文/康凯 赵志岩 范英 施一琳 宰旭昕
摘要:随着各行各业对高效的身份认证的迫切需求,人脸识别研究在近几年取得了显著的进步。然而不受控场景下的人脸识别仍然是计算机视觉领域的热点问题,有许多问题亟待解决。尤其是在人证比对的双样本人脸比对应用场景中,人脸识别研究仍面临巨大挑战。本文首先对大规模人脸识别的研究背景和意义进行了简单介绍;然后基于大规模双样本人脸识别算法,提出了一个高效的大规模人证比对训练框架;其次介绍了用到的大规模分类的关键技术;最后对文章进行了总结。
关键字:人脸识别 深度学习 大规模 双样本
1 引言
人脸识别研究在近几年取得了显著的进步,主要得益于网络架构的革新和数据量的爆发。然而不受控场景下的人脸识别仍然是计算机视觉领域的热点问题,作为高效的身份认证手段,仍有许多问题亟待解决。在人证比对的应用场景中,有大量的数据包含了每个人的两张图像。其一是在数据库中可查询的身份证等照片,其二是在应用场景的现场照。当前这种应用类型仍为人脸识别研究带来巨大的挑战。
其挑战主要有三方面:一是“大规模”:当前海量的人证对比照片为如何在有限的GPU资源上进行深度训练带来了挑战;二是“双样本数据”:一般情况下,现场人像照是通过人脸认证系统采集的。当使用者通过人脸认证系统时,他的一对照片会被记录下来,其一是证件照,其二就是在线拍摄的现场照,也就是对于每一个类别,只有两个可用样本。类内变化无法很好表达,难以进行有类间辨别力的训练;三是“异质性”:ID照片是在有约束环境中拍摄的,而现场照片是无约束的,受到光照、姿态、背景等影响。另一方面,证件照和现场照可能会有很大年龄差,因为证件照每10-20年才更新一次,异质性为人证对比的人脸识别问题带来了更大的困难。
上面的三个特征为人证对比情景下的人脸识别问题带来很大挑战。在现实应用场景中,需要在低误识率下有很高的识别准确率。为了达到这个目的,需要特征空间中较大的类间距离,以及类内样本的紧实性。但是由于每一类只有两个样本,在训练过程中很难描述类内变化,获得的特征空间很难有区分度。除此之外,由于类别数的庞大,在有限的GPU设备上,很难在大规模样本上探索有区分性的信息。比如深度学习中的softmax,数以百万的模板量级,对于绝大多数的计算资源而言,GPU存储空间都是不够用的。
本文试图借鉴文献中的各种方法,对基于深度学习的大规模双样本人脸识别算法进行复现。并在此基础上,提出一个高效的大规模人证比对训练框架,该框架能够针对大规模的人脸识别进行增量训练,并对双样本数据保持高精度。在高效性、精度、可拓展性上达到目前最优标准,甚至超越。
2 大规模双样本人脸识别训练框架
针对大规模双样本人脸识别任务,目前的基于深度学习的研究主要集中在两方面,其一是通过不充足数据的学习(双样本甚至单样本),其二是大规模分类的学习。
目前主流的人脸识别框架有两种,分类和验证。分类框架将每个人作为一个单独的类别并将样本逐个分类到其中一个类别中。而测试时,将最后一个分类层去除,最后一层的特征就可以看作是人脸的表征。其中使用最广泛的损失函数是softmax[1]函数,基于softmax函数,人们提出了各种改良版本,如large-margin softmax[2],A-softmax[3],AM-softmax[4]等等,通过分类的整体训练,这个框架可以将一类样本和其它样本区分开,可以很快收敛,并具有不错的泛化能力。
验证框架则是专注优化样本之间的距离。在一个mini-batch中,contrastive 损失函数[1]优化了特征空间中样本对之间的距离,在增大类间距离的同时减小的类内距离。而triplet损失函数[5]则在每一个batch中构筑样本三元组,通过设定一个距离阈值来增大三元组中负样本对距离,减小正样本对距离。在此基础上,N-pair loss[6]在优化每一个正样本对距离时,根据局部softmax的策略,同时推远了所有相关负样本对的距离。困难负样本挖掘(hard negative mining[7])也是一个广泛采用的训练方法,它通过移除简单负样对来确保训练过程能够快速收敛。
