作者
中国工商银行业务研发中心专家 苏建明
中国工商银行业务研发中心信息安全部 叶红 吕博良 程佩哲

中国工商银行业务研发中心专家 苏建明
随着国家层面对电信诈骗的治理,以及基于机器学习的大数据反欺诈风控技术的迅猛发展,各行业头部企业在反欺诈风控领域取得长足进步,传统模式的网络诈骗得到了有效遏制。但在巨大的经济利益驱动下,黑色产业链规模、手段、技术不断发展,不法分子欺诈手法不断升级,单次欺诈行为贯穿社交媒体、银行等多个行业及领域,各机构、企业基于自身数据难以应对,跨行业反欺诈数据共享及模型共建迫在眉睫。
银行业在与黑产的博弈过程中认识到关联多企业数据进行联合反欺诈可更加有效洞察黑色产业的欺诈行为,但在数据为王的时代,企业对自身数据资产愈发重视,同时关于公民隐私数据安全的相关法律法规相继出台,导致跨行业、跨机构的反欺诈风控协作无法开展,企业自身的反欺诈能力也无法有效输出。为更加有效地应对黑产欺诈行为,企业可依托联邦学习(Federated Learning)技术打通企业间数据孤岛,加大反欺诈监控响应的力度,大幅降低欺诈风险和威胁对企业和客户的影响。
一、联邦学习分类
联邦学习技术最先由谷歌于2016年提出,原本用于解决安卓手机终端用户在本地更新模型的问题,其设计目标是在保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证合法合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习,有望成为下一代人工智能协同算法和协作网络的基础。根据参加联合建模的数据提供者提供的样本和特征的重叠情况,可将联邦学习分为横向联邦学习、纵向联邦学习和迁移联邦学习三大类,如图1所示。

1.横向联邦学习
横向联邦学习也称“特征对齐的联邦学习”,适用于数据提供方的数据特征重叠很多但样本重叠较少的场景。在横向联邦学习过程中,各数据提供方联合具有相同特征的多行样本进行模型训练,即各数据提供方的训练数据是横向划分的,使得训练样本的总数量增加。
2.纵向联邦学习
纵向联邦学习也称“样本对齐的联邦学习”,适用于数据提供方的样本重叠很多,但数据特征重叠较少的场景。在纵向联邦学习过程中,各数据提供方先进行样本对齐,即找出共有样本,再联合共同样本的不同特征进行模型训练,使得训练样本的特征维度增加。
3.迁移联邦学习
迁移联邦学习适用于数据提供方的样本和特征重叠都较少的场景。在迁移联邦学习的过程中,不对数据进行划分,而利用迁移学习来解决单边数据规模小和标签样本少的问题,从而提升模型效果。
二、联邦学习技术原理
联邦学习技术在保障建模双方数据隐私不泄露、保证合法合规的前提下,实现了多参与方或多计算结点共建共享机器学习模型。该技术框架中提供了基于同态加密、差分隐私等技术的加密样本对齐和加密模型训练方法,为模型的安全共建提供基础。以两个参与方(企业A和企业B)共建机器学习模型的场景为例,企业A、B分别拥有各自的数据,通过加密样本对齐确认共有数据样本,再利用加密模型训练完成双方模型参数的计算与更新,形成联邦学习模型。整个过程中各方的数据均保留在本地,只计算加密过的模型参数和中间结果。联邦学习框架计算流程如图2所示。

