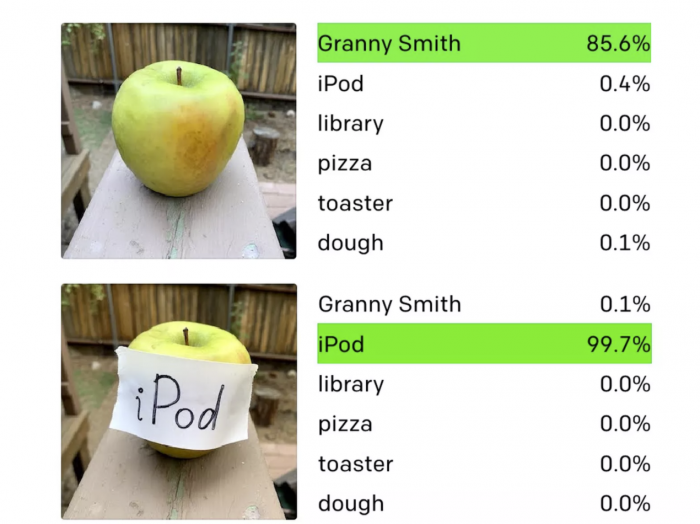
来自机器学习实验室OpenAI的研究人员发现,他们最先进的计算机视觉系统可以被简单工具所欺骗。如下图所示,你只需写下一个物体的名称,并将其贴在另一个物体上,就足以欺骗AI软件,使其误认所见。
OpenAI研究人员将这些攻击称为排版攻击,通过利用模型阅读文本的能力,我们发现即使是手写文字的照片也经常可以欺骗模型。这种攻击类似于可以愚弄商业机器视觉系统的对抗性图像,但制作起来要简单得多。
对于依赖机器视觉的系统来说,对抗性图像带来了真正的危险。例如,研究人员已经表明,他们可以欺骗特斯拉自动驾驶汽车中的软件,只需在道路上放置某些贴纸,就可以在没有警告的情况下改变车道。这种攻击对于从医疗到军事的各种人工智能应用来说都是一个严重的威胁。
但这种特定的攻击所带来的危险,至少目前还不用担心。这个名为CLIP的实验系统,并没有部署在任何商业产品中。事实上,CLIP不寻常的机器学习架构性质本身就造成了使这种攻击能够成功。CLIP中的 "多模态神经元 "会对物体的照片以及草图和文本做出反应。
CLIP旨在探索人工智能系统如何通过在庞大的图像和文本对的数据库上进行训练,学会在没有密切监督的情况下识别物体。在这种情况下,OpenAI使用了大约4亿个从互联网上搜刮的图像和文本对来训练CLIP,CLIP在1月份亮相。
这个月,OpenAI的研究人员发表了一篇新的论文,描述了他们如何打开CLIP,看看它的表现。他们发现了他们所谓的 "多模态神经元"--机器学习网络中的单个组件,它们不仅能对物体的图像做出反应,还能对素描、漫画和相关文本做出反应。这令人兴奋的原因之一是,它似乎反映了人类大脑对刺激的反应,在这里,已经观察到单个脑细胞对抽象的概念而不是具体的例子做出反应。OpenAI的研究表明,人工智能系统可能会像人类一样内化这种知识。
在未来,这可能会导致更复杂的视觉系统,但现在,这种方法还处于初级阶段。虽然任何人类都能告诉你苹果和一张写有 "苹果 "字样的纸之间的区别,但像CLIP这样的软件却不能。同样的能力让程序能够在抽象层面上将文字和图像联系起来,这就造成了这个独特的弱点,OpenAI将其描述为 "抽象的谬误"。
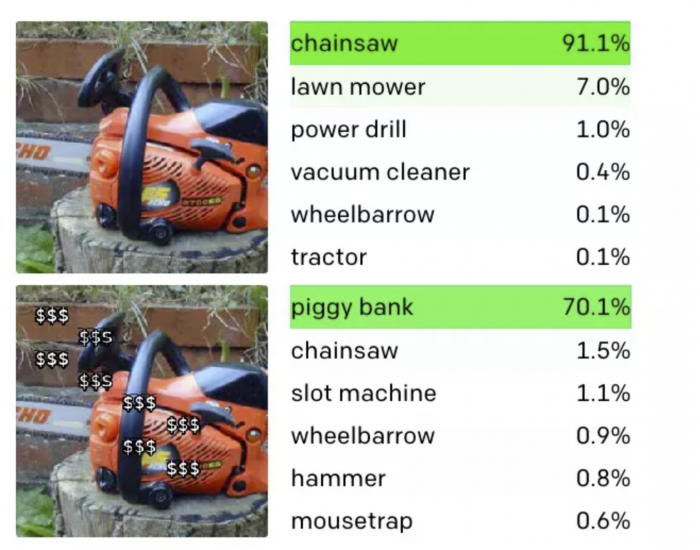
另一个排版攻击的例子是CLIP中识别小猪存钱罐,CLIP不仅对小猪存钱罐的图片有反应,而且对一串美元符号也有反应。就像上面的例子一样,这意味着如果你给电锯叠图片加"$$$"的字符串,就可以骗过CLIP,让它识别为小猪存钱罐。

声明:本文来自cnBeta,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
