笔者按:
《数据安全法(草案)》已经正式开始公开征求意见了。前一篇文章关注《数据安全法》的立法思路:对《数据安全法》的理解和认识 | 立法思路。
本篇文章将关注《数据安全法》第十九条提出的数据分级分类的要求。在公号君看来,《数据安全法》提出的这条规定,具有重大的意义。本篇文章结合此前开展的一个课题研究【数据安全管理视角下的数据分类研究:研究报告全文】,来探讨《数据安全法》第十九条的重大创新。
先摆出来《数据安全法》第十九条:
第十九条 国家根据数据在经济社会发展中的重要程度,以及一旦遭到篡改、破坏、泄露或者非法获取、非法利用,对国家安全、公共利益或者公民、组织合法权益造成的危害程度,对数据实行分级分类保护。
各地区、各部门应当按照国家有关规定,确定本地区、本部门、本行业重要数据保护目录,对列入目录的数据进行重点保护。
一、国家层面开展数据分级分类工作
要特别注意到第十九条第一款中规定的数据分级分类的主体——国家。而在《数据安全法》之前,我国现有的法律法规也有数据分级分类的规定,但是分级分类的主体绝大多数是规范对象自身,而非国家。以下举例说明:
1、国务院2018年3月17日发布的《科学数据管理办法》第十条规定:
“科学数据中心是促进科学数据开放共享的重要载体,由主管部门委托有条件的法人单位建立,主要职责是:(一)承担相关领域科学数据的整合汇交工作;(二)负责科学数据的分级分类、加工整理和分析挖掘;(三)保障科学数据安全,依法依规推动科学数据开放共享;(四)加强国内外科学数据方面交流与合作”。
《科学数据管理办法》第二十条规定:“法人单位要对科学数据进行分级分类,明确科学数据的密级和保密期限、开放条件、开放对象和审核程序等,按要求公布科学数据开放目录,通过在线下载、离线共享或定制服务等方式向社会开放共享”。
2、中国证券监督管理委员会2019年6月1日实施的《证券基金经营机构信息技术管理办法》(第152号令)第三十条规定:
“证券基金经营机构应当将经营及客户数据按照重要性和敏感性进行分类分级,并根据不同类别和级别作出差异化数据管理制度安排”。
【更完整的例举和相关研究,见:数据安全管理视角下的数据分类研究:研究报告全文】
从上述规定可以看到,要求规范对象本身开展数据分类分级(本文称之为自下而上的路径),与国家自己开展数据分级分类工作(本文称之为自上而下的路径),会有这本质的区别。
二、自下而上路径的展开和根本目的
相对于法律层面(主要是行政法规和部门规章)止步于提出数据分类分级要求,近两年一些部门在其发布的工作性文件中,提出了数据分类分级的具体标准。以下举例说明:
工业和信息化部2020年2月印发的《工业数据分类分级指南(试行)》中,提出了对工业数据的分类和分级标准。
第五条规定:“工业企业结合生产制造模式、平台企业结合服务运营模式,分析梳理业务流程和系统设备,考虑行业要求、业务规模、数据复杂程度等实际情况,对工业数据进行分类梳理和标识,形成企业工业数据分类清单”。
第六条中给出了工业企业的数据分类范例:“工业企业工业数据分类维度包括但不限于研发数据域(研发设计数据、开发测试数据等)、生产数据域(控制信息、工况状态、工艺参数、系统日志等)、运维数据域(物流数据、产品售后服务数据等)、管理数据域(系统设备资产信息、客户与产品信息、产品供应链数据、业务统计数据等)、外部数据域(与其他主体共享的数据等)”。
第七条给出了平台工业企业的数据分类范例:“平台企业工业数据分类维度包括但不限于平台运营数据域(物联采集数据、知识库模型库数据、研发数据等)和企业管理数据域(客户数据、业务合作数据、人事财务数据等)”。
【更完整的例举和相关研究,见:数据安全管理视角下的数据分类研究:研究报告全文】
可以看出,《工业数据分类分级指南(试行)》遵循了前面所说的“自下而上的路径”,但其更进一步,提出了“自下而上的路径”可资采取的方法。
从第五、六、七条来看,这是一种所谓的“实然路径”——此种路径的基本思路是不改变企业实际如何组织生产的方式和流程(用大白话说就是:“是什么就是什么”),且客观描述在这个方式和流程中所收集、产生出的数据类型。
此种“实然路径”的另一例证是证监会于2018年9月27日正式公布实施《证券期货业数据分类分级指引》(JR/T0158—2018)。在这个标准中,数据分类的方法是:
《证券期货业数据分类分级指引》6.4要求:“本标准推荐的分类分级方法,从业务条线出发,首先对业务细分,其次对数据细分,形成从总到分的树形逻辑体系结构,最后,对分类后的数据确定级别;同时,推荐考虑确定数据形态”。
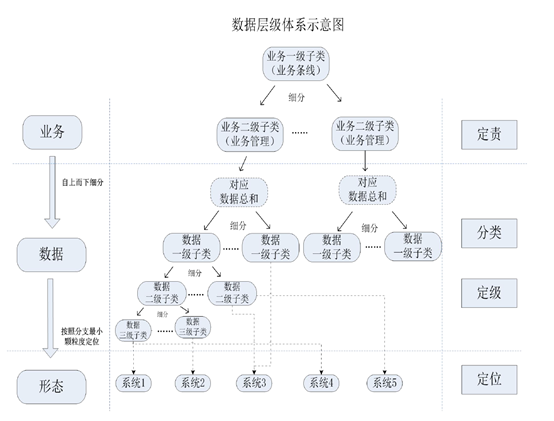
从上面的研究可以看出,无论是法律还是部门规章,往往仅仅止步于提出数据分类分级的要求,并没有对如何分类分级提出进一步的方案。近年来,特别是2019年以来,在国家部委发布的指引性文件,或者国家和行业标准层面,可以看到一些尝试或方案。
在这些尝试或方案中,数据分类采取的路径主要是一种所谓的“实然路径”。此种路径的基本思路是不改变企业实际如何组织生产的方式和流程(用大白话说就是:“是什么就是什么”),且客观描述在这个方式和流程中所收集、产生出的数据类型。
在完成数据分类的前提下,根据“后果”路径,来对数据进行分级。此种路径的基本思路是根据某类数据的安全属性(完整性、保密性、可用性)遭到破坏后的影响对象、影响范围、影响程度,对数据进行定级。一般来说,有分为三级的,也有分为四级的。【笔者注:此部分从略,感兴趣的读者见:数据安全管理视角下的数据分类研究:研究报告全文】
观察目前部委指导性文件和标准所提出的数据分类分级路径,给规范对象内部开展数据治理提供了很好的思路。规范对象如果能按照上述路径开展分类分级工作,能够对其所掌握的数据建立管理目录,并对目录里面的数据进行“差序有致”的管理。
总的来说,“实然路径”的数据分类,和“后果”路径的数据分级,是站在规范对象的视角来看。但是,如果由规范对象自主开展数据分类分级工作,其第一诉求往往是防止自身权益因为数据安全事件而导致损害。
三、自下而上路径不足以支撑国家监管
目前,数据的重要程度越来越高,掌握在企业手中的数据,其对国家、社会、个人的价值,要比对企业来说,价值更高或者说一旦出现安全事件,对国家、社会、个人造成的危害,可能比对企业利益的危害更大。例如剑桥分析事件中,Facebook疏于对第三方的管理,导致大量个人数据被用于政治目的,包括影响脱欧公投和美国总统大选等。
这就出现了一个所谓的“外部性”问题。外部性又称为溢出效应、外部影响、外差效应或外部效应、外部经济,指一个人或一群人的行动和决策使另一个人或一群人受损或受益的情况。然而,目前的“实然”路径的数据分类,和“后果”路径的数据分级,并不能很好地解决数据安全管理中的“外部性问题”。
因此为了督促或监督企业切实负起数据安全责任,同时对某些“外部性”很强的数据给与更高水平的安全保护,就需要国家站在企业外部,要求企业对具体的、特定的数据类别,提供更高水平的保护。为了达到这个目的,目前的“实然”路径的数据分类,和“后果”路径的数据分级难以达成。
另一方面的原因是,目前的部委指导性文件和标准所提出的数据分类分级路径,在单个组织内部可以适用,但是对面对众多组织的监管部门来说,不具备互操作性,即一个组织的数据分类或数据分级,很可能与另外一组织的数据分类和数据分级截然不同。这种情况下,数据安全监管机关无法开展统一的管理和监督工作,更无法判断其所维护的国家和公共利益、个人合法权益是否得到充分的保护。
换句话说,完全依赖规范对象的自我管理的“自下而上”的路径,难以服务于监管层面的工作开展。从国家层面,或者站在国家角度,组织或开展数据安全管理工作来说,在“自下而上”路径的基础上,还需要“自上而下”的路径。
在公号君看来,“自下而上”的数据分类分级路径有助于企业自我开展数据安全工作,但不足以支撑国家开展数据安全管理和监督工作的需要。例如,国家对劳动人口的身份管理,国家就“自上而下”划分为公务员、事业单位人员、企业员工、务农人员等。这样一种相对整齐划一的分类,有助于统一管理,这实际上就是本文所谓的“自上而下的路径”。
四、“自上而下的路径”的展开
在【数据安全管理视角下的数据分类研究:研究报告全文】这项研究中,公号君提出的数据分类思路,正是“自上而下的路径”的展开。如下图:

在这项研究中,公号君提出,数据安全监管存在两个基本命题:第一是为什么要保护,其中“为什么要保护”——即保护的价值,“为什么要保护”同时决定了“如何保护”——即具体的安全责任内容;第二是谁来保护——即谁的保护责任。
因此,从设计、落实数据安全监管的角度来对数据进行分类,可以遵循这两个维度:
数据处理活动(包括收集、使用等)的主体存在哪些?