1.加密样本对齐
企业A和企业B采用非对称加密协议(如RSA加密算法等)在数据加密的前提下找到双方的共有样本。具体地,企业A和企业B对各自拥有的样本ID进行哈希处理,得到样本ID的哈希值,然后,将各自样本ID的哈希值利用非对称加密协议发给对方,以便对方根据哈希值确定样本ID的交集,确定出共有的样本ID。在整个交互过程中,没有明文数据交互,即使采用暴力或者碰撞的方式也无法解析原始样本ID,从而保护双方数据样本的差集部分。
2.加密模型训练
在确定共有样本ID后,企业A和企业B分别在本地环境利用本地数据训练各自子模型,然后把子模型的中间计算结果,如梯度值、损失值进行同态加密传到云端,云端将双方结果进行聚合运算,得到联合模型的中间参数,再把更新后的模型参数下传到双方,反复迭代直至收敛完成模型训练。
以逻辑回归模型为例,企业A利用本地特征X1和X2进行训练,两个特征的模型权重分别为W1和W2,计算中间结果为W1×X1+W2×X2;企业B利用本地特征X3和X4进行训练,两个特征的模型权重分别为W3和W4,计算中间结果为W3×X3+W4×X4。两家企业分别将中间结果和样本标签进行同态加密后传输到联合平台。联合平台将两方的中间结果进行聚合(W1×X1+W2×X2)+(W3×X3+W4×X4),得到模型预测值,然后利用损失函数对模型预测值和样本标签进行计算得到总损失。利用总损失,根据反向传播算法计算模型参数基于损失函数的偏导数,通过梯度下降迭代更新模型参数W1、W2、W3和W4。随后联合平台将更新后的W1、W2传输给企业A,W3、W4传输给企业B,两家企业利用更新后的模型参数重新计算中间结果,反复迭代直至收敛。
三、反欺诈体系及场景建设
1.反欺诈体系建设
反欺诈体系依托联邦学习技术框架,在保障公民隐私信息、企业数据资产安全的前提下,打通金融、消费、运营商、互联网、政务数据孤岛,实现跨行业反欺诈体系的构建。在该体系下,构建反欺诈服务平台(如图3所示),平台的控制模块和计算模块作为平台的“大脑”,负责控制和计算,实现模型的融合共建;加密模块和学习模块作为平台的“手脚”,在合作方部署,提供开箱即用的建模和加密服务。
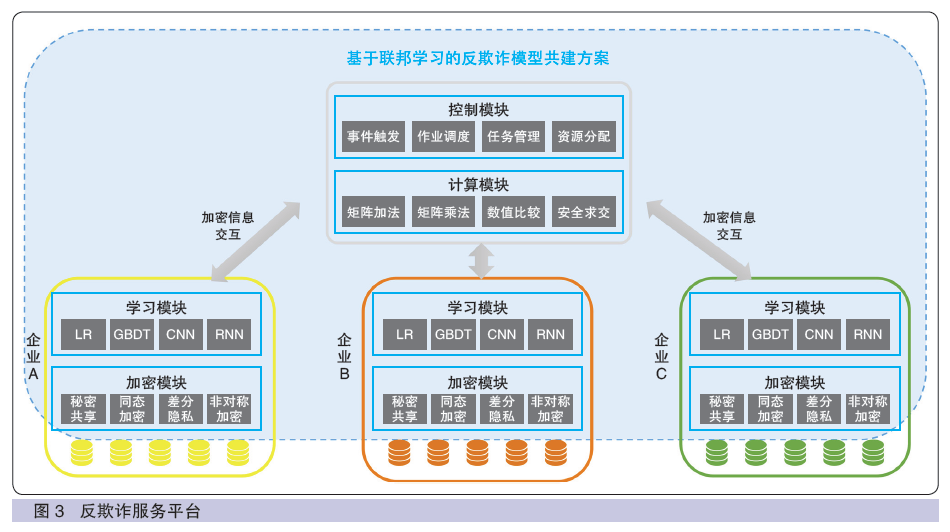
接入反欺诈服务平台的企业,企业本地存储原始数据,首先利用特征工程转换成为精确的、可量化的数据特征,便于模型训练时更好地理解和计算,然后调用平台的加密模块和学习模块提供的加密方法和算法完成企业间的数据样本对齐和模型加密训练。
2.反欺诈场景建设
