笔记作者:Alston
原文标题:Enabling Refinable Cross-Host Attack Investigation with Efficient Data Flow Tagging and Tracking
原文作者:Yang Ji, Sangho Lee, Mattia Fazzini, Joey Allen, Evan Downing, Taesoo Kim, Alessandro Orso, and Wenke Lee, Georgia Institute of Technology
原文来源:USENIX 2018
原文链接:https://www.usenix.org/system/files/conference/usenixsecurity18/sec18-ji.pdf
1 摘要
调查跨越许多主机的攻击通常具有挑战性。来自不同主机的安全敏感文件、网络终端和内存对象之间真实依赖关系,很容易被依赖爆炸或者未定义的程序行为(比如memory corruption内存损坏)所掩盖。
动态信息流追踪技术(Dynamic information flow tracking (DIFT))仅仅能够追踪单个主机上的信息流,而且在多台主机之间维护和同步数据流标签缺乏一个有效的机制。
本文提出的方法叫做RTAG,这是一种有效的数据流标记和追踪机制,可以用于实际的跨主机环境下的攻击调查。RTAG的创新技术具有以下三点:
•记录和重放(record-and-replay):它将不同数据流标签之间的依赖关系从分析中解耦出来,从而在不同主机的独立和并行DIFT实例之间实现延迟同步。
•利用系统调用级的起源信息来计算和分配内存消耗方面的最优标签映射。
•将标签信息嵌入到网络数据包中,从而实现跨主机的数据流追踪,且网络带宽开销小于0.05%。
通过实验验证,RTAG能够恢复跨主机攻击场景的真实数据流。性能方面,RTAG能在基于DIFT分析方法的基础上,内存消耗最多减少90%;整体分析时间与之前的分析系统相比减少60% - 90%
2 介绍
现存的攻击调查系统:
•一些通过监控系统调用级别或者指令级别的事件在每台主机上分析攻击,而忽略了跨主机的攻击
•一些着眼于跨主机情景下,多主机之间的交互,但是因为他们缺乏系统调用级别的信息,所以他们的分析可能会导致依赖爆炸问题
不同解决方案及其优缺点:
•使用粗粒度信息(如系统调用):其性能开销很小,但是即使是在单主机环境下,它也不能准确地追踪依赖爆炸和未定义的程序行为(如memory corruption)
•如果使用网络会话将不同主机上的粗粒度信息联系起来:会包含太多的错误依赖
•使用细粒度信息(如来自DIFT的指令级别信息):会解决准确度问题,但是将会增加开销
•跨主机DIFT机制:在运行时,在网络数据包中使用元数据(标签)并关联它们,也会是巨大的性能下降
因此,我们提出了RTAG系统:基于记录和重放的数据流标记和追踪系统。
使用记录和重放来进行跨主机的信息流分析带来了新的挑战:
•分析时间:DIFT分析需要以一种同步的方式,在不同主机之间传输分析数据