公权力要保护的价值是什么?
在这两个维度的指引下,就能清晰地确定:
哪些主体的数据处理活动,可能对哪些价值造成危害;
根据造成危害的风险,相应地设计数据安全管理的要求。
具体的例子如下:
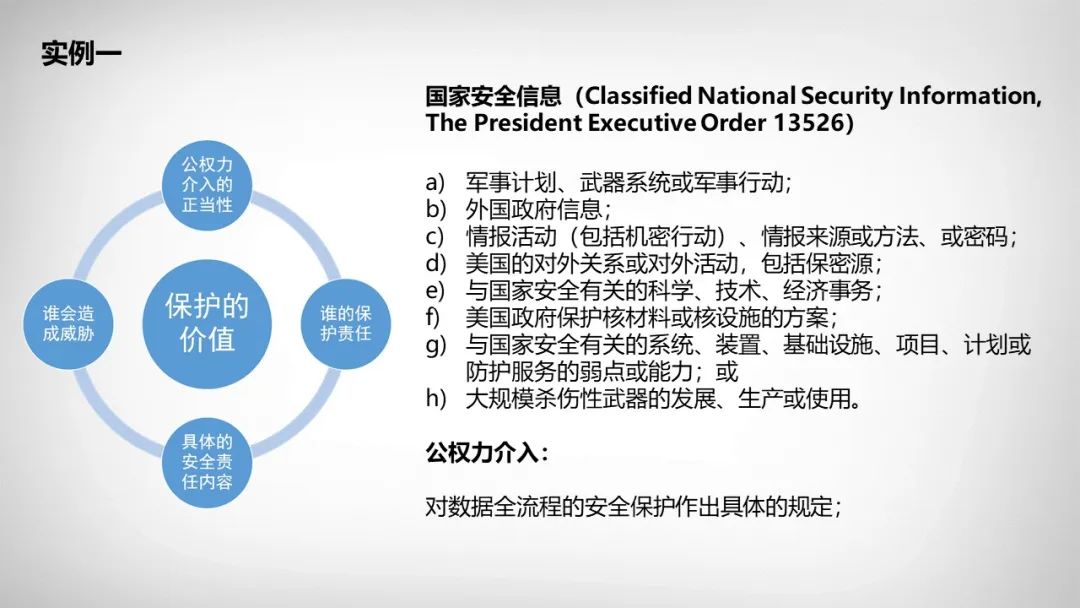
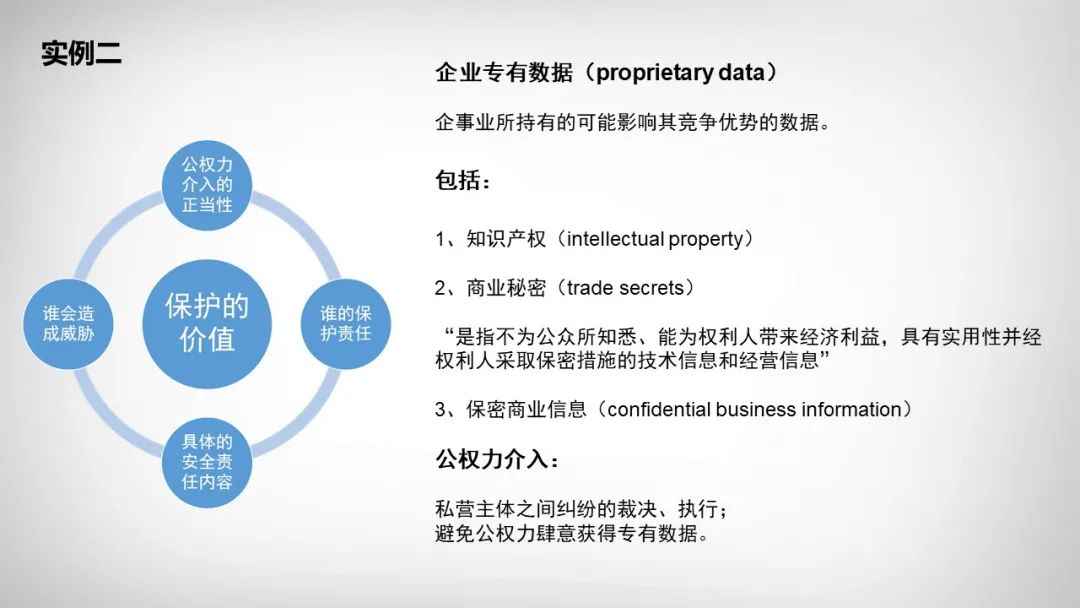
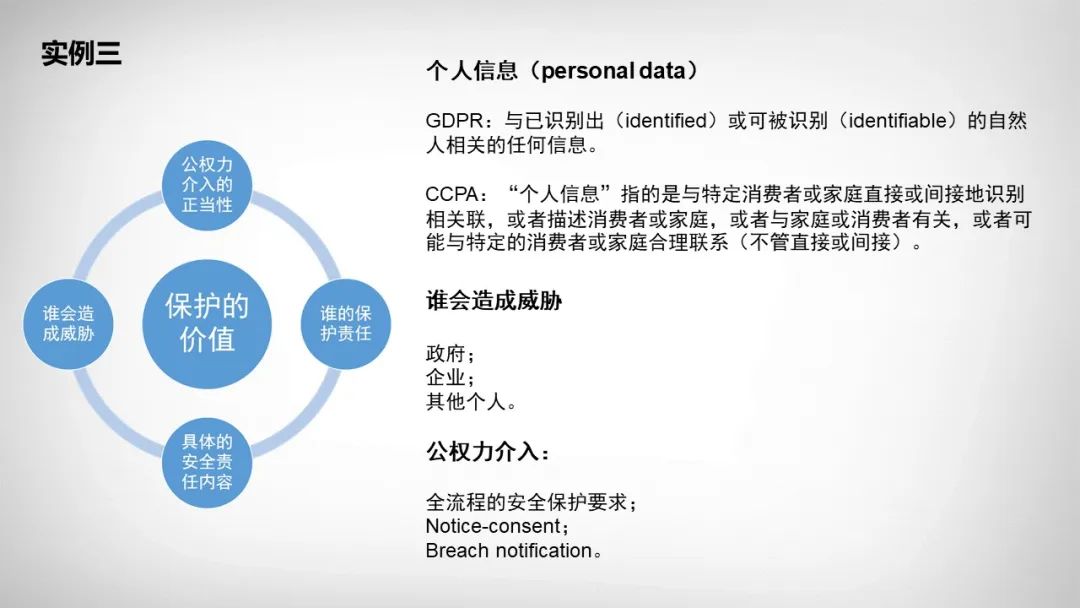

注:在实例一、实例二中列举的数据类别,例如外国政府信息、知识产权、商业秘密等,就是所谓的“自下而上”路径的数据分类方法;而国家安全信息、企业专有数据等,是所谓的“自上而下的路径”。
沿着这个思路,在【数据安全管理视角下的数据分类研究:研究报告全文】这项研究中,公号君提出的数据分类框架如下,摘录如下:
数据安全的基本要求存在两个层次:
一是“传统的数据安全”:保障数据作为资产的安全,即保障数据完整性、保密性、可用性。【即第一层安全保护的价值】
二是“新的数据安全”:管控数据处理过程中对外部可能造成的危害。【即第二层安全保护的价值】第二个层次“新的数据安全”中的外部又可以分解为:
个人安全——即数据处理行为危害到个人安全,包括人身、财产、名誉等合法权益。此方面为个人信息保护法律管控的主要内容。
