
原文作者:
Ligeng Zhu and Song Han
Massachusetts Institute of Technology, Cambridge, USA
编译:对外经济贸易大学金融科技实验室
编者按
数据交易流通是数据要素市场建立的关键环节。为了在推动数据流动的同时保护数据安全、个人信息和隐私,隐私计算技术因运而生。目前,该技术分为三个流派,一是基于密码学的隐私计算技术,典型的是多方安全计算(Multi-party Computation);二是明文算法增强技术,如数据脱敏(Data Masking)、差分隐私(Differential Privacy)和联邦学习(Federated Learning);三是基于硬件的可信执行环境(Trusted Execution Environment,TEE)。深刻理解上述不同技术的优劣,不但有着理论价值,还有着重要的实践意义。近日,北京国际大数据交易有限公司正式成立;作为定位于打造国内领先的数据交易基础设施和国际重要的数据跨境流通枢纽的数据交易所,如何选择和配置适当的隐私增强技术,成为当务之急。麻省理工学院的两位教授在《来自梯度的深度泄露》一文中,指出了联邦学习系统中的潜在风险和可能的防御策略,具有启发意义,特推荐给读者。
——对外经济贸易大学数字经济与法律创新研究中心执行主任 许可
摘要:交换模型更新结果是一种在现代联邦学习系统中被广泛应用的方法。长期以来,人们认为梯度由于信息量少于训练数据而可以安全共享。然而,梯度中往往隐藏着一些信息可用于原始数据的推测。此外,从公开分享的梯度中也可重建私有的训练数据。本文讨论了一些能够推测梯度信息的技术,及其在常见深度学习任务中的有效性。本文认为,提高人们对重新思考梯度安全性的意识非常重要。本文还将讨论一些可能防止这类隐私泄露的防御策略。
关键词:联邦学习 隐私泄露 梯度安全
1.引言
随着对数据自身的要求越来越高,以及数据隐私问题日益凸显,联邦学习(Federated Learning, 简称FL)引起了各界广泛关注[1-3]。在联邦学习系统中,用户数据不在整个系统网络中共享,只有模型梯度或参数更新等中间计算结果被传输。因此,这种分布式学习已应用于对隐私安全要求高的实际场景中,例如医院数据和移动设备上的文本预测[3]。理想情况下,任何这类应用都被认为是安全的,因为人们认为梯度所含信息量少于原始数据。如下图1所示,单从一列数值张量难以推测出原始图像是一只猫。

图1. 从训练中计算梯度容易,但从梯度倒推原始训练数据并不直观。
(如图所示,无论是图像还是标签-人类不能从未处理的数值中看出这是一只猫)
由于在联邦学习训练过程中仅梯度被共享,而各建模参与者的模型训练不出本地,联邦学习被默认保护了参与者的隐私。然而,这种协议真的安全吗?梯度是否不包含任何训练数据?若不是,我们能从梯度中恢复多少信息?在本文接下来的部分,我们将探索上述梯度中的隐藏信息问题,重新思考梯度共享方案的安全性。
2.来自梯度的信息泄露
在考虑隐私相关问题时,我们研究诚实且好奇的服务器可能造成的泄露(即它可信地收集来自参与方的更新并返回更新后的模型,但是它可能会好奇参与方的信息并试图通过收到的更新来揭露这些信息)。为了研究这个问题,我们考虑一个关键问题:我们能从一个参与方在联邦学习中分享的梯度中推测出哪些关于参与方训练数据的信息?
