一方面,现有工作已经证实,将程序语义转换成图表征,通过图分析可以实现高精度的安卓恶意软件检测。但是,这些传统基于图的方法总是执行昂贵的程序分析,导致可扩展性较低。另一方面,由于社交网络分析的高扩展性,它被应用于大规模的恶意软件检测。但是,基于社交网络分析的方法只考虑了简单的语义信息(即中心性)。当恶意软件故意展示和正常软件类似的行为时,中心性分析会出现误报漏报。在本文中,我们提出了一个基于API亲密度分析的系统,以将基于图分析方法的高精度和基于社交网络分析方法的高效率进行结合,实现高效率、高精度的安卓恶意软件检测。
该成果“IntDroid: Android Malware Detection Based on API Intimacy Analysis”发表在ACM Transactions on Software Engineering and Methodology (TOSEM)上(Volume 30,Issue 3,May 2021,Pages:1-32),该期刊是由ACM出版的软件工程领域的旗舰级期刊,是CCF A类期刊,每年一卷,每卷四期,每年发表的文章约23篇。
论文原文:https://dl.acm.org/doi/10.1145/3442588
背景与动机
安卓是最受欢迎的移动操作系统,已经吸引了全球数亿用户。与此同时,近年来,新的安卓恶意软件数量呈指数级增长。为了阻止恶意软件的恶意传播,研究者开发了不同的恶意软件检测工具。其中,由于考虑了应用的不同语义信息,基于图分析的方法精确度最高。但是,这些方法的效率并不理想,因为一个语义图通常包含成千上万的结点,导致恶意软件检测的扩展性较低。为了实现百万级的恶意软件扫描,基于社交网络分析的方法被提出。社交网络分析可以处理百万结点的网络,比如Twitter、Facebook。这些方法的可扩展性很高,但是为了效率,它们只考虑了敏感API调用的中心性,当应用通过调用敏感API展示与恶意软件类似的行为时,这种简单的中心性分析可能会出现误报漏报。为了解决这些问题,我们提出了一个基于API亲密度分析的系统(IntDroid),以将基于图分析方法的高精度和基于社交网络分析方法的高效率进行结合,实现高效率、高精度的安卓恶意软件检测。
设计与实现
如图1所示,IntDroid主要分为4个阶段:1)静态分析,输入是一个安卓应用,输出是安卓应用的函数调用图;2)中心性分析,输入是函数调用图,输出是调用图中的中心节点;3)亲密度分析,输入是敏感API和中心节点,输出是敏感API和中心节点的平均亲密度;4)分类,输入是平均亲密度,输出是预测的结果。预测为恶意软件则为1,否则为0。
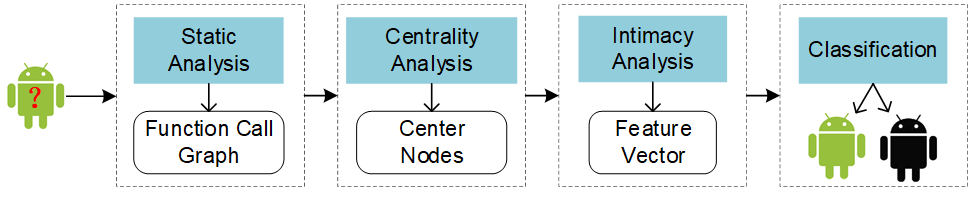
图1 IntDroid系统框架图
在静态分析阶段,我们采用了一个安卓逆向工具Androguard来提取应用的函数调用图,图中每个节点都是一个函数,可以是一个API调用或用户自定义的函数。
在中心性分析阶段,给定一个函数调用图,我们首先计算图中所有节点的中心性,中心性在前n%的结点会被视为中心节点。为了进行更全面的实验分析,我们一共选择了8个不同的n值:1-8。关于中心性度量,我们一共选择了4种中心性度量方式:degree centrality、katz centrality、closeness centrality和harmonic centrality。正常情况下,在社交网络分析领域,度量一个节点的重要程度一般会结合多种不同的中心性度量方法,所以,我们在本文中还构建了另外两种度量方式:average centrality和all centrality。average centrality的构建是取前面4种中心性的平均值,all centrality的构建方式如图2所示,即将前面4种中心性计算得到的中心节点取并集。
