从刷单谈起
一年两度的618和双十一,是电商和剁手党在仲夏和金秋的两场盛宴,也是刷单党的两场狂欢。竞争与压力之下,刷单成为了新入商户和低信用商户在官方选择之外速度最快的店铺成长方式。它们按订单价格及数量向“刷单军团”支付刷单佣金来提升虚假销量和好评,从而获取更好的信誉度和搜索排名。对于时间充裕的社会群体如学生党和宝妈而言,刷单也正好可以成为其动动手指就能月入千元的低风险副业。
可以说电商的发展,滋生并带火了一个由出资店铺、刷单中介、各级代理、刷手、空包物流组成的刷单产业。但其繁荣的背后,本质仍是恶意炒作信用和获取利益的不正当竞争行为,这一方面侵害了其他商家的交易公平,导致了“刷单找死”,不刷单等死’的劣币驱良币行业现状,另一方面也会误导消费者对商品和店铺的选择。为了行业的长远发展,电商平台反刷单欺诈,势在必行。

对于刷单欺诈,平台可以从订单、商品、店铺、用户、设备、物流等多个维度进行分析识别。但此类分析的弊端在于随着欺诈手段的不断变化,如刷单行业从机刷向人刷的升级、浏览下单方式的改变,都会导致已有的经验指标和模型特征的失效。这使电商平台在反欺诈的对抗过程中,总存在滞后风险。如果我们以一个更高的维度抛开细节来看问题,或许可以得到一个更好、更稳定的解决答案。刷单场景里,变的是欺诈手段和交易细节,不变的是交易结果。众多的刷手和出资店铺在一段时间内的交易关系形成了一张网络,这是电商平台在整体交易网络中的一个子网。如果我们可以有效的把欺诈子网从整体网络中识别出来,问题就得到了定位和解决。

图 复杂关系网络
关系网络与二部图
不同于对个体自身特征的分析,网络提供了对多个对象的关系之间另一种看问题的视角。把对象看做结点,把交互看成边,对象间的发生的各种关联自然会构成一张关系网络。从图论的角度出发,根据结点属性的不同可以把网络分为同构图和异构图。同构图是由同一种结点组成的关系网络,如家庭亲属关系、社交好友关系、论文间的引用关系等。历史上对于同构图的网络表示有很多研究,早在十九世纪就形成了几何拓扑学这一数学分支。在现代的同构关系研究中也逐步提出了基于网页链接的谷歌PageRank网页评级、基于结点关系紧密度的Louvian社区发现等重要算法。不过异构图在生活中的表现更为广泛,异构图是由不同属性的结点组成的关系网络,如由买方卖方以及中介组成的交易网络、由大V和其关注者组成的关注网络、由手机号\地址\证件号\IP地址组成的复杂关系网络等。二部图(也叫二分图)是异构网络的一种,它由两类结点组成,并且同类结点之间通常没有关联。前述的刷单欺诈,即是以出资店铺和刷手这两类结点组成的交易关系二部图。
