融合多特征的视频帧间篡改检测算法
肖辉1,2, 翁彬1,2, 黄添强1,2, 普菡1,2, 黄则辉3
1 福建师范大学数学与信息学院,福建 福州 350007
2 福建省大数据挖掘与应用工程技术研究中心,福建 福州 350007
3 世新大学,台湾 台北 350108
摘要:传统的视频帧间被动取证往往依赖单一特征,而这些特征各自适用于某类视频,对其他视频的检测精度较低。针对这种情况,提出一种融合多特征的视频帧间篡改检测算法。该算法首先计算视频的空间信息和时间信息值并对视频进行分组,接着计算视频帧间连续性VQA特征,然后结合SVM–RFE特征递归消除算法对不同特征排序,最后利用顺序前向选择算法和Adaboost二元分类器对排序好的特征进行筛选与融合。实验结果表明,该算法提高了篡改检测精度。
关键词: 视频篡改检测 ; 融合算法 ; 特征选择 ; Adaboost二元分类 ; 视频分组
中图分类号:TP393
文献标识码:A
doi:10.11959/j.issn.2096−109x.2020007
1 引言
数字视频为信息的主要载体之一,到2021年其在互联网上的视频流量将占消费者使用流量的85%。与此同时,大量的视频剪辑软件使视频篡改成为一项很轻松的工作,而这些篡改后的视频往往人眼很难分辨出来。然而,视频的真实性和完整性在新闻媒体、科学发现、法庭取证等领域都十分重要。因此,视频篡改检测已经成为近年来一个热门的研究方向。
视频的帧间篡改包含帧复制粘贴、帧插入和帧删除等操作,这些篡改方式易于实现,且对社会安全危害较大。因此,帧间篡改检测算法吸引了大量的研究者,近年来不断有新方法被提出。然而,这些方法往往通过提取视频的某个特征来识别篡改。而现实世界的视频是丰富多彩的,不同的光照环境、模糊程度和画面运动的快慢等都有可能导致某种特征失效。所以,已有的检测算法一般对某类视频比较有效,而对其他视频的效果不好。将这些特征融合起来以提高篡改检测的效果是一个新的研究方向。
为解决上述问题,本文提出了一种融合多特征的视频帧间篡改检测算法。针对待检测的视频,该算法首先计算多个特征,然后对这些特征排序并筛选,最后得到的融合检测结果往往要优于基于单个特征的方法。此外,事先将视频分组,再进行特征融合来提高融合算法的检测精度。
2 相关工作
2.1 帧间篡改检测
视频帧间篡改的检测已有不少研究成果。Chao等提出了一种基于光流特征的帧间检测方法。使用小窗口移动计算第一帧和最后一帧以及相邻帧之间的光流,出现帧删除或插入时,光流的高度不一致,用二分查找方案来检测插入篡改,并应用双自适应阈值来检测删除篡改。然而,光流特征对篡改帧数少的视频的检测精度不高。Wu等提出了基于速度场特征的检测方法。速度场特征是由粒子图像测速(PIV)的关键点计算相邻帧并估计它们的位移,根据速度场序列计算相应的相对因子序列,最后用广义极值学习偏差(ESD)来识别篡改类型并定位,速度场特征随压缩比例的增大,检测精度会大大降低。