本文整理自2020北京网络安全大会(BCS)企业安全运营实践论坛上奇安信网络安全部大数据平台负责人邓小刚的发言。
邓小刚,SIEM领域ArcSight国内第一人,一个纯粹的技术工程师。

大家好我是来自奇安信的邓小刚,很高兴参与北京网络安全大会企业安全运营实践论坛,我分享的题目是《海量日志采集、解析实践》。
内容主要是五部分:
一、简单的自我介绍;
二、面临的挑战与应对;
三、日志采集的手段;
四、案例的定制;
五、现状的简述。
一、简单的自我介绍

我现在在奇安信集团网络安全部。网络安全部主要是负责公司内部安全,我在网络安全部主要负责内部安全大数据平台架构的实施和维护。我有20年以上的IT和安全从业经验,2007年开始从事SIEM的学习与实践,当时主要是从事与ArcSight相关的产品的实施,同年获得了ArcSight相关的AEIA和AESA的官方认证,也就是ArcSight架构师和分析师认证。2011年帮助公司获得了中国首家ArcSight Service Partner认证,成为国内第一个认证的讲师。这些年主要参与的比较知名的企业跟SIEM相关的项目有——主要是港交所的培训服务、招商银行、世纪互联、中石化、神华集团、厦门国际银行、包商银行的SIEM相关平台的搭建,安利中国和太平洋保险主要是做的跟SIEM相关的咨询专业服务。
二、面临的挑战与应对
挑战:

(一)日志量非常大
因为以前大多做的是商业化的产品,以前商业化产品最大的问题是在很多情况下都是单一节点的,它只能做到纵向的扩容,很难做到横向的扩容,大家知道现在IT发展很快,日志量非常大,不能横向扩容就会难以为继,系统的性能受到很大制约。
(二)商业化产品都非常昂贵
从Splunk进入这个领域以后,它就推出了一种叫做eps(每秒日志量)计费的方式,这种计费方式对于小规模可能是一个比较理想的状态,但是作为一个企业级的SIEM就会有问题,一方面是预算不太好评估,你很难评估日志量有多少,另一方面就算平台搭建完成,面临的一个问题就是日志越来越多,那么预算就会越来越大,很难承受。
(三)灵活
因为SIEM的特征,它本身并不会产生日志,它不像NOC,比如说像网管,有很多探针。SIEM实际上是依赖于其他的第三方日志,这些日志源本身就是会存在如下几个问题:
1、安全领域本身的新技术、新产品就非常多,它的日志格式就会不断的变化,产品也不断地迭代,后续做的很多的我们叫做Use Case,就是规则、报表、仪表板等内容,就有可能因为日志格式的变化导致后续很多的这些Use Case会失效。
2、即便是传统的、成熟的产品,比如Windows,日志也会变化,比如说Windows2003以后整个事件的ID和事件的格式已经发生了天翻地覆的变化。所以怎么能够规避这种日志格式的变化,导致后续做的Use Case依旧能用,这是一个很重要的问题。