•内存消耗:多个DIFT实例的内存消耗是巨大的,尤其是不同主机上的多个进程交互时
为了解决这两个挑战,RTAG通过标签覆盖和标签切换技术将标签依赖从分析中解耦出来,并且时DIFT独立于由通信所决定的任何特定顺序。这使得DIFT分析可以在多主机、多进程并行的环境下运行。此外,RTAG通过设计标签映射数据结构减少了内存消耗,标签映射数据结构用于追踪标签和关联值之间的关系。
评估结果表明分析时间降低了60% - 90%,内存消耗最大减少了90%。评估环境使用了真实跨主机攻击场景,包括GitPwn和SQL注入。
2.1 主要贡献
•可精炼的跨主机调查标签系统:RTAG解决了“标签依赖耦合”问题,它将标签依赖解耦合,避免在重放DIFT上进行容易出错的编排工作,并使DIFT能够独立地并行执行
•DIFT运行优化:在重放阶段,优化了运行时间和内存。运行时间优化是通过并行运行DIFT任务;内存优化是基于系统调用级别的可达性分析,为DIFT分配最佳标签大小
3 背景
3.1 执行程序日志
•使用高粒度数据,如系统调用,开销低,准确度低
•使用低粒度数据,如指令,准确度高,开销大
•结合上述二者,使用记录和重放,在记录程序运行时,执行高级别的日志记录和分析;在重放程序运行时,执行低级别的日志记录和分析
3.2 记录和重放
该技术的目的是记录软件执行时的信息,并利用存储的信息,重新执行软件并重构程序状态,其执行路径跟初次执行时一样。
根据执行记录重放任务系统的层次,进行以下分类:
•在用户层执行程序:在重放阶段效率较高,因为它可以直接将注意力放在特定程序的记录信息上,然而这种技术需要程序源码或者二进制代码,或者需要额外的空间来记录通信程序的执行(特别是通过文件系统),因为记录的信息要存储多次。•通过观察操作系统的行为来进行记录和重放:通过管理程序(hypervisor)或仿真来监视OS,在存储信息方面非常高效,然而即便是在只有一个程序是与攻击相关的情况下,该方法也得将所有程序重放一遍。•前两种方式的融合:在OS级别记录信息,在用户级别重放。
3.3 DIFT
DIFT是一种在执行程序内分析数据流的技术,具体包括以下几点:
•用“标签”标记程序中感兴趣的value
•通过处理指令传播标签
•在程序执行中的某些特定的点,检查与value相关联的标签
该技术可以准确地判断程序的两个value之间是否有关联。然而,因为它需要对每个执行指令进行额外的操作,因此会有较大的开销。

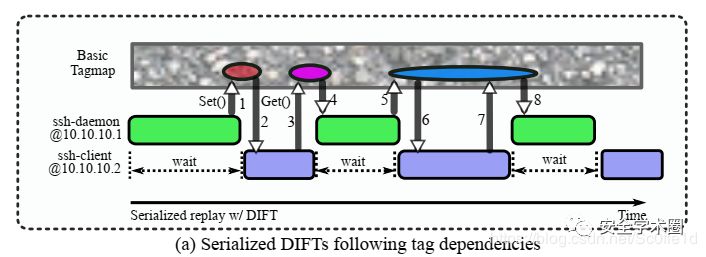
上图比较了序列化的DIFTs(串行)和RTAG加持的并行DIFTs;
•(a) 展示了在服务器上的ssh守护进程和另一台主机上的ssh客户端,两者都遵循相同的标签依赖(标签依赖在记录阶段被记录下来,DIFTs用它进行重放)
•(b) 中RTAG使用标签切换、分配和关联技术,将标签依赖从程序重放中解耦出来,从而使得每个进程在线下分析时可以并行
4 攻击实例和挑战
4.1 攻击实例
攻击实例使用GitPwnd,其行动包括多主机的文件窃取。链接:https://github.com/nccgroup/gitpwnd.