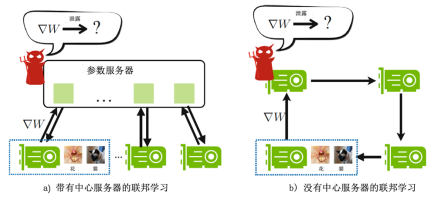
图2.两种联邦学习中的信息泄露
(红色的小恶魔所在位置标记着泄露可能发生的地点)
鉴于梯度和模型更新在数学意义上等价,本地模型的更新可以通过获取梯度和学习率得到。在以下讨论中,我们使用了基于梯度的聚合模型,而讨论并不失一般性。我们关心的是通过梯度可以推测出哪些信息。这样的攻击发生在中心化联邦学习的参数服务器(图2a),或在去中心化联邦学习的任意相邻参与方之间(图2b)。由于中心化联邦学习的应用更广泛[4,5],我们重点研究了中心化联邦学习中发生的攻击。在此设置下,我们进行了一些实验,验证了以下结论:从梯度上推测出一些隐藏信息是可能的。
成员推理[6]是在此情况下的一个基本的隐私侵犯:给定一个数据点和一个预训练过的模型,判断该数据点是否被用于训练该模型。在联邦学习中,每轮迭代的梯度都被发送给了服务器,服务器因此通过本地数据获知训练后的模型。在成员推理(攻击)中,该服务器有能力推断一个特定数据点是否在本地训练集中。在一些情况下,它可以直接导致隐私泄露。例如,发现特定患者的临床记录用于训练与疾病相关的模型会泄露该患者患有疾病的事实。在实践中,Melis等[7]证明了一个恶意攻击者可以准确(准确率达0.99)判断一个特定位置档案是否被用于一个性别分类器在FourSquare 位置数据集上的训练(见图3)。

图3. 在联邦情景下的成员推理[6]
(它使用了预测结果和真实标签以推测一个记录是否在受害者的训练集里)
属性推断[7] 是一个相似的攻击: 给定一个预训练过的模型,判断其对应的训练集是否包含一个带有特定属性的数据点。值得注意的是,该属性并不一定与主要训练任务有关。当使用LFW数据集[9]训练一个识别性别或种族的模型时,属性推断不仅能够揭示数据集中人的性别和种族,而且能够判断出他们是否戴眼镜。在实践中,这也会带来隐私泄露的风险。即使姓名和临床记录被隐藏,只要知道他/她的年龄、性别、种族、和是否戴眼镜,确定一名患者的身份依然很容易。

图4. 在联邦情景下的属性推断[7]
(它推测了受害者的训练集里是否包含一个带有指定属性的数据点)
模型反演[10] 是另一个泄露参与者隐私的有力攻击。该攻击利用了学习过程的实时性,并允许对手训练一个通用对抗网络(GAN)[11]以生成本应为隐私的目标训练集的原型样本。如图5所示,泄露的图像与原始图像几乎相同,因为GAN旨在生成来自于和训练数据分布相同的样本。当所有分类的样本互相相似时(例如人脸识别), 这种攻击非常强大。

图5. 联邦情景下的模型反演[10]
(它首先从模型的更新和攻击者自己的训练数据中训练了一个GAN模型,然后从受害者的更新中用该GAN模型生成相似图片)
以上三种攻击策略都揭示了一定程度反推被梯度隐藏的信息,但它们都有自己的局限性。成员推断需要现有的数据记录来进行攻击,当输入数据并非文本数据(如图像、声音)时,此类攻击难以实现;属性攻击的约束条件稍微宽松,只需要标签即可导致泄露,然而这种攻击只会缩小目标所在范围,并不一定能准确识别其身份;模型反演虽然它可直接生成来自和训练数据的相同统计分布的合成图片,但其得到的只是视觉上相似的替代品(并非原始数据),且仅在所有分类的数据都看起来相似的情况下有效。
接下来,我们考虑一个更有挑战性的问题:在对训练数据没有提前了解的情况下,我们是否可以从梯度中完全窃取训练数据?传统观点认为答案是否定的,但我们将证明这实际上是有可能的。
3.来自梯度的训练数据泄露
联邦学习旨在在不共享数据的情况下训练一个鲁棒的模型,然而现已证明知道梯度信息等于知道数据。当信息泄漏已经侵犯了联邦学习参与者的隐私时,我们对泄露程度的上限感到好奇–我们能否从共享的信息中完全重建隐私的训练集?这个问题至关重要,因为它对联邦学习的基本隐私性假设发起了挑战。在本章节,我们将研究该挑战,并演示这种泄露带来的潜在风险(图6)。
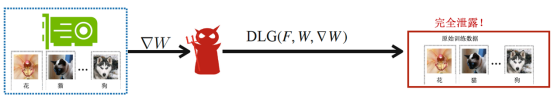
图6. 联邦情景下的深度泄露
(已知模型更新/从受害者处获取的梯度,它旨在保留梯度并完全重构私有训练集)
3.1 特定神经网络层的部分泄露