3、因为这些日志不是由SIEM产生的,就会有一个问题,怎么能发现日志有还是没有,就是日志有效性的监控。其次是日志质量问题,一旦格式变化,导致解析会失败。
(四)度量
这是很考验一个企业的IT治理的能力。因为日志的分析很多情况下对时间很敏感,尤其是跨设备分析的时候,如果时间是不同步的,做跨设备的分析和报表,基本上没有办法在同一个时间维度做处理,所以所有的SIEM系统都需要有一个比较好的对日志源怎么样做度量的手段。
应对:
对于以上问题,我们现在采取的方法:

(一)解决横向扩容的问题,解决性能的问题。实现横向扩容性能的问题,现在比较好的话就是虚拟化的集群,比如说虚机解决Iaas平台的处理能力。像Kafka、ES和Redis这些就是相当于Pass平台的集群,都做得很好。我比较幸运在奇安信,奇安信比较大,本身也有相应的一些技术平台,比如说虚拟化的Iaas平台,Kafka平台、ES平台和Redis平台,这些Pass平台都有现成的,所以基本上我就不用花过多的精力在这些基础设施的搭建上,通过虚拟化的方法解决这个横向扩容的问题。
(二)我加入公司以后肯定不能再用商业化国外的产品,我们基本上采取一些开源的解决方案,ELK是一个比较好的方案,也是现在比较成熟的解决方案。使用开源产品,当然一个可以解决自我可控和license费用的问题,开源也方便可以个性化、客户化。当然开源产品也有开源产品的问题,就是说不在license上付费那就要填很多的坑,所以说我比较幸运,因为在公司有这些基础平台的服务团队,所以我在这些基础产品上面的这些坑,基本上由他们来去负责,更多的是参与跟SEIM相关的问题解决。
(三)灵活性。灵活性就是说目前来看,虽然说传统的用类似Splunk、ELK的解决方案做全文检索,其实都是挺方便的,但刚才说了要解决灵活性的问题,后续做的Use Case,规则、报表、仪表板用的日志,还是要做一些规范化的解析。但是需要前期做一些调研,并不是所有的日志都需要做解析,有些情况它只需要做全文检索就行了,所以我们是按需做解析,按需去做规范化的格式,因为解析到什么颗粒度,跟你后续做Use Case的需求是有关系的,所以我们基本上是按需做解析。
(四)富化。这块主要解决几个问题:
1、解决度量的问题,就是要去检测时间同不同步。
2、解决一些本来日志报文里面没有的内容,可能需要把这些内容给富化进去。
3、有一些比如IP,日志里,可能只有账号,可能只有IP,但是我们人肉去分析日志的时候,不是简单地去看IP,我们可能会去考虑这个IP它的属性,属于哪个网段、属于哪个部门,是开发的、还是生产的,那实际上我们要把这些信息都要富化到这些原始日志里,成为一个规范化的日志,后续去做关联分析的时候就会比较简单容易,定制的规则相对来说也比较好维护。