Liu 等将RGB颜色空间转化为2D对立色度空间,使用Zernike矩来计算二维对立色度空间的Zernike色度变换矩(ZOCM)执行粗略检测,利用相邻帧ZOCM的差异性来提取异常点。粗检测过程计算速度快,但会存在误检测现象,最后使用Tamura粗糙度特征来进行精细计算得到更准确的帧复制粘贴位置,篡改区域移动速度过快时,Tamura粗糙度特征的检测精度不高。Wang 等分析了MPEG-1,2压缩视频,当视频序列遭受伪造(帧删除/插入),一些帧从一个GOP组删除或插入另一个GOP组时,会出现较大的运动估计误差。它依赖于P帧残差特征产生的周期性伪像,用傅里叶变换检查P帧残余误差造成的峰值从而判断出伪造视频。基于此基础,Aghamaleki等提取了具有空间约束的算法来检测P帧残差特征量化误差的丰富区域,减少运动对P帧残差的影响,继而用小波变换丰富频域中的量化误差轨迹。利用P帧残差特征的缺点在于对删除整个GOP组的伪造痕迹无法被量化出来。Li等提出了一种基于结构相似度(MSSIM)特征的新算法,由于重复帧之间的相似度值高于正常帧之间的相似度值,通过测量短子序列之间的时间相似性度量策略来检测帧复制粘贴篡改。文献同样使用MSSIM特征,基于相邻帧之间 MSSIM 商具有连续性,使用两次切比雪夫不等式及阈值法对提出的MSSIM商特征进行异常点检测,从而实现对视频帧插入和删除的篡改检测和定位。MSSIM利用了视频帧之间的连续性,用作视频篡改检测时有较好的效果,本文将其融入提出的算法中。上述的帧间篡改检测技术通常只使用某个特定的特征来寻找异常点。然而,现实世界的视频往往具有不同的特点,如不同的光照、颜色、亮度和运动的剧烈程度等。因此,基于单个特征的篡改检测方法,一般只对某类视频有较好的效果,而对另一类视频检测效果较差。本文的思路是建立一个算法来融合多个不同特征。
2.2 视频质量评估
视频质量评估(VQA,video quality assessment)模型针对视频每帧的序列进行计算,随时间记录汇总每帧的测量质量,以评估整个视频的质量。VQA特征已有不少。本文不仅测试将其他 VQA 特征应用于视频帧间篡改检测的可行性,而且将它们融合到一个统一的算法中。
2.3 多特征融合
Liu等通过融合图像质量评估特征(IQA, image quality assessment)来实现客观图像质量评估,根据失真类型将图像分为3到5组,使用机器学习方法训练预测模型,在6个代表性数据库中进行了测试,结果表明提出的融合方法比现有的IQA方法性能好。Lin等融合VQA特征进行客观视频质量评估,将视频按压缩率和调整大小分组,在每组内融合几个 VQA 特征预测感知质量,通过机器学习减少了内容多样性并提高融合性能,在 MCL-V 数据集中进行测试,结果表明融合VQA特征比单个VQA特征的评估效果更好。上述特征融合方法均是针对质量评估的。