首先,我们从一些特殊的神经网络层开始讨论。第一个是全连接(FC)层。FC层被广泛地应用在神经网络(NN)和卷积神经网络(CNN)中。对于一个带有偏差项的FC层,我们可以证明无论该层在哪里,无论其相邻层是什么类型,对应的输入都可以从其梯度中推导出来。
引理 1. 使一个神经网络包含一个带有偏差项的全连接层,使该层的输入
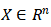 ,它的输出为
,它的输出为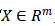 :
:
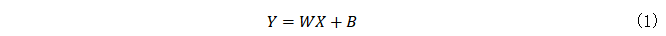
其中,权重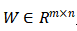 ,偏差
,偏差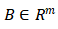 。如果存在一个坐标 i 使得
。如果存在一个坐标 i 使得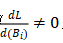 ,则输入X可以通过
,则输入X可以通过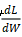 和
和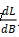 重新得出。
重新得出。
证明 1. 已知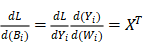 ,因此
,因此
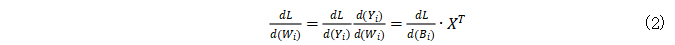
其中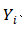 和
和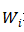 代表输出 Y、权重 W 和偏差 B 的第 i 行。因此只要
代表输出 Y、权重 W 和偏差 B 的第 i 行。因此只要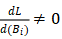 ,X即可被重新得出。
,X即可被重新得出。
得到相对于偏差的导数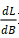 对于重建该层的输入至关重要。为了使泄露更通用化,Geiping进一步证明,即使没有偏差,只要使用了适当的激活函数(例如ReLU),也可以重建输入。证明过程同上相似,不需要任何优化即可从完全连接的网络重建训练集。
对于重建该层的输入至关重要。为了使泄露更通用化,Geiping进一步证明,即使没有偏差,只要使用了适当的激活函数(例如ReLU),也可以重建输入。证明过程同上相似,不需要任何优化即可从完全连接的网络重建训练集。
即使不对导数求导,一些层的梯度已经含有关于输入数据的某些信息。例如,语言任务中的嵌入层只会为数据中出现的单词产生梯度,从而揭示其他参与者的训练集使用过哪些单词[7]。另一个例子是分类任务中的交叉熵层,它仅为在训练集中标记为正确的类别生成负梯度[13]。这种性质暗示了真实标签。
但是,扩展到卷积层(CONV)并非易事,因为其特征的维度远远大于梯度的维度。像引理1那样的分析重建不再可行。现代卷积神经网络需要更通用的攻击算法。
3.2 来自梯度的完全泄露
为了克服这种局限性,Zhu等[14]提出了一种迭代方法,通过仅在同一神经网络上截取相应的梯度来完全重建本应是本地私有的训练集。该技术由于对用户数据的隐私造成了“深度”威胁,被称为“来自梯度的深度泄漏”(DLG)。
DLG是一种基于梯度的特征重建攻击。攻击者在第 t 轮收到其他参与者 k 的梯度更新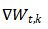 ,并试图从共享的信息中窃取参与者 k 的训练集
,并试图从共享的信息中窃取参与者 k 的训练集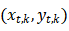 。图7展示了它如何在图像任务的联邦学习中进行攻击:该算法首先初始化具有与真实分辨率相同的分辨率的虚拟图像,并初始化一个具有概率表示的虚拟标签和softmax层。DLG在中间本地模型上对这种攻击进行了测试,以计算“虚拟”梯度。我们需要注意,大多数联邦学习应用场景都默认共享模型架构 F() 和权重