在服务器端使用gitolite[1],在客户端使用git。
4.2 挑战
跨主机的数据流追踪所面临的挑战是:同时满足准确度和效率。
目前支持跨主机的数据流捕获系统,在运行时使用DIFT,它在程序执行的主机和另外的主机之间传播标签,而不会丢弃任何标签和他们之间的依赖关系。然而这样的系统会有很大的开销。
为了同时满足准确度和效率,可精炼的系统(refinable system)首先记录每个程序的执行过程,然后使用DIFT有选择性地(与攻击相关)重放它们。然而,目前的refinable system面临的挑战是标签依赖性问题:也就是说,这种系统需要进行重放,但是在重放过程中,如果不同重放进程的标签之间存在依赖关系,那么重放必须按照与记录相同的顺序来进行。所以这种必须按顺序执行的方式就要求,DIFT任务们必须等待其上游的DIFTs来更新它们所依赖的标签,在我们所面临的多主机场景下,这种挑战更加明显
下面时GitPwnd的一个例子,来形象地阐述这种挑战。在服务器端,需要暂停sshd的重放,等待客户端的ssh-client的重放,以完成流量在Tagmap中的传播结果。此外,sshd将使用此流量作为ssh协议响应来回应ssh,这意味着需要暂停ssh的重放并等待sshd。
当存在多个通信参与者时,这种挑战就更加严重了。例如,在一个P2P的文件共享系统中执行搜索和下载文件操作,我们需要在每个节点上编排P2P客户客户端的重放工作,当面对成千上百个节点是,这是非常不切实际的。
为了解决这个问题,本文提出的RTAG,使用符号化标签(symbolized tags) 为每个独立的DIFT实例分配合适大小的标签,将标签依赖从重放过程中解耦出来。
5 概述
RTAG,将标签依赖从分析过程中(DIFT任务)解耦出来,使得DIFT独立于任何特定的顺序,允许为不同主机上不同进程并行运行DIFT,在离线分析时,这种独立性避免了按照特定顺序实时的复杂性。
•标签覆盖(tagging overlay):RTAG在传统的起源图(provenance)上维护一个标签覆盖(tagging overlay),从而独立准确地进行标签管理
•标签切换(tag switch):用于交换跨主机唯一的全局标签(global tag)和对DIFT实例唯一的本地标签(local tag)。为每个DIFT实例使用一个本地标签,这可以解开标签之间的耦合,因为之前时不同的DIFT任务共享这些标签的。DIFT完成后,RTAG将本地符号切换回它原来的全局标记
•Version:在某段数据的标签更新不止一次的时候,为了确保标签及其传播不会丢失,RTAG根据系统范围内的写操作,跟踪数据的每个更改(version)。每段数据版本都有它自己的标签,每个标签值的版本都会被正确地传播到其他的数据片段。
(不懂)RTAG不仅可以通过独立运行DIFT使分析速度得到提升,而且会减少内存消耗。我们使用最佳的符号大小,为每个DIFT分配本地符号,这足以表示涉及内存重叠的数据的熵(entropy)。
•标签关联(tag association):映射主机之间字节级的数据收发,这有助于识别跨主机的标签传播。
