【编者按】2019年7月,美国兰德公司发布《算法公平——社会应用框架》(Algorithmic Equity A Framework for Social Applications)报告,报告旨在指导社会应用中公平使用算法决策工具,并结合算法决策工具在汽车保险定价、就业招聘和刑事司法三个场景中日益广泛的使用,指出未解决的公平性挑战会破坏社会机构的稳定性和合法性,并提出了社会应用中实现算法公平的若干建议。

1、介绍
20世纪算法系统的出现为实现社会机构公平增加了一个新的维度。计算技术的改进,以及可用于训练的数据集海量增长,使得算法能力取得了巨大的进展。一方面,算法保证了一种形式上的客观性,例如它是一种更优的利用现有信息进行决策的工具,产生更小的噪音或偏差,不受人类主观、情感和偏见的影响等。另一方面,由数据驱动的算法意味着算法对客观性的承诺被更好地描述为对一致性的承诺,而这种一致性并不意味着绝对正确或没有偏见。
由于缺乏健全的应对措施和机构实践经验,且尚不清楚如何调整现有的法律和政治机制,因此监管部门在应对算法在不同系统应用中带来的公平挑战时存在不足。为了解决这些挑战,报告提出一种框架来检查算法决策,并通过汽车保险、就业招聘和刑事司法这三个领域的探索具体分析。
2、公平的概念
公平是决策代理机构的一个基本属性,机构的公平性来源于决策过程的质量(程序公平性)和/或决策结果的质量(结果公平性)。
从法律、哲学和统计机器学习(statistical machine learning)的多个角度阐述公平的概念:首先,公平不是一个单一的概念,不同的公平准则通常适用于不同的社会机构。其次,看似合理的公平概念可能会相互冲突,甚至互不兼容。第三,有时公平的规范性和理论性概念与一般的实践概念并不相同。这些问题都会引起对公平问题的挑战,即对机构中固有的原则、规则和价值观的偏离。
3、汽车保险中的算法
在汽车保险领域,最关注的理念是个人风险的公平性,也就是个人期望的费率与自身的保险风险或公司的预期成本相称。
算法公平带来的挑战包括:(1)红线,即风险溢价不符合基于社会经济条件的个人风险公平。在这种情况下,生活在社会经济地位较低的社区成员的保险费相对高于其实际的保险风险,如果红线存在,它就违反了个人公平的要求和负担得起的社会要求。受影响的恰恰是那些无法承担保费上涨的人,同时它也增加了不遵守强制性保险法的风险;(2)确定哪些数据属性必须排除在保险风险考虑因素之外或被包含在其中。在这个问题上,各州差异很大。州规定允许或完全禁止使用性别、宗教、性取向和年龄等个人数据属性。许多州禁止使用种族属性,但实际上种族分类仍然存在,很可能是因为,只要有足够的数据和训练,种族属性很容易从合法、甚至是无害的次要属性中推导而出。(3)强制保险的影响。许多州要求司机必须有汽车保险,但是私营保险市场和全民医保的结合,可能导致高风险且贫穷的司机选择的困境:非法驾驶或支付难以负担的保费。一国如果无法提供负担得起的公共产品,那么这一困境尤其难以解决。
在一个完全透明、竞争激烈的保险市场中,除了具备与风险相关的特征以外,不应有任何形式的歧视,产生歧视的原因有两方面因素:一是透明度低,判断保险公司算法和模型公平性的信息要么只是部分公开,要么完全属于商业机密。二是法律规定的信息属性黑名单。虽然监管机构有时强制要求保险公司在某些信息属性上不得有歧视,但是实际上存在某些“歧视”,而算法越来越有能力帮助保险公司使用不受监管的信息属性。更糟糕的情况是,保险公司删除了具有敏感属性的数据会导致难以检查保险算法的公平性。
4、就业招聘中的算法
在就业招聘领域,原来许多不影响工作表现的一些特征被证明对招聘产生了影响。1964年美国《民权法》(Civil Rights Act of 1964)第七章规定禁止对被保护阶层的雇员的歧视,发展至今,禁止歧视的依据扩展到了性别、种族、年龄、宗教、性取向、移民身份和婚姻状况等。法律禁止基于敏感信息属性对求职者进行区别对待,也禁止使用与招聘无关且会严重影响受保护阶层(被正式禁止在决策中使用的个人特征)的做法。