。图7展示了它如何在图像任务的联邦学习中进行攻击:该算法首先初始化具有与真实分辨率相同的分辨率的虚拟图像,并初始化一个具有概率表示的虚拟标签和softmax层。DLG在中间本地模型上对这种攻击进行了测试,以计算“虚拟”梯度。我们需要注意,大多数联邦学习应用场景都默认共享模型架构 F() 和权重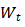 。
。
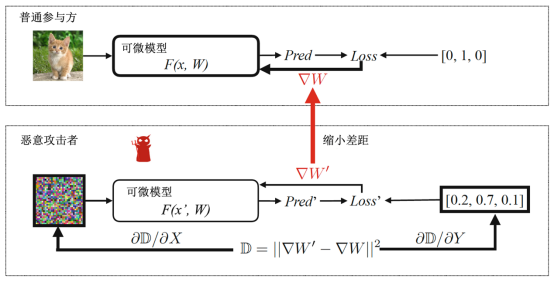
图7. DLG算法概述
(要更新的变量以粗体标记。普通参与者使用其私人训练集计算∇W以更新参数,而恶意攻击者则更新其虚拟输入和标签以最小化梯度距离。优化完成后,恶意用户便可以从诚实的参与者那里窃取训练集)
接下来,虚拟梯度和真实梯度之间的梯度距离损失被计算出并作为优化目标。重建攻击的关键是迭代地优化虚拟图像和标签,使攻击者的虚拟梯度逼近实际梯度。当梯度构造损失达到最小值时,虚拟数据也将以高置信度向训练数据收敛(范例见章节3.3)。
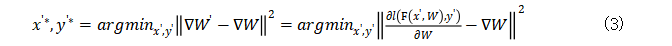

需要注意的是,该距离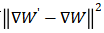 对虚拟输入
对虚拟输入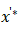 和标签
和标签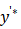 可导,所以可以使用标准的基于梯度的方法进行优化。因此,这样的优化方法需要二阶导数。在此,F被温和地假设为二次可微的。这适用于大多数最新的机器学习模型(例如大多数神经网络)和任务。
可导,所以可以使用标准的基于梯度的方法进行优化。因此,这样的优化方法需要二阶导数。在此,F被温和地假设为二次可微的。这适用于大多数最新的机器学习模型(例如大多数神经网络)和任务。
3.3 图像分类上的DLG攻击
给定一个包含对象的图像,图像分类旨在确定对象所属类别。DLG攻击的效力首先在现代CNN架构ResNet [18]和来自MNIST [15]、CIFAR-100 [16]、SVHN [17]和LFW [9]的图像上进行评估。请注意,我们做了两项修改:
(1)对于模型结构,所有ReLU运算符均被Sigmoid取代,并且消除了CONV中的步长(stride),因为我们的算法要求模型具有两阶可微分性。(2)对于图像标签,我们随机初始化了一个 NXC 的向量,其中N为批次大小,C为类别数,然后将其softmax输出作为优化和DLG攻击的分类标签,而不是直接优化离散的类别数值。

图 8. 可视化图像分别显示了来自MNIST [15],CIFAR 100 [16],SVHN [17]和LFW [9]的图像上的严重泄漏
(我们的算法可以完全恢复这四个图像,而以前的工作仅在具有干净背景的简单图像上才能成功)
泄露过程如图8所示。所有DLG攻击均始于随机的高斯噪声(第一列),并试图匹配虚拟数据和真实数据所产生的梯度。
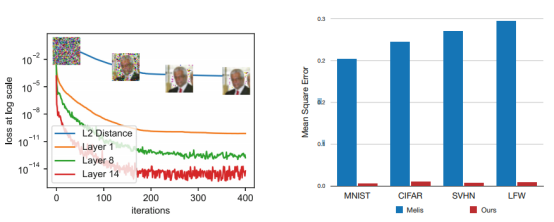
图9. Layer-i表示第i层的真实梯度与虚拟梯度之间的MSE 当梯度距离变小时,泄漏图像和原始图像之间的MSE也变小。图10. 对由不同算法泄漏的图像的MSE和真实标签的伸缩(图像)。DLG方法始终在很大程度上优于以前的应用算法
如图9所示,使梯度之间的距离最小化还减小了数据之间的间隙,并使虚拟数据逐渐收敛到原始数据。可以观察到,具有干净的背景(MNIST)的单色图像最容易恢复,而像人脸(LFW)这样的复杂图像则需要更多的迭代才能恢复(图8)。当优化完成时,伪像素可忽略不计,重建的结果几乎与真实图像相同。
我们在图8(视觉效果上)和图10(数值上)中将DLG攻击的有效性与GAN反演结果[7](见第2节)进行了比较。以前的基于GAN的反演需要知道类别标签,并且仅在MNIST上非常有效。在图8的第3行和第6列上,尽管在SVHN上揭示的图像仍然可以在视觉上识别为数字“9”,但它与原始训练图像有很大不同。在LFW上的情况更糟,而在CIFAR上则完全无效。图10显示了通过对所有数据集图像执行泄漏并测量均方误差(MSE)进行的数值比较。图像被归一化至[0,1]范围,并且DLG在所有四个数据集上都显示出更好的结果(<0.03对比之前>0.2)。
3.4 在掩码语言模型上的DLG攻击