在篡改检测方面,Huang等提出了融合音频的多通道方法。该方法利用篡改视频文件的视频通道时会影响音频通道的原理,取得了较好的检测效果。然而,许多视频常常没有音频通道(如监控视频),这就限制了该方法的应用范围。Shanableh等从视频比特流中提取多特征来对 MPEG 视频进行检测,得到了较好的效果。然而,他们只用到了MPEG视频中P帧的一些简单特征,而本文的算法和所选用的特征则不受限于具体的视频编码格式。而且,他们的方法仅对帧删除的篡改进行了测试,而本文会对复制、插入和删除等篡改都进行测试。此外,本文还提出利用视频分组来改进特征融合的效果。
3 帧间篡改检测融合算法
融合算法的目的是融合多个特征,获得比利用单一特征检测精确度更高的视频篡改取证算法。但视频特征数量多,将所有可能的组合遍历一遍显然是不可取的。本文使用特征递归消除算法(SVM-RFE)对特征进行排序,然后用文献中提到的顺序前向选择(SFS,sequential forward method selection)算法和Adaboost二元分类器对排序好的特征逐个融合,每次留下能提高当前得分的特征,这样只要遍历一遍特征集就能得到一组满意的结果,实验表明该方法可以提高融合算法的检测精度。融合算法流程如图1所示。
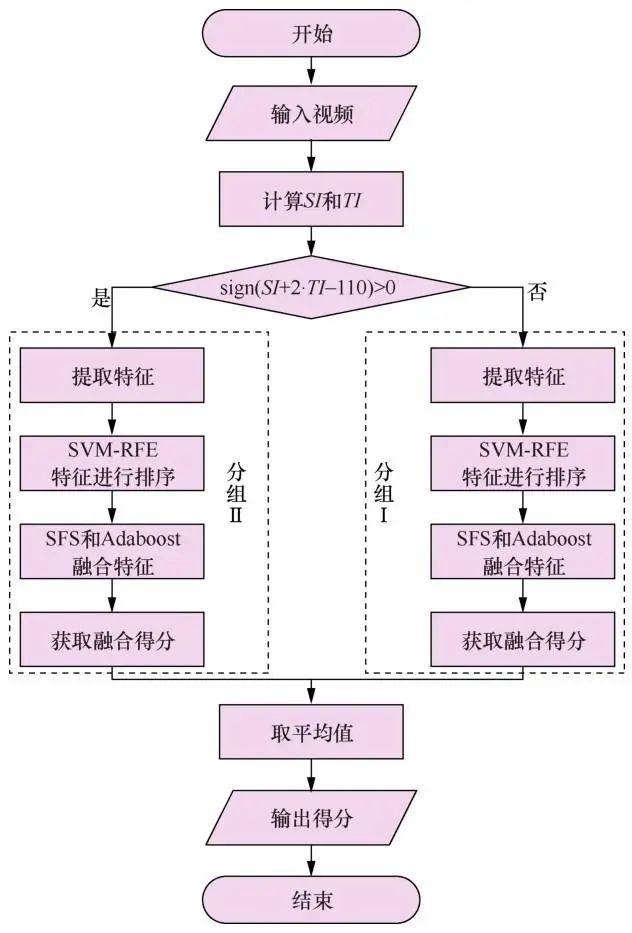
图1 融合算法流程 Figure 1 Fusion algorithm flow
3.1 视频分组
将类似内容的视频分类到同一组当中,可以在每一组中构建更加准确的检测模型。在每一组中,希望有足够多的样本和视频来学习和训练。根据实验的情况分析发现,利用空间信息(SI)和时间信息(TI)将视频分成两组,可以取得比不分组更好的检测效果。
国际电信联盟组织(ITU-T)给出了空间信息和时间信息的定义。SI用于度量图片中的空间细节。空间更复杂的场景的SI值一般会更高。TI用于衡量视频序列时间变换。高运动序列中的图片的TI值通常会更高。SI基于Sobel滤波器,首先用[Sobel(Fn)]滤波器对时间n处的视频帧Fn (亮度平面)进行滤波,然后计算经过Sobel滤波帧像素上的标准偏差。对视频序列上每一帧重复该操作,并产生场景空间信息的时间序列。选择时间序列中最大值来表示场景的空间信息。以上过程可以用式(1)表示。
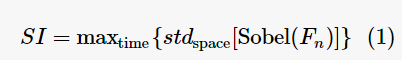
其中,Fn表示视频帧序列的第n帧,[Sobel(Fn)]表示的是对视频帧进行 Sobel 滤波,stdspace表示取标准偏差,maxtime表示取最大值。
TI 基于视频帧之间的运动差异特征Mn(i,j),是连续两帧之间相对位置上的(亮度平面的)像素值之差。在视频帧序列第n帧处, Mn(i,j)定义为
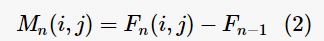
其中,Fn(i,j)是视频帧序列第n帧i行j列处的像素值。
