非常高兴来参加人工智能治理会议,我想从技术和社会发展两个角度谈一下造成人工智能需要治理的原因是什么,在技术上、政策上有哪些东西还可以进一步加强。报告里面有不够到位的地方请各位专家批评指正。

我们发展人工智能时抱持有一种想法,希望人工智能可以和社会发展有一个共性的互动关系,因为我们发展人工智能技术不是为了把老百姓的饭碗都抢了,这不是我们原来发展的愿望。

这张图左边和右边代表两个世界,右边是我们目前发展的人工智能技术,不论是专用还是通用的,都到了一定阶段。左边是我们原来发展人工智能的愿望,希望把人工智能技术赋能于行业。我们发展人工智能技术的时候有这样的初始愿望,希望人工智能技术能够和人类社会的发展共性互动、共生互动。
这张图有两部分内容,告诉大家人工智能技术从专用发展到通用,再发展到强人工智能。左边是等待人工智能赋能的方向,比如我们希望人工智能技术能够在工业界推进智能制造,我们需要发展智能医疗来解决老龄化问题,我们希望把我们城市生活打造得更加美好,而智慧城市也是我们的一个目标。中间的是和谐共生,是我们追求的目标。
那么人类社会和智能技术之间有哪几类关系呢?我们将其分成四大类。
第一类,辅助关系。我们大家知道上海地铁10号线其实是一列无人驾驶的地铁,智能系统起着辅助作用。我们现在发展了很多汽车电子,这也是希望我们驾驶员能够更加舒适、安全地驾驶车辆。以上是我们说的人工智能起到辅助作用。
第二,人在回路上。我们希望在整个社会生活的各个环节里,不是靠单单一个机器人来完成一些任务,而是靠人和机器人合作。一些复杂的工作就交给机器去做。现在医院里在做的医疗机器人就是这样的,尽管达芬奇机器人有很好的手术技术,但操刀的还是医生。
第三,互动关系。我们发展的很多穿戴设备和脑机接口,都是交互关系的产品。在各行业都可以看到,交互促进人们享受更好、更便利的生活。
最后是我们不太希望看到的竞争关系。一些重复性的劳动可能会逐步被机器人所替代。
那人工智能的风险在哪里产生呢?给大家举个例子。