6 威胁模型和假设
本文的目标:通过DIFT建立一个可精炼的跨主机攻击调查系统。
文章所使用的威胁模型:攻击者有机会远程接入受害者网络,尝试窃取敏感数据,并在主机之间传播错误信息(如篡改数据)。
本文的可信计算基础(trusted computing base,TCB)包括内核、存储、网络。
假设:
•在RTAG启动之后攻击才发生
•硬件攻击不在本文考虑范围之内
•攻击者不会攻击RTAG本身和操作系统,不会篡改RTAG所用到的数据(通过安全日志机制实现,或者将数据存在远程分析服务器上)
•攻击者不会篡改主机之间传播的数据包载荷
7 标签系统
7.1 表示数据流和因果关系(tag overlay)
为了追踪跨主机的不同文件或网络数据流,我们建立了一个标签模型,它作为一个覆盖图(overlay graph)覆盖在现有的起源图之上。
在覆盖图内,RTAG将全局唯一的标签和感兴趣文件相关联,以字节级别(byte-level)的粒度来追踪它们的起源和流动。标签使得RTAG可以反向追踪文件的起源,包括从远端主机传来的文件;还能够前向追踪文件造成的影响,也可以包括传向远端主机的文件。(SLEUTH中的回溯分析取证和前向影响性分析)
起源图需要追踪以下的信息流:
•从进程到文件
•从进程到另一个进程
•从文件到进程
起源图中的边表示两个节点之间的事件(如进程节点从文件节点读数据的一个系统调用)
在标签覆盖图(overlay tag graph)中,文件的每个字节都对应一个标签键(tag key),用于唯一标识这一字节。每个标签键都与此键的原始值向量相关联。通过递归检索键的值,可以获得从这个数据字节开始的所有上游起始点,该点以树的形式扩展到远程主机上的起始点。相反,通过递归检索值的标签键,分析人员能够在树状图中找到所有影响,包括远程主机上的影响。(正向与反向分析)下图是一个例子: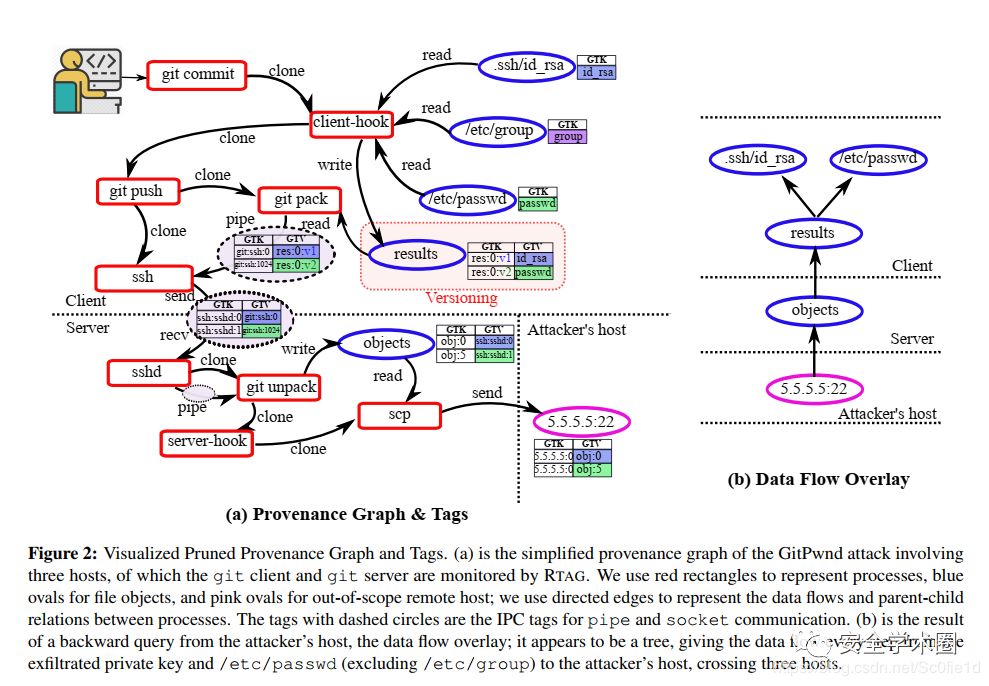
RTAG需要在每台主机的文件系统,使用全局标签(global tag)来唯一标识数据的每个字节。出于这个需要,我们使用mac地址来标识主机,使用inode、dev、crtime来标识文件,使用偏移量(offset)来标识文件中字节级的偏移量。例如,mac地址占48 bits,inode、dev、crtime分别占64、32、32 bits,偏移量占32 bits,可支持的文件大小就是4GB(offset=32,2的32次方字节),全局标签的总大小就是208 bits。
7.2 跨主机可达性分析
RTAG遵循RAIN[2]的可达性分析设计,并且将其扩展至可以处理跨主机的场景。
给定一个起始点,RTAG通过削减原始的起源图,以提取与指定攻击相关的子图,该子图包含进程和文件/网络流之间的因果关系。RTAG依赖于此子图中的粗粒度数据流来维护标签覆盖,同时执行标签切换和最优分配。
可达性分析首先遵循基于时间的数据流,以了解攻击中涉及的潜在过程。接下来,它捕获每个进程内部文件或网络的输入/输出的内存重叠并将它们标记为“干扰”,由DIFT进行处理。在干扰信息准确的情况下,重放和DIFT被快速转发到干扰开始处(例如,read系统调用),并在干扰结束处提前终止(例如,write系统调用)。
