摘要
随着欧盟GDPR、美国CCPA,以及我国《网络安全法》等法规的实施与监管,隐私合规与数据安全治理成为企业当前亟需解决的一大安全任务。具体来说,企业通过技术与管理措施,如何在不影响或少影响原有业务流程的同时去满足合规性?其中,数据匿名化作为一种重要的技术手段,在满足数据统计分析的同时可有效地降低个体隐私泄露风险。且有趣的是,近年来研究发现它具有天然的合规遵循优势。GDPR等法规对赋予用户更多的隐私数据控制权,反过来削减企业的数据控制权与主动权。那么,匿名化技术是否可以帮助企业重新打开数据主动权和控制权这个局面?带着这个疑问,本文将从合规背景、技术算法以及应用与产品三个方面对该技术进行介绍。
一、安全合规背景
欧盟GDPR、美国CCPA赋予了用户非常多的数据权利,例如,GDPR规定用户可对个人数据提出限制处理以及删除的请求;CCPA规定用户有权要求企业不得出售其个人数据。我国《网络安全法》等法规也赋予了一定权利,例如用户发现企业违反规定或错误有权要求企业删除或更正个人信息。
反过来,这些法规对企业提出更高的隐私和安全要求,在一定程度上削弱了企业以往普遍存在的数据掌控能力与权利优势。无疑,这给企业100%的数据掌控权关上了大门,但法规在平衡个体隐私与数据发展的原则指导下,关上一扇门,同时也打开一扇窗——企业可以通过数据匿名化在一些典型数据场景下重新打开数据主动权与控制权。
GDPR:对于个人数据、以及假名化等数据,GDPR对相关处理和存储的企业提出十分严厉且全面的法律义务,需要企业履行相关义务。而唯独对于经过处理的匿名数据网开一面——该数据企业可用于统计和研究目的,不受GDPR的约束与限制,即对履行用户各类数据控制权请求等条款具有豁免权。(GDPR前言26段)
《网络安全法》:“匿名”数据(“经过处理无法识别特定个人且不能复原”),企业无需征求被收集者同意,可直接与第三方进行数据共享。(四十二条)
《个人信息安全规范》:个人信息经匿名化处理后所得的信息不属于个人信息(3.14节);在个人信息主体注销账户场景中,处理注销账户的个人信息有两种方式:①选择直接删除数据;②存储匿名化处理后的数据。(8.5节)
由此可看出,匿名化有重要的合规遵循的应用价值,尤其是在数据统计、研究以及数据开放与共享场景中;同时实施该技术措施给企业带来其他方面的好处。即:
合规遵循。匿名数据在向第三方提供、统计分析和注销账户保存匿名数据等场景中是合规的;
数据共享价值。在数据共享场景中,尤其数据敏感且价值密度高的行业,比如医疗,金融等行业,实施数据匿名技术后,可合法合规(光明正大)地进行数据共享与价值挖掘;
增强用户信任。匿名数据,数据是匿名的,即任何人无法识别和关联匿名数据记录的身份。那么用户不担心该数据公开和处理过程中泄露本人隐私;
降低隐私风险。匿名数据在流动和处理过程中,“数据部分可见但身份不可见”,从而有效地降低个体隐私泄露的风险。也就是说,即使匿名数据库遭受黑客攻击外泄,攻击者也无法破解或还原出匿名数据记录所涉及的用户身份信息。
那么什么是匿名化呢?《个人信息安全规范》给出详细的定义:“通过对个人信息的技术处理,使得个人信息主体无法被识别或者关联,且处理后的信息不能被复原的过程”。即匿名化通过数据变换与失真,处理结果可保持一定的可用性,但任何手段无法识别特定个人,且数据不可逆(非“一一映射”(例如加密、置换手段))。
数据脱敏(包括去标识化)作为目前企业广泛实施的数据安全技术,可以看成是“数据匿名化”的相近技术,它对数据进行一系列的数据变换和失真,但无法保证每次处理的结果是真正“匿名”的,即是否达到“无法识别特定个人且不能复原”。若需评估该技术的效果——是否满足法规定义的匿名化门槛,可参考系列文章《数据脱敏后的隐私攻击与风险评估》、《身份证号+手机号如何脱敏才有效?》。如何真正实现和逼近法规的“匿名化”?幸运的是,在学术界中能找到具有广泛和深入研究以K-匿名为代表的数据匿名技术(也称匿名化技术),它可以达到法规要求的匿名化效果。本文下面将对该技术原理、算法,以及现有工业界应用进行介绍,以期进一步促进数据匿名技术在企业场景的研究与应用。
二、数据匿名技术与算法
2.1概述
早期,个人数据发布的隐私保护场景中,对标识符或准标识符进行简单处理,比如删除、或者使用随机ID替换姓名、用户昵称,对地址信息和出生日期进行泛化处理,这种方式可看成前面提到的“数据脱敏”。然而随着一些攻击案例和研究发现,这种处理方法的“匿名”处理是不充分的,仍然存在个体隐私泄露的风险。验证这一观点,有多个著名的实际案例:
案例1: 1996年美国麻省发布了医疗患者信息数据库(DB1),去掉患者的姓名和地址信息,仅保留患者的{ZIP, Birthday, Sex, Diagnosis,…}信息。另外有另一个可获得的数据库(DB2),是州选民的登记表,包括选民的{ZIP, Birthday, Sex, Name, Address,…}详细个人信息。攻击者将这两个数据库的同属性段{ ZIP, Birthday, Sex}进行关联操作,可以恢复出大部分选民的医疗健康信息,从而一起严重的医疗隐私数据泄露事故。
案例2:AOL公司公布了2006年3个月用户的真实搜索日志,包括1900万搜索记录,为保护隐私对用户ID进行处理,使用随机ID代替真实ID。然而纽约时报记者发现,根据一系列历史搜索行为和包含的相关信息进行推断,可以确定编号4417749的身份——一位62岁的老太太,家里养了三条狗,患有某种疾病。后经过老太太本人证实确实是她搜索的关键词。记者曝光该事件后,引起美国公民对AOL公司隐私保护措施的诸多顾虑,并导致AOL首席技术官引咎辞职。
以上均属于链接攻击(也称重标识攻击、去匿名攻击)范畴,即攻击者通过各种渠道获得公民/用户的身份信息和其他用户的静态属性信息(学术称为“准标识符”属性,比如性别,出生年月、邮编等),包括访问查询公开身份数据集、了解亲朋好友的基本信息、互联网“人肉搜索”陌生人,甚至利用数据泄露、黑灰产数据库等对脱敏数据集进行关联、相似匹配与碰撞,进而还原出上述脱敏数据集的某些记录的身份信息。
为了应对潜在的隐私攻击问题与挑战,学术界开始聚焦和设计隐私保护效果更好的匿名化技术与模型。一般地,用户希望攻击者无法从存在多个个体记录的数据集中识别出自身,以及对应的敏感隐私数据,数据匿名技术便是这种朴素思想的实现之一。Samarati和Sweeney学者在1998年首次提出了匿名化的概念,对个人一些基本信息进行泛化和失真处理,隐藏公开数据记录与特定个人之间的对应联系,从而保护个体的隐私。后面,Sweeney学者在2002年提出了K-匿名模型(K-Anonymity),该模型保证数据记录的任意等价组至少有K个个体记录,即攻击者无法唯一地确定个体的记录准确身份。如下图所示,它对原始数据进行2-匿名处理,包括对Birth(出生日期)进行泛化、对邮编(ZIP)进行屏蔽处理等操作,最后输出的数据集除敏感属性(Disease)外,其他属性(也称准标识符属性)组成的记录形成等价组,每个等价组至少有两条记录,如索引 (1,2)有2条记录、(2,3)有2条记录、(4,5)有2条记录、(5,6)有2条记录、(7,9)有3条记录,(10,11)有2条记录。在攻击场景中,假设攻击者拥有背景知识,了解Jack在该数据集中且掌握了他的基本属性:Race:Black; Birth:1965-09-01;Gender: male;ZIP:02146。攻击者想识别Jack具体属于数据集的那一条记录?经过相似匹配和关联,定位到索引1和索引2,但不能唯一确定那个属于Jack,那么也无法确定Jack患上了那种疾病。也可以说,无法确定索引1和索引2对应的真实身份,从而保护患者的个体隐私。
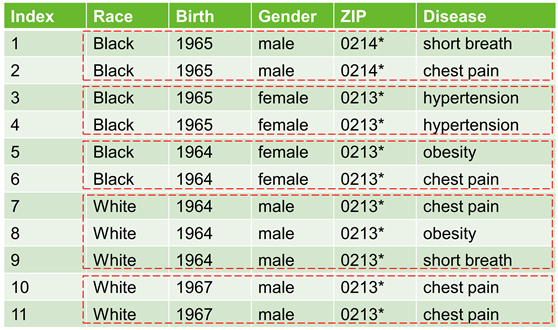
图1 经过2-匿名处理的医疗数据
数据发布场景的隐私保护(PrivacyPreserving Data Publishing, PPDP)是K-匿名最早的应用,也是研究最为广泛的场景,除此以外将K-匿名为代表的数据匿名技术应用在位置服务和社交网络等领域成为近年来新的一个热点。基于匿名化的PPDP场景可看作为一个通信模型,如图2所示,主要由三方参与:数据控制者/发布者(Data Controller/Publisher),可看作发送者;数据接收者(DataRecipients);隐私攻击者(Attacker)。数据控制者/发布者收集个体(Individuals) 的个人信息,将这些数据通过匿名化处理(Data Anonymization) 后得到匿名化数据集,发送给第三方共享或者对外公开。攻击者尝试通过掌握的背景知识和数据库进行攻击,获取具体某个个体的隐私信息。典型一种攻击方式是链接攻击,即去除准标识符信息 (Identifier,ID,如姓名,身份ID),攻击者通过其他渠道掌握的数据库的同属性段(称为准标识符,Quasi-Identifier,QID)与公开数据库进行链接和匹配操作,恢复出具体个体敏感信息(Sensitiveattribute, SA,如健康、薪资、位置等)。