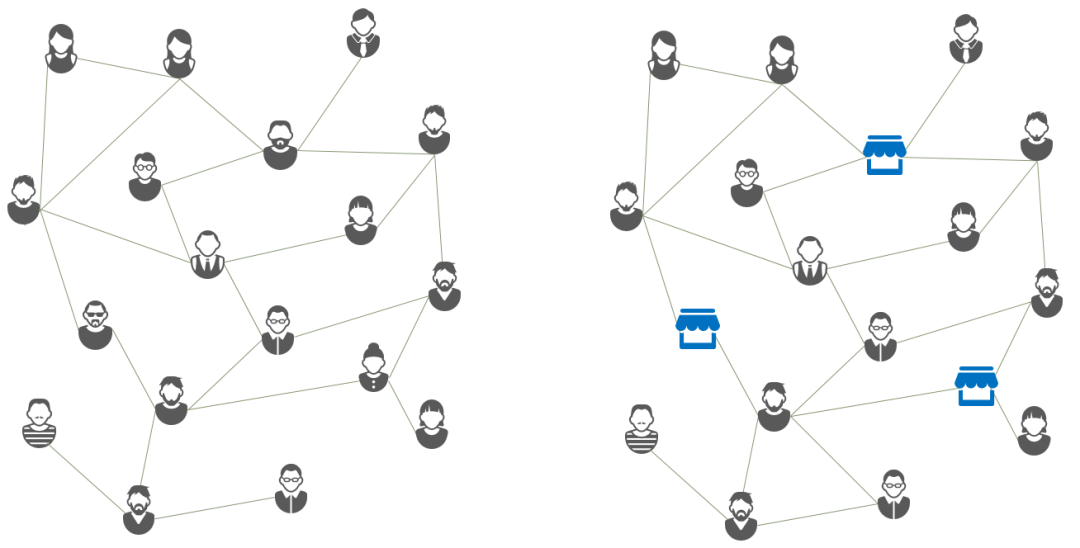
图 同构图(左)与异构图(右)
二部图下的欺诈
两类结点组成的欺诈场景还可以举出很多例子,如电商场景下用户对商户的薅羊毛、刷好评,如社交场景下水军账号的虚假关注、转发,又如消金场景下用户与商户勾结对平台的消费贷套现欺诈。这些行为都会使两类结点之间出现异常的连接分布,从整体网络看来其呈现出了一张致密的双边连接子图,且该子图内的结点与图外结点联系相对较少。我们把这种大量的、同步的非正常关联行为模式称之为Lockstep,即在本不应出现聚集行为的二部图自然关系网络中,出现了双边聚集性行为。
只要能把欺诈行为总结成一种模式,自然可以将其分离出来。但是欺诈者往往会对自己做出某种伪装以使自己看起来有向好的一面,意图绕过风控系统。如在刷单欺诈场景下,为了尽量贴近真实用户的购买习惯,刷单平台会对刷手提出一系列要求,比如要求货比三家、要求最低浏览时长、要求滚动浏览高度及停留时间、要求对于正常热销商品做一定购买等,这些行为都会导致风控经验指标和模型特征的部分失效。在二部图交易网络中,对于正常热销商品的购买体现为刷手为自己增加了一些优异的边连接,使自己看起来更像一个正常的消费者结点。我们需要一种能从这种复杂关系网络中对抗伪装、抽丝剥茧的提取出异常致密子图的算法。接下来对症下药引入Fraudar。Fraudar算法来源于2016年的KDD会议,并获得了当年的最佳论文奖。
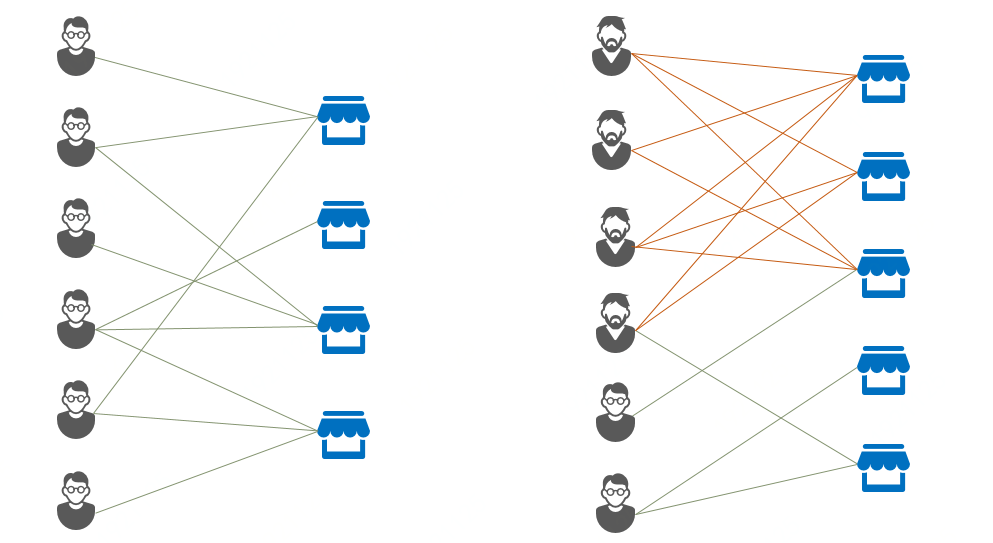
图 二部图下的正常连接模式(左)和Lockstep欺诈连接模式(右)
Fraudar算法介绍
简单来说,Fraudar定义了一个可以表达结点平均可疑度的全局度量G(·),在逐步贪心移除可疑度最小结点的迭代过程中,使G(·)达到最大的留存结点组成了可疑度最高的致密子图。接下来我们稍微细化一下算法过程,以刷单交易场景为例(定义二部图结点集合S=[A,B],其中A、B分别代表消费者和店铺的结点集合),看Fraudar是如何从交易网络剥离出刷手和其出资店铺的。
1.定义全局度量G(s)
全局度量的定义公式非常简单:G(S) = F(S)/|S| = (F(A)+F(B))/(|A|+|B|)。其中F(·)是结点可疑度的总合,|S|是当前的结点数,所以G(s)可以理解成网络结构中每个结点的平均可疑程度。当网络中增加一个高可疑度的结点时,其带来的F(S)增加百分比大于|s|带来的增加,G(S)增大;当增加一个低可疑度的结点时,其带来的F(S)增加百分比小于|s|带来的增加,G(S)减小;所以G(S)是全局可疑度的一个有效表达。