一家银行,在国内多个城市拥有支行。但出于数据安全的考虑,现有的法规不允许这些支行同时交换彼此的原始数据。这意味着,即便是在同一家公司内部,数据的“墙”仍然存在。
如何“破墙”?
一项技术的创新性应用为此提供了解决方案。
分享者 | 罗松
腾讯云与智慧产业事业群(CSIG)安全云部
腾讯安全大数据创新中心负责人
2011年,世界经济论坛发布了《个人数据:一种新资产类别的出现》报告,指出个人数据正在成为“新资产类别”。同年,互联网开始了从PC向智能手机的大迁徙,全球用户数据增长至惊人的1.8ZB(1.8万亿GB)。
尽管大多数人并不理解“新资产类别”意味着什么,但没有人会怀疑数据对于未来社会的价值和潜力。
2020年4月9日,中共中央、国务院印发《关于构建更加完善的要素市场化配置体制机制的意见》,将数据定义为一种新型生产要素,与土地、劳动力、资本、技术要素并列。这在中国市场经济发展历史上具有标志性意义。
但大多数数据从未真正易手。
一方面,数据的流动规则仍需进一步明确,市场的建立必须以规则为前提;另一方面,数据流通更需要技术保障,新的技术方案亟待提出。具体来说,新的方案必须既能保护用户隐私、让数据在监管框架下合规流通,同时又能提高数据的使用效率,促进不同公司、产品和行业之间的数据融合,进而提升商业服务质量和政府的社会治理水平。
在这样的大背景下,腾讯云与智慧产业事业群安全云部用“联邦学习”探索出一条创新性的数据融合道路。
这一切都要从安全云部的转型说起。

►从“守门员”到“数字化助手”
作为腾讯公司内部的安全部门之一,安全云部此前主要从事与反欺诈有关的工作,保护QQ、微信、微信支付等腾讯产品的安全。
2018年9月30日,腾讯宣布新一轮组织架构调整,率先发布产业互联网战略,明确提出“扎根消费互联网,拥抱产业互联网”。腾讯董事局主席兼首席执行官马化腾表示,互联网公司作为传统企业的“数字化助手”,要做好连接器、工具箱和生态共建者。
为了做好“数字化助手”,原本对内服务的安全云部将多年来在反欺诈领域积累的技术能力对外部合作伙伴开放,场景集中在金融风控等领域。在这个过程中,安全云部发现,无论大企业还是小企业,业务的提质增效都对数据融合有极大的需求。
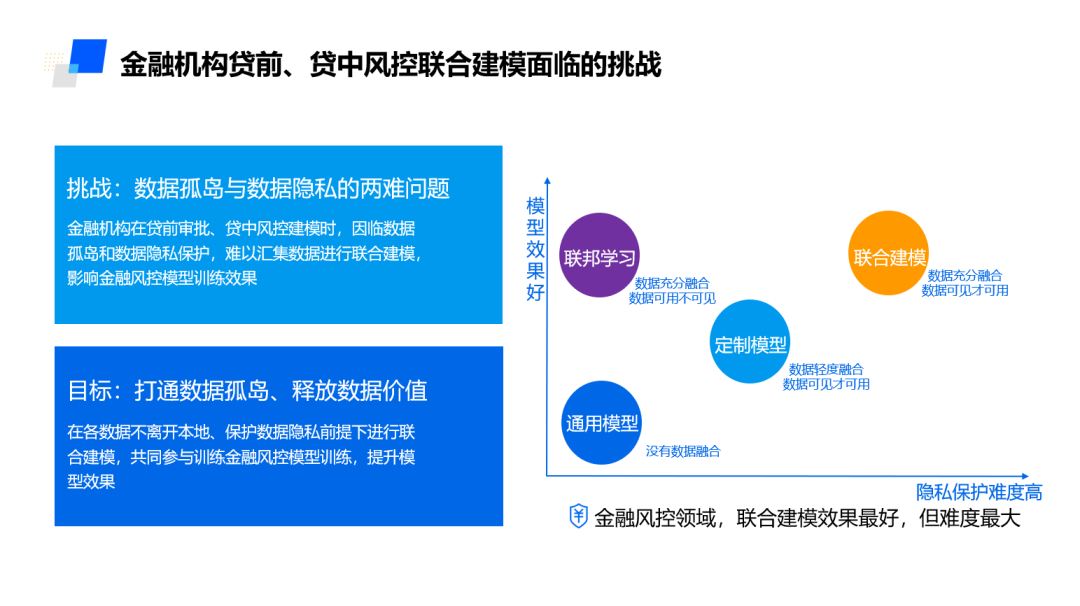
但一个行业性的难题是,传统的联合建模虽然有效,但这种老方法建立在数据可见的前提下,这意味着用户的隐私无法得到充分保护,也很难满足合规要求。
如何在保证合规的前提下连接数据孤岛,在各机构间实现安全有效的数据融合?联邦学习在去年进入安全云部的视野,安全大数据创新中心负责人罗松博士带领团队开启了对该技术的研究。
2016年,联邦学习的概念由谷歌科学家H.BrendanMcMahan等人提出。原本用于解决安卓手机终端用户在本地更新模型的问题。其设计目标是在模型更新过程中避免直接上传终端用户数据到云端,从而保护安卓手机用户的隐私。
在国内,联邦学习主要用于不同机构间的联合建模。其目标是在保障大数据交换时的信息安全、保护机构数据资产安全和个人数据隐私、保证合法合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习,真正实现了数据和特征变量的“可用不可见”。