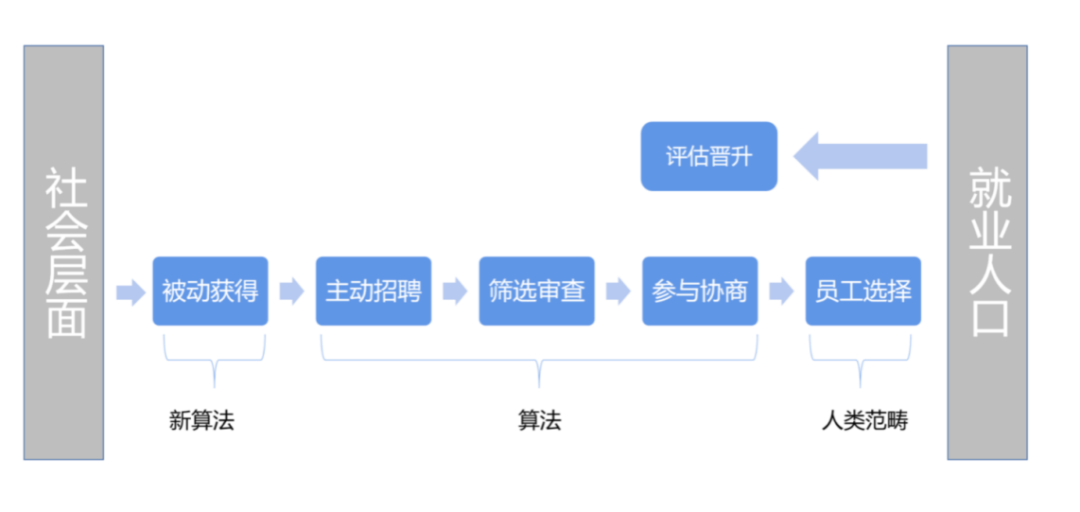
图1 关于就业招聘决策中的算法
图1显示出在就业招聘过程中的决策点,我们重点关注两个阶段:被动获得和主动招聘。
在被动获得阶段:越来越多的个人和商业数据能够从互联网上获得,这种获得方法可能因算法而变得更加强大,通过识别那些不积极寻找工作但很可能被说服跳槽的人,被动获得为企业获得最佳人才方面提供了竞争优势。
在主动招聘阶段:为了吸引求职者补充职位空缺,企业可能会使用机器学习算法来实现,但是在雇主作出雇佣决定之前,如果雇主查看候选人受保护的数据是有风险的,如果候选人没有被雇佣,雇主可能面临指控。
在就业招聘中,算法公平带来的挑战包括:(1)缺乏代表性的可用训练数据;(2)关于工作绩效的基本事实数据的不完善和不完整性;(3)利用算法规避监管责任。
5、刑事司法中的算法
在刑事司法领域,关键的公平规范是平等待遇和正当程序。
平等待遇要求处境相似的人受到同样的待遇,完全不同的待遇是不允许的。然而,在风险/需求评估中使用的大多数群体分类都只经过理性的基础审查,这就意味着只要政策具备合理的目的,并且风险/需求评估与该目的合理相关,那么它的合宪性就会得到维护。其中最大的两个例外是性别和种族。关于种族问题,许多学者认为将种族问题纳入刑事司法判决是违宪的。
正当程序是指个人与国家之间关系的公平,即通知的规定和听证的机会,这些规范为算法公平挑战提供了共同的基础。算法模型很难保证公平对待,特别是考虑到代理变量的普遍性,这些属性通常会受到严格的审查。当前司法系统中算法的使用会在不通知受影响个人的情况下影响最终结果。
6、建议和措施
为应对算法在各种领域应用中的挑战,报告提出了促进更加公平使用算法的建议和措施,具体包括:
(1)明确公平的概念:规范多元化的问题和公平概念之间存在潜在的冲突,考虑到规范的不确定性,算法决策机构和人员需要对他们遵守的标准和规范保持清晰和透明性,并让利益相关者参与进来,确保一种全面的考虑。
(2)减少指定敏感属性,从而确保公平:利用信息属性黑名单的监管方式来确保公平是一种建议举措,而监管机构仍然要秉持怀疑的态度以验证对此种方式的合理性,可能监管机构更需要一种可解释的、甚至是透明的模型来保证公平。
(3)由准确的真实情况决定:算法设计者和机构都需要仔细考虑他们打算利用算法决策进行优化的结果,并厘清可接受的误差,然后验证是否有正确的数据来训练和评估算法模型。
(4)可信的验证和确认:对算法透明性的需求,核心是确保已经部署的算法模型是可问责的,更是可信的。工程领域可以通过向合格的专业人员全面披露和评估、专业标准机构颁发合规证书等方式来实现验证和确认,社会应用中可以通过保险计划、侵权法以及责任或罪责判定等方式来实现。
(5)人类的判断:不能仅仅依靠程序来监管或评估算法决策,也需要人类的判断。
(6)技术建议:算法的设计者和应用者能够从算法公平检查表的方法中受益,从而最小化不公平结果的出现。这种检查表的最低要求可能包括数据审计、模型信息披露、事后分析等。
(7)算法治理:算法治理机制包括监管、激励机制、自愿性标准等。从“硬治理”(自上而下的治理)角度来看,算法治理机制可以存在于地方、州、国家甚至超国家机构层面,例如《一般数据保护条例》和《加州消费者隐私法案》。这两种治理机制通过要求数据主体对收集数据及其使用方式的透明性,以及赋予主体删除其数据的权利来解决算法公平的问题。从“软治理”(自下而上的治理)角度来看,包括由利益相关者就最佳实践和公平使用规范进行自下而上的协调推动。例如《多伦多宣言》(Toronto Declaration),它利用国际人权法的框架来保证机器学习系统中公平和非歧视的权利。
编译 | 李书峰/赛博研究院研究员
声明:本文来自赛博研究院,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