对于跨主机的网络通信,RTAG通过socket来练习数据流。进一步,RTAG通过TCP和UDP协议的套接字通信进一步跟踪字节级别的数据传输,这使得扩展跨主机的标记传播成为可能
由于RTAG从记录的文件/网络 IO 系统调用中获得了关于源和目的信息,因此可以为每个独立的DIFT任务分配最优的标签大小。
另外,此外,为了避免丢失由不同进程执行的、对同一资源的中间标签更新,RTAG监视对文件的相同偏移量的“覆盖”操作,并跟踪这个版本信息,因此它准确地知道应该在传播中使用哪个版本的标签。
7.3 解耦标签依赖
RTAG的目标是使用DIFT进行离线重放,而不增加程序运行的开销。为了使其支持跨主机环境,我们要解决的问题是如何协调不同主机上的重放程序,来追踪他们之间的标签依赖。解决方案是将标签依赖从每个进程重放过程中解耦出来,为此我们为每个DIFT使用本地标签(local tags)(也就是符号化symbolized),这需要在写作操的之前和之后来区别标签的变化,并且向其它相关的标签同步这些变化。换句话说,RTAG需要在每次IO操作之后,追踪每个标签的原始版本的动态变化(标签的多个版本)。
用下图GitPwnd的例子来说明:
(详解GitPwnd)client-hook守护进程持续从不同的文件读取数据,并保存在result文件中。同时,当受害之执行git commit操作时,git packet应用从results文件进行复制,然后通过pipe IPC(Inter-Process Communication)用SSH发送出去。为了正确地分辨下列两个数据流:
•id_rsa→results→pipe•/etc/passwd→results→pipe
RTAG需要为results维护两个版本的标签,client-hook上的DIFT为$id_rsa$存储的表示其来源的标签为$results.v1$,为$etc/passwd$存储的表示其来源的标签为$results.v2$(图中用红色虚线表示);因此git pack上的DIFT可以分辨 git:ssh 数据的来源:
•偏移量为0来自 results.v1,也就是来自 id_rsa•偏移量为1024来自 results.v2,也就是来自 etc/passwd
更重要的是,这个时候client-hook和git pack上的DIFT任务就可以独立执行了,而不会由于在results文件上的重写而导致中间标签值的丢失。
为了更加方便地支持这种标签化,我们附加了一个32位的版本字段(version field),用来表示文件中有关文件IO操作的数据的版本。仅仅在由可达性分析所决定的的数据干扰出现时,才会使用版本字段。通过实验,我们为版本字段分配32 bits的长度,可以在500天的实验环境中精确找出IO系统调用。
7.4 切换全局和本地标签