组织安全——即数据处理行为危害到其他组织的合法利益,包括知识产权、商业秘密,以及其他竞争和名誉等方面的利益。例如企业非法爬取其他企业的数据。企业非法窃取其他企业的商业秘密。企业非法使用其他企业的知识产权(比如商标、专利等)。此方面可总结为,数据处理行为不得侵害其他组织的专有数据,具体包括两方面:企事业专有数据和政党社团专有数据。企事业专有数据(proprietary data)可定义为:企事业所持有的可能影响其竞争优势的数据。
公共安全、公共利益、公共秩序——即数据处理行为危害到公共安全、公共利益、公共秩序。例如企业公开发布统计信息影响行政管理、经济秩序。
国家主权、安全、发展利益——即数据处理行为危害到“国家在政治、经济、国防、外交等领域的安全和利益”。例如企业通过数据聚合分析,推论出国家秘密,进而影响国防、国际关系等。
总结起来,数据安全的目标如下表所示: 
结合国标31167中的“敏感信息”,以及《国家网络安全事件应急预案》中的“重要敏感信息”的定义,公号君进一步将“个人信息、企事业专有数据、政党社团专有数据、重要数据”,统称为“敏感信息”或“重要敏感信息”,并得到了如下的数据分类框架:
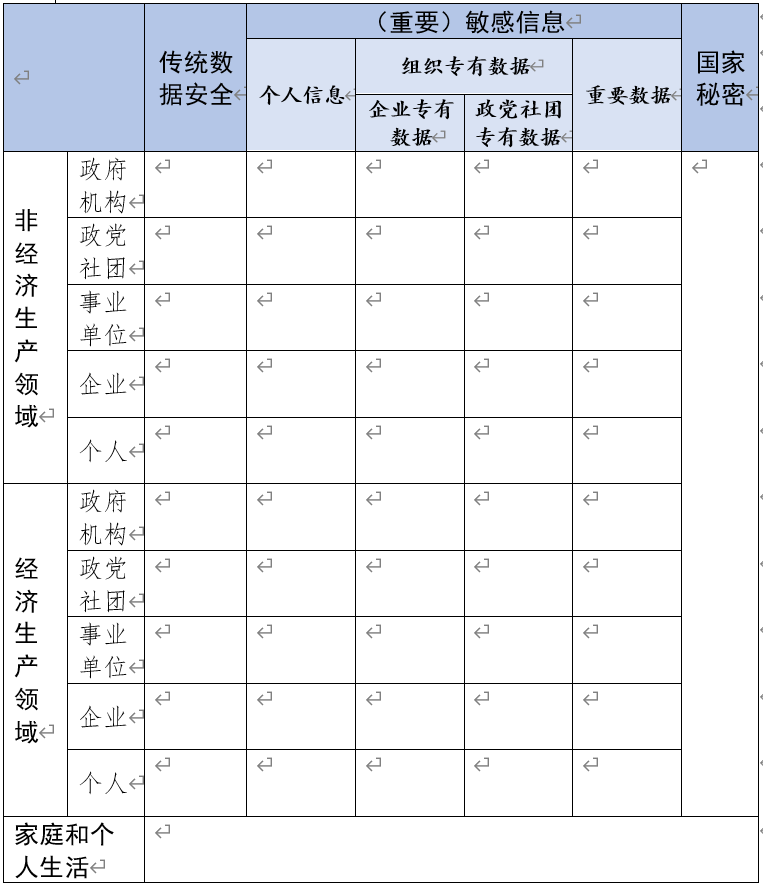
五、对《数据安全法》第十九条的理解
《数据安全法》第十九条正是提出了“自上而下的路径”。该条要求国家根据所保护价值(“国家安全、公共利益或者公民、组织合法权益”),以及对所保护价值的危害后果(“一旦遭到篡改、破坏、泄露或者非法获取、非法利用”......“造成的危害程度”),来开展数据分级分类的工作。
总的看来,笔者在【数据安全管理视角下的数据分类研究:研究报告全文】这项研究中提出的数据分类思路,和《数据安全法》第十九条的思路非常契合。
而且从《数据安全法》的全文,以及正在制定的《个人信息保护法》来看,从数据安全监管的角度,国家对数据的分类思路已经呼之欲出:
1、数据——指任何以电子或者非电子形式对信息的记录。
2、个人信息
3、重要数据
对这三类数据,《网络安全法》、《数据安全法》、《个人信息保护法》提出了配套的安全保护要求。限于篇幅原因,本文对这部分就不展开了。【注:对于《数据安全法》中提出的“政务数据”这个类别,公号君认为是从“自下而上”路径提出的。】
以上是公号君对《数据安全法》提出的数据分级分类要求的认识,供大家批评指正。(洪延青)
声明:本文来自网安寻路人,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