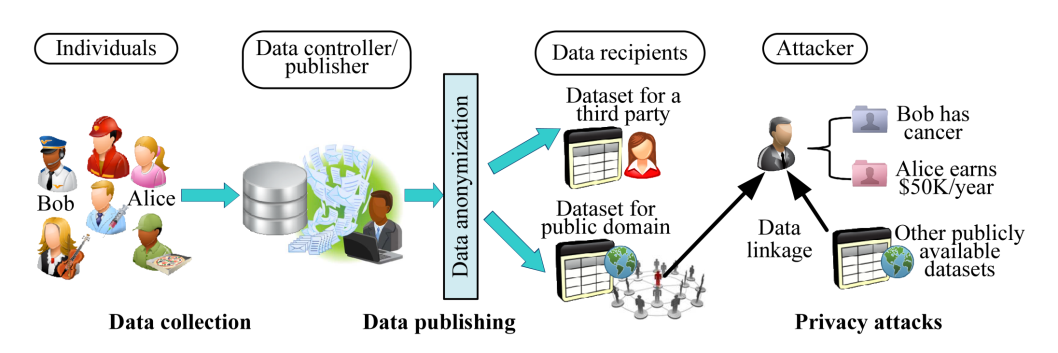
图2数据匿名化的一般应用场景
2.2模型与算法
数据匿名技术的研究主要集中在模型、算法、匿名处理操作和评估指标四个研究方面。
2.2.1匿名模型
前面提到的 K-anonymity由于敏感属性进行约束,当等价组的敏感属性取值相同时,仍然存在隐私风险,Machanvajjhala等人提出了L-diversity模型,在每一个等价组中,至少存在L个不同的敏感属性,相比K-anonymity增强了安全性。 Li等人在L-diversity基础上,考虑敏感属性分布,设计了T-closeness模型,通过保证任意等价组的敏感属性的分布与敏感属性的全局分布之间的距离小于T,进一步增强了安全性,然而约束条件越来越多,降低数据的可用性。除以上模型外,还出发展和衍生出了-anonymity和个性化隐私保护 (Personalized privacy preservation)的模型等。
2.2.2匿名化算法
匿名化算法以最小的数据缺损代价实现满足模型的约束。然而研究表明,实现最优的匿名化是一个NP难题。幸运的是,目前已经发展许多有效的近似算法,典型的算法包括Datafly算法,Mondrian算法。前者是单维度泛化算法,其核心思想是对给定数据表中QID的属性中取值最多的那个属性按预先给定的泛化树进行泛化,直到匿名化数据表满足K-anonymity;后者是多维度泛化算法,其核心思想是将所有QID属性看成是一样的,即只有一个等价组,然后自上而下,启发式选择QID的某个属性逐次划分,直到满足条件无法划分。除以上算法外,由于聚类算法思想与匿名化等价类划分思想十分相近,因此一些学者提出基于聚类的匿名化算法。
2.2.3匿名处理操作
主要包括数泛化、抑制、置换等操作。其中泛化最为广泛应用,泛化是指用模糊/抽象/概括的值代替精确值,使得多个数据是相同的。例如年龄26,29被泛化为“25-30”,地址朝阳区、海淀区被泛化为北京市,那么攻击者无法精确地获得数据主体精确信息;抑制操作一般将数据使用“*”代替,隐藏和遮蔽数据值,使得攻击者无法获得该部分的信息;置换是对数据表中的属性值进行位置打乱操作,使得数据主体与该属性信息不对应,一般用于SA属性的处理中。
2.2.4评估指标
主要分为两个方面的评价,数据可用性 (Data Utility)与隐私保护性(Privacy Protection)。在文献研究中,前者指标较为丰富,可对,包括匿名化的NCP (Normalized Certainty Penalty),CM (Classification Metric)和DM (Discemibility Metric)。后者研究文献,一般默认使用模型的参数进行评判,例如K-anonymity、L-diversity,参数K和L越大,分别对应的重识别和隐私泄露风险越小。近年来,一些学者基于通信模型和Shannon信息论对,对隐私泄露问题进行数学建模与分析,提供了理论的度量方法。
三、数据匿名技术的应用
数据匿名技术随着发展逐步趋向成熟,一些高校和研究机构基于软件功能实现开源数据匿名化项目与工具,一些面向隐私合规的欧美科技公司对该技术进行产品化和应用。
3.1开源项目
基于数据匿名技术的工具化实现主要集中在欧美高校和研究结构,有4个著名的开源项目:ARX、UTD Anonymization Toolbox、Cornell Anonymization Toolkit焕然Amnesia。从成熟度看,ARX最为成熟,提供丰富的界面和API接口,以及在微软匿名化,提供完整的数据可用性、重标识风险评估等功能组件。
表1数据匿名的相关开源项目
ARX | UTD Anonymization Toolbox | Cornell Anonymization Toolkit | Amnesia | |
开发者机构 | 慕尼黑工业大学 ·德国 | 得克萨斯大学达拉斯分校·美国 | 康乃尔大学·美国 | 信息系统管理研究所(IMSI)·希腊 |
开发语言 | Java | Java | C++ | Java |
