2020年的春节是一个不平凡的春节,新型冠状病毒以武汉为中心迅速席卷神州大地,在这场没有硝烟的战争中,中国打破了一个个不可能的界限,充分展示了“中国智慧”和“中国力量”。
其中,“健康码”作为一项新的大数据应用,在疫情防控中发挥了重要作用,很大程度上省去了繁琐的填报工作、减小了交叉感染的可能性,同时大幅提高了人员信息核验效率和精准度。很多人感慨健康码的神奇,今天我们就来谈谈“健康码”背后的风控技术。
1、“健康码”背后的风控原理
什么是风控?
风控即风险控制,风险控制是指风险管理者采取各种措施和方法,消灭或减少风险事件发生的各种可能性,或风险控制者减少风险事件发生时造成的损失。
世界纷繁复杂,风险无处不在。大数据技术使业务安全风控领域有了飞跃提升,如:
设备风险识别
调用设备风险SDK,精准防御篡改、虚拟、伪造的设备,以及设备农场等设备风险。
黄牛党/羊毛党行为识别
精准防御各类场景下优惠券、红包、秒杀高价值、稀缺商品等,被恶意抢刷、倒卖。
欺诈团伙识别
基于手机号、设备、IP建立时域关联网络,利用社群发现、风险传播等无监督算法精准防御从事批量、规模性欺诈活动的黑产团伙。
2020年春节突如其来的新冠疫情,让我们看到了风控技术在疫情防控领域的超强应用。健康码作为风控技术在疫情防控领域的典型应用,在新冠疫情防控中发挥了重要作用。
健康码-风控技术在疫情防控领域的典型应用
健康码主要通过采集大家日常出行以及消费,或者其他活动的相关数据,进行大数据分析得到大家的出行轨迹。出行轨迹数据来源比较多,如:过往7-14天的GPS定位,线下消费扫码支付的商家位置,公交、地铁及线上火车票、机票的首末站点,三大运营商的基站数据,等。
目前,支付宝健康码和腾讯健康码的结果有可能不一样,因为两者采集的数据不一样,有可能支付宝上是绿码,而到腾讯上就变成黄码了。
总之,健康码不能判断大家什么时候生病或者生了什么病,但是可以通过出行轨迹及时判断出大家有没有可能接触到新型冠状病毒,从而为新型冠状病毒疫情防控提供追溯,快速找到可能被感染的人群,并及时采取措施防止病毒进一步扩大。这对于疫情防控是非常有帮助的。
下面笔者将利用大数据知识图谱带领大家构建一个基本的健康码实例。
2、什么是知识图谱?
知识图谱(Knowledge Graph/Vault)又称为科学知识图谱,2012年由谷歌提出,如今已经成为人工智能领域的热门之一,吸引了来自学术界和工业界的广泛关注,在一系列实际应用中取得了较好的落地效果,产生了巨大的社会与经济效益。
知识图谱的逻辑结构分为两个层次:数据层和模式层。
在知识图谱的数据层,数据如果以『实体-关系-实体』或者『实体-属性-值』作为基本表达方式,我们把这种表达方式称为“三元组”,则存储在图数据库中的所有数据将构成庞大的实体关系网络,形成知识的图谱。
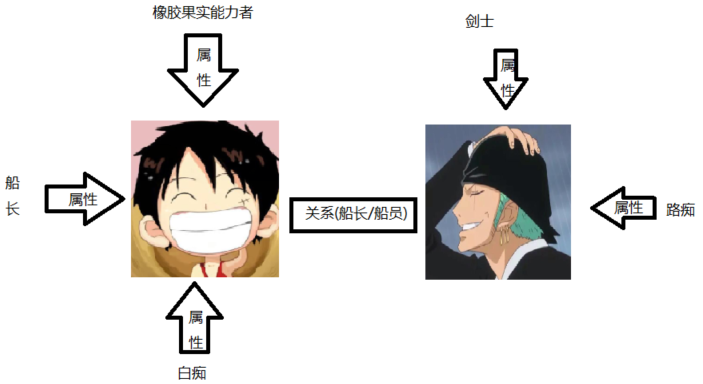
实体:指的是有可区别性且独立存在的事物(人,国家...)