结点总可疑度F(s)=F(A)+F(B),是两类结点可疑度的总和。而结点可疑度又是其所连接的边的可疑度的总和。Fraudar对边可疑度的定义准则是‘与B类结点连接的边越多,其可疑程度越小,即根据连接数降权。一个有效的边可疑度计算公式为1/log(x+5),其中x是边的数量,实际含义是交易量越大的店铺,其交易可疑程度越小,因为大概率是真热门店铺。下图展示了客户与热门店铺和刷单店铺的交易网络中,初始各边及结点的可疑度计算,计算过程为B类结点边数量的确定->边可疑度计算->A/B类结点可疑度计算。
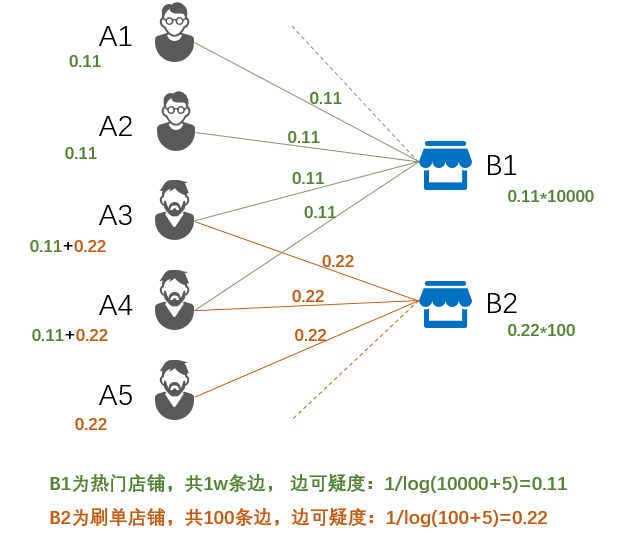
图 网络初始边和结点可疑度计算示意
2.结点的迭代移除
初始可疑度确定完毕后在模型迭代过程中,Fraudar贪心的逐步移除图所有二类结点中可疑度最低的结点。因为网络规模通常较大,如电商场景下每天会产生数百万的消费者结点和数十万的店铺结点,如果每一步迭代都遍历全部结点来定位最小值,将是非常大的开销。作者以空间换时间,为两类结点分别构建了用于快速搜索的优先树。优先树是一棵二叉树,以二部图中的A类或B类结点作为叶结点,并让父结点记录其子结点中的最小值。这样从根结点记录的全局最小值出发,可以快速定位到该最小值所对应的叶结点,然后将其从二部图中删除,并更新网络可疑度、更新优先树。
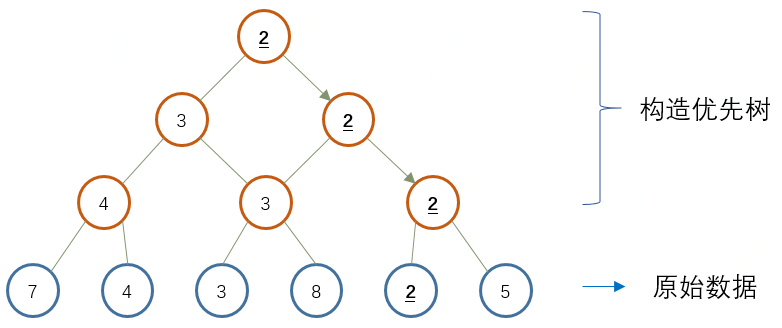
图 基于优先树的最小值快速定位
3.结点可疑度更新
迭代过程对结点的删除改变了网络结构,每次迭代后都需要在保持边可疑度不变的前提下,更新剩余有关结点的可疑度。迭代初始,A类结点中正常的低活消费者因为边连接少、可疑度低而被首先移除,如下图中的A1结点。同时B1商户因与A1关联的边连接被删除,其可疑度也被更新降低。如此往复,低可疑度的A类用户结点逐步减少、正常B类商户结点的可疑度也逐步降低而被删除,网络剩余结点的全局平均可疑度G(·)逐步增大,直到最后一个结点被移除而归为0。
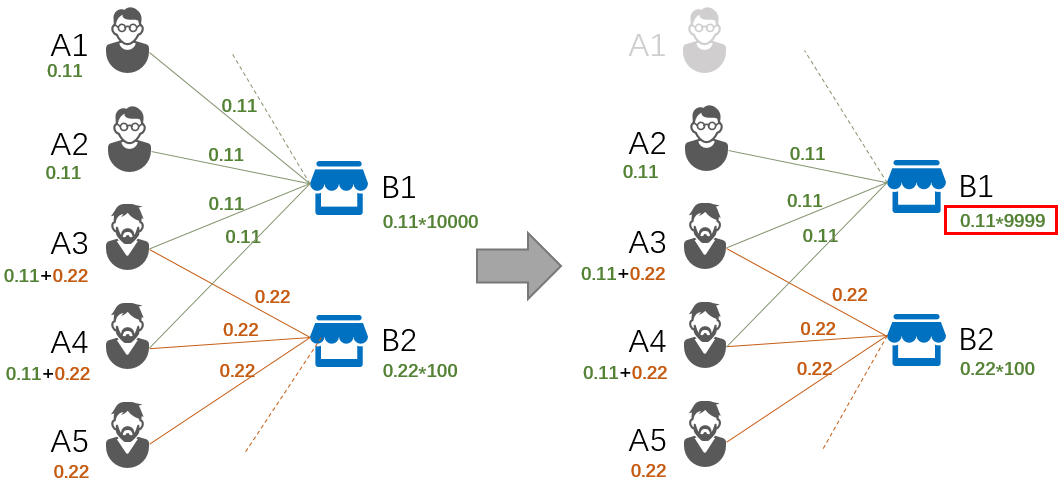
图 结点移除导致剩余网络可疑度更新
4.回溯最大全局度量
