
现在BlackHat官网的ppt下载真是麻烦,不再像以前放在一页里面直接显示,而是在议题列表里面,一个个点进去翻看才能下载。
这种事真要一个个去下载,近百个议题,你得下到手软。
不搞个爬虫去自动化下载,都对不起攻城师的头衔。
原本是想用scrapy写个python脚本去批量下载,后来决定用更加高效的方法:使用Web Scraper这个Chrome插件,通过点鼠标就可解决,无需编写代码。可直接在浏览器里面模拟网页浏览与操作,可以有效绕过一些反爬虫机制。

通过Chrome商店安装好Web Scraper后,在其“开发者工具”里面可以看到:

点击“Create new sitemap”,设置下任务的名称,以及爬虫的起始页,这里就取BlackHat的议题列表地址:

创建后点击“Add new selector":
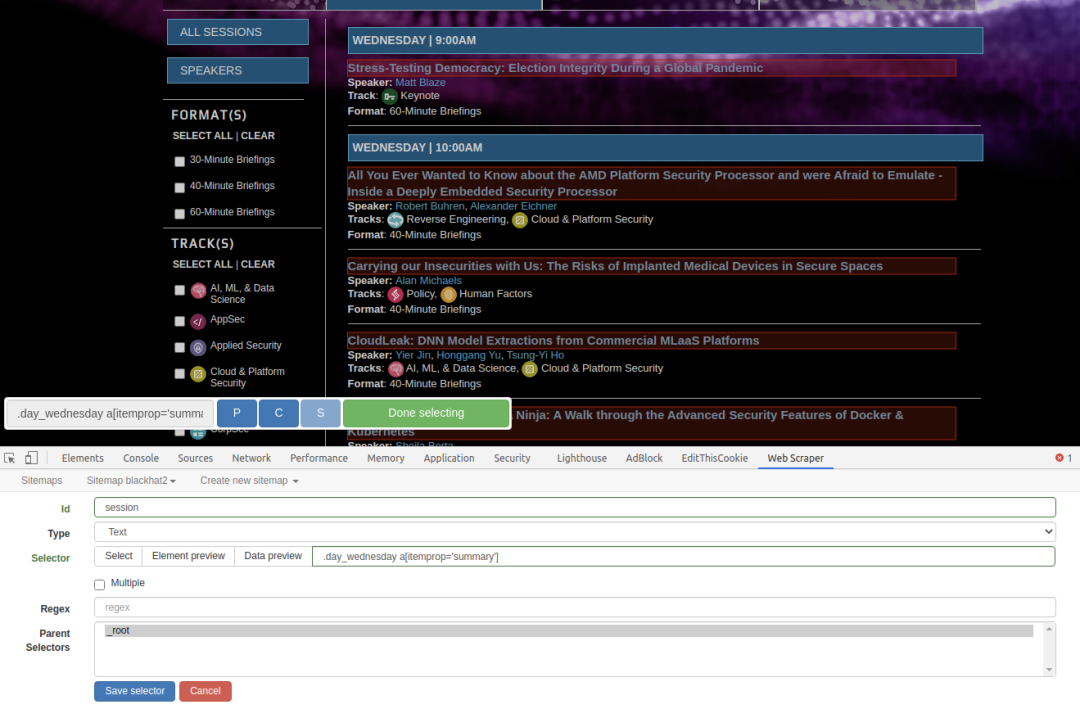
设置id,Type为“Link",为的是获取二级页面的链接地址,选择”Select”,然后在页面中去选择链接的位置,它会实时显示出红框,帮助你识别。
注意:这里必须勾选“Multiple”,否则无法选上所有议题链接:
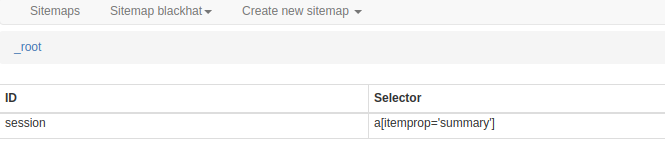
点击创建的“session”进入议题详情页面,即二级页面:
接下来就要获取PDF下载地址了,这里包括slide和paper两个下载地址(不一定都有提供,但全选上不影响),然后继续按前面的操作去添加selector(下载链接的页面元素)。此处“Type”选“Link”而不是“Element click”去模拟点击下载,是因为chrome里面点击pdf链接会直接打开,所以获取链接地址再用命令行去下载:
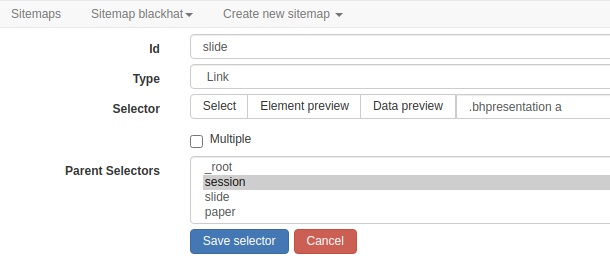
这里“Parent Selectors”就是父页面中我们设置的对应id,层级关系相当于爬虫进入下一页再找目标元素一样,用它我们也可以实现翻页效果(翻页经常在get参数中设置,所以有时可以直接在起始URL中设置页参数范围,比如http://test.com/abc?page=[0-100]),保持默认就可以了。
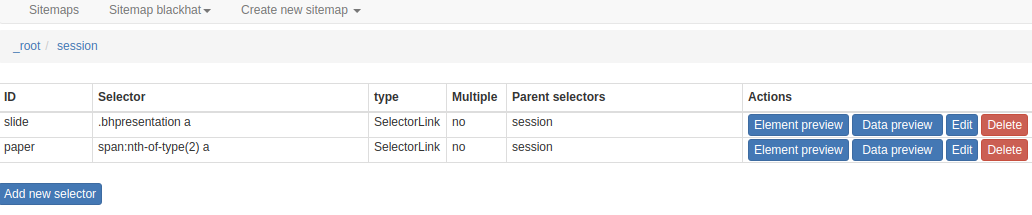
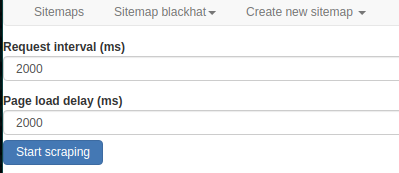
最后点击“Sitemap blackhat” =》"Scrape” =》“Start scraping”开始爬虫:
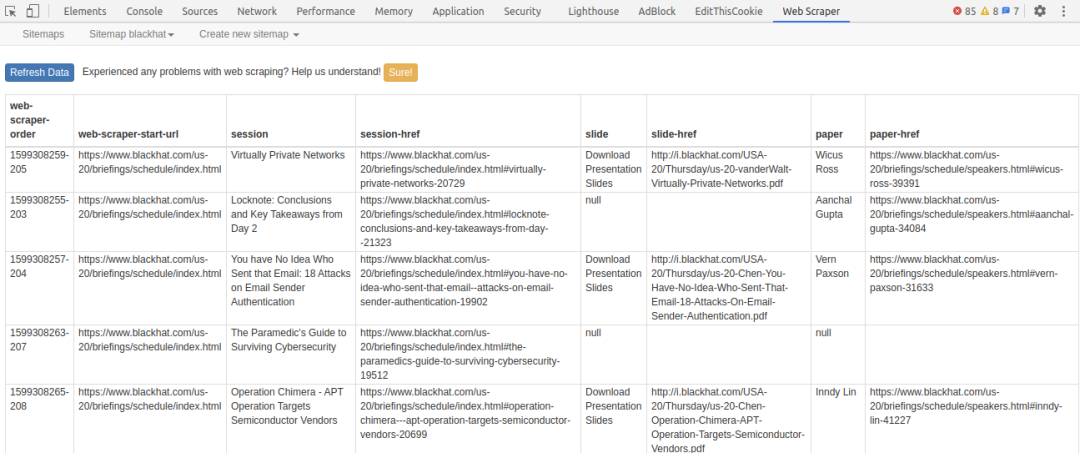
再将爬虫结果导出csv,用命令行批量下载就可以了。
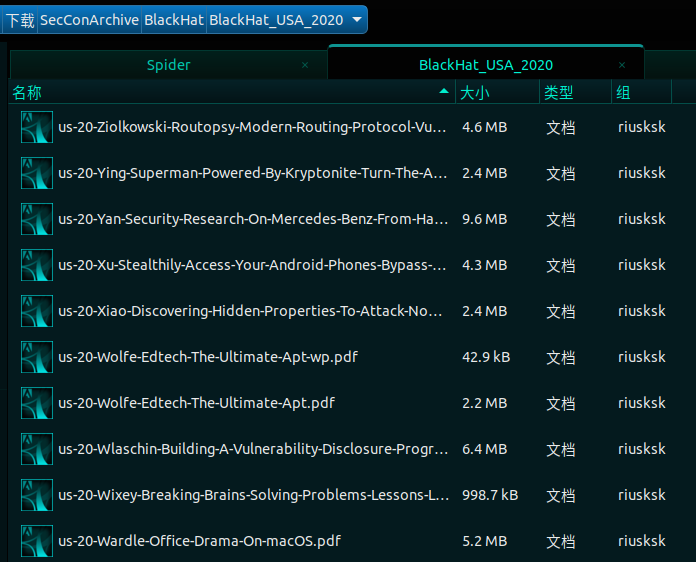
BlackHat资料打包下载地址:
https://github.com/riusksk/SecConArchive/tree/master/BlackHat/BlackHat_USA_2020
声明:本文来自漏洞战争,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