依托联邦学习技术等前沿技术,可打通银行间、银企间存在的数据孤岛,基于金融特征、交易特征、行为特征和干系人特征等信息构建联合反欺诈体系,共同提升银行业和其他企业反欺诈能力。针对银行业当前面临的主要欺诈风险和联邦学习技术特点,可重点建设金融同业反欺诈、社交金融反欺诈和消费金融反欺诈三个反欺诈业务场景(如图4所示)。
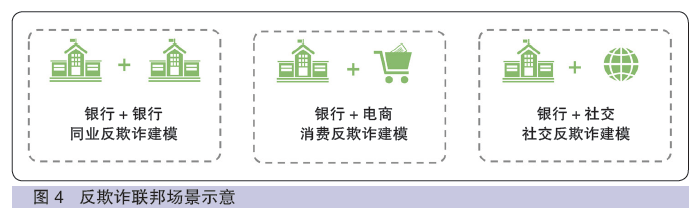
(1)金融同业反欺诈
大型银行已具备成熟的反欺诈能力和金融数据样本,反欺诈服务平台保证在数据资产、模型资产不外流的情况下,将大型银行积累的欺诈黑样本特征如欺诈交易、欺诈账户、恶意设备等信息通过共建模型的方法向中小银行输出,一方面弥补了中小银行欺诈样本少和反欺诈能力不足的缺陷;另一方面通过对同业欺诈数据的整合,将更多样的欺诈数据特征纳入共建反欺诈模型,提升了银行业整体反欺诈能力。
(2)消费金融反欺诈
针对羊毛党利用代理IP、群控设备、自动化工具对电商、O2O平台进行刷单、秒杀等交易作弊的攻击行为,仅依靠电商侧数据建模很难识别现在的羊毛党欺诈行为,无法进行有效防护和阻断。每一笔订单背后都需要银行卡进行支付,金融数据可以帮助电商从银行卡数据、支付数据、账户数据中挖掘羊毛党。可通过反欺诈服务平台实现消费交易数据与银行支付数据的联合建模,提高交易作弊反欺诈的精确度及时效性。模型可结合下单、秒杀环节获取的设备、行为、订单、物流信息和支付环节银行卡的开户、资金来源信息进行联合建模,实现消费支付环节信息的闭环,帮助电商提升反欺诈能力。
(3)社交金融反欺诈
通过银行与社交媒体或电信运营商的联合建模,通讯企业提供社交行为数据如微信账号身份、收发短消息数据量、在线时长等,银行业提供电子银行账户身份、交易记录等数据,共同训练反欺诈模型对不法分子进行识别,解决跨行业欺诈行为难以识别的痛点,更精准地发现不法分子欺诈行为,实现对黑产钓鱼撒网、社会工程诱骗客户、客户受骗转账支付、黑产资金转移等完整欺诈链条的反欺诈监控,提高网络诈骗风控的时效性及精准度,在欺诈初始阶段发现并及时拦截。一方面保护银行客户资金安全,另一方面实现与电信运营商及社交媒体的共赢,提升跨行业电信诈骗打击能力。
四、结束语
联邦学习技术是互联网风口的前沿技术,将深刻影响大数据及反欺诈行业的生态及运作模式。随着商业银行数字化转型的不断推进,面对来势汹汹的网络诈骗犯罪,急需利用多方数据协同构建反欺诈风控体系,提升反欺诈能力,创造新的社会及经济价值。在此背景下,反欺诈服务平台的方案设计切实履行了国家网络安全法、数据安全法等法律法规要求,可有效避免中心化的信任问题,实现多方协同数据联合分析。
随着反欺诈服务平台的建立和完善,反欺诈生态中的各数据提供方无需将数据集中到一起,即可进行统一的建模分析,避免了数据在多方间的跨企业流动,从而解决各方之间互不信任的问题,实现多企业共同提升反欺诈能力。
文章刊于《中国金融电脑》2021年第2期
声明:本文来自中国金融电脑,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