第一类,在辅助关系之中,辅助装置做得可能不够到位,比如智能汽车里面的设备对场景的认识能力比较弱,因而没有给你正确的信息,提示前面有障碍物。特斯拉汽车事故就是因为这个原因发生的。

第二类例子,图中间的是达芬奇机器人,理论上是“人在回路上”的典型代表,主治医生在计算机平台上看到的东西是通过达芬奇机器人的视觉系统反映来的,但有时机器人视觉系统受到污染,医生看不到开腹病人的真实情况,于是就出了事故。
第三类,人工智能的偏见。可能有些正面的东西被识别为负面的东西。
第四类,在竞争关系里,实际技术其实还没有到位,和伦理的关系并不大。但是因为我们过分夸大了技术进步的情况,因此产生此类忧虑。
美国飞机上用的人工智能软件 ,它的判别就有错误。还有人们还很担心人脸识别系统被广泛使用以后会产生隐私侵犯,这个情况在中国没人反映,现在摄像探头装的越来越多,没人能说你的隐私可以受到保护。最后,AI换脸技术甚至造成了政治外交事故。
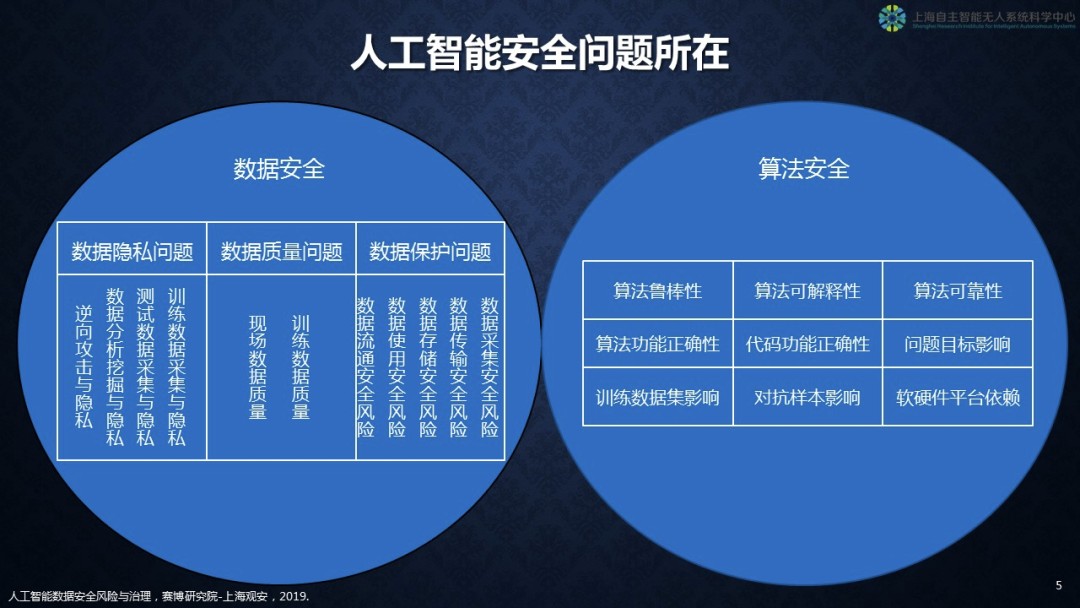
从技术总结,我将人工智能的安全问题分成两部分。
第一类是数据安全,第二类是模型安全。
我们的机器都是通过数据训练出来的,数据上现在有三种问题。
第一种,本身数据质量有问题。数据包含现场搜集到的数据,还有我们为训练模型而准备的数据,数据质量会影响人工智能产生的模型是否到位。
第二种,数据保护。传统的数据保护主要集中在传输、存储、使用,而近两年有了新的数据保护问题,数据流通安全风险。上海搞一网通达,数据要流动,从其他部门传到集中的办公室,在流动过程当中也会带来新的数据质量问题。
第三种,数据隐私。关于此不再赘述。
第二类,关于算法安全和伦理相关的东西很多,简单列举几个。
第一,算法鲁棒性。因为数据本身不可能没有噪音,不受到环境影响,如果算法缺乏鲁棒性,那么往往只在场景上做一些小变化,算法的判别就错误了,这会对我们的安全带来很大的威胁。