对于语言任务,我们在“掩码语言模型”(MLM)任务上评估了DLG。在每个序列中,15%的单词被替换为[MASK]标记,而MLM模型会尝试根据给定的上下文预测被掩盖单词的原始值。BERT [19]被选为核心模型,且所有超参数均采用于官方的实现。
与RGB输入为连续值的视觉任务不同,语言模型需要将离散的单词预处理为嵌入。因此,在语言模型上,DLG攻击被应用于嵌入空间,以使虚拟嵌入与真实嵌入之间的梯度距离最小。优化完成后,通过反向查找嵌入矩阵中最接近的条目来导出原始单词。
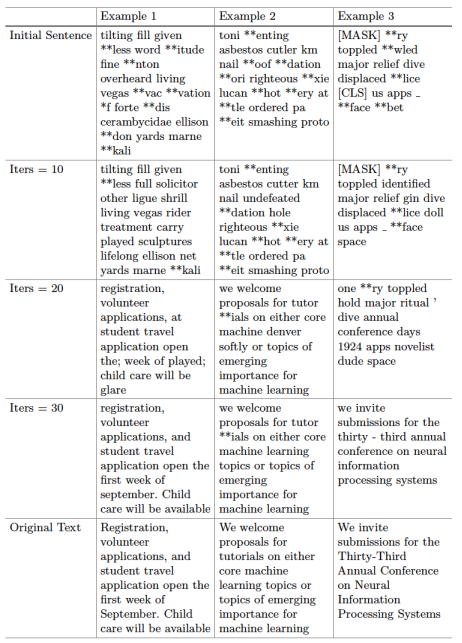
表1展示了从NeurIPS会议页面选择的三个句子中的泄露追踪。与视觉任务相似,DLG攻击从随机初始化的嵌入开始:在迭代0处重建的结果毫无意义。在优化过程中,虚拟嵌入产生的梯度逐渐与原始数据的梯度相匹配,并且虚拟嵌入也收敛到原始数据的嵌入。在之后的迭代中,部分原始句子开始出现。在示例3中,在第20次迭代时,“年度会议”出现在第30次迭代中,且泄露的句子已经接近原始句子了。当DLG完成时,尽管有一些由标记化时产生的歧义引起的不匹配,但主要内容已被完全泄露。
表1. 深度泄露在语言任务上的过程
3.5 DLG攻击的拓展
在算法1中,许多因素都会影响泄露结果,例如数据初始化(第2行)、两个梯度之间的距离测量(第6行)以及优化方法(第7和8行)。除此之外,联邦学习中的超参数(例如批处理大小和本地步骤)也很重要。在某些情况下,DLG可能无法显示(例如非常不好的初始化)。为了提高DLG的稳定性,几种方法被探索出来。
分类任务中标签信息的泄漏。DLG攻击建立在梯度和训练数据之间存在一对一的映射的假说上。因此,如果DLG没有发现真实数据,则攻击将无法收敛。对于具有交叉熵损失的任务,Zhao等[13]提出了一种从共享梯度中提取真实标签的解析解决方案。当可微的模型在one-hot监督下被训练后,损失函数为:
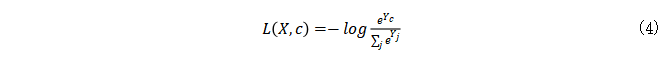
其对应的导数为
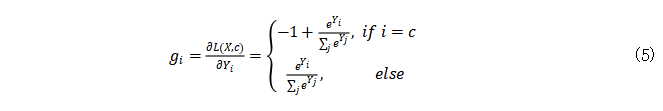
已知softmax概率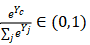 。因此,只有在真实标签那一列的坐标会出现负的梯度。
。因此,只有在真实标签那一列的坐标会出现负的梯度。
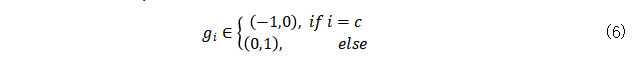
通过观察可以直接得到真实标签,有了提取出的标签,泄露过程会更稳定且有效。
梯度距离损失函数的选择:在原始DLG算法中,重构通过L-BFGS优化器优化了两个梯度之间的欧式距离(也称为均方误差)。
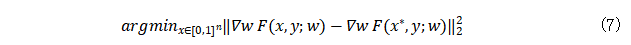
其中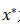 为原始训练输入。注意这里的标签 y 被假设为已通过上述技巧得知。Geiping等人[12]表明此处的模似乎不是一个重要因素。相反,在泄漏过程中梯度的方向更为重要。他们建议基于余弦相似度
为原始训练输入。注意这里的标签 y 被假设为已通过上述技巧得知。Geiping等人[12]表明此处的模似乎不是一个重要因素。相反,在泄漏过程中梯度的方向更为重要。他们建议基于余弦相似度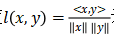 进行重构,且优化的目标变成
进行重构,且优化的目标变成
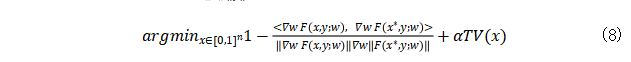
TV(X)项为一个简单的图像预先项总变化[20]。他们将其当作一个额外正则化项以保证泄露的结果为实际的。图11对比了两种损失函数。提出的目标函数(公式8),尤其在复杂的CNN结构中,表现更好。

图11. 在MNIST [15](左)和LFW [9](右)数据集上的欧氏距离和余弦相似度之间的比较
(图下方显示的数字是PSNR-该值越大越好)
