
各位说不定还记得,之前有个导演,模仿奥巴马的声音吐槽了川普,还把自己的嘴完好地贴到了奥巴马脸上。
这样,虽然嘴部有些异样,但不盯着嘴看的话,也不易察觉吐槽视频是合成的。
不过,就算只为了那一小撮火眼金睛的观众,科学家们大概还是要为合成视频的逼真程度赴汤蹈火。

最近,普朗克研究所 (MPI) 一群技艺精湛的研究人员,表示他们是第一个,把替身的3D头部和面部动作整体搬运到目标主角脸上,的团队。
三位一体
在他们的系统里,只要输入一段替身的单人表演视频,和目标主角的一段单人视频,就可以让主角学到头部和面部的所有动作。

视频输入后,算法会用“面部重构 (face reconstruction) ”的方式追踪替身和主角,得到一系列参数,用来表示头部姿势、面部表情和眼球转动等等动作。
这些参数向量可以直接输送到主角的脸上,下一步就是渲染合成的主角图像。
然后重点来了,团队建造了一个拥有时空结构 (space-time architecture)的神经网络,向它输入渲染过的人脸参数模型,它就能“脑补”出目标主角的逼真视频,称为动态肖像 (video portrait) 。
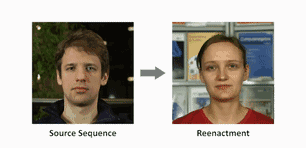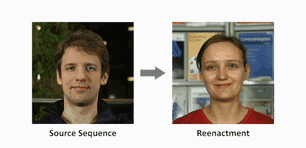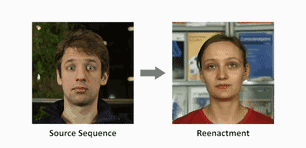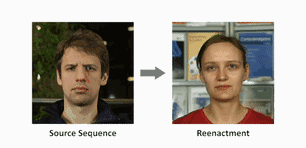
团队说,这样的真实度是靠艰苦的对抗训练来实现的。
成果是,只要有几分钟的主角视频作为训练素材,替身的表演就可以获得高质量的继承。

头发、脖子、肩膀还有目标背景,都会随着生成的头部和面部动作,发生自然的变化。就连背景里的阴影,也能跟着前景走。
想调哪就调哪
另外,如果不想让头部跟着一起动,也可以只改表情。

还有啊,如果不想完全照搬替身的表演,我们还可以手动调节头的朝向,脸上的表情。
任何参数都可以单独调,也可以整体调。

这就是说,没有替身,直接给视频里的主角改动作也没问题。眨眨眼,撇下嘴,都可以。
有对比才有伤害
至于这研究成果到底厉害成什么样,当然还是要和其他人的算法比比看。不然,极客们怎么获得碾压同行的快感?

首先,他们把自家的动态肖像算法和Thies团队的Face2Face做了对比。
二者相比,动态肖像大法的表情更加到位,头部动作更吻合,生成的视频也就一气呵成。
第二个对手是Suwajanakorn团队基于音频的配音法术。

对方的嘴唇同步很优秀,但没有给主角任何表情控制技能,效果便略显僵硬。而己方的面部、头部和眼球搭配食用,更为自然清新。
第三场比赛,是在头部运动的选手之间展开。
Averbunch-Elor团队的算法在动作上和动态肖像相差无几,但背景明显扭曲,翻了修图大计。
对此,普朗克研究所表示,这是因为对方算法是一帧一帧单独学习的,而他们是用整段视频来学姿势。
谦虚地说,还有局限
虽然,现在生成的视频已经很接近真实了,但团队说这个算法还是有自己的局限性。

比如,人物的活跃范围,超出了训练语料库 (Training Corpus) 的表情和动作,就很难高度还原替身的表演了。
但他们说,这也是多数同行会遇到的问题。
那不就是说,“我做到的你没做到,我没做到的你也没做到”,么?
论文摘要传送门:
https://gvv.mpi-inf.mpg.de/projects/DeepVideoPortraits/index.html
声明:本文来自量子位,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