项目主页/github | https://arx.deidentifier.org https://github.com/arx-deidentifier/arx | http://cs.utdallas.edu/dspl/cgi-bin/toolbox | https://github.com/wanghaisheng/Cornell-Anonymization-Toolkit | https://amnesia.openaire.eu https://github.com/dTsitsigkos/Amnesia |
项目成熟度 | 实验研究,半产品 | 实验研究 | 实验研究 | 实验研究,接近半产品 |
支持的匿名模型 | K-匿名、L-多样和T-近似 | K-匿名、L-多样和T-近似 | L-多样 | K-匿名、-匿名 |
支持的匿名算法 | Flash | Datafly、Mondrian、Incognito | Incognito | Flash、基于聚类算法 |
特点 | 提供丰富的数据可用性、风险评估等功能 | 提供多种匿名算法实现 | 可简单进行数据可用性、风险评估的计算 | 支持在线https://amnesia. openaire. eu/amnesia |
3.2企业产品应用
GDPR、CCPA的隐私合规驱动,一些欧美企业,包括Google,以及主打隐私合规产品的创业公司,率先将数据匿名技术进行了孵化与产品应用。
Google 的云DLP产品
Google浏览器的隐私声明中,承诺对用户数据使用K-匿名、L-多样数据匿名化以及差分隐私等技术进行处理。随着用户隐私与敏感数据上云,隐私和数据泄露问题引起云使用者的担忧,谷歌将匿名化技术嵌入DLP产品中,可以解决隐私风险问题。DLP产品实现四种匿名化模型与算法,包括K-匿名、L-多样、K-图和-存在性,用户可以根据隐私保护和数据统计分析的需求选择合适的模型算法。在匿名处理数据前,云DLP谷歌提供了原始数据的风险洞察功能:如图3所示,使用者可以看到在K-匿名的不同K值下,不满足的记录数比例(蓝色)。
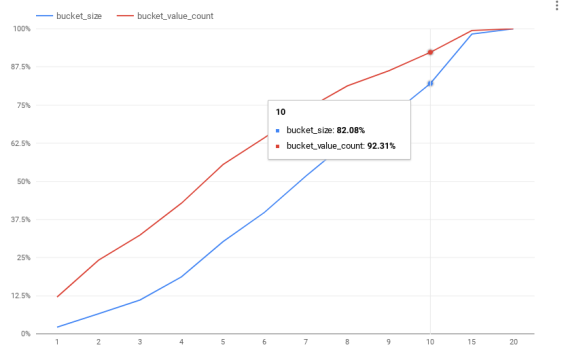
图3 Google云DLP产品的风险洞察功能
Immuta的数据治理平台产品
Immuta是一家美国初创企业,目前处于C轮融资(融资总额6820万美元)。Immuta在云云生数据治理平台 (cloud-nativedata governance platform)应用到了K-匿名技术,K-匿名可应用在静态数据和动态数据中,后者可能采用类似m –invariance的匿名算法,即保持动态增量的数据仍然满足等价组数量至少为K个,该技术的应用可增强云存储与计算的隐私安全。
图4Immuta的数据治理平台
Privitar的数据脱敏产品
Privitar是一家成立于2014年总部位于英国伦敦的创业公司,目前处于C轮融资(融资总额15050万美元),主打推出一系列的隐私产品,包括大规模数据隐私治理的自动化、隐私政策管理、数字水印平台以及数据脱敏产品(公司称为De-Identification产品,实际功能与国内的Data masking功能基本相同)。在数据脱敏系统中,除了使用传统的基于泛化、替换、屏蔽和加密等脱敏策略外;其数据脱敏嵌入了K-匿名算法,它相比传统脱敏的策略在隐私保护上更强优势,攻击者即使获得经过K-匿名的脱敏数据,也无法通过其他渠道获得的身份信息或数据库进行关联推断,还原脱敏记录的真实身份,进而有效保证隐私前提下实现脱敏数据的提取与利用。
Anonos的BigPrivacy产品
Anonos是一家美国初创企业,目前融资总额1200万美元。其公司主要推出了BigPrivacy产品,同样可以看成一个脱敏平台,其假名化和身份与业务数据分离,这些功能可满足GDPR具体条款的一些合规性。在该平台中,Anonos也应用了K-匿名技术与算法,在保证数据在业务场景的可用性时,可保证K-匿名处理后的数据不被重标识与身份识别。
四、小结
全球的数据安全隐私法规的立法,一方面赋予了公民与互联网用户的数据控制权利;另一方面对数据处理的企业提出了更高的隐私与安全要求。企业一方面可以通过访问控制和网络安全防护等措施降低数据收集、存储和处理等阶段的隐私泄露风险,另一方面在日益增多的数据共享与计算场景实施数据匿名化是不错的选择——不仅满足业务利用与隐私保护,同时遵循了合规性。
参考资料