第二,算法可解释性。什么情况下是能够工作的,什么情况下它工作起来会有困难,这种可解释性工作才刚刚开展。还有算法可靠性,在IT技术里面,可靠性已被谈及很多年了。还有算法功能正确性,代码的功能正确性,这些都是现实问题。
以上讲的这些例子,我们把它分成三种不同层次的安全问题。
第一层,对抗攻击。因为环境的破坏、环境的干扰从而引起系统不安全。在交通牌上稍微做一些小改动,我们的汽车系统就不认识这个交通牌了,认为它是一个普通的里程碑标志。我们要尽可能地防御对抗样本,可是目前我们缺乏理论工具性支撑。这是人工智能安全当中很复杂的问题。
第二层,网络安全。人工智能系统是很容易被攻击的,隐私数据被窃取,漏洞被攻击,这种事情非常多了。目前来说人工智能也可以用在大规模高效率的网络攻击上,作为矛和盾两方面,它充分发挥它的长处。
最后一层,我们通常说的奇点问题。我们这里分成五大奇点。第一,规范奇点。目前我们无法保证人工智能不会突破人类现有的法律和道德规范,这是研究伦理和治理的人应该关心的。第二,经典理论奇点。人工智能及其影响可能完全超越我们经典社会科学所能做解释的范畴,这是一个比较令人担心的现象。特别是当机器人自我学习能力增强以后,可能会创造自己的语言,人类都不知道他们在想什么、做什么。第三,经济奇点。机器开始逐步替代通常的劳动力。但是这个情况可能要分两面来说,落后的生产方式慢慢会被先进生产方式所代替,一部分人虽然下岗,但却可能找到了新的就业方向。第四,社会形态的奇点。人工智能或许会把人类社会导向至一个自由人的联合体,而不是当前的社会治理状态。最后是技术奇点。人工智能会逐渐地摆脱人类的控制。
接下来解释一下哪些问题在我们研究人工智能技术时是很重要的。
第一,为了解决人工智能安全问题,我们首先要讨论可解释性。换句话说,在我们需要了解或者解决一件事情的时候,我们能够获得我们所需要的足够的可被理解的信息。我要知道它为什么能够工作,这是我们想达到的主要目标。
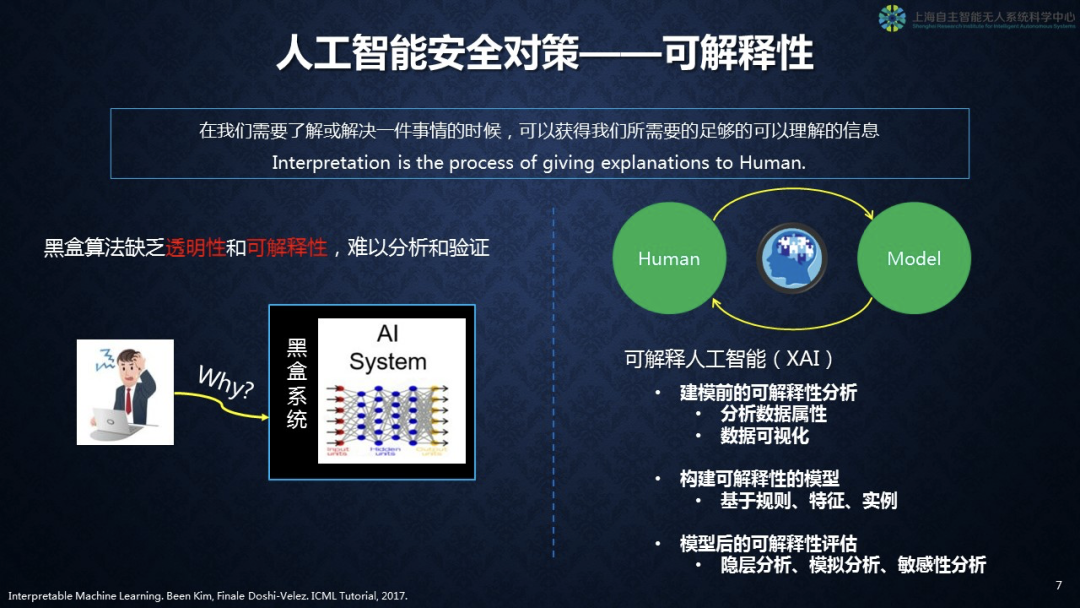
右边图上谈到人和机器模型之间的关系,我们强调所谓XAI——可解释人工智能,有三方面的事情可以做。