计算TI,先对视频帧序列提取的运动差异特性Mn(i,j),再计算标准偏差。TI为沿着时间轴计算Mn(i,j)的空间标准偏差的最大值,可以用式(3)表示。
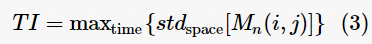
利用以下分割线将视频分为两组,如式(4)所示。

其中,x为视频样本,SIx和TIx分别为对应视频的SI和TI值。图2展示了SULFA视频库中的视频分组结果。其中,为了使数据样本均匀分布到每一组中,取a=1,b=2,c=-110。当Gx值为–1时,将视频分为组Ⅰ;当Gx值为1时,将视频分为组Ⅱ。
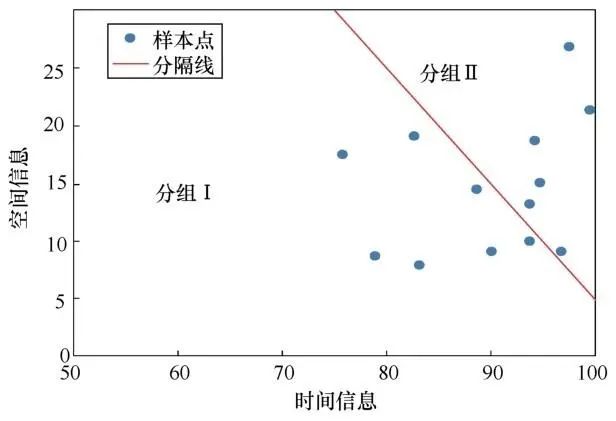
图2 视频分组 Figure 2 Video grouping
3.2 特征提取
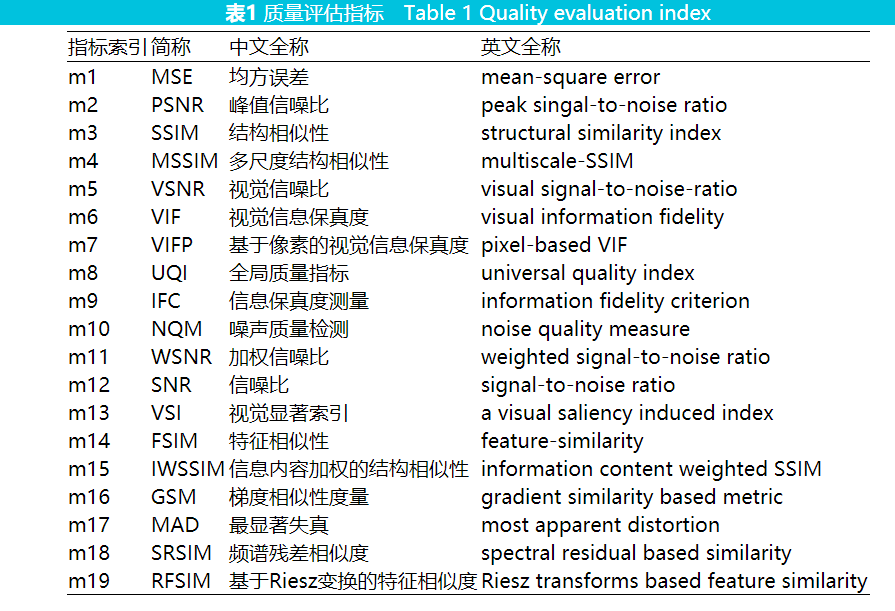
在分组之后,分别对每组里的视频提取特征。因为要检测视频的帧间篡改,所以计算视频的帧间 VQA 特征。首先将视频分解成帧序列,然后逐帧提取两帧间的19个VQA特征(见表1)。有以下帧序列:
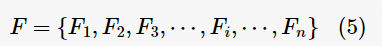
对于n个连续的视频帧,可以提取n–1次帧间相关特性,每次都提取19个VQA特征,如式(6)所示。
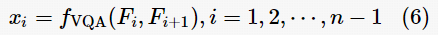
其中,fVQA代表所有的VQA特征提取方法,xi表示相邻帧Fi和Fi 1+ 所提取的19个VQA特征。xi作为模型的输入样本。在未被篡改的原始视频帧序列中,相邻帧间具有很强的相关性;而在被篡改的视频帧附近,相关性会减弱,此时某些 VQA特征会有明显变化。在这 19 个 VQA 特征中, SSIM、MSSIM、VIF、VIFP、UQI、VSI、FSIM IWSSIM、GSM、SRSIM、RFSIM的特征值介于0到1之间,特征值越接近1表示相邻帧相关性越高。MSE值越小说明两帧之间的相关性越高。而PSNR、VSNR、IFC、NQM、WSNR、SNR、MAD 特征值越大则说明两帧之间相关性越高。在实验过程中,所有数据的数值被归一化为0到1之间。
3.3 特征排序与融合
在提取特征后,首先对这些特征排序,然后根据排序的结果进行融合。排序的目的是尽量让样本中对融合性能有正面贡献的特征排在前面。本文使用特征递归消除算法对特征进行排序,该方法使用特征值的大小作为排名标准。SVM-RFE算法过程如算法 1 所示。算法输入样本集; 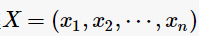 ;y={1,0},其中n为样本数,每个样本xi表示的是两帧之间提取的VQA特征,包含了表1 中展示的所有特征;y 为样本标签,正常点处提取的样本用1表示,异常点处提取的样本用0表示。初始化特征序列s(包含表1中的所有特征)和特征排序序列r(初始值为空)。