7.1节中定义的全局标签,足以在多主机环境下,表示特定版本文件的某个字节。但是为每个DIFT任务分配全局标签,实际上是一种浪费,因为RTAG的每个DIFT任务仅覆盖一个进程组,因此确保进程组级唯一性的本地标签就足够了。因此,对于每个DIFT任务,我们基于其源符号的熵使用不同的标签大小。在进行DIFT之前,RTAG将标签从全局标签切换到本地标签,并在完成DIFT后将标签切换回全局标签。DIFT的标签是本地的,因为它仅需要唯一地标识当前进程内DIFT(in-process DIFT)中源的每个字节,而不是标识跨主机的数据字节。
进一步,每个DIFT中源的数量取决于可达性分析,通常会由数据修剪而极大的减少。换句话说,本地标签的大小取决于干扰(interference)情况。(干扰越多,也就是可达数据越少,有效的数据越少,就可以用更小的local tag来表示)。因此,本地标签的信息熵要远小于全局标签。举个例子来说,如果一个程序仅从DIFT中标记为源的文件那里读取10个字节,那么本地标签仅用4 bits就可以将其表示,这与全局标签的208 bits相比简单了不少。
标签的大小不仅会影响源和目的的symbol,还会影响所有中间存储器和寄存器,因为标签会根据DIFT的传播策略,随每个指令的执行一起被复制,合并或更新。标签大小;影响整个标签映射的内存成本,所以标签切换显着降低了DIFT的总体内存成本。
7.5 最佳本地标签分配
•采用记录-重放机制的原因:
现存的DIFT引擎系统是在程序运行时工作的,事先不了解关于数据的源或者目的地的信息,所以要为其分配一个固定大小的标签,以确保其足够大。这样就会消耗大量的系统资源。
相比于在程序运行时执行DIFT,RTAG采用的是记录 - 重放机制,这样,在重放阶段实施DIFT时,关于数据源和目的的信息就已知了。这样,我们就可以动态调节标签大小,而不是采用固定大小的标签了。
下图比较了不同DIFT引擎标签映射的内存消耗情况:
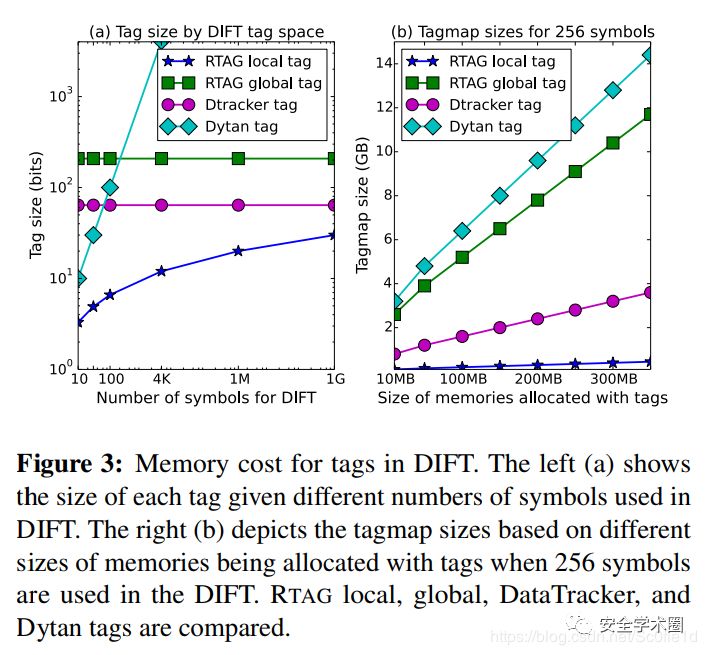
•操作过程:
在执行DIFT之前,RTAG会计算最佳本地标签来标记源,并在将源加载到进程的内存空间时(例如,通过read() 系统调用)将全局标签替换为本地标签。在执行DIFT时,当内存单元或寄存器因为某些标签被污染时,RTAG会为中间位置分配标签。当传播到达目的地时(例如,通过write() 系统调用),RTAG将本地标签替换为原始的全局标签,并更新目的地的标签值。
7.6 标签关联
为了追踪不同主机之间的数据流,我们还附加了操作内核的hook the socket处理,以启用跨主机标记(cross-host tagging)。本文提出了一种 “in-band” 的方法,在主机之间追踪数据流,这种方法尤其适合系统层面的可达性分析和DIFT。
本文设计的跨主机的标签方法依赖于socket协议的特征:TCP和UDP
•TCP:可靠传输,我们依赖TCP连接中字节的顺序,从而可以在字节层面识别数据流。注意到,尽管TCP控制着数据流的顺序,但是发送发和接收方之间在接受和发送数据的时候,可能运行着不同数目的系统调用。举个例子,发送方可能执行五个writev()系统调用以发送10,000字节的数据(每个调用2,000字节),而接收方可以进行10个read()调用(每个调用1,000字节)以检索完整的数据。这就是为什么需要对发送或接收的字节进行计数,而不是对系统调用数进行计数的原因。