第一,建模前的可解释性分析。在此我们要解决对数据语义的分析,现在无非只是给数据打个标签,其他方面的信息给予是非常少的,还有要解决数据可视化问题。
第二,构建可解释性的模型。换句话说,要讲出它工作的规则,它有哪些特征,还要有很多实例作为作证。
第三,模型建立以后的可解释性评估。它到底干得好不好,它什么情况下有问题,对此要做隐层分析、模拟分析、敏感性分析。
第二,隐私保护。实际上在人工智能系统中,性能和隐私保护是天平的两端,我们没有办法说两个之中一个比另外一个更重要,我们希望在某种场景下能够取得动态性平衡。性能方面主要是功能和性能,隐私方面包含诸如我们的身份、数据、喜好还有其他很多行为,这些都应该属于被保护的隐私行为。我们在这个方面提出了一个方案,要把传统的机器学习技术改成面向隐私保护的机器学习新技术。
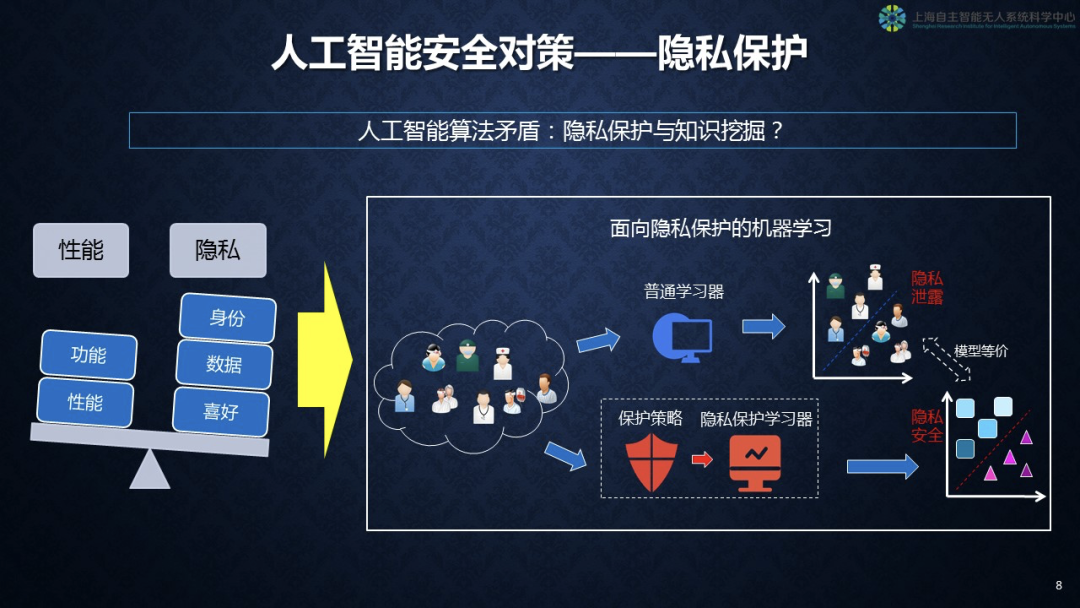
图右侧的蓝色图标就是一个普通的学习器,给它提供数据以后,它会判别出很多我们要的结果,其间是没有隐私保护的。如果我们把它的保护策略和隐私保护学习器结合在一起,以后会产生一些在模型上同构的输出信息,隐藏一些必要的应该被保护的信息。
第三,关于公平性。过去不少伦理的例子里面都提及歧视弱势群体,在美国还有种族歧视。在建模过程中要讨论如何保证模型本身的公平性。
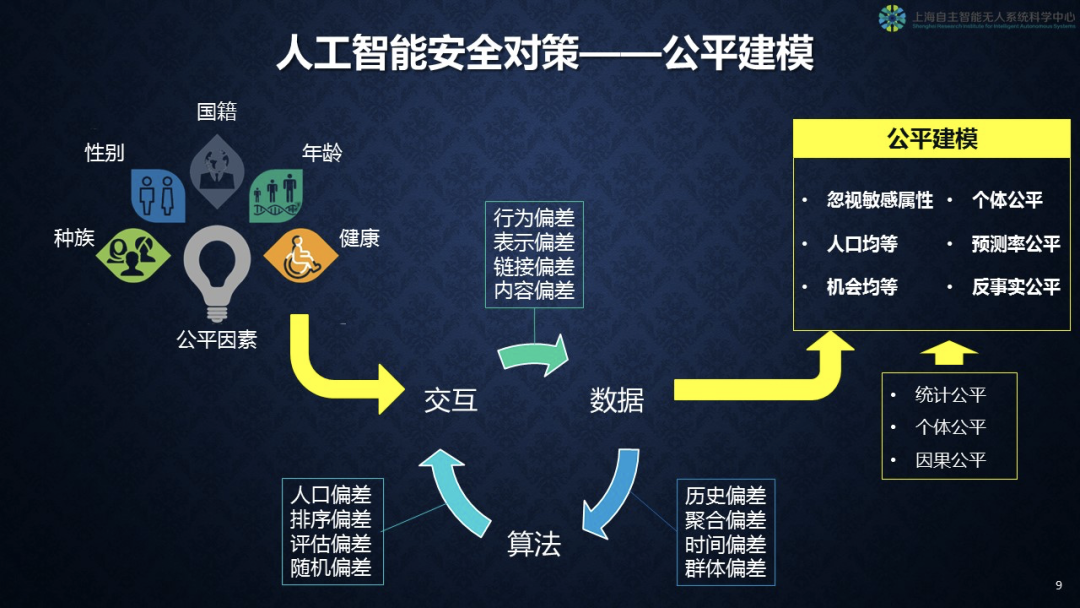
我们看一下图左上角的各类关于人本身特性的标签,比如种族、性别、国籍、年龄、健康情况,这里面应该有一个健康因素,放到整合数据里面。在数据算法交互的过程当中,我们要避免行为偏差、表示偏差、链接偏差、内容偏差,这对我们的建模是起很大作用的。从数据到算法,我们要解决历史偏差、聚合偏差、时间偏差、群体偏差等等,理想上我们要达到图右侧所写的公平建模,忽视敏感的属性,在人口机会上要实现均等,要实现个体预测和反思公平,这都是我们的奋斗目标。之后要用统计办法、个体办法、因果办法制定度量体系,看到底是公平还是不公平。