全局平均可疑度G(S)在结点的贪心迭代移除过程中会取得最大值,当全部结点迭代移除完毕时,回溯此过程中使G(·)达到最大的迭代,此时对应的留存结点即我们的目标结点,他们之间的关系网络是整个网络的最可疑致密子图。该子图中两类结点之间关系紧密,且都与外部结点连接相对稀疏,这在公共电商平台下是违反社会关系规律的一种连接模式,可以认为是拥有极大刷单概率的可疑群体。全图的一次迭代可以获得一个高危群体,将该群体的结点从图中删除后再运行一次迭代,又可以获得另一个次高危群体,如此往复可以根据业务需要得到多个群体,再进行后续排查分析。
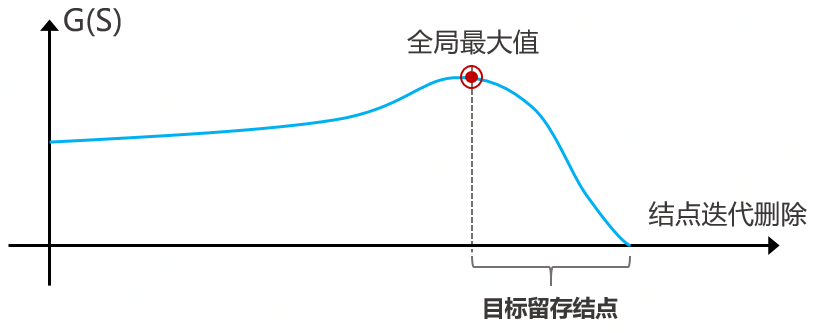
图 全局平均可疑度G(S)得分曲线
可疑致密子图分析
从模型有效性来说,Fraudar有着和其它无监督算法如聚类和异常检测共同的缺点,即模型输出结果的可解释性差、稳定性差,需要结合统计性指标做出二次判断。但专家判断需要大量的人工干预,且不具备泛化能力,有效性完全取决于专家业务能力。例如当我们从二部交易网络中提取致密子图时,除了刷单,可能还提取出了多个羊毛党或黄牛网络,这些拥有类似连接关系的欺诈模式都会被抓取出来,只有经过充分的二次定性才能进行后续的案件处理。当然,为了增强模型输出的可信度,也可以根据先验的业务知识对图做预剪枝,同时可以有效的减少数据量和运算量。如刷单场景下我们预先可以把所有高信用的白名单店铺从结点中移除,只保留更危险的低活店铺来提高准确度。在实际中为提高社群的挖掘准确性,我们开发了一套无监督社群发现和有监督模型协同训练的模型框架。
社群发现与有监督的协同训练
基于关系网络的无监督社群发现考量了各结点间的拓扑关系,但仅以交易或评论、关注等交互行为的频繁程度来判断风险有些片面,没有考量到结点自身的属性和行为特征。这些特征如消费者的注册时长、历史活跃度、设备稳定性,如店铺的漏斗转化率、交易增长率等都是对欺诈程度的一个有效评价。高活跃高信用的消费用户,一般是不会参与到刷单和薅羊毛等活动中去的。而有监督算法虽然使用了高维特征来对样本做刻画,但这些特征并不能很好归纳其邻接以及更远的网络关系。为将两类互补信息做有效结合,我们使用了一种两类模型协同训练的方法,如下:

图 社群发现与有监督模型协同训练
在建模初期可以获得的数据包括少量的欺诈标签、用户结点特征、商户结点特征、以及用户和商户的交易关系组成的边。我们用两类结点的关联关系构建了交易二部图,以全局可疑度作为度量标准进行Fraudar无监督社群挖掘;用欺诈标签、用户结点特征和商户结点特征这些单点的数据进行有监督建模,得到单点的欺诈概率。在此过程中,一方面,有监督模型的结果对无监督做指导:其模型打分结果可以对结点可疑度做加权调整,使结点可疑度能够从拓扑信息和单点行为属性上综合表达其欺诈程度;也可以通过计算输出社群的模型平均分和在特征空间类内聚集度作为社群挖掘质量的有效性评价。