不同的初始化。Wei等[21]分析了单层神经网络上DLG的收敛性,并证明收敛速度为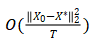 ,其中T是攻击的迭代次数。结果显示,攻击速度与x0的初始化密切相关。初始化虚拟数据的默认方法是从均匀分布中采样。尽管这种初始化在大多数情况下都可行[12-14],但它不是最佳选择,有时可能无法收敛。为了解决该问题,他们研究了各种初始化。理想的初始化是使用来自与私有训练集相同类别的自然图像。尽管此初始化要求收敛的迭代次数最少,但它需要额外关于用户数据的预先了解,而这些数据可能并不总是已知。作为替代方案,几何初始化[22]是提高攻击强度的更通用方法。
,其中T是攻击的迭代次数。结果显示,攻击速度与x0的初始化密切相关。初始化虚拟数据的默认方法是从均匀分布中采样。尽管这种初始化在大多数情况下都可行[12-14],但它不是最佳选择,有时可能无法收敛。为了解决该问题,他们研究了各种初始化。理想的初始化是使用来自与私有训练集相同类别的自然图像。尽管此初始化要求收敛的迭代次数最少,但它需要额外关于用户数据的预先了解,而这些数据可能并不总是已知。作为替代方案,几何初始化[22]是提高攻击强度的更通用方法。
4.防御策略
4.1 密码学
密码学方法能用于防止泄露:例如Bonawitz等[23]设计了一种安全聚合协议,Phong等[24] 提出在发送梯度之前先加密。在所有防御策略中,密码学手段是最安全的,而且理论上可以完美防御泄露。然而,大部分给予密码学的防御策略都有其局限性。安全聚合需要梯度是整数,所以和多数卷积神经网络不兼容,安全外包计算仅支持有限的运算,而同态加密的计算效率因密文计算大大下降。所以,我们在实践中对轻量的防御策略更感兴趣。
4.2 噪声梯度
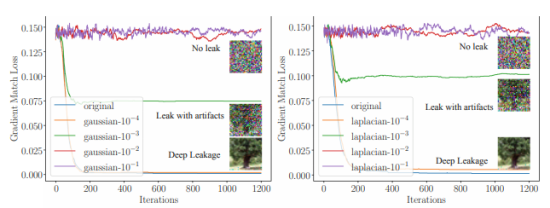
一种防御DLG的直接尝试是在共享梯度之前先加噪声。为了评估,我们先试验高斯和拉普拉斯噪声(被广泛应用于不同的差分隐私研究),并控制方差在10-1到10-4的范围, 中值控制在0。从图12a和12b中,我们观察到防御效果主要取决于分布方差的大小,和噪声种类关联较小。如果方差在10-4的范围内,噪声梯度不能防止泄露。当噪声在10-3的范围内,尽管有人工干预,泄露仍能完成,只有方差比10-2大的时候,噪声才开始影响准确度,DLG会无法执行。我们还注意到,拉普拉斯噪声在方差和噪声都在10-3的范围时表现出较好的防御性。
另一种梯度上常见的扰动是半精度,其原本是为保存内存占用而设计,并广泛运用于减少通信带宽。我们测试了两种常用的半精度的实现IEEE float(单精度浮点数格式)和bfloat16(脑浮点数[27],32字节浮动的一种简化版本)。如图12c,不幸的是两种半精度格式都不能保护训练数据。
a) 用不同数值的高斯噪声做防御
b) 用不同数值的拉普拉斯噪声做防御
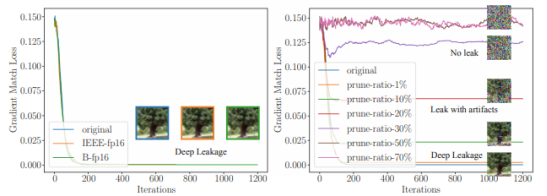
c) 用fp16转换做防御
d) 用梯度修剪做防御
图12. 不同防御策略的有效性,相对应的精确度见表格2.
表2 准确性和防御强度之间的权衡
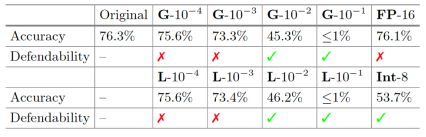
(G:高斯噪声,L:拉普拉斯噪声,FP:浮点数,Int:整数量化。✓表示成功防御了DLG,而✗则表示没有防御成功(无论结果在视觉上是否可识别)。准确性为在CIFAR-100数据集上评估的结果)
4.3 梯度压缩和稀疏化
我们还尝试通过梯度压缩进行防御[28,29]。梯度压缩会将较小的梯度修剪为零,因此,由于优化目标也会被修剪,DLG会很难匹配梯度。我们评估了不同的稀疏程度(从1%到70%)如何防御泄漏。当稀疏度为1%到10%时,它对DLG几乎没有影响。如图12d所示,当修剪比例增加到20%时,恢复图像上会出现明显的伪像素。我们注意到,稀疏度的最大容忍度约为20%。当修剪率大于20%时,无法再从视觉上识别恢复的图像,因此,梯度压缩成功地防止了泄漏。
已有工作[28,29]表明,梯度可以被压缩300倍以上而不会降低精度。在这种情况下,稀疏度超过99%,已经超过DLG的最大容差(大约20%)。这表明压缩梯度可以是避免泄漏的一种很好的实用方法。
参考文献
1. McMahan, H.B., Moore, E., Ramage, D., Hampson, S., et al.: Communication efficient learning of deep networks from decentralized data, arXiv preprint