三、日志采集的手段
日志采集这方面,我们结合公司现在的情况。公司在操作系统层级,基本上是两大操作系统,一个是Linux,一个是Windows。
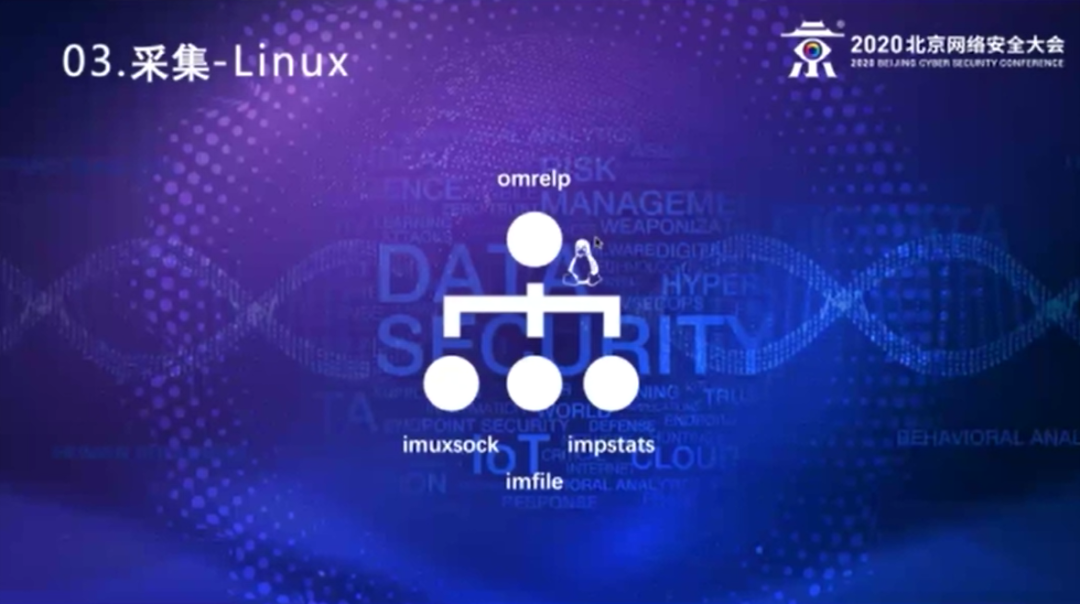
在Linux上,我们就直接使用它现在Linux主流的rsyslog,因为rsyslog本身就是一个开源的产品,第二它的性能的确比较高,而且它的input、output的模块会比较丰富。我们基本上在就是使用imuxsock模块,将本机的一些syslog收到的日志转发出来,imfile把本机上面文本性的日志转发出来,还有一个impstats这个模块,它会去定时地汇报rsyslog自身的健康状态,比如说rsyslog的一些规则、动作的执行情况,以及队列的执行情况。rsyslog它本身有一个协议叫RELP,可信日志传输协议,因为后台接收日志的集群也是由rsyslog搭建的,所以我们直接会用RELP协议,从客户端将日志传输到后端的日志集群。
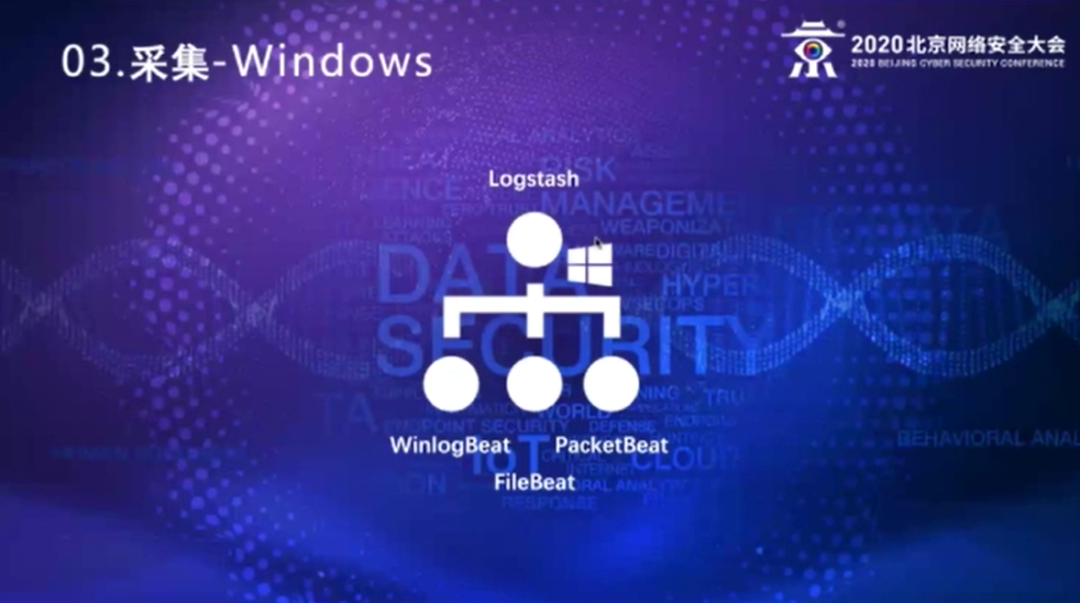
那么在Windows平台上,我们基本上是用elastic的beat家族,用winlogbeat采集eventlog,filebeat采集文本类日志,流量类的主要用packetbeat来采集。当然之前也用过其他的一些产品,当时也曾经用过nxlog,它也有好的方面,nxlog只需要一个软件,它既可以采集Windows eventlog日志,也可以采集文本类的日志。但是nxlog最大的问题在我看来就是,因为它还有企业版和社区版,那么社区版实际上有些功能是不足的,最大的问题就是网络一旦断了它不会重连,这样的话,在服务器端上部署还没问题,但是在客户端、桌面上去部署就会有问题,所以在Windows这个平台上基本上都是通过beat这个家族的日志采集,发往我们后端日志采集的Logstash上去做处理。
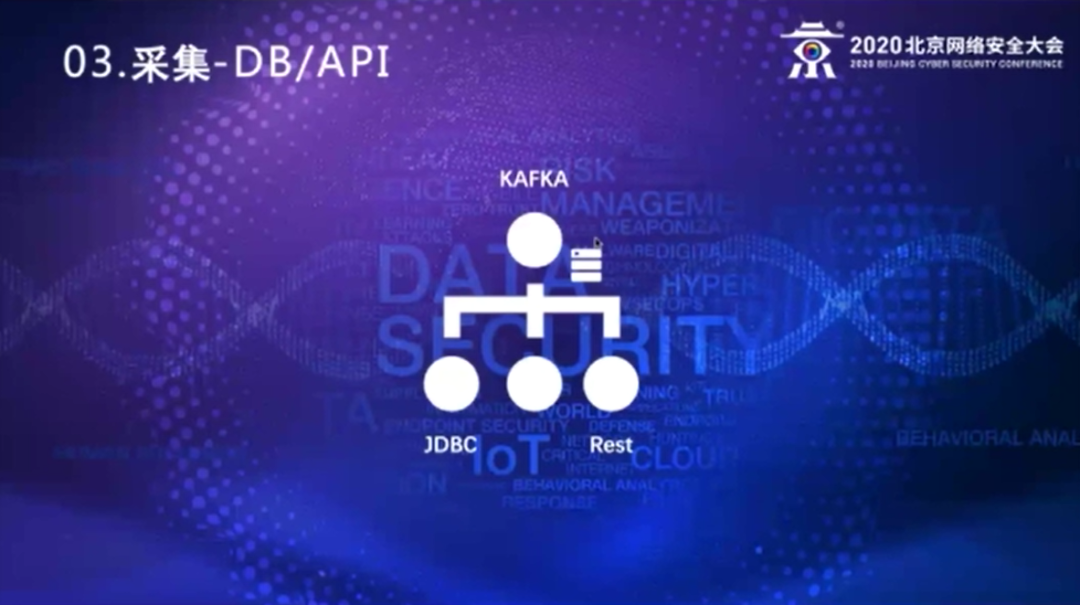
还有些日志是存在数据库,基本上是些应用类的日志,它的审计日志会记在数据库里,基本上是通过JDBC去读取这个数据库的日志后转发。还有一些,通过Web service的方式,通过rest去读取,比较典型的就是在公有云上的一些服务,通过自己写的程序,通过JDBC或者rest方法获得日志以后,直接发送到后台的Kafka集群里面去。
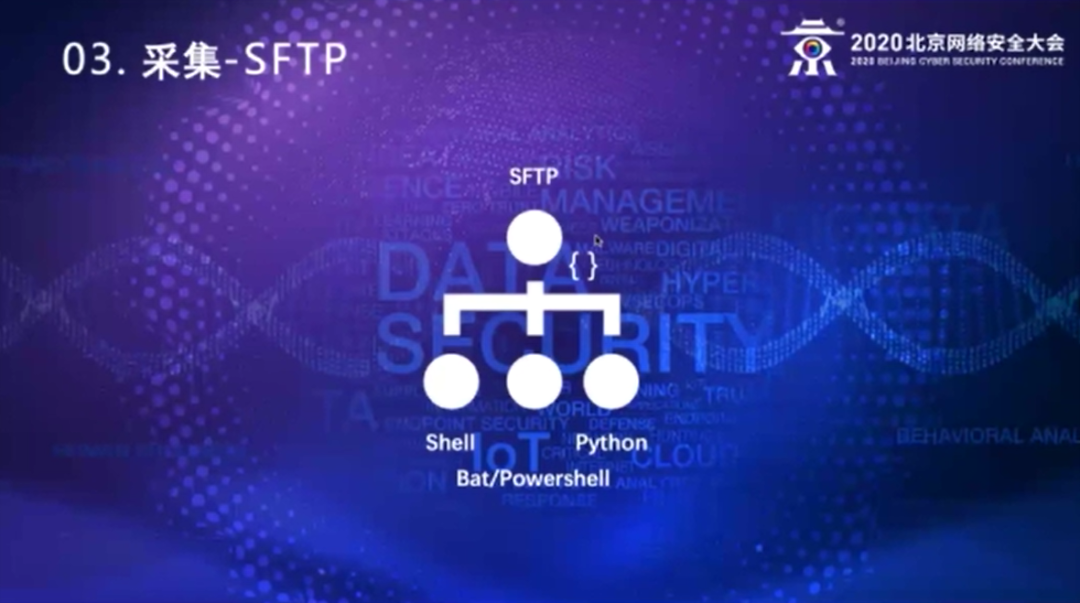
还有一些特例的日志,就是比如说我们现在碰到的,我见过的主要就是SAP的日志。因为SAP的审计日志是文本型的,只不过它的格式是UTF16,那用UTF8处理UTF16,会存在一些分词、分行的问题,我们就采取一些脚本的方式去传输这些文件。
