作者:Rozero
0x00:前言
日志分析在入侵检测中的应用越来越广泛。尤其在甲方安全的建设当中,由于种种原因,数据只能从日志当中去获取,这也给安全日志分析领域带来了一线生机,使其得以发展。
在甲方安全工作当中,会使用分析日志的方式去发现日志当中存在的攻击行为或分析防火墙、安全设备、WAF、HIDS等产生的攻击日志,最终使得这些数据能够产生价值,帮助判读攻击行为及关联kill chain上下文信息。随着AI时代的到来,目前业内有一种说法叫AISEC,即通过AI(人工智能)及机器学习的方式去训练算法,帮助识别攻击行为,非常火热。本文暂不讨论AISEC相关的内容,仅描述通用的安全分析系统建设过程,本文也并不会表述如何搭建日志分析系统的具体实现技术细节,仅从建设流程和工作内容上去补充一些个人看法。
0x01:数据收集
谈到日志收集不得不提一下数据科学,在数据科学工作当中做任何数据处理的第一步即是收集数据。获取数据的方式多种多样,通过爬虫也好,通过日志也好、通过旁路流量也好,目标都是为了收集数据。在大型网络环境中通用会被收集的日志,包括操作系统日志及access log访问日志、WAF日志、HIDS日志等。在工作中特别常用到的是操作系统日志及access log访问日志,这两种日志对于安全工作来说至关重要,通过分析操作系统安全日志,可以得出当前主机中正在执行的命令,当前主机登陆的用户,登陆操作的IP地址等信息,初步处理后,设置相应的检测规则及告警规则,能够检测主机异常行为,如爆破、执行威胁命令等动作。而access log,在不同的公司或者网络环境,可能都不太一样。但使用的场景,大抵相同。access log中包含有正常用户及异常用户的网页请求访问日志,处理access log访问日志,并设置相应的检测、告警规则,可发现针对WEB的攻击行为,如SQL注入、XSS、文件包含、通用扫描器行为等。
日志本身不会产生价值,通过更进一步的处理,可以及时报警一些未成功的攻击行为,并作为入侵检测的补充部分。因为只是发生了攻击行为,但具体攻击是否成功,需要额外的检测,例如使用access log放到扫描器中重放攻击行为或者使用机器学习算法或规则匹配的方式检测请求当中的攻击行为,这暂时不在本文讨论的范围内。
回到日志收集,目前通用的日志收集方式是使用beats、logstash、flume来对日志收集。针对上述两种情况,笔者有一点自己的观点想和大家分享下。
操作系统日志收集,通用的解决办法是使用syslog或者rsyslog,在/etc/rsyslog.conf中新增对authpriv.* 的规则,将日志传到我们配置的日志中心服务器中。其次还可以收集auditd日志,从linux 2.6开始支持。auditd是Linux审计系统中的一个组件,负责将审计日志写入磁盘。审计日志当中会包含当前的syscall(系统调用)、comm(用户访问文件的命令)、exe(上面可执行文件路径)、cwd(当前路径)等信息,记录内核信息、包括文件的读写及改变等。
access log 收集,互联网公司使用最多的web server是ngx,所以这里的access log即是ngx(nginx),下文都以ngx来称呼nginx。Nginx收集中有个tips,Nginx配置文件中有log_format字段,log_format用于记录ngx的日志信息。默认的ngx log_format信息如下:
log_format compression '$remote_addr - $remote_user [$time_local] '
'"$request" $status $bytes_sent '
'"$http_referer" "$http_user_agent" "$gzip_ratio"';
log_format字段中可以使用分隔符例如“\t”来分割,这样处理的时候,只要按照”\t”分割即可免除使用正则表达式来处理日志的烦恼了,这种烦恼,谁处理过都会很难忘记。数据收集后,可以将数据存储到Q(queen) 即消息队列中,以备后续分析使用。
0x02:数据处理
数据收集后,需要对数据做处理即加工。不经过加工的数据是不能使用的,因为其中掺杂着噪音。数据处理的工具也非常多,实时及近实时处理工具有logstash、strom、spark、impala等数据处理工具。离线有hive等。数据处理相对来说比较体力活,但后续的数据分析都依赖于数据清洗的结果。下文以logstash来做一些常见数据处理的逻辑展示。
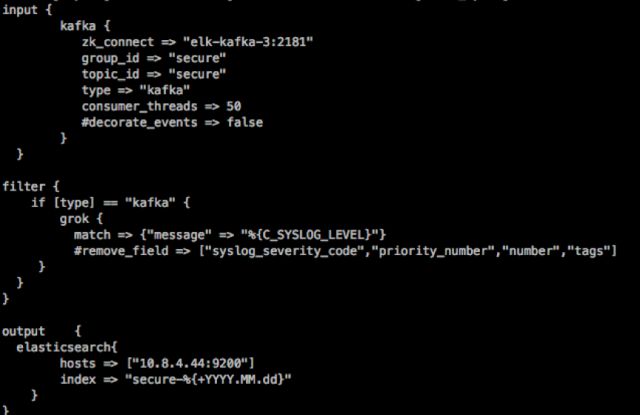