首先选取训练样本Xs,包含s中的所有特征。然后使用选取的样本Xs训练SVM分类器。接着根据训练 SVM 分类器得到最优化权重向量 w。然后使用最优化权重向量w计算候选特征的排序标准 c,排序标准 c 越小说明对应的特征在当前训练样Xs中是最不重要的。之后选出排序标准c中得分最小的排序特征f。然后将特征f放入特征排序列表r的表头,即本轮选取的特征f都是已选特征的排序列表r中的最佳特征。最后从特征序列s中删除本轮选中的最不重要的特征f。重复以上步骤,直到特征序列s为空。
;y={1,0},其中n为样本数,每个样本xi表示的是两帧之间提取的VQA特征,包含了表1 中展示的所有特征;y 为样本标签,正常点处提取的样本用1表示,异常点处提取的样本用0表示。初始化特征序列s(包含表1中的所有特征)和特征排序序列r(初始值为空)。首先选取训练样本Xs,包含s中的所有特征。然后使用选取的样本Xs训练SVM分类器。接着根据训练 SVM 分类器得到最优化权重向量 w。然后使用最优化权重向量w计算候选特征的排序标准 c,排序标准 c 越小说明对应的特征在当前训练样Xs中是最不重要的。之后选出排序标准c中得分最小的排序特征f。然后将特征f放入特征排序列表r的表头,即本轮选取的特征f都是已选特征的排序列表r中的最佳特征。最后从特征序列s中删除本轮选中的最不重要的特征f。重复以上步骤,直到特征序列s为空。

对输出的特征排序列表r,使用顺序前向选择算法对特征进行融合。思路是依次添加待选特征,直到最终选出得分最高的一组特征集。算法过程展示在算法2中,其中,特征集 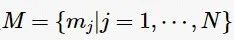 ,1到N的排序是按照SVM-RFE算法输出的特征排序列表r排序的。判断特征mj是否加入子集Ms的目标函数J为Adaboost二元分类器。Adaboost分类器的工作原理是先从初始训练样本中训练出一个基学习器,再根据基学习器的表现对样本分布进行调整,使在先前做错的样本在后续的学习器中受到更多的关注,然后基于调整分布的样本来训练下一个基学习器;重复进行这个步骤,直到弱学习器学习的次数达到预设的阈值T时,最后将这T个学习器通过结合策略进行结合,得到最终的强学习器。Adaboost的优点在于作为分类器时,分类精度高,在本文的实验结果中也证明了这一点。因此,在本文的工作中用Adaboost分类器作为目标函数J判断当前特征是否加入特征子集Ms。当J(Mn+mj)>J(Mn)时,特征mj加入子集Ms,直到遍历完所有的特征,选出一组得分最高的特征作为最终的融合特征。