另一方面,有监督模型也从无监督模型收到了正向的反馈:通过对有效社群的分析获得了更多风险标签和特征构建上的指导。二者综合利用各方数据信息互相协同形成模型闭环,通过多轮迭代不断提升社群挖掘的数量和有效性。在建模初期标签稀缺时,一个简化的替代版本是以专家经验构建的多维线性打分模型来替代有监督模型,在经过几轮迭代积累足够的标签后再进行有监督学习。
运算效率提升
Fraudar的一个缺点是它的串行运算特性导致在大规模二部图上运算缓慢,其每次迭代只动态的删除一个结点并更新剩余结点状态,对于由1千万个消费者和10万个店铺构成的交易网络,一共需要迭代1万亿次。但在迭代初期,模型移除的结点都是交易量很少的低可疑度结点,由于单位时间内的客户交易量服从长尾分布,在总体客户中有大量这样低交易量低可疑度结点的存在。为此我们设定了一个对网络状态自适应的可疑度阈值:2*G(S0),即初始全局可疑度的2倍。在初始时将结点可疑度低于此值的结点提前移除,可在不影响网络欺诈模式的前提下,减少约40%的计算量。在开始迭代后,也以x/1000的数量做结点的批量移除来减少串行运行量,其中x是当前的某类结点的留存总量,之后随着留存结点数量的减少,每次批量移除的结点数也在不断减少,精度不断提升,以这种先粗后细的手段使模型在运算效率和子图挖掘有效性上做出了平衡。当然,批量的结点删除也需要在优先树的最值查找策略和网络状态更新上也做出调整,并付出相应可接受的计算代价。

结语
搭配上有监督模型对结点的刻画,Fraudar成为了一把对抗二部图欺诈模式的精准利器。‘如果你拍的不够好,是因为你离的不够近’,这是20世纪最伟大的战地摄影师罗伯特·卡帕的名言。在电商、支付等行业的蓬勃发展带来的各类欺诈与反欺诈攻防大战中,如果你做的不够好,那是因为你分析的不够细致,没有挖掘出所有的欺诈模式。如果你做的不够好,也可能是你站的不够高。抛开繁杂的细节,不妨站在更高的维度把交易抽象成一张网,也不妨试试今天的Fraudar。
参考文献
[1] "FRAUDAR: Bounding Graph Fraud in the Face of Camouflage." Hooi, Bryan , et al. the 22nd ACM SIGKDD International Conference ACM, 2016.
声明:本文来自京东数科风险算法与技术,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