属性值:实体指向的属性的值(性别、国家面积…)
关系:在知识图谱上,关系是把kk个图节点(实体、语义类、属性值)映射到布尔值的函数。
模式层在数据层之上,是知识图谱的核心,在模式层存储的是经过提炼的知识,通常采用本体库来管理知识图谱的模式层,借助本体库对公理、规则和约束条件的支持能力来规范实体、关系以及实体的类型和属性等对象之间的联系。本体库在知识图谱中的地位相当于知识库的模具,拥有本体库的知识库冗余知识较少。
3、利用知识图谱构建健康码实例
实例构建流程图
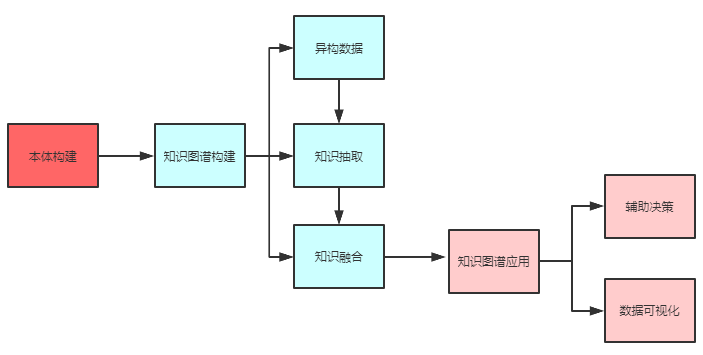
本体构建
构建风控领域知识图谱的首要工作是构建本体模型,即定义行业的通用概念为实体,以及实体之间的关系。
本体构建完成后,需要对比实际业务对本体进行验证,确保本体能够正确描述当前业务,并且包含了所有的业务流程。
对于本体的具体构造过程,可以用以下公式:
本体 = 概念(Concept)+ 属性(Property) + 公理(Axiom) + 取值(Value)+ 名义(Nominal)
从语义上讲,基本的关系共有4种,如下表:
关系名 | 关系描述 |
part-of | 表达概念之间部分与整体的关系。 |
kind-of | 表达概念之间的继承关系,类似于面向对象中的父类与子类之间的关系。给出两个概念C和D,记C′={x∣x是C的实例},D′={x∣x是D的实例}, 如果对任意的x属干D′,X都属干C′,则称C为D的父概念,D为C的子概念 |
instance-of | 表达概念的实例与概念之间的关系,类似于面向对象中的对象和类之间的关系。 |
attribute-of | 表达某个概念是另一个概念的属性。如概念“颜色”是概念“玫瑰花”的一个属性。 |
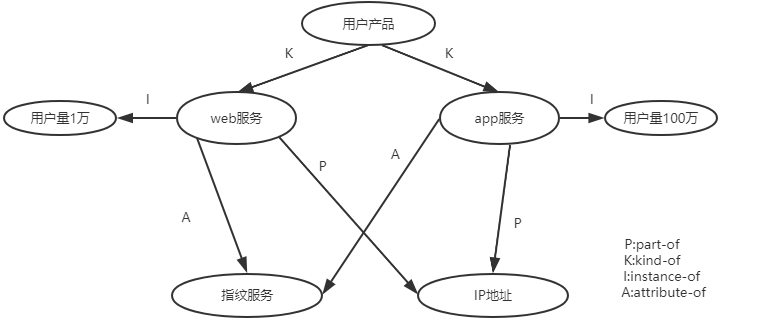
在实际建模过程中,不一定要严格地按照上述5类基本建模元语来创建Ontology,概念之间的关系不限于上面列出的4种基本关系,可以根据领域的具体情况定义相应的关系,以满足应用的需要,本体案例图如下:
知识图谱构建
构建的主要工作是把数据从不同的数据源中按照本体模型所规定的规则抽取出来。对于垂直领域的知识图谱来说,数据的主要来源是业务本身的数据,其通常是机构自己的私有数据以结构化的形式存储。通过ETL处理,将数据抽取转换为图谱数据。对于大部分金融行业图谱的构建是比较清晰的。但是大多数互联网行业对于用户的信息图像化是比较抽象的。我们今天要做的例子是当我们没有多余外部信息做支撑的时候,如何将用户关联起来。
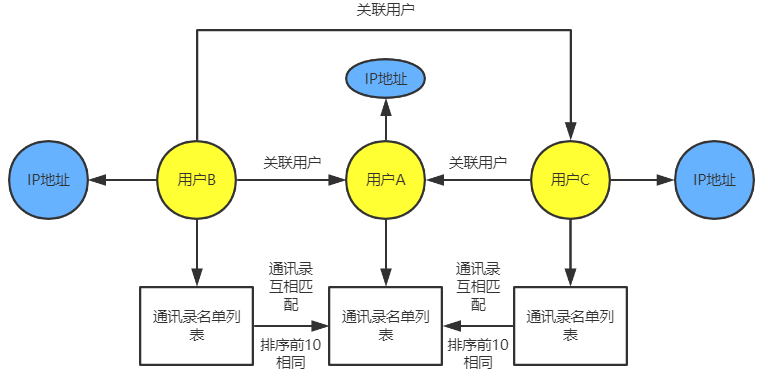
我们采取用户提供的通讯录互相匹配来确认多人之间存在可能认识的熟悉度关系。然后再利用IP地址分布算出经纬度的坐标查看好友的地理分布,通经纬度范围与时间窗口将人与人互相关联起来。
异构数据
知识抽取处理的对象按照结构化程度可以分为结构化、半结构化和非结构化信息。
结构化文档具有良好的布局结构,可以很容易地对其执行知识抽取。结构化文档主要存储在业务数据库,可以通过ETL从结构化信息中提取知识。
在处理半结构化数据方面,主要的工作是通过编写包装器,从半结构化数据中提取实体属性,适用在百科类站点、垂直网站中进行包装器归纳,从网页表格中提取属性信息。
非结构化文档是指由符合某种语言表达规范的自然语言语句组成的文档,这类文档表达方式灵活,可以用不同的形式和词汇表达相同的意思,因此对这类文档进行知识抽取是非常困难的,往往要借助自然语言处理技术对其进行语法和语义分析。
知识抽取
我们今天来取结构化文档中的数据,首先我们来介绍今天要做的事情。App通过用户许可在使用期间获取用户通讯录,并存入mysql。我们可以利用Flume对其进行采集(mysql中必须要有一个字段是随着数据写入伴随有自增长的ID,因为采集任务有可能中断,如果中断重启可以直接从当前采集的ID继续,oracle有RID, 此操作对同一个用户一般只会做一次,所以暂时不考虑用户通讯录的变更)。
agent.sources = s1agent.channels = c1agent.sinks = kfkagent.sources.sql-source.type = com.anji.flume.source.SQLSourceagent.sources.sql-source.channels = c1agent.sources.sql-source.connection.url = jdbc:mysql://xxx.xxx.xxx.xxx:3306/testagent.sources.sql-source.user = rootagent.sources.sql-source.password = rootagent.sources.sql-source.table =/**数据库表名字*/agent.sources.sql-source.columns.to.select = *agent.sources.sql-source.incremental.column.name = id/**表里面的某个字段,用来判断增量*/agent.sources.sql-source.incremental.value =0agent.sources.sql-source.run.query.delay=5000agent.sources.sql-source.status.file.path = /var/lib/flume/**有就不用动,没有就创建 mkdir -p /var/lib/flume*/agent.sources.sql-source.status.file.name = sql-source.status/** touch sql-source.status 创建文件 *//** chmod -R 777 sql-source.status 修改文件权限 sql-source.status 文件用来记录当前记录的数量*/agent.sources.sqlSource.start.from =1agent.sources.sqlSource.custom.query = SELECT * FROM (SELECT $table.idas INCREMENTAL, $table$.custid,$table.phone_info,$table.phone FROM $table$ ) where INCREMENTAL > $@$ ORDER BY INCREMENTAL ASC#c1agent.channels.ch1.type = memoryagent.channels.ch1.capacity =1000agent.channels.ch1.transactionCapacity =100#配置hdfs sinkagent.sinks.HDFS.channel = c1agent.sinks.HDFS.type = hdfsagent.sinks.HDFS.hdfs.path = hdfs://nodes:9000/flume/mysql3 /**存放数据的hdfs目录*/agent.sinks.HDFS.hdfs.fileType = DataStreamagent.sinks.HDFS.hdfs.writeFormat = Textagent.sinks.HDFS.hdfs.rollSize =268435456agent.sinks.HDFS.hdfs.rollInterval =0agent.sinks.HDFS.hdfs.rollCount = 0
采集的用户信息如下图:
序列ID | 用户ID | 用户ID对应的通讯录 |
1 | 100000001 | 138****1234 |
2 | 100000001 | 138****1235 |
3 | 100000001 | 138****1236 |
4 | 100000001 | 138****1237 |
5 | 100000002 | 138****1238 |
… | …. | … |
知识融合
数据采集后直接放入HDFS提供给后续离线计算使用。当用户量越大时对应用户通讯录会越多,利用大数据分析将会变得十分高效。
val content = spark.read.csv("hdfs://nodes:9000/flume/mysql3/*").rddrdd.map(row =>newString(row.getBytes)).map(elem => {val arr = elem.split(",")(arr(0), arr(1))}).groupByKey().map(agg => {var content =new ListBuffer[String]()val list = agg._2.toList.sortedif (list.size >=10) {for (index <-0 until10) {content += list(index)}}else {for (elem <- list) {content += elem}}(agg._1, content)}).map(tuple => (String.format("%s:%s", tuple._2, tuple._1), tuple._1)).groupByKey().filter(agg => agg._2.size >=2).foreach(result => {println("### 关联用户:%s 关联id:%s", result._1, UUID.randomUUID())})
通过离线统计获取如下结果:
[4501776, 4757897, 2767684, 1550836]:(5c0e1145-337d-47ca-a4f3-bd2cbb5) 将数据存入redis(这里将数据存入redis是为了将其与后续的数据进行合并使用,key是用户id,value是每个数据集的uuid)。通过用户许可,在使用应用的期间获取用户的IP地址,数据样例如下:
用户ID | 时间 | IP地址 |
100000001 | 2020/4/26 15:00 | 114.xxx.xxx.33 |
100000002 | 2020/4/27 15:10 | 58.xxx.xxx.210 |
100000003 | 2020/4/28 15:20 | 120.xxx.xxx.88 |
… | … | … |
这类数据一般都是流数据可以通过端口传输过来,Flume脚本可以是以下类型的程序。
#sourceagent.sources.r1.type = netcatagent.sources.r1.bind = xxx.xxx.xxx.xxxagent.sources.r1.port = 11203agent.sources.r1.channels = c1# 配置 kafka sinkagent.sinks.kfk.type = org.apache.flume.sink.kafka.KafkaSinkagent.sinks.kfk.brokerList=xxx.xxx.xxx.xxx:9092agent.sinks.kfk.topic=mytopicagent.sinks.kfk.requiredAcks = 1agent.sinks.kfk.batchSize = 2agent.sinks.kfk.channel = c1
数据存入kafka之后就通过与redis中的数据进行合并再与用户信息表结合,这里技术方案可以通过kafkaStream、spark-Streamming、flink、storm等方式去实现。
Storm数据合并代码如下:
publicvoidexecute(Tuple tuple){JSONObject msg = parseContent(tuple.getString(0));if (!msg.isEmpty()) {System.out.println("this is spout-msg:"+msg);collector.emit(new Values(msg.toString()));}}public JSONObjectparseContent(String message) {JSONObject jsonObject = JSON.parseObject(message);String uuid=redis.hget(jsonObject.get("custid"))jsonObject.put("uuid",uuid)return jsonObject;}
得到的相关数据如下表:
用户ID | 时间 | IP地址 | 关系ID |
100000001 | 2020/4/26 15:00 | 114.xxx.xxx.33 | 5c0e1145-337d-47ca-a4f3-bd2cbb5 |
100000002 | 2020/4/27 15:10 | 58.xxx.xxx.210 | 5c0e1145-337d-47ca-a4f3-bd2cbb5 |
100000003 | 2020/4/28 15:20 | 120.xxx.xxx.88 | 123ass5f-337d-47ca-a4f3-bd2cbb5 |
… | … | … | … |
图谱数据的存储形式目前有以下几种方式:

知识图谱应用
我们将数据输出到Elasticsearch中利用kibana等工具就可以展现指定任意一段时间内想要查询的关联好友所处的城市。
这样使每个圈子的分布范围可视化,利用用户初期数据生成低风险感染用户码,如下图:

如果一个人成为确诊或疑似患者,我们可以通过关系id找出附近范围内可能会接触到该患者的人,在数据字段中统一修改标签flag,将其全部标记为风险对象,绿码变红码。至此,一套简单的疫情风险控制流程就走完了。

4、知识图谱在风控领域的应用
推导识别
根据以上离线计算出来的数据使用在某营销活动中。
A推荐了B,B推荐了C,C推荐了D,如果判定A为黑产则可以推导这个图的节点上所有用户都疑似为黑产。
如果A失联,我们可以通过知识图谱找到与A关系相近的其他人,进行追踪。
聚类识别
当资源有限时,为了提高转化率。我们可以将份额按图谱圈来划分。上面4个用户为一个圈只能分到1-2个正常用户的资源。
知识图谱的适用场景
关系复杂的数据;
类型繁多的数据;
结构多变的数据;
作为数据融合与链接的纽带,知识图谱整合结构化、半结构化和非结构化数据。
但知识图谱不是万能的,需要我们依据不同的问题寻找合适的方法,不要为了用知识图谱而用知识图谱。
知识图谱的不适用场景如下:
不适用的数据场景
· 通常的二进制数据
· 日志数据
· 流式数据
不适用的业务场景
· 数据统计
· 数据计算
这些不适用场景都需要借助其它工具存储和处理,同时结合其它工具和方法使用,最终与知识图谱进行数据链接。
声明:本文来自上汽安吉安全应急响应中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