相较于其他安全多方计算技术,联邦学习是一种“节能”的计算路径。
联邦学习是安全多方计算技术的一种。其他的安全多方计算技术,要么对机器硬件有特殊要求,比如基于可信执行环境(TEE)的集中式多方计算技术;要么本地计算资源消耗太大,比如使用混淆计算,秘密共享,同态加密等方法对原始特征数据进行加密的分布式多方计算技术。
而使用了分布式计算终端的联邦学习,在每个终端上的计算要简单的多,这种方法只需加密处理计算双方乃至多方的中间值,因而大大降低了对本地资源的消耗。
除了对算力资源上要求,当涉及到多方数据源时,传统AI模型通常也会面临侵犯隐私、违反法规的问题。例如,一个在北京、上海两地都有支行的银行,尽管两支行同属一家公司,但现有法规并不允许这两个单位同时交换彼此的原始数据。
联邦学习在数据融合的同时保证了双方绝对不会接触到彼此的原始数据,只需要透过加密的中间值(误差和梯度)就可以不断迭代优化模型。这有效解决了数据流通与隐私保护、数据合规间的矛盾。
最为重要的是,联邦学习保证数据不离私有域的情况下,能够实现与传统AI联合建模同等的效果。对于众多受监管政策趋严影响、同时又苦于“数据孤岛”问题的金融机构来说,这毫无疑问是一个好的解决方案。
鉴于联邦学习的诸多优势,安全云部加快了从研究到商业化落地的节奏。
今年4月,江苏银行与安全云部共同举行了联邦学习线上发布会。双方将联合共建“智能化信用卡管理联合实验室”,围绕联邦学习开展深入合作。
在此之前,江苏银行在对信用卡申请用户进行审核的时候,应用了很多从外部采买的数据。因为要保证数据的合规使用,这些数据只能提供包含各种标签的用户分数,但颗粒度相对较粗。因此,一些底层的数据特征会被忽略掉,从而导致银行无法感知具体的业务风险。
安全云部“抓取底层特征”的能力派上了用场。基于联邦学习技术,多方数据可以在不接触彼此数据源(不同来源的数据彼此“不见面”)的同时进行联合建模,这极大提升了数据精度,一些与业务风险相关的具体特征被暴露了出来。
在建模效果上,联邦学习产品也表现出色。在金融风控领域,业内人士一般用KS值来形容风控的效果。在进行合作之后,江苏银行风控模型的KS值提高了约50%。现在,联邦学习服务已正式在江苏银行业务中开始调用。
除了日常的业务实践,联邦学习还有更大想象空间。在安全云部的设想中,联邦学习产品类似于人工智能应用中的“超级应用”,有效连接了供求信息极度不透明的企业数据各方。天生具备超级连接者属性的联邦学习产品,对促进安全、高效的数据市场有积极作用。
那么,联邦学习何以能够解决数据市场的关键难题?联邦学习产品为什么有成为“超级应用”的潜力?我们采访了罗松(Jonluo)博士。以下是他的分享。

腾云:安全云部是怎么接触到联邦学习的?
罗松:因为我们要做联合建模,经常碰见一种情况,外部客户有数据,我们腾讯方也有数据,如果两方数据能够融合在一起,就能更有效地利用这些数据,助力企业控制金融风险。但因为监管政策和隐私保护的问题,用传统的技术手段是没办法把数据融合在一起进行分析。
我在微众银行首席人工智能官杨强教授的讲座中了解到联邦学习技术,微众银行的FATE框架为我们提供了一个不错的基础。在试用之后,我们基于FATE框架进行了很多优化,保证能够在银行的环境里稳定高效运行。
腾云:您曾打比方说联邦学习产品像一个“超级应用”,为什么这么说?这个“超级应用”的创新点体现在哪里?
罗松:“超级应用”是一个很好的比喻。简单地说,我们这个平台连接了腾讯内部和外部各种数据源。对外,我们先是连接了银行等外部合作伙伴的数据源;对内,我们又扩展到内部的数据源,发挥腾讯各大产品的数据能力。
有很多非金融类型的合作伙伴也对联邦学习非常感兴趣。典型的就是政府——许多政府希望把自身的数据与腾讯的进行融合,为当地企业提供更好的服务,提升社会管理水平。此外,电力、烟草等传统行业也有大量类似需求。行业数据、政府数据等多方数据的融合,将极大提升各行业的运行效率。
正因如此,我们在做联邦学习的时候,我们不仅把它做成一个技术上联合建模的工具,而是把它朝着一个数据撮合的平台方向打造。
一方面,对于数据需求方来说,即便它最初不知道哪些数据能够为其所用,但当它进入我们的平台后,我们可以依照经验为其推荐数据源,协助其将业务和数据源实现匹配、连接;另一方面,很多企业都想进行数据增值服务,但并不知道从哪里找买方。在连接平台以后,我们可以用联合建模的方式进行测试,找出其数据与哪些合作伙伴以及应用场景匹配。
所以这个平台对业务方和数据方同时都能起到桥梁作用,连接数据的买方与卖方,精准连接不同行业的合作伙伴,成为一个数据的超级连接应用。
我觉得最大的创新点在于,在这个“超级应用”中,联邦学习保证了数据买卖双方的交易并非“一手交钱一手交货”,而是只能“利用”却无法“触碰”“拥有”。因为在这个平台上,除了数据拥有方,没有任何人可以触碰到源数据,所以实现了对用户隐私数据的保护。最后,我们根据数据价值量化的结果来划分双方的运营收益。