1.Samarati P,Sweeney L. Generalizing data to provide anonymity when disclosing information(abstract). symposium on principles of database systems, 1998.
2.Sweeney L.K-anonymity: A model for protecting privacy. International Journal ofUncertainty, Fuzziness and Knowledge-based Systems, 2002,10(5):557-570
3. L-diversity:Pri-vacybeyondk-anonymity. Machanavajjhala A,Gehrke J,Kifer D,et al. Proceedings of the22th International Conference on Data Engineering . 2006
4. Li N H, Li T C,Venkatasubramanian S. T-Closeness-privacy beyond K-anonymity and L-diversity.IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, April15-20, 2007: 106-115.
5. Dwork C.Differential privacy. Encyclopedia of Cryptography and Security, 2011: 338-340.
6.Rocher L, HendrickxJ M, De Montjoye Y A. Estimating the success of re-identifications inincomplete datasets using generative models. Nature communications, 2019, 10(1): 1-9.
7. El Emam K.Guide to the de-identification of personal health information. Auerbach Publications,2013.
8.Meyerson, Adam,and Ryan Williams. "On the complexity of optimal k-anonymity",Proceedings of the twenty-third symposium on Principles of database systems.ACM, 2004.
9. LeFevre, K., D.J. DeWitt, and R. Ramakrishnan. "Mondrian Multidimensional K-Anonymity"22nd International Conference on Data Engineering (ICDE"06). IEEE, 2006.
10.Aggarwal, CharuC, "On k-anonymity and the curse of dimensionality", Proceedings ofthe 31st international conference on Very large data bases. VLDB Endowment,2005.
11.Zakerzadeh H,Aggarwal C C, Barker K, "Towards breaking the curse of dimensionality forhigh-dimensional privacy", Proceedings of the 2014 SIAM InternationalConference on Data Mining, 2014: 731-739.
12.Terrovitis,Manolis, Nikos Mamoulis, and Panos Kalnis, "Privacy-preservinganonymization of set-valued data", Proceedings of the VLDB Endowment 1.1(2008): 115-125.
声明:本文来自绿盟科技研究通讯,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