还有个考虑就是SAP的系统管理员,一他会很介意你在服务器上装软件,二他不知道你干了什么,三他要从性能的角度考虑,他觉得随时有控制力,能够把它断掉。这样通过脚本的方式第一他能知道我们干了什么。第二他也可以随时把我们的这个传输脚本的crontab给停掉,增加它的可控性。
对于Windows,我们基本上在特殊的情况下写BAT、PowerShell来传输,但目前来说我们还没有碰到过这样的情况,还有一些情况要写Python脚本,这种种情况是什么呢,就是一些合规性要求挺高的,它不会给你对外提供服务,让你远程来拿,但它可以接受你在上面装一个脚本,从里面往外吐日志,就是说你往外发可以,但是从远程来读取它不接受。这样的情况下,我们都是写脚本的方式采集。基本上就是我们用这四大类的方式来采集日志。
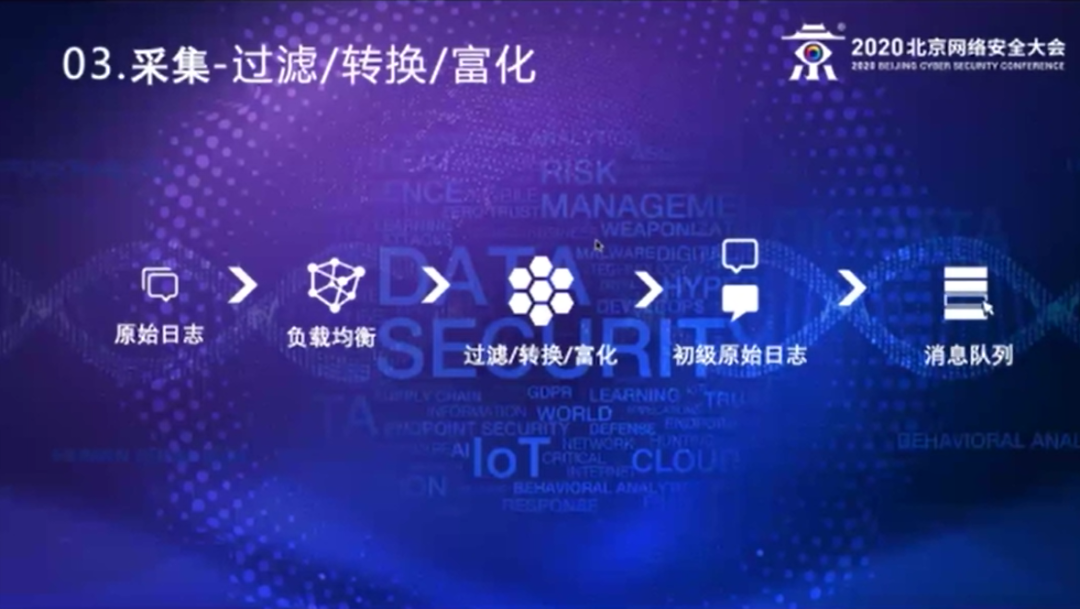
日志从原始日志采集了以后,会发到我们公司的一个LVS的节点上,LVS转发我们后台的realserver中。我们基本上是两大类,一个就是rsyslog类型的,接收从rsyslog转发过来的日志,还有一部分就是logstash的集群,接收从beat转发的日志。我们之所以要有一个集中的接收点,主要的考虑是在于:
第一,所有的日志就像刚才介绍的日志量大,即便是我们横向扩容,但实际上有些日志是跟我们安全没有什么特别直接的关系,尤其是有些跟完全没关系,也不参与任何的关联分析的,那么有些日志我们就会把它过滤掉。我们是在这个集中接收点上做过滤,如果是由原始日志的节点上直接发送到Kafka的集群上,这部分工作就做不了了。
第二,我们还要做一些转换。这部分的转换,基本上是在Logstash上去做。就是在winlogbeat收集Windows日志的时候,它收过来的内容有一部分就是像百分号数字,在原始eventlog里面看的时候,可能是一个中文,实际上它是做了一个翻译的,原始日志是通过eventlog发过来的时候,这部分它就还是原始的这个数字,所以我们要在这个地方做一个转换,把它变成可读的文本信息,方便后续的判断、分析,让我们的运营人员能看得懂这些日志到底什么意思。
第三,富化。这个富化包括几个问题,刚才说了一个解决度量的问题,就是说如果你原始日志的报文,里面可能不含设备地址,它可能只有消息,我不知道是从哪台设备发过来,日志报文里面可能没有设备地址信息,一旦产生了告警的时候,要去做反向追溯的时候,找不到哪台机器,这就会是一个大问题,所以我们在这部分里面要富化这部分内容,因为syslog包头里面是蕴含了这个发送地址,所以我们会把这部分的内容加到日志的内容里面去。同时我们也会把日志的时间、接收的时间也会这个富化到里面来,这样是为了方便后续做度量判断,这样形成了一个叫做初级的原始日志。