logstash的处理非常简单,logstash的架构会分为,input(输入)、filter(处理)、output(输出)。logstash支持例如grok 规则可以编写相对较为复杂的规则,将检测规则放到logstash逻辑中。
为什么选择ELK做例子?因为其简单学习成本低。我们一起简单了解下,ELK的架构特点:
1.处理方式灵活 (不需要像用storm、spark时需要写大量复杂的代码。)
2.配置简易方便,学习成本较低。检索性能高效。(能够满足查询秒级响应的需求。)有些公司甚至已经做到了百、千亿级别的搜索。
3.集群扩展性强。(增加新机器,集群能够自动识别。)
4.kibana能够快速生成炫酷的报表,省去以前大量花在前端代码的工作量。
需要说的是对于安全分析师来说,数据处理工具只是工具,我们只要把它用好就行,还是应该把心思多花在数据上。特别要说明的是使用开源软件是有一些坑要踩的。 数据处理分场景,在处理流式数据时推荐使用storm和spark,对于处理bat(批处理)数据时推荐使用spark、hdfs。决定使用何种数据处理工具,在乎的是使用数据的场景及日志量,毕竟杀鸡焉用牛刀。
0x03:数据分析
数据分析是重中之重,现在的数据分析小到使用ELK、splunk,大到使用hadoop、hive、storm、spark,都是为了能够得到更加快速、简单、精确的处理数据,以便满足工作需求。在几年前使用perl及hive在日志中拉日志分析的场景还历历在目,那时候并没有非常完善的数据处理框架,分析数据非常依赖“人工智能“。后来有了数据框架后,处理数据非常方便。安全人员只需要专注在自己的领域,将自己的安全知识输入成规则,加到检测引擎中即可实现想要的分析效果。这感觉非常棒!安全日志数据分析的领域多种多样,诸如DNS、WEB、newflow等等。分析后的目标只有一个,为了更好为做决策使用。数据分析的展示也特别重要,能图不表,尽量用图来展示效果。
0x04:数据使用
当前安全行业中火热的威胁情报即是把安全分析后的结果产出,提供出来给安全人员使用。同时“态势感知”类似的产品也是安全分析场景的产物,数据展示是否精确,主要靠后端的分析模型及算法来体现。数据使用的场景,如当发现某个IP地址大批量访问登陆接口,可以通过聚合IP请求及URl得出访问次数,发现攻击来源,联动WAF封锁异常请求IP地址。如当某个攻击端尝试进行SQL注入攻击行为,能够在短时间内判断攻击是否已经触发规则,做出处置。以上场景都依赖于基础建设,拦截需要有具体的动作执行方,数据分析后给出的结论只是方便了决策。使得以往需要人肉做的事情,可以得以自动化。
0x05:处理架构
安全日志分析系统是以上所谈的最终目标,系统化使得收集、处理、分析相关的流程得以联动,将流程合在一起就是一个较为完整的数据处理架构了,这里只做一个类比,不代表真实环境。仅供学习参考。
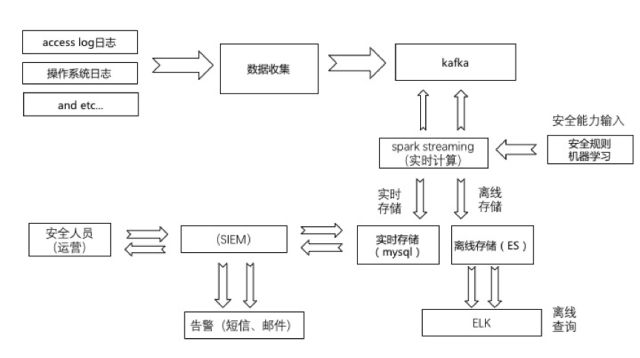
△安全日志分析系统流程图
上图会涉及到存储(在线、离线),以及人员事件处理等流程。
具体解读如下:
1.数据收集:数据流程图走向为数据收集工具收集日志,存储到kafka。
2.数据读取:spark streaming(流式计算)会从kafka里读去数据。
3.数据计算&分析:spark streaming 中会完成日志处理、计数器功能对IP、URL等访问请求做计数。同时也会有安全专家能力输入。
4.数据存储:数据在计算后实时存储到mysql类似的数据库,离线存储到ELK中,便于通过ELK查询日志。
5.数据展示:最终会有一个后端的WEB应用用于展示这些结果。
6.安全运营人员,通过SIEM运营数据。处理数据的渠道有短信及邮件告警。
7.架构特点:以上就成为了一个较为完善的安全日志分析系统,当然没有研发条件的可以用ELK、splunk等。具体的架构在不同的公司可能会略有不同。如某云上有完善的ODPS服务,可算可存,如果能够将这些繁琐的工作都通过云平台解决,那就可以专注在安全数据分析领域了。
0x06:总结
本文对安全数据处理做了个介绍,技术实现上还是较为繁琐的。可能有些坑你需要踩过一遍以后才能懂。分析使用的场景也仁者见仁,智者见智。本文只是提供了安全日志分析建设中的一些方法和思路。希望能够给其他实践的伙伴一些微小帮助,就已足矣。
安全日志分析工具在企业当中的使用的难点,不在于架构、搭建,重点还是在于系统精细化运营及如何检测威胁。所以建议大家大可以把工作交给专业的DA、DBA及SA去做,这样可以节省很多时间,把更多心思花在安全日志分析系统的“安全分析“上。
声明:本文来自饿了么安全应急响应中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
