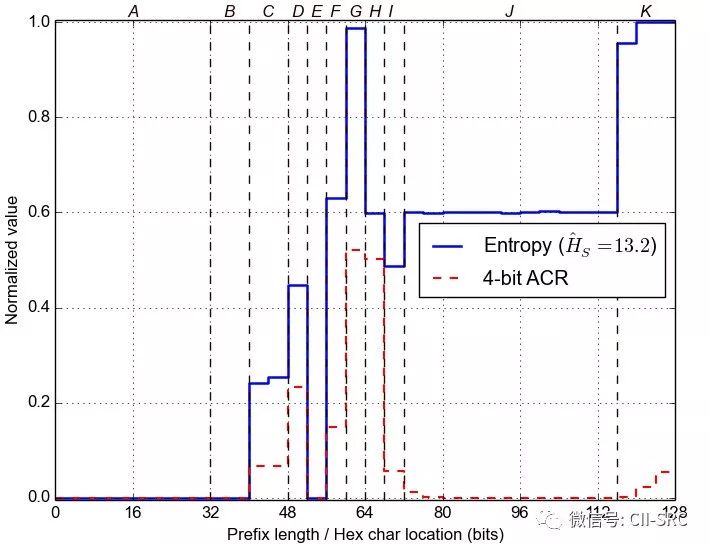
图4地址位熵值(归一化)分布情况
然后,统计出现频率较高的地址位或地址段。使用DBSCAN聚类算法统计出现频率高的地址值和所在的地址段。具体的数据集结果如图5所示(前缀1-8位已做匿名处理)。

图5 不同位的地址值出现频率情况
接下来,利用数据集训练贝叶斯网络(BN)来找到各个地址段的依赖关系,如图6所示,箭头表示影响关系,被连接的网段(字母A-K)会对两个方向(上游/下游)有影响。当然,没有直接连接的网段,仍然可以被其他网段影响。例如:如果C依赖于B,而B依赖于A(即使A和C之间没有直接箭头),则A可以通过B影响C。从数据中学习BN结构通常是一个有难度的优化问题。所以,同一数据集可能存在多个可能的BN结构图。
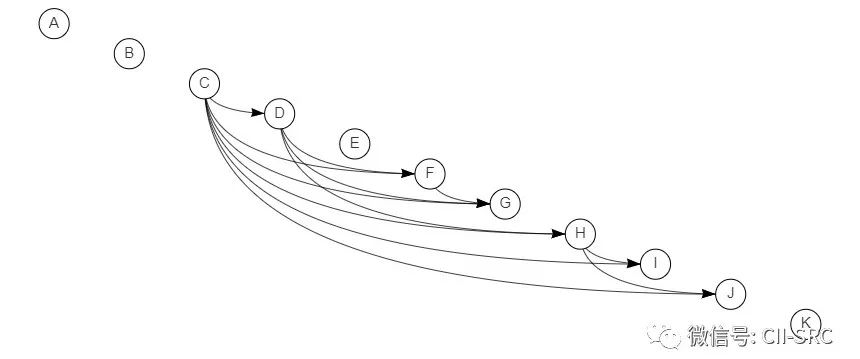
图6 地址
最后,为了展示直观,以图的方式列出数据集得到的IPv6地址段、值、范围和相应的概率,如图7所示。上述的方法能够成功的扫描到服务器和路由器的IPv6地址,并可以预测可能存活的IPv6地址。
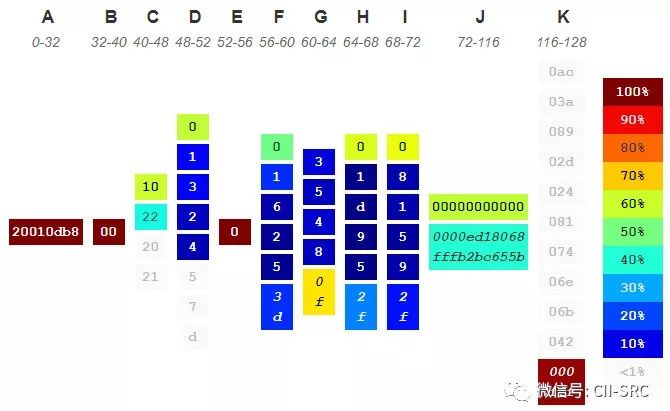
图7 IPv6地址段、值、范围以及概率
3.4 基于地址分布密度挖掘种子集
文献[16](2017)提出了一种目标生成算法(Target Generation Algorithms,TGA),该算法是对已知地址集的进行处理,计算出地址分布密集的空间区域,从而在这些区域内生成扫描目标地址。并且利用这个算法开发IPv6地址生成的系统——6Gen。通过与文献[14]的Entropy/IP算法进行对比,6Gen可以将预测的地址数量可扩展到种子集1-8倍,并且对某个特定的地址数据集,它可以预测超过99%的地址。基于DNS的种子数据集上使用6Gen,对生成的目标进行了主动扫描,发现了超过5500万个新的IPv6地址。
4.总结
本文对近年的部分国内外IPv6扫描的相关文献进行梳理,总体来看,目前对IPv6的地址扫描的研究主要分为利用地址特征来缩小扫描空间和通过种子生成新的地址集两个方面。但无论哪个研究方向优质的地址种子集都是IPv6地址发现的重要前提,这样生成的目标地址集才会丰富准确,当然还需通过生成的目标地址反复扫描并收集。此外,地址生成算法也需要不断更新或者新增。总之,IPv6地址测绘很难一劳永逸,通过对地址集合算法的持续运营,才会积累更多的存活地址。综上,希望这篇文章对研究人员和相关从业者有所有帮助。
参考文献
[1] 全球43亿IPv4 地址正式耗尽http://www.sohu.com/a/358057452_99992317
[2] 推进IPv6网络就绪专项行动[J].信息化建设,2019(07):16.
[3] 李东宁,王振兴.基于抽样的IPv6高效地址扫描[J].计算机工程,2007(15):121-123+126.
[4] Chown T. IPv6 Implications for Network Scanning.2008
[5] David Malone,Observations of IPv6 Addresses.
[6] F.Gont,T.Chown, Network Reconnaissance in IPv6 Networks
[7] 刘林波. IPv6地址扫描技术的研究与应用[D].山东大学,2017.
[8] 赵玉婷. 基于模式的IPv6地址扫描检测算法研究[D].新疆大学,2018.
[9] Hitlist项目地址:https://ipv6hitlist.github.io/
[10] Oliver Gasser, Quirin Scheitle, Paweł Foremski, Qasim Lone, Maciej Korczyński, Stephen D. Strowes, Luuk Hendriks, Georg Carle.Additional Plots. Clusters in the Expanse: Understanding and Unbiasing IPv6 Hitlists. In ACM Internet Measurement Conference, 2018
[11] RIPE Atlas:https://atlas.ripe.net/landing/about/
[12] Scamper:https://www.caida.org/tools/measurement/scamper/
[13] Pawel Foremski, David Plonka, and Arthur Berger. Entropy/IP: Uncovering Structure in IPv6 Addresses. In ACM Internet Measurement Conference, 2016
[14] https://github.com/akamai/entropy-ip
[15] http://www.entropy-ip.com/reports/example/#structure
[16] Austin Murdock, Frank Li, Paul Bramsen, Zakir Durumeric, and Vern Paxson.Target Generation for Internet-wide IPv6 Scanning. In ACM Internet Measurement Conference, 2017.
本文作者:绿盟科技创新中心 桑鸿庆
声明:本文来自关键基础设施安全应急响应中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