,1到N的排序是按照SVM-RFE算法输出的特征排序列表r排序的。判断特征mj是否加入子集Ms的目标函数J为Adaboost二元分类器。Adaboost分类器的工作原理是先从初始训练样本中训练出一个基学习器,再根据基学习器的表现对样本分布进行调整,使在先前做错的样本在后续的学习器中受到更多的关注,然后基于调整分布的样本来训练下一个基学习器;重复进行这个步骤,直到弱学习器学习的次数达到预设的阈值T时,最后将这T个学习器通过结合策略进行结合,得到最终的强学习器。Adaboost的优点在于作为分类器时,分类精度高,在本文的实验结果中也证明了这一点。因此,在本文的工作中用Adaboost分类器作为目标函数J判断当前特征是否加入特征子集Ms。当J(Mn+mj)>J(Mn)时,特征mj加入子集Ms,直到遍历完所有的特征,选出一组得分最高的特征作为最终的融合特征。

使用算法 1 对特征进行排序,再使用算法 2选择特征并逐个融合特征,最终每个分组得到一组特征集。在所有样本中使用融合特征集获取融合样本,将样本分为训练样本和测试样本。使用融合测试样本训练Adaboost二元分类器,获得一个融合算法的分类模型。将测试样本输入融合分类模型得到每组融合模型得分。为了方便分组融合模型与不分组融合模型的比较,使用平均法取两个分组的平均值作为融合算法的得分,最后得到整个融合算法的视频取证得分。得分越高说明融合算法检测帧间篡改的精度越高。
4 实验结果与分析
4.1 实验设置
本文使用了华南理工的视频篡改检测数据库(VFDD,video forgery detection database)Version1.0和 SULFA(surrey university library for forensic analysis)视频库中的220个视频对融合算法的有效性进行验证。实验中使用Matlab R2016b提取视频特征,使用Scikit-learn库进行特征选择以及分类。实验环境为Intel Corei5-4590 CPU 3.30 GHz、8 GB内存、Windows 10系统。
4.2 实验样本来源
首先构造一个视频帧间篡改的数据集。该数据集包含44 686条样本,其中正负样本各占一半。视频内容包括日常生活场景,如行人走路、汽车在公路行使、做体育运动(踢球、打羽毛球、打乒乓球、跑步)、自然风景等。图3展示了帧间篡改操作。其中,图3(a)为原始帧序列(以第1到第12帧为例);图3(b)显示了帧插入篡改操作,其中 x、y、z 为插入帧;图3(c)显示了帧删除篡改操作,其中第7、8、9帧(用白色表示)已从视频帧序列中删除;图3(d)显示了帧复制粘贴篡改操作,第10到第12帧被复制粘贴到了第3帧和第4帧之间。上述3种帧间篡改操作会导致视频帧序列发生变化,在构造样本时,篡改点处对应的是负样本。如图3(b)中,编号为3的帧和编号为x的帧之间是异常点,编号为z的帧与编号为 4 的帧之间也是异常点;图3(c)中,编号为 6的帧与编号为10的帧之间是异常点。图3(d)中,编号为3的帧与其相邻的编号为10的帧之间是异常点,编号为12与相邻的编号为4的帧之间是异常点。在异常点处的样本是负样本。帧间篡改的视频异常点比正常点要少得多。