因为rsyslog和Logstash本身功能比较强,可以定制各种各样的过滤器,可以基于一些日志的特征,将不同的日志发到后台Kafka的不同topic里面去,而不是放在一个里面。放在不同的topic,一个是解决性能的问题,第二就是简化授权的问题,因为我们采集的日志里头不仅是网络安全部使用,可能其他的部门也会去用使用这些日志,这样的话授权可能只需要简单的基于某个topic做授权就可以了,这就是我们在采集日志上面的考虑。
四、案例的定制
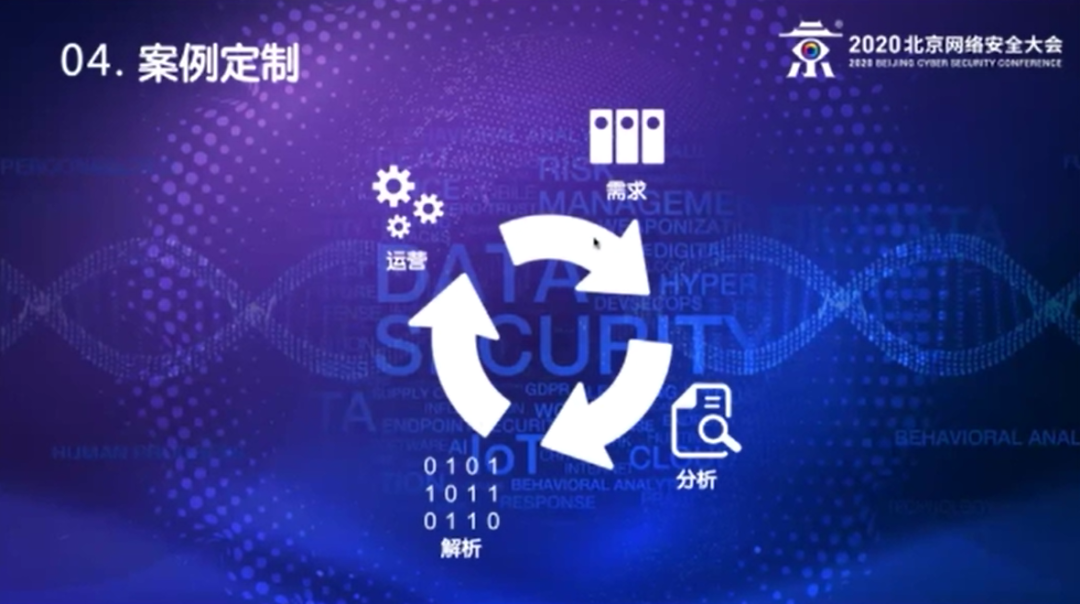
采集日志是要做Use Case或者案例,实质上就是解决使用场景的问题。这部分,实际上是跟软件开发本质上是一样的。
首先要有需求。需求需要去做详细的分析,我见过很多企业的需求都很宽泛,比如说我见过最常见的需求就是找出所有的异常。简单地说,我要找出所有的异常是什么。
首先要定义什么叫异常,或者定义什么是异常什么是正常。
第二,定义完什么叫异常什么是正常以后我们要去找,有没有这样的日志内容。
有些是有日志内容,有些就没有,那么我们要解决这些日志或者产生实现Use Case需要的数据源。有了数据源以后,数据源里日志的哪些关键字段是我们需要的,是要参与后续做分析的,要把这些内容去做解析,确定要解析到什么颗粒度。解析完了以后我们定制相应的Use Case,实际上在企业里面,一开始这些需求很多情况下,说的难听点叫拍脑门的想法,真正要把它做成一个可运营的状态,像四处报警这种就是一个不可运营的状态,这个时候就会需要有运营团队,结合真正了解公司实际的网络结构,公司的安全策略,有大量的加白的工作,把这些杂音过滤掉之后,可能还需要经过两三个这样的一个循环,这样的一个Use Case才是一个真正的有生命力的Use case,而不是说做完了就四处报警,这样其实是没有意义的。
不要追求数量,追求可运营的状态更重要,这是Use Case定制的基本策略。
邓小刚

以下我们举个例子:比如说公司会用Gitlab,那可能一开始提的一个要求就是对Gitlab的代码拉取情况做监测,我相信很多人都会有这样的需求。这个时候,我们要去看Gitlab相关的文档,首先我们是基于社区版而不是基于企业版,因为企业版它本身有很多高阶的功能,但是我们并没有去用企业版,所以我们只是基于CE版。其次,我们发现Gitlab拉取代码的特征,外部获取代码的方式是http、ssh,Gitlab本身有很多种类型的日志,大概有将近十种,但是在研究了以后就会发现在api_json、application_json、git_json、Gitlab_shell这4个日志里面,有我们感兴趣的这些拉取代码的日志,就需要对这些日志进行解析,而且解析内容至少要包含相应的拉取代码的仓库、地址、账号。