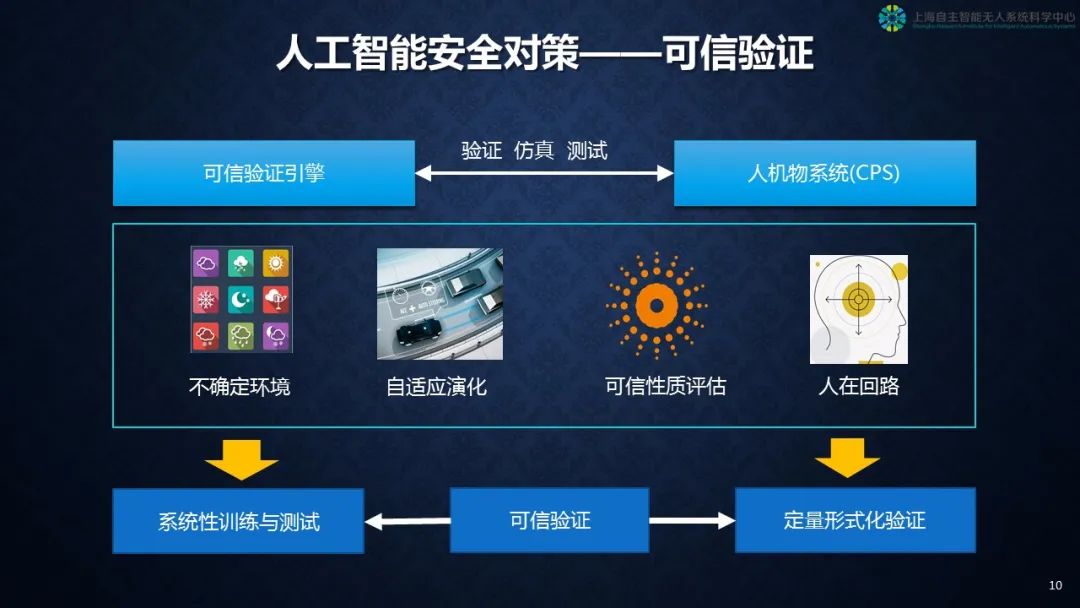
第四个对策,可信验证。这里有两个对象,一个是建设可信验证的引擎、手段、工具,一个我们目前用的人机物融合的系统,我们用仿真测试方法来验证。这里面临什么问题呢?
第一,我们面对的是不确定的环境,我们不知道环境会有什么变化,会发生什么突然事故。
第二,我们希望机器在被训练完以后自己还有自适应变化的能力,否则很难做到可信,所以它可能在不同环境下做事情会有适度的变化。
第三,我们有可信性评估,给它打分,可靠性到底几个9。
第四,我们要强调人在回路上。人和机器是共生的,这样通过系统训练与测试,加上定量形式化验证,我们可以实现某种意义上的可信人工智能产品。
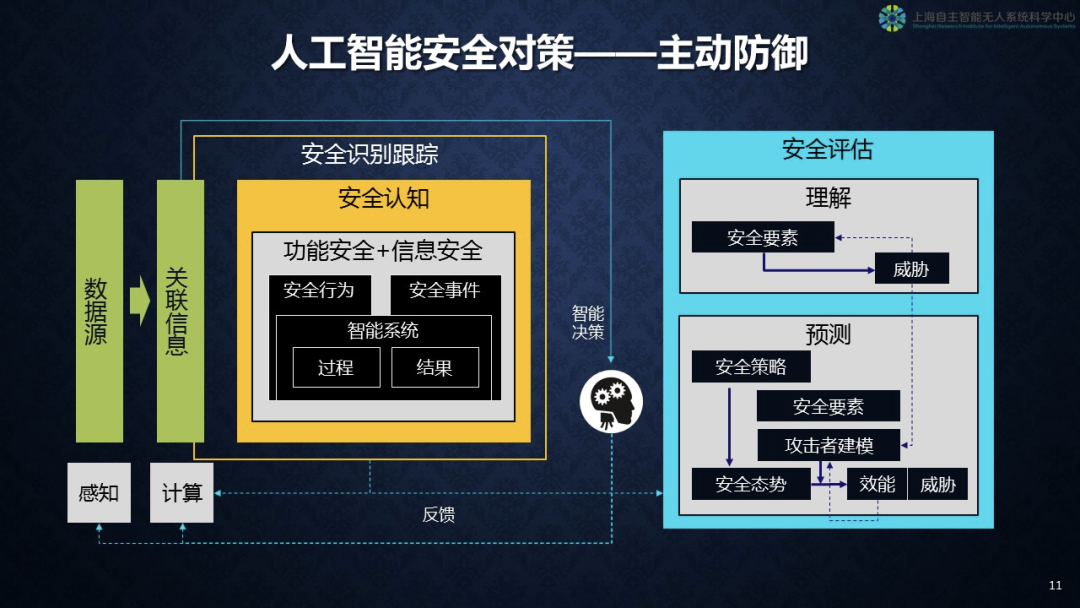
第五个对策,主动防御对策。图右侧是我们追求的目标,我们希望能够有一个安全评估的系统,它能理解人工智能系统的安全要素,知道什么情况下这个系统会受到威胁。你要知道敌人在哪里,知道自己的弱点在哪里。当然很重要的是要做预测,我们要建立安全策略库,通过感知系统搜集系统当前的态势,通过对安全要素和攻击者的建模,可以做相应的反应。整个安全认知是由两大部分组成的,有功能安全也有信息安全,因此我们既要处理安全行为,也要关心安全事件。整个智能系统的安全不仅结果是安全的,整个过程也应该是安全的。
第六个对策,伦理法律。人工智能伦理和治理已成为基本的共识,国际社会正在探索建立广泛认可的人工智能伦理规则,分成四大责任:
第一,伦理责任;
第二,安全责任;
第三,法律责任;
第四,社会责任。
在国际上已经有一系列原则和宣言了,最早是欧盟委员会人工智能高级别专家组发布了可信人工智能伦理准则。我们国家新一代人工智能治理专业委员会发布了“发展负责任的人工智能”。一些大的企业也在发布自己有关AI伦理原则,这是一个现状。
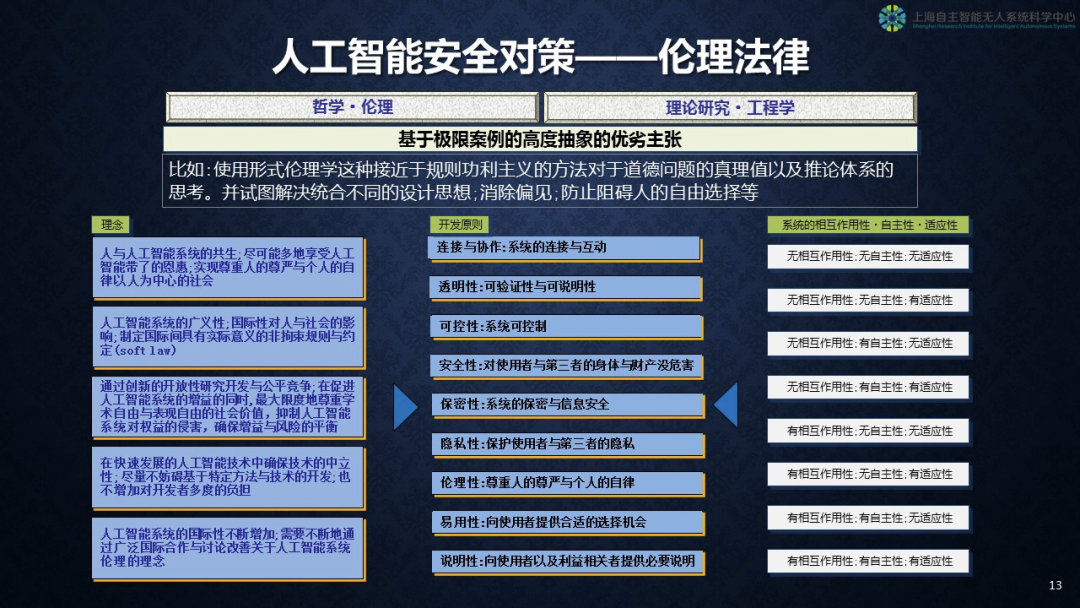