2.1 大规模人脸识别数据及预处理
在人脸识别数据集中,Ms-Celeb-1M[8]是当前最大的无约束场景人脸数据集之一,包含98685个人物和超过1000万张图。本论文中使用的是包含84165个人物的350万张图。这些数据都是经过人脸对齐过的。
除了MS-Celeb-1M数据集的评测指标,常用的人脸识别评价指标还有误识率(FAR),代表了把非匹配样本当成匹配的样本的比例。

ROC(receiver operating characteristic),曲线上每个点反映了对同一刺激信号的感受性。ROC曲线的横轴表示假正率(FPR),代表假正样本占所有负样本的比例,而纵轴代表真正率(TPR),即分类器判断的正类中实际正样本占所有正样本的比例。
人证数据集是项目采集,专用于人证比对人脸识别的。其中每个人有两张图,其中一张是身份证上面的证件照,拥有统一的拍摄背景和适当的光照条件,人物呈正面姿态,且表情正常。另外一张是在现场设备上拍摄的现场照片,姿态、表情、遮挡和光线等等变化很大。
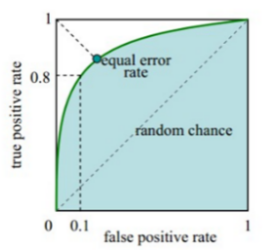
图 1 ROC曲线
对于采集来的原始数据,本文中利用MTCNN人脸检测和关键点定位方法,通过标定五个关键点(包括两只眼睛,鼻尖和两个嘴角),用仿射变换进行人脸对齐。所有的人脸都经过相似变换进行归一化处理,并裁剪成120×120的RGB三通道彩图。
由于现场采集来的原始图片存在人脸模糊和遮挡的现象,在预处理中通过设定信息熵的阈值的方法来去除明显模糊图像,并通过设定检测模型置信度阈值来滤除明显遮挡的图像。
2.2 大规模双样本学习框架
2.2.1 人证匹配任务简介
人证匹配任务,是对现场照与证件照中的人脸分别进行特征提取,再利用度量函数进行相似度计算与匹配。在一般的人脸识别训练中,训练集常用的是公开的人脸数据集,在数据集中每一个人,具有多张状况较佳的训练样本。但是在人证对比任务中,每个人只有两个样本,样本非常不充分。当训练样本与测试样本分布不同时,样本的性能会急剧下降。在人脸识别领域,训练数据与测试数据分布不同是一个常见的问题。为了解决这个问题,我们可以模仿人类的学习方式,将从训练数据上学习的知识通过一定的手段迁移到测试数据上。在Pan 和Yang等人的工作[9]中,在Pan 和Yang的工作中对迁移学习进行了比较权威的定义。迁移学习的提出旨在解决不同场景下领域之间存在数据分布不同的问题。在工作[10]中,Kan等人通过在Mongolian人数据集上训练一个人脸识别模型来识别Caucasian人时,识别准确率只有59%。而在Caucasian人的数据集上训练的模型来识别Caucasian人,模型的准确率却有96%。直接证明了在Mongolian人数据集上训练的人脸识别模型是很难被直接应用到Caucasian人数据集上来做识别。Su[11]等人提出了一种自适应通用学习(Adaptive Generic Learning, AGL)方法,通过线性组合辅助数据集中每个人的类内散度矩阵来估计Gallery中每个人的类内散度矩阵。Kan[12]等人,提出了自适应判别分析(Adaptive Discriminant Analysis, ADA)用来估计Gallery中每个人的类内散度矩阵。Hu等人提出了一种新的判别迁移学习(Discriminative Transfer Learning, DTL)[13]方法。在工作[10]中,Kan等人提出目标化源域(Targetize the Source Domain,TSD)的方法并将其应用于单样本人脸识别。在工作[14]中Yi,提出了一种通过公共子空间的桥接方式来目标化多个源域(Targetize Multi-Source Domain,TMSD)方法。Koch的研究表明[15],当训练样本不充分的时候,采用从相关任务迁移学习的方法比直接在目标域(人证照片集)训练效果更好。受Koch等人的启发,我们可以将带标记且每个人有多个样本的数据集作为源域,而人证数据集作为目标域,采用分类-验证-分类(CVC)的训练策略[10],将从源域场景中学到的知识迁移到人证场景中,从而提高大规模分类的表现。