腾云:与传统的人工智能服务相比,联邦学习的优势在哪里?
罗松:人工智能是一个很广泛的概念,它建立在大数据基础上。
目前金融行业对人工智能的应用,多是在自有数据上运行各种算法。也就是说,银行先把数据都准备好,人工智能公司把算法升级成知识图谱或复杂网络。联邦学习更是以大数据技术为主的技术,它给客户带来的收益主要源于数据融合。
比如,传统的人工智能服务的方式可能是,基于银行的数据可以跑出一个知识图谱,利用这个图谱,帮助银行分析各个账户之间的关系;而基于联邦学习,可以把银行账户间的资金流数据和外部的用户行为数据融合,然后在这个基础上再运行更多算法,从而形成更精准的判断。
也就是说,哪怕算法不变,即便还是运用一个很简单的逻辑回归算法,但因为我能把不同机构的数据融合在一起,就能给业务带来巨大收益。但在这个过程中,用户数据隐私得到了保护。
从我们的经验来看,新的有效数据源通常比复杂的AI算法更能提升模型的效果,能给业务带来更多的收益。因此,我们首先选择数据融合而非算法,来作为AI服务的突破口。
通过联邦学习,我们相当于为金融机构架设了很多桥梁,他们可以通过桥梁安全的与外部实现数据连接,因此他们的可用数据大大增加。
另外,在可复制性方面,联邦学习要强于其他很多人工智能服务。因为不管是为哪一家银行提供助力,我们所用的底层联邦学习的软硬件框架都一样,只有模型是定制化的。模型的定制化取决于数据,它只是一个数字的表现形式,储存在你的硬盘上面。
当然,联邦学习不是万能的。比如,要分析账号之间的关系,那么知识图谱可能比联邦学习更有效。但我相信,对于绝大多数应用场景,通过联通学习引入更多数据源会实现一个更有效的提升。

腾云:联邦学习对我们常说的企业数据中台有什么样的影响?有无可能塑造一种新形式的数据中台?
罗松:对于很多机构内部的中台来说,他们首先要做的是把数据拉通,用单一的Key值或者ID标识不同业务的数据,这样数据才能被统一使用。从这一点上来说,数据中台跟联邦学习是两回事。
但数据中台把数据拉通以后,能够促进联邦学习的使用,使得联合建模更加容易。这是数据中台跟联邦学习之间的第一个关系。
另外,即便企业有了一个数据中台,大公司的很多部门、产品之间,依然会存在隐私保护和数据隔离的需求——虽然可以用通用ID来标识每个业务的客户,但仍然没办法在各个业务之间实现真正的数据共享和可见,这会违反数据的隐私保护原则。所以在这种情况下,联邦学习又能派上用场。它可以在尊重各个部门隐私保护的前提下,把数据融合之后进行联合建模,训练更好的模型。
当然,对于业务和产品比较单一的小公司来说,建立一个集中存放数据的中台或许不是一个问题,那么联邦学习的价值暂时无法在内部得以体现。把数据集中存放效率会更高。
传统意义上的中台意味着,只要你身处中台之中,你就有可能什么数据都能够看得见,也正因如此,腾讯对此非常谨慎。如果用户的数据都变成可见状态,这对公司、对用户来说都是一个巨大的风险。
我认为,数据的融合使用是一个趋势。如果各个行业不能很好的发挥数据的价值,就不能够更好的提升社会的整体运作效率。这也是我们为什么要将腾讯的数据能力开放给行业合作伙伴的原因。
总结来说,我们可以为拥有大量数据的企业建立“数据能力”,而不是传统意义上的“数据中台”。这对于公司内部数据的合规使用,具有很大的意义。
声明:本文来自腾云,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