arXiv:1602.05629 (2016)
2. Jochems, A., et al.: Developing and validating a survival prediction model for NSCLC patients through distributed learning across 3 countries. Int. J. Radiat.Oncol. Biol. Phys. 99(2), 344–352 (2017)
3. Yang, Q., Liu, Y., Chen, T., Tong, Y.: Federated machine learning: concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 10(2), 1–19 (2019)
4. Koneˇcn´y, J., McMahan, H.B., Yu, F.X., Richtarik, P., Suresh, A.T., Bacon, D.: Federated learning: strategies for improving communication efficiency. In: NIPS Workshop on Private Multi-Party Machine Learning (2016). https://arxiv.org/
abs/1610.05492
5. Bonawitz, K., et al.: Towards federated learning at scale: system design. CoRR,vol. abs/1902.01046 (2019). http://arxiv.org/abs/1902.01046
6. Shokri, R., Stronati, M., Song, C., Shmatikov, V.: Membership inference attacks against machine learning models. In: 2017 IEEE Symposium on Security and Privacy (SP), pp. 3–18 IEEE (2017)
7. Melis, L., Song, C., Cristofaro, E.D., Shmatikov, V.: Exploiting unintended feature leakage in collaborative learning. CoRR, vol. abs/1805.04049 (2018). http://arxiv.org/abs/1805.04049
8. Yang, D., Zhang, D., Yu, Z., Yu, Z.: Fine-grained preference-aware location search leveraging crowdsourced digital footprints from LBSNs. In: Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, pp.479–488 (2013)
9. Huang, G.B., Ramesh, M., Berg, T., Learned-Miller, E.: Labeled faces in the wild:a database for studying face recognition in unconstrained environments. University of Massachusetts, Amherst, Technical Report 07-49, October 2007
10. Fredrikson, M., Jha, S., Ristenpart, T.: Model inversion attacks that exploit confidence information and basic countermeasures. In: Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, pp. 1322–1333.