然而,训练分类模型一般要求正负样本数相当才能训练出好的分类模型。因此,在生成数据集时,每生成一个正常点,就随机构造一个异常点。构造方法如下,假设原始视频帧序列是从F1到Fn,如果正常点F1和F2之间提取特征作为正样本,则同时随机选取一帧Fi,F1与Fi构成负样本。这样,对于一个原始视频可以生成等量的正样本和负样本。考虑到视频篡改的帧数一般超过5帧,本文选取的随机帧Fi与当前帧的间隔在5~35帧之间。

图3 帧间篡改操作 Figure 3 Interframe tamper operation
4.3 分类器的比较与选择
一组样本的众多分类器的得分如表2所示。从表中可以看出AdaBoost分类器的效果较佳,优于其他分类效果。选择AdaBoost作为分类器时,分类精度高,作为简单的二元分类器时,构造简单,且不容易发生过拟合。

4.4 实验结果与分析
大量的实验结果表明融合所有特征往往不能达到最好的效果。因此,一般不需要融合所有特征,只需要找到一个较佳的融合数量即可。在表3中第1到19栏展示了逐一添加特征的结果,第20栏是本文融合算法添加特征的结果,并绘制了结果曲线,如图4所示,以便更好地展示融合效果。表3中索引号1到19栏展示的是先对特征进行排序,按照排序结果依次添加特征后的得分,其过程中没有排除任何特征。最后一栏(索引号20)展示的是使用本文中提到的算法 2(只添加能提高当前检测精度的特征)融合特征的结果。表3中第一个所选的特征是给定样本下得分最高的特征,在增加一个特征后,其性能反而下降了。图4可以清晰地看出当特征数从2增加到4时,性能有大幅提升。当融合特征数为4时有最佳性能。特征数大于4之后,性能有所下降也有所上升,一般保持在一个比较平稳的水平。最后一栏只融合了部分特征也获得了较高的得分。从图4中可以看出融合方法确实有利于提高检测精度且使用本文的算法不需要融合所有特征也可以选择一组效果较佳的特征。高维数据性能有所下降而不是改善的原因有两点:特征增加意味着噪声和误差也随之增加;样本数据量不足以获得统计上合理和可靠的估计。如果选取一组样本,要找到最佳的特征组合,需要遍历所有可能,显然,这是不可取的。那么,使用本文提到的顺序前向选择算法,可以找到一组性能较佳的特征,而只需遍历一遍所有特征,且复杂度低。
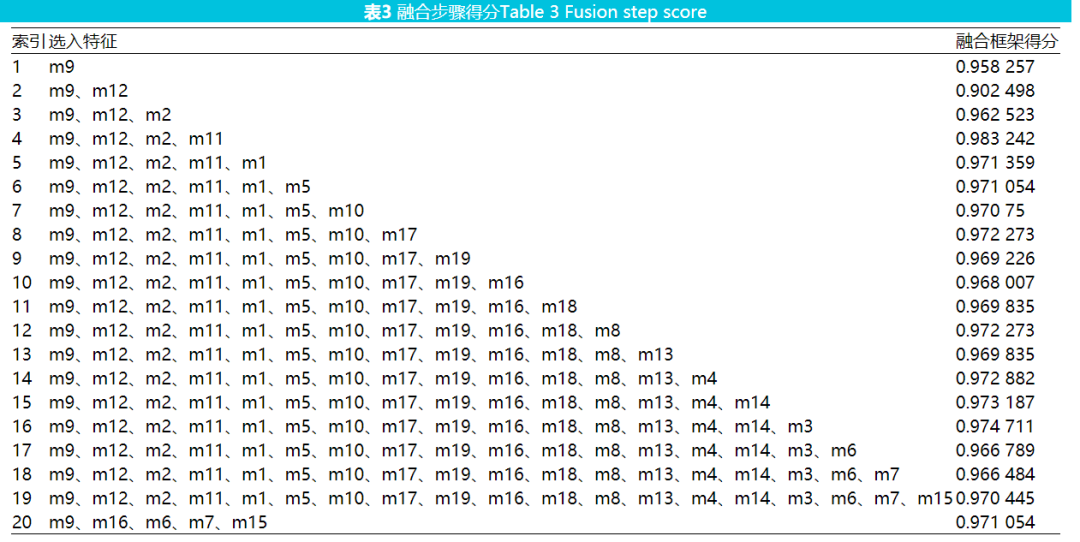
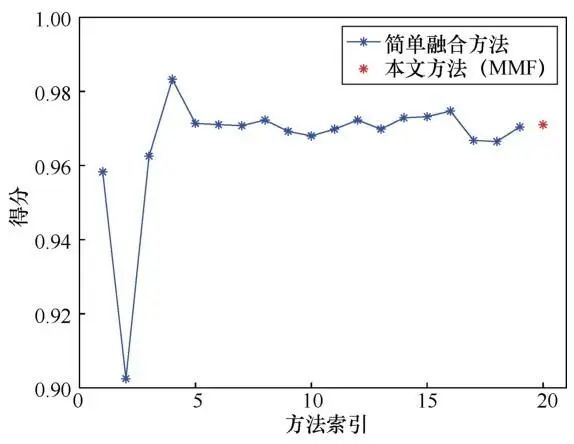
图4 融合方法曲线 Figure 4 Fusion method graph
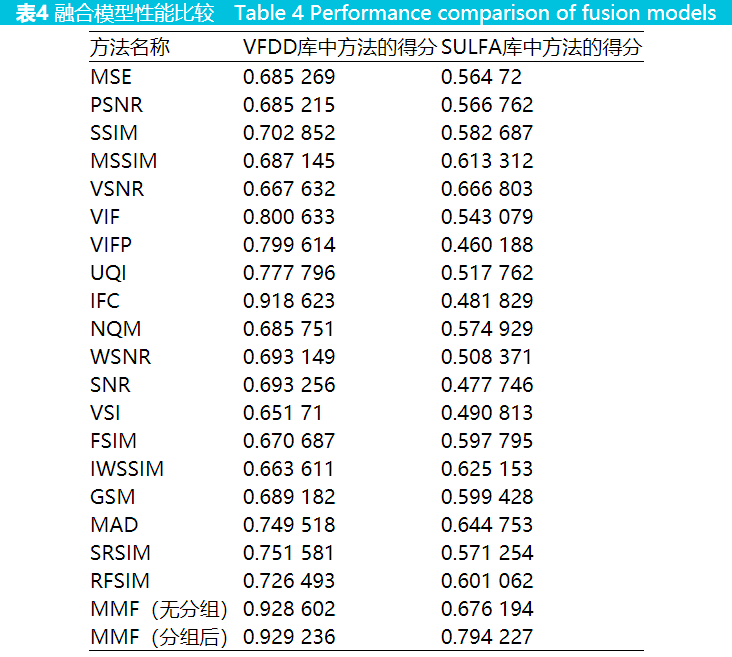