下面看一下应该从哪几方面做事情。哪些部门会和人工智能伦理治理相关呢?我将其分为社会科学和功能科学两部分,一块是做哲学、法律、伦理的,另外一批是做理论研究和工程学的。他们最希望发展什么呢?基于极限案例的、高度抽象的优劣评价体系。
分成三大板块来说,第一,理念。理念分成五个部分,
(1)希望人与人工智能系统能够共生,尽可能使人民群众享受人工智能带来的恩惠。
(2)人工智能本身发展过程当中有很大的广义性,换句话说,我们要追求现有的规则该怎么处理发展当中的一些矛盾。我们称之为软定律,和通常说的法律系统是有差别的。
(3)通过创新的开放性研究来达到这个水平,换句话说,在促进人工智能系统正义的同时最大限度尊重学业自由和表现自由的社会价值,抑制人工智能系统对权益的侵害,确保正义和风险的平衡。
(4)我们要尽可能保证中立性。
(5)最后人工智能系统的国际性要不断增加。另一方面要从人工智能本身讨论系统之间的交互性、自主性、适应性的不同组合产生的八种情况,中间提到一些开放原则,以及该怎么进行治理。
第七项对策是关于系统伦理的问题。人工智能系统试图对人的行为进行智能调控,因此带来了一系列值得我们深刻研究的问题。这是第一个我们关心的出发点。第二个出发点是,人工智能系统不仅会放大本来有的科研伦理问题,还会产生新的伦理问题。伦理问题本身不是人工智能带来的,原来其他的课题上也都有。

早先研究社会科学和自然科学都有研究伦理问题,我们提到应该有这样的原则,称为SSH,包含三个方面:
第一,技术开发者的伦理;
第二,学术研究者的伦理;
第三,科技成果的伦理。比如核武器,原来成果可以用来造福于人的,但是如果是武器,就变成了很危险的东西了,这就是科技成果伦理。在这个基础上人工智能要研究什么伦理呢?要研究法律社会科学伦理,要研究人性的概念,研究对世界发展流动所造成的问题。
下面我们提出一个流程,第一,从社会数理统计到数据的解剖。第二,从统计平均个体到数据解析单体。第三,避免极端差异不平等的计划。最后目标是走向更加公平的社会。