ACM (2015)
11. Goodfellow, I., et al.: Generative adversarial nets. In: Advances in Neural Information Processing Systems, pp. 2672–2680 (2014)
12. Geiping, J., Bauermeister, H., Dr¨oge, H., Moeller, M.: Inverting gradients-how easy is it to break privacy in federated learning? arXiv preprint arXiv:2003.14053 (2020)
13. Zhao, B., Mopuri, K.R., Bilen, H.: iDLG: improved deep leakage from gradients.
arXiv preprint arXiv:2001.02610 (2020)
14. Zhu, L., Liu, Z., Han, S.: Deep leakage from gradients. In: Annual Conference on Neural Information Processing Systems (NeurIPS) (2019)
15. LeCun, Y.: The mnist database of handwritten digits. http://yann.lecun.com/exdb/mnist/
16. Krizhevsky, A.: Learning multiple layers of features from tiny images. Citeseer,Technical report 2009
17. Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B., Ng, A.Y.: Reading digits in natural images with unsupervised feature learning (2011)
18. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pp. 770–778 (2016)
19. Devlin, J., Chang, M., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. CoRR, vol. abs/1810.04805 (2018).http://arxiv.org/abs/1810.04805
20. Rudin, L.I., Osher, S., Fatemi, E.: Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 60(1–4), 259–268 (1992)
21. Wei, W., et al.: A framework for evaluating gradient leakage attacks in federated learning. arXiv preprint arXiv:2004.10397 (2020)
22. Rossi, F., G´egout, C.: Geometrical initialization, parametrization and control of multilayer perceptrons: application to function approximation. In: Proceedings of 1994 IEEE International Conference on Neural Networks (ICNN 1994), vol. 1, pp.546–550. IEEE (1994)
23. Bonawitz, K., et al.: Practical secure aggregation for federated learning on userheld data. CoRR, vol. abs/1611.04482 (2016). http://arxiv.org/abs/1611.04482
24. Phong, L.T., Aono, Y., Hayashi, T., Wang, L., Moriai, S.: Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 13(5), 1333–1345 (2018)
25. Hohenberger, S., Lysyanskaya, A.: How to securely outsource cryptographic computations.In: Kilian, J. (ed.) TCC 2005. LNCS, vol. 3378, pp. 264–282. Springer,Heidelberg (2005). https://doi.org/10.1007/978-3-540-30576-7 15
26. Armknecht, F.. et al.: A guide to fully homomorphic encryption, Cryptology ePrint Archive, Report 2015/1192 (2015). https://eprint.iacr.org/2015/1192
27. Tagliavini, G., Mach, S., Rossi, D., Marongiu, A., Benini, L.: A transprecision floating-point platform for ultra-low power computing. CoRR, vol. abs/1711.10374 (2017). http://arxiv.org/abs/1711.10374
28. Lin, Y., Han, S., Mao, H., Wang, Y., Dally, W.J.: Deep gradient compression:
reducing the communication bandwidth for distributed training. arXiv preprint arXiv:1712.01887 (2017)
29. Tsuzuku, Y., Imachi, H., Akiba, T.: Variance-based gradient compression for efficient distributed deep learning. arXiv preprint arXiv:1802.06058 (2018)
声明:本文来自数字经济与社会,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