如果是ssh,你要把IP地址相应的网段信息富化进去,这是解析的需求。现在我们可以做一个最简单的Use Case,源网段的设备异常拉取相关业务仓库的行为。翻译一下,比如说我是a部门的,这个部门是在网络里边有相应的安全域划分的,这个部门可能有1、2、3三个仓库,另外一个b部门可能有4、5、6三个仓库,那么a部门的拉1、2、3的这一部分的情况我们认为是正常的,但是a要拉到4、5、6这个我认为是异常的,我们可以去做一个相应的监控,基于这个日志,包括我们富化的这个信息,基本上可以实现这个要求。
我们还有一个理想的状态就是希望知道你在仓库拉了多少行代码。但实际上我们在CE版 Gitlab几个日志里并没有看到类似的记录,目前我们还没有找到在CE版里面特别好的方法,这部分的需求目前只能搁置,看以后有没有其他更好的方法,所以对这个需求我们需要去做分析,不一定是马上就实现了。

我们刚才做了第一版的需求之后就会产生第二个需求,即便是本部门的拉了一些代码,我不知道他拉了多少行,但我知道他拉了哪些。假如说他是一个离职人员,那就需要知道他在离职期间、离职之前拉过多少代码,我们需要去审核他是不是应该干这件事情,是不是在离职之前做了一些资料收集的情况。
我们怎么能知道这些人是不是离职呢?Gitlab本身的日志是不可能知道的,所以我们就只能从人力资源的系统去获取这个人员的离职状态,就要求我们再去拉人力资源系统里的相应信息,这部分的需求并不需要实时告警,因为我们很可能是需要去拿他离职前一个时段的数据,我们需要出具一些报表,有两种情况,一种是按需,可以给各个部门相应的领导发周报和月报,你们部门的人大概都拉取过哪些代码,因为他们本身对本部门人员该访问哪些会比我们更清楚。这样的话我们就需要有一个报表,这个报表是相对长期的,比如说是半年一年以上的报表,它是按需的方式或者是定时的方式要出具,这是2.0的需求。

下面我举一个例子,这是一个product.json日志,就是刚才说的Gitlab里面有很多类,我随便挑了一个product.json的日志,这是原始日志的报文,它是json的格式,可以看到它的动作、时间、访问的项目、拉了库、从哪个地址来、用了哪个账号、它的UA是什么。刚才说了我们要为度量做富化,首先我们要做一个简单的度量,就是原始日志要保证它收没收到、时间对不对,首先会富化两个时间。
第一个时间就是timestamp这是日志本身的时间,还有一个timegenerated的时间,实际上是集群syslog收到这个日志的时间。由于集群是由我控制的,相当于是我们整个日志平台的组成部分,可以保证机器都是可以做时间同步的,这样就有两个时间信息了,比对本身日志源的时间跟接收的时间,有没有过大的差异,是不是在可接收的范围内。