•UDP:不可靠传输,在传输过程中可能会丢包。因此,我们不能依赖传输字节的顺序,因为目标主机不知道应该到达哪些数据以及丢失了哪些数据。为了支持UDP,我们在源主机的每个发送相关系统调用中嵌入了一个小的“跨主机”标签,并在目标主机的接收相关系统调用中解析了该标签。在计算校验和之前,将标签作为用户数据报的一部分插入到数据报的开头。如果数据报传输成功,RTAG就会知道从源到目的的数据长度。如果目标主机发现接收到的数据报已损坏或完全丢失,它将丢弃该数据报,因此RTAG也意识到丢失的情况,并从可达性分析和DIFT中清除了该入站数据。评估显示,TCP情况的通信成本为0,而UDP的成本在基准测试中也很微不足道。
跨主机标签表示跨主机的两个进程之间的套接字通信中的字节级数据。每个标签键(tag key)使用源和目的进程凭证,代表一个套接字会话中的数据流量;使用偏移量来标识字节层面的数据。
对于会话的唯一性,我们使用进程标识符(pid)和进程创建时间来标识每个进程。
标签值(tag value)表示标签键的来源,其由DIFT决定,并且更新为全局标签图(global tag map)。
对于跨主机的标签,我们同样在执行DIFT之前进行切换,然后在之后进行恢复。
•处理进程内通信:
RTAG也可以追踪两个进程之间的数据传送)。IPC使用系统调用作为控制接口,RATG通过hook系统调用来追踪传送的数据。当进程使用pipe将数据发送到子进程时,RTAG监视读写系统调用以跟踪传输的数据。在可达性分析过程中,我们创建标签键来标记从parent发送到child的每个字节。标签值由DIFT实现。另外,RTAG基于共享内存来追踪IPC,这样就可以在进程的内存单元内,传播此共享内存的标签。这些过程不需要单独的标签分配。
7.7 查询系统
例如,在图中,对攻击者受控主机5.5.5.5:22的向后查询(backward query)将返回图(b)中描绘的树形数据流覆盖图。
另外,前向查询会从被请求的标签键到它所有的影响,返回数据流的每一个片段。它依赖于反向映射,在该映射中标签键和值被交换以定位文件的下游影响。例如,对客户端的私钥id_rsa的前向查询返回一个流:

通过对这两个节点执行前向和后向查询,然后计算两个结果树的交点,点对点查询可提供起源图中两个节点之间的详细数据流。
8 实施
系统实施是基于单主机的RAIN[3],然后在其基础上扩展了标签系统。
关于追踪Socket连接:
•TCP:使用计数器,通过追踪send/write系统调用的返回值,来计数发送或接受字节的总数
•UDP:在内核函数sendmsg内负载缓冲区的开头,插入一个递增的四字节序号;而不是在类似于send/recv这样的系统调用函数内插入,为的是避免影响用户程序的接口、避免校验和计算。在接收端,在计算完校验和之后,在recvmsg中剥去序列号,得到原始的载荷。
9 评估
评价目标在于解决以下问题:
•RTAG在跨主机攻击调查中,处理数据流查询时的表现如何,包括前向查询、后向查询、点对点查询