CVC框架包含以下三个阶段:
分类阶段,即预训练阶段,在学术集上训练深度模型,来取得一个对一般人脸识别比较好的初始化。由于学术集类别一般不超过10万类,所以可以采取softmax形式的损失函数来进行优化。虽然在学术集上训练好了模型,但由于模型比较大的偏移,在人证场景中表现不是很好,但是这个初始化模型学到了关于人脸的基本知识。
下一阶段就是利用验证框架进行迁移学习。由于验证框架在每一个iteration中只需要每类两个样本即可优化类内距离,认为它对于大规模的双样本数据也是鲁棒的。所以采用了验证框架来进行从学术集适定场景到人证对比场景的知识迁移。这一阶段就是在预训练阶段的基础上去掉了分类层,并利用验证损失函数——contrastive损失函数或triplet损失函数,在人证数据上进行微调。由于预训练过程中对模型进行了初始化,加上验证框架对双样本数据的鲁棒性,就可以比较好的优化损失函数,为下一阶段人证数据集上的分类铺垫一个好的初始化。
最后一个阶段是在人证数据集上进行分类。为了更好地提取人证数据集中的人脸特征,一般采用分类框架进行模型训练,框架的倒数第二层的输出即作为人脸的特征表达。这一阶段在上一阶段的基础上,在模型的最后一层加回了分类层,由于分类规模超过了softmax的能力,所以往往采用一些针对性的训练方法。比如Megaface challenge的baseline模型C中,将人证全体数据分为K类,采用轮询的方式进行训练等等。
2.2.2 网络架构
目前学术界在设计高效的损失函数和更深层的网络架构上做了大量的工作,使得在相对小规模的数据集上训练出的模型有更好的性能,提取出的特征能够更有区分度。例如,在LFW测评数据集上的准确率从97%提升到了99.8%。
近两年的人脸验证框架基本是以ResNet[11]为架构实现的,其性能表现也达到了目前最优水平,故本文中人脸特征提取、分类与匹配网络的整体框架就是在深度残差网络(ResNet)的基础上实现的。残差网络容易优化,并且能够通过增加相当的深度来提高准确率。它的提出是为了解决随网络层数增加带来的梯度消失现象,残差单元的设计如图3。
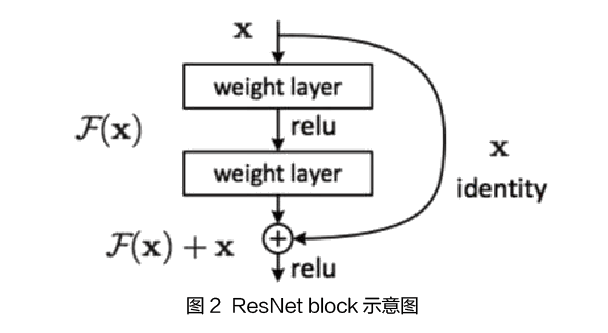
该残差结构通过叠加输入和前向神经网络的结果实现,输入的shortcut连接相当于恒等映射,这样的设计对权重的调整作用更大。本文中采用的是基于ResNet50的图像特征提取框架,在最后通过全连接层得到512维的特征向量。
除此之外,本文在CVC框架的基础上引入了数据迁移的思路,进行了训练框架的改良,变成了多任务联合预训练框架,如下图。
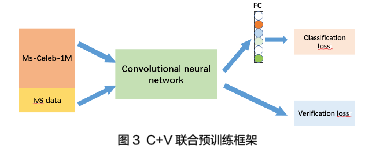
通过设置合适的输入数据比例和损失函数权重比例,可以得到较CVC框架收敛更快的模型,以及可比的精度。
2.2.3 损失函数设计
在CVC框架的三个阶段中,分别采用了不同的损失函数进行训练。第一阶段在学术集上进行分类训练,之前的人脸识别训练表明,一般的softmax损失函数与常见的网络结构搭配,可以达到较优的结果。而本文中采用的是softmax的变式——A-softmax损失函数,A代表angular,其通过控制角余量(angular margin)来尽量拉大不同类之间的距离,在目前的人脸识别训练中能达到最优的效果。