第二Syslog本身的报文协议在包头里是包含了发送者IP的,那报文内容实际上是hostname,但是hostname对于我们做分析的时候会不太敏感,尤其是在很多企业里很难保证它的hostname命名是规范的,很多情况下localhost结果很难去分析,这样的话我们就要富化,从syslog的报文的包头里面把它的源地址富化进去。此外还要加上比如集群节点名称,因为syslog集群有很多,有时候要去排查,假设出现故障,要去排查本身接收这个节点有没有问题,我们把这个节点的信息富化进去。同时发送这个日志,比如说这是一个文本类型的日志,那我们就要知道这个是哪种类型的文本的日志。比如说我们这是Gitlab的product.json,我就知道是product.json类型的日志,那么我会给它打开一个tag,因为rsyslog有很多的输入模块,富化通过那个模块输入的,或者说从哪种方式接收到的,然后再加一个message把这个相应的原始报文打包进去,形成一个json的报文,就可以把它放在后台的初级ES集群里。这部分日志实际上就可以做两部分工作,一是全文检索,二可以做相应的度量,日志量本身是多少,时间有没有差异,这个IP有没有按时给我发日志,这部分就是做了日志源度量的工作。

下一步就是刚才我们说的Use Case,接收到的原始日志要去做解析。解析实质上是两部分工作,第一就是做字段的映射,按照一个固定的schema,把它对应的映射到我们相应的表中,或者说我们后台的字段里去。第二刚才说了日志里面有IP,实际上后台需求是要做的就是判断这个I属于哪个网段,后续好去做Use case。我们需要从cmdb里面去拉取这个网段和这个IP的网段的映射信息,我们会从总工办获取,比如说各个仓库的列表、以及这些仓库和部门的映射列表,这样我们就能得到相对静态化的两个信息。
富化的数据是富化到日志里,静态的数据是参与到关联分析里,这样通过关联分析去检查,这个网段的这个账号访问了哪个仓库,这个仓库和它的部门是不是相匹配,这样就可以去满足刚才我们1.0的Use Case的需求。

刚才说到的2.0需求是做报表,报表这部分我们直接消费格式化的日志,报表肯定就关心这些账号从哪一个地址,对某个仓库做了什么动作,就需要这几个字段,从数据集里将这些字段抽取出来,这部分的数据的量会减少很多,这部分的内容放到另一个数据库里,按时按需定时产生一些汇总报表,就能满足2.0的需求。
五、现状
(一)日志处理架构
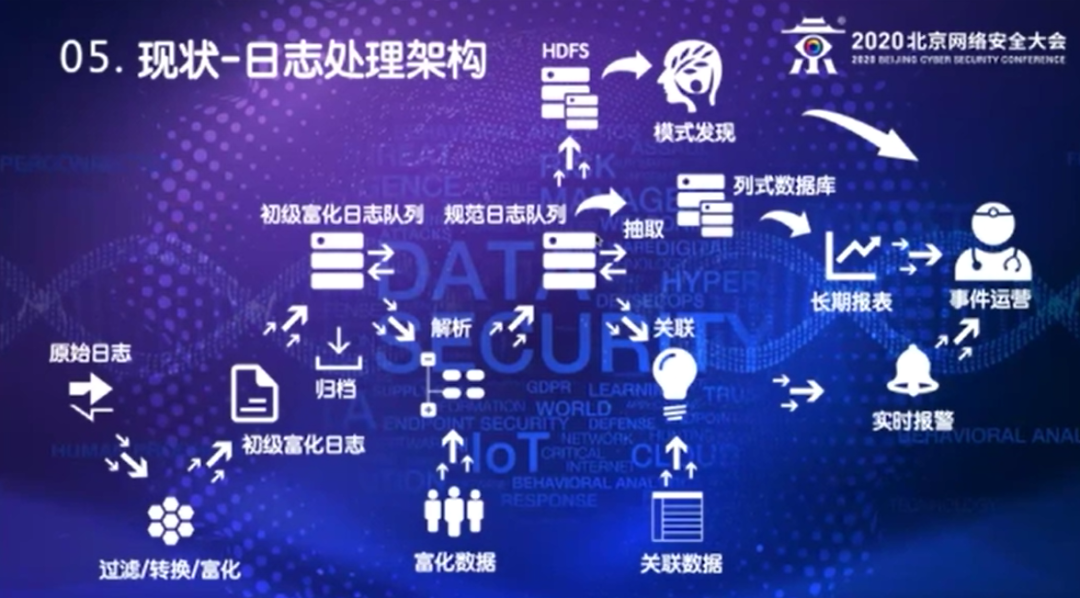