对本文所提融合算法与单一 VQA 方法在华南理工视频篡改检测数据库和 SULFA 视频库的精确度进行比较。结果如表4所示。表中第一列展示了方法的名称。其中 MMF 为本文的融合算法,MMF 分有分组和无分组两种,第二列是VFDD 库中每种方法的得分,第三列是 SULFA库中每种方法的得分,得分越高表示检测精度越好。在 VFDD 视频库中表现最好的单一特征是IFC(得分0.918 623),而在SULFA视频库中表现最好的单一特征为VSNR(得分0.666 803);同时也可以看出 IFC 特征在 SULFA视频库中的得分只有0.481 829,相比于其他特征的表现有明显的不足,同样VSNR在VFDD视频库中的表现相对于其他特征也有明显的不足。从表4中可以看出融合算法在两个数据库中的性能表现都是最优的。VFDD数据库中,MMF(无分组)融合的特征为IFC、VIF、MAD、IWSSIM、GSM、VSI、SSIM。MMF(分组后)将视频分为两组,第一组融合特征为IFC、NQM、PSNR、SNR、VSNR、WSNR;第二组的融合特征为IFC、MSE、NQM、PSNR、VSNR、UQI、SSIM。分组与未分组的融合方法性能几乎无差别;在SULFA中,MMF(无分组)融合的特征为IFC、NQM。MMF(分组后)将视频分为两组,第一组融合特征为 IFC、IWSSIM、SRSIM;第二组的融合特征为WSNR、SNR、PSNR。分组后的融合方法比未分组的融合方法在性能上有显著的提升。这说明正确的分组有利于融合算法性能的提升。在时间上效率上,融合算法比单一特征多花费200 s。相比于检测效果的提升,额外的开销时间在可接受范围之内。
5 结束语
本文提出了融合多特征的视频帧间篡改检测算法。首先计算视频帧间的TI和SI,使用TI值和SI值对视频进行分组;分组后提取视频帧间的VQA特征;对提取的VQA特征使用特征递归消除法对特征进行排序;然后再使用顺序前向选择算法和Adaboost二元分类器对排好序的VQA特征逐个融合,最终得到每组融合方法的得分,最后取两组得分的平均值得到整个算法的帧间篡改分类得分。实验对比表明,融合算法的篡改检测效果优于单一特征,且对视频进行分组能够提高融合算法的得分。下一步工作,将做更多的实验来寻找更合适的视频分组策略,进一步提算法的融合性能。未来也会尝试使用深度学习的方法来自动提取特征及融合。
作者简介
肖辉(1991-),男,福建建瓯人,福建师范大学硕士生,主要研究方向为信息安全、数字多媒体取证。
翁彬(1981-),男,福建福州人,博士,福建师范大学讲师,主要研究方向为机器学习及应用。
黄添强(1971-),男,福建仙游人,博士,福建师范大学教授、博士生导师,主要研究方向为机器学习、数字多媒体取证 E-mail:fjhtq@fjnu.edu.cn。
普菡(1995-),女,河南平舆人,福建师范大学硕士生,主要研究方向为信息安全、数字多媒体取证。
黄则晖(1999-),女,福建仙游人,主要研究方向为多媒体编辑与传播。
声明:本文来自网络与信息安全学报,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