•RTAG对基于DIFT的分析提升了多少效率,包括时间和内存消耗
•RTAG会造成多少带宽和内存消耗
9.1 攻击场景
下图总结了攻击调查中,处理一个query的每个阶段的统计情况:原始的Provenance Graph包含了所有的主机;Pruned Graph中,由可达性分析将与攻击无关边和节点过滤掉;Data Flow Overlay中,标签存储查询所涉及的每个数据字节的来源。
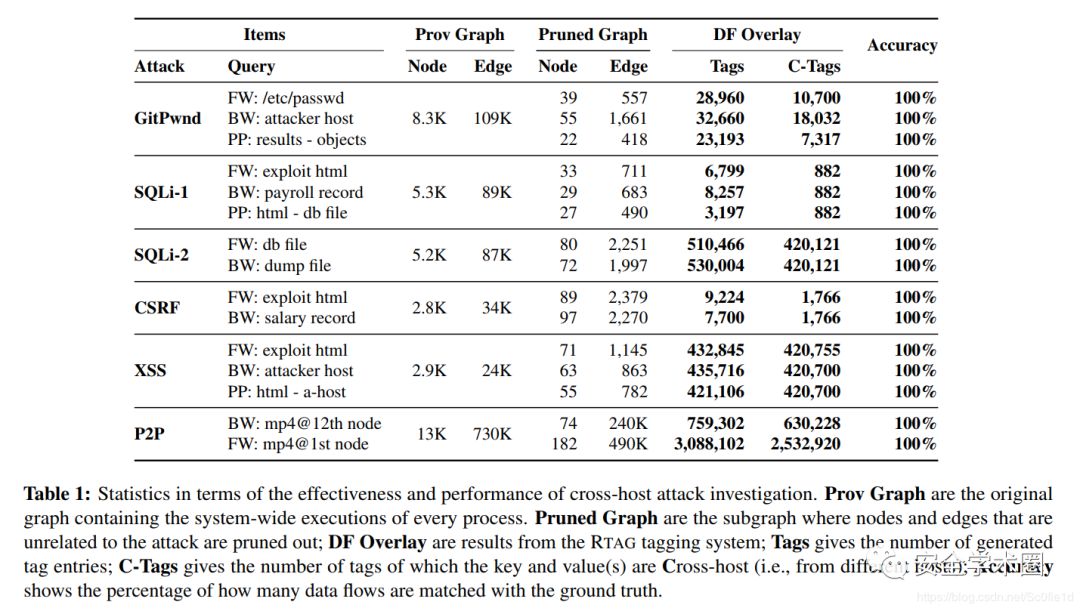
下图汇总了每个query所花费的时间和内存:

评估所用到的场景:
•GitPwnd
•Web-based Attacks:SQLi、CSRF、XSS
•Memory Corruption涉及内存损坏的攻击:整数溢出、缓冲区溢出
•P2P网络中文件的传播:我们还运行RTAG来跟踪P2P网络上恶意文件传播中的数据流,这在分散式文件共享中被视为越来越大的威胁
9.2 性能
•DIFT性能:
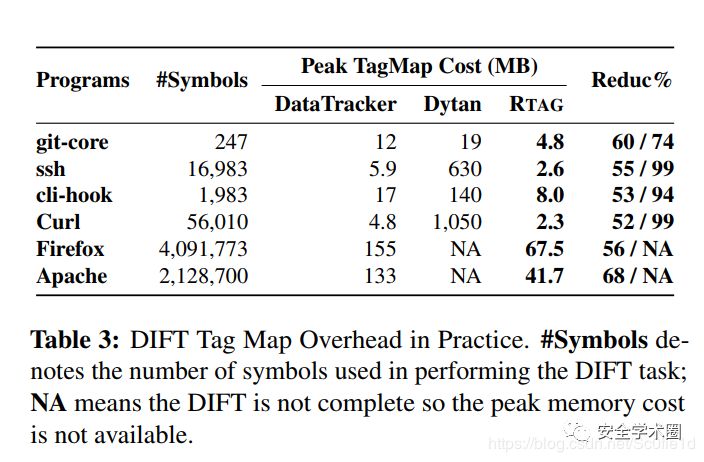
在RTAG中,总时长消耗取决于最长的DIFT任务,所以还需要继续寻找集成化的进程间并行DIFT技术来进一步降低时间消耗。
•运行时间开销:
分别用CPU和IO运行时间来衡量。CPU消耗时间如下图所示,结果表明RTAG和RAIN相似,其运行时间开销都比较低。
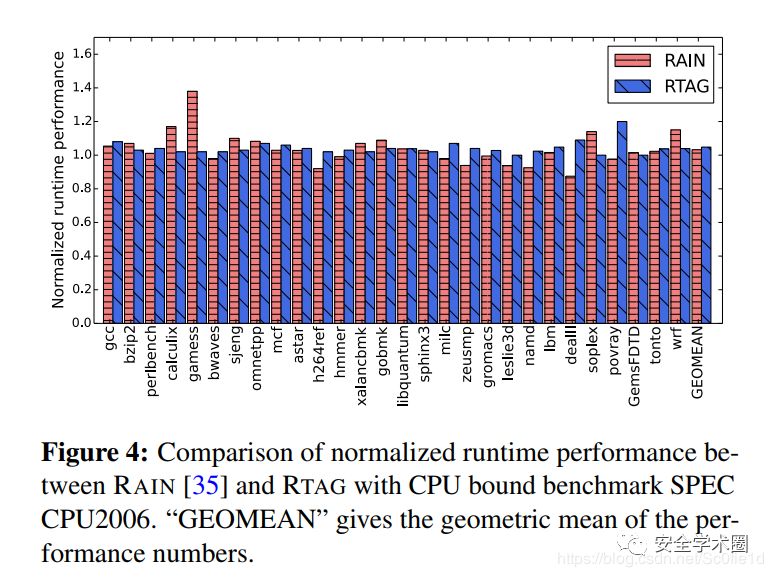
IO运行时间消耗如下图所示

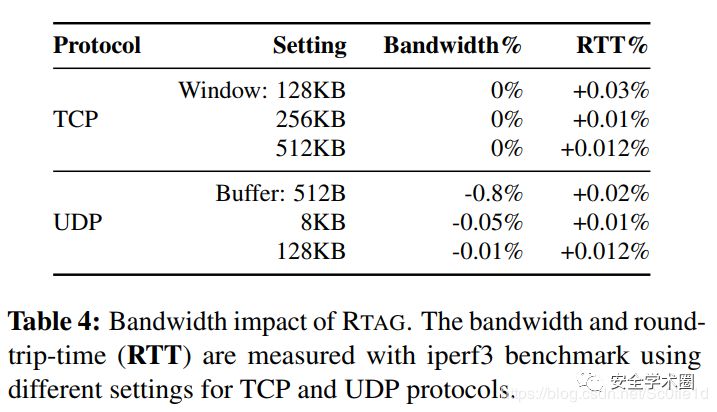
•网络性能开销:
所有的网络开销都可以忽略不计。
10 相关工作
•DIFT:动态污点分析是一种众所周知的技术,用于在程序运行时逐条指令跟踪信息流指令,而无需依赖程序源文件或二进制文件的语义。DIFT可用于策略执行,恶意软件分析和检测隐私泄漏。
•Provenance Capturing:使用data provenance来调查APT是比较流行的研究领域。
•Network Provenance:网络层面的provenance也是研究热点。其弱点显而易见,就是无法检测大部分终端上系统层面的因果关系。但是基于网络和基于主机的Provenance是相互正交的,因此我们可以将二者结合起来。
•记录和重放系统:确定性的记录和重放是研究热点,最新的作品还可以记录不确定性的事件。
未来研究的方向:
•使运行RTAG的主机与不运行系统的主机可互操作。为此,计划将标签信息嵌入UDP标头的可选字段中
•能够实现在给定网络中,RTAG可能没有运行在每台主机上的情况下,仍可以识别信息流并还原事实
•将进程内(in-precess)的并行DIFT集成到RTAG中,进一步优化运行时间
•减少对不确定性输入的存储空间需要
•扩展RTAG支持的query,以便可以比较同一程序的不同执行相关的信息流。这样,就有可能查明程序何时何地受到威胁。
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