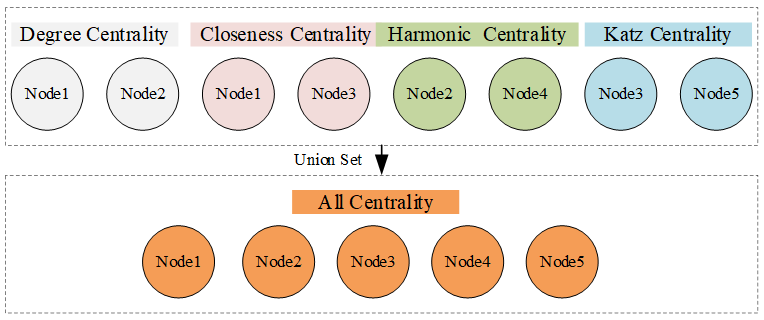
图2 all centrality的构建方式
在亲密度分析阶段,给定中心节点之后,我们会计算敏感API和这些中心节点之间的亲密度。敏感API的选择是依赖于现有最大的一个敏感API数据集,一共21,986个敏感API。一方面,如果两个函数之间存在着更多的可达路径,则这两个函数之间的“交流”可以视为频繁。另一方面,如果两个函数之间的距离较短,则它们之间的“交流”可以认为是容易的。本文中,如果两个函数之间的“交流”是频繁和容易的,它们将被视为一个亲密对。两个函数 a、 b之间亲密度的计算公式如下:
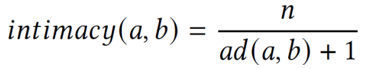
n表示 a和 b之间可达路径的数量, ad ( a, b)表示这些可达路径的平均距离。例如,假设a和b之间有两条可达路径: a → p → q → b和 a → m → b 。即 n = 2,平均距离为(3 + 2) / 2 = 2.5。因此, a和 b之间的亲密度可以计算为2 /(2.5 + 1) = 0.57。此外,会存在着一种特殊情况,即当中心节点也是某个敏感API时。在这种情况下,该敏感API和中心节点之间的平均距离将为0,为了避免分母为0,我们将亲密度的计算公式中平均距离多加了1。
在分类阶段,给定敏感API和中心节点的平均亲密度,我们会将这些亲密度作为特征输入机器学习模型中,以此来训练一个分类器。训练得到的分类器会分类待检测的应用,输出为1则表示应用为恶意软件,否则则为正常应用。
为了验证IntDroid在检测恶意软件上的有效性,我们一共收集了8,253个应用,包括3,988个正常应用和4,265个恶意应用。
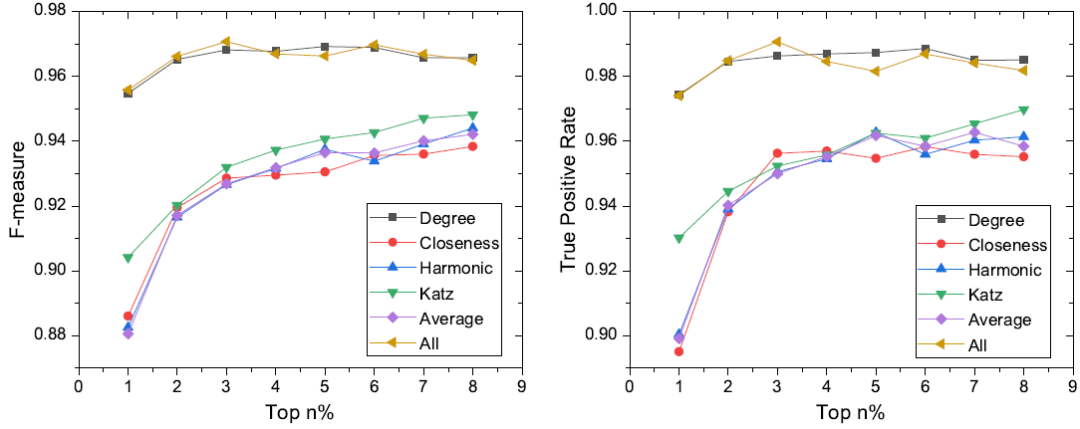
图3 IntDroid在筛选中心节点时选择不同top n和不同centrality的检测效果
从图3可以看到,选择前n%的节点作为中心节点时,n不一样检测效果会不一样。同样的,选择不同的centrality也会导致得到的中心节点不一样,使得最后的检测效果也不一样。总而言之,degree centrality和all centrality的效果要优于其他4种centrality,当选择centrality在前3%的节点作为中心节点时,IntDroid的检查效果最佳。

图4 PerDroid、MaMaDroid、MalScan和IntDroid的对比实验结果
另外,我们还选择了PerDroid(TIFS’2014)、MaMaDroid(NDSS’2017)和MalScan(ASE’2019)作为我们的对比系统,对比实验结果如图4所示。从图中可以看出,IntDroid的表现最佳,可以达到97.1%的F1和99.1%的TPR。
表1 IntDroid的运行开销(秒)
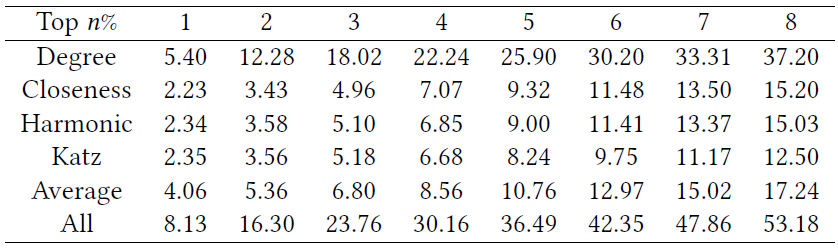
最后,我们还测试了IntDroid的运行开销。如表1所示,选择不同的centrality时检测应用的开销不一样,选择不同top n时,IntDroid的运行开销也不一样。n越大,代表着中心节点数量越多,导致在计算亲密度时开销增大。整体而言,当我们选择degree centrality在前1%的节点作为中心节点时,只需要大概5.4秒就可以分析完一个应用,此时的TPR为97.4%。
声明:本文来自穿过丛林,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