下面按日志处理的过程来介绍架构。首先原始日志,通过配置及采集的客户端发到采集集群里面,通过过滤、转换和富化能产生初级的富化日志,把它打到初级富化的日志队列里面,就是初级的Kafka Topic中,这部分日志做压缩归档,主要是为了满足合规性的要求,例如等保要求某些日志要满足一年存留的要求。解析器会消费初级富化的日志队列,产生规范化的日志,规范化的日志解析的时候会加入富化信息,规范化日志会打到规范化的队列中,关联引擎会消费规范化日志队列,结合一些关联的数据,产生实时的告警。实时的告警会发送到后台的事件运营平台,有相应的运营团队后续的做运营,他们会给我们反馈、做修正。
规范化的日志队列也可以通过ETL手段抽取部分字段,放到一个历史数据库比如我们现在用的clickhouse,由它来负责提供数据做长期的报表。我们其他同事可能会在研究模式发现,或者叫机器学习也好,人工智能也好,各种说法。就是我们之前做的这些关联规则,实际上更多做的是一些已知威胁检测,对于未知威胁更多是通过一种行为方式做检查,它需要的时间比较长,不是实时处理的,也是基于未知的一种模式,也是消费规范化的日志队列,通过大数据平台的架构,再去做处理,架构大概是这样。

我们现在这个平台,原始日志的采集能力大概是12万左右,现在取样的24小时大概是在13万左右,关联日志的处理是2万左右,实际上最高的时候跑到过4万5左右。之所以把这两个区分开是由于有很多的日志不需要做实时关联分析,有些只是记录性的信息,它只是满足合规要求的,现在的存储量大概在1.2PB 左右。
日志的解析类型我们是分为几层,比如从网络设施层,公司主要用的国内的网络设备,包括公司自己的sd-wan,基础设施基本上是一些虚拟化的平台,还有TACACS认证,IPA、DNS和微软dhcp的基础设施。操作系统上基本是Linux操作系统日志和Auditd还有Windows的Eventlog和sysmon日志。安全设备比较多,主要采集的是我们公司自己的安全设备和一些开源的安全产品。基础应用类,Web类的,Apache Access、nginx Access、IIS;应用类,比如jira、Jenkins,和exchange通讯协议和跟踪日志,应用日志,就是crm的导出日志,工单系统,蓝信的搜索日志,这些日志基本上都做了解析。
关联分析规则截止目前已运营的是178个,试运营的是218个。刚才介绍过不是所有的规则做完以后就会马上运营的,需要循环迭代几次之后才会变成一个已运营的状态。未启用的内容是针对某些特定的场景,临时开启的规则。通知方式,一个是通过邮件的方式传送,二是通过公司的蓝信发送通知,最重要的是会传送到后台,就是一个事件处理平台去做后续的闭环处理。
今天介绍大概就是这些,需要交流的可以入职来找我(^-^)。
声明:本文来自君哥的体历,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