我的报告结束,谢谢各位。
报告人简介:
何积丰,中国科学院院士,著名计算机软件科学家。曾任中国科学院信息学部常委会副主任,现任 中国科学院人工智能创新研究院学术委员会委员、全国信息技术标准化技术委员会软件与系统工程分技术委员会主任委员、 国家可信嵌入式软件工程技术研究中心首席科学家、 国家可信软件国际联合研究中心主任、 中国人工智能开源软件发展联盟专家委员会主任委员、 中国工业技术软件化产业联盟专家委员会委员、 教育部可信软件国际合作联合实验室主任、 上海市科学技术协会副主席、 上海市人工智能战略咨询专家委员会委员、 上海市人工智能产业安全专家咨询委员会主任、 上海市公共数据开放专家委员会副主任委员、 上海市高可信计算重点实验室主任、 华东师范大学终身教授、 华东师范大学软件学院创院院长、 上海工业控制系统安全创新功能型平台(上海工业控制安全创新科技有限公司)首席科学家。
1965 年何院士从复旦大学数学系毕业,随后进入华东师范大学工作,先后担任教授、博士生导师; 1980 年被派往美国旧金山大学进修; 1984 年在英国牛津大学计算机实验室任客座教授、高级研究员; 1998 年担任联合国大学国际软件技术研究所高级研究员; 2001 年担任华东师范大学软件学院院长; 2002 年成为华东师范大学首批终身教授; 2005 年当选中国科学院院士; 2010 年被英国约克大学授予荣誉博士学位; 2015 荣获法国国家棕榈教育骑士勋章、 2016 年受聘为华东师范大学计算机科学与软件工程学院院长、 2018 年受聘为上海工业控制系统安全创新功能型平台(上海工业控制安全创新科技有限公司) 首席科学家、 2020 年, 创建上海自主智能无人系统科学中心可信人工智能研究所。

本文为何积丰院士在2020世界人工智能大会云端峰会治理论坛上的演讲报告。文章观点不代表主办机构立场。
声明:本文来自三思派,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