而第二阶段验证框架中则采用了triplet三元组进行优化。
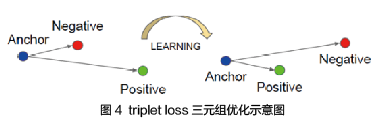
Triplet loss 是在每一个batch中选取三元组,其中包含一个正样本对和一个负样本对,它通过设定一个margin,拉近正样本对之间的距离,同时推远负样本对之间的距离。最终正样本对距离加margin还要小于负样本对之间距离,达到优化类内和类间距离的目的。然而这样的方式较为低效,在此基础上,本文采用了效率更高的N-pairs loss进行每一个batch内三元组的重组。
3针对大规模人脸识别训练的softmax改良
3.1 softmax介绍
Softmax在多分类问题上有着很好的表现,在机器学习和深度学习中有着非常广泛的应用,其函数的定义如下:

其中,i表示类别序号,Vi是softmax的输入,总类别数为M。Si即当前类别判断的相对概率。Softmax输出一个由相对概率组成的向量。若softmax层的输入为M*1的向量,则输出也是M*1的向量,向量中的每一个值表示测试样本属于每个类的概率,大小范围从0到1。
在softmax回归模型下,softmax loss为:
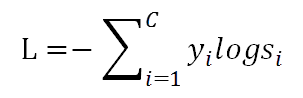
上式中,L代表损失,表示softmax输出向量S的第i个值,即这个样本属于第i个类别的概率。本文中大规模分类的实现即在softmax回归方法实现。
3.2 softmax的改良
在大规模分类框架中,随着分类规模的增长,训练也会变得非常有挑战性。如果直接在大规模的类别上做分类,大量的模板就会占据非常多的显存,而且由于模型参数量的增长,急速增加了训练时间。
本文中采用了DP-softmax算法[10],改良了随机模板挑选的低效性。融合困难样本筛选的思想,在一个batch中放入更多的困难负样本对,可以取得更有区分度的分类效果。经过证明,在每个轮次中,只有一小部分的负模板会产生比较大的梯度[10]。这一部分带有大梯度的负模板就称为“主导模板”,其相对应的模板挑选方法称为DP-softmax。从一个主导的模板序列中来挑选模板,并根据当次softmax的预测结果来更新序列。与随机挑选模板相比,挑选困难样本作为分类模板大大减少了训练过程中使用的模板数,可以使训练性能更优,训练时间更短。
4典型人脸数据库上的评测性能
LFW(Labeled Faces in the Wild)数据集是自然场景人脸识别数据集,通常用来判别人脸识别算法的性能。
用LFW中的数据组成6000对人脸样本对,其中3000对为同一个人的正样本对,另外3000人为非相同人的负样本对。通过判断每个样本对是否为同一个人,来测试人脸验证系统的性能好坏。其中,每600对图像(其中正负样本各半)为一组交叉验证,以10次交叉验证的平均准确率作为最终的准确率。CVC框架在LFW数据集上整体验证准确率达到93.3%,而(C+V)C联合训练框架在LFW数据集上验证准确率达到93.9%。
5结语
本文在CVC训练框架基础上进行了大规模双样本人脸识别训练框架的进一步探索,尝试通过相关多任务联合训练的思路进一步提升识别准确率和训练效率;并尝试简化迁移学习的中间步骤,由“框架迁移”启发,也尝试了“数据迁移”的思路,但在融合各框架的长处、提升人证比对模型的性能方面,还有待进一步探索。
本文着手于大规模双样本数据上的训练方法,在实际人证数据集上取得了满意的结果,但是这种结果的可迁移性或普适性仍有待提升。未来可能要继续增加大规模的双样本数据,一方面是对训练框架的可拓展性进行提升,另一方面是增强模型性能,检验其普适性。
本文为公安部技术研究计划(2019JSYJB03)基金项目成果。
参考文献
声明:本文来自公安部检测中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
