声明:以下内容编译自互联网,不代表本公众号的观点,如有侵权,请联系删除。

网络安全中最棘手的问题之一是试图找出攻击的真正幕后黑手。创建互联网的五角大楼机构 Darpa 正试图解决这个问题,通过一项新的努力来开发网络上的指纹或 DNA 等价物,即使是最隐蔽的黑客也能识别出来。
1.提案背景
美国国防高级研究计划局 (DARPA) 的科学家2010年针对网络基因组计划发布了一份广泛的机构公告 (DARPA-BAA-10-36),该计划旨在开发革命性的网络侦查技术,以帮助美国国防部 (DOD) ) 执法、反情报和网络防御团队。
本质上,网络基因组计划旨在开发指纹或 DNA 的网络等效物,以帮助制作基因型的数字等效物,以帮助追踪网络恐怖分子、他们的动机和行动。
国防部官员表示,当今的信息战和网络防御技术以定制解决方案为中心,以应对来自网络恐怖分子的个人网络威胁和其他信息战威胁,这导致了网络攻击、恶意软件和垃圾邮件的扩散。
这种方法为不对称的敌人提供了优势,他们可以开发廉价的、进化的网络战方法,绕过或击败入侵检测和保护系统、基于主机的防御和取证分析。
相反,DARPA 科学家需要新的、强大的网络防御和调查技术来从实时系统(如传统计算机、个人数字助理和云计算等分布式信息系统)中收集数字工件。
具体而言,DARPA 科学家对网络遗传学、网络人类学、网络社会学、网络生理学和相关的高级信息战学科感兴趣,以识别阻止来自计算机黑客和网络恐怖分子的潜在威胁。
网络遗传学是指数字制品的祖先和起源地。网络人类学指的是人工制品、二进制文件和用户之间的关系。与此同时,网络生理学是指机器语言功能和行为的逆向工程。
网络基因组计划是一项为期四年、耗资 4300 万美元的计划。提案于 2010 年 3 月 15 日提交给 DARPA。
2.提案摘要
当前用于生成和检查软件产品(尤其是恶意软件)之间的关系的技术和方法充其量是缺乏的。散列或“模糊”散列和匹配技术的使用是在程序级别进行的,忽略了恶意软件实际开发过程的任何反映。此方法仅在查找仅与开发过程相关的恶意软件中发现的密切相关变体或匹配工件时有效,例如硬编码的 IP 地址、域或登录信息。这个匹配过程通常不知道内部软件结构,除非在最基本的意义上,一次处理整个代码段,在处理任意块边界时尝试对齐匹配。这种方法类似于文盲尝试比较关于同一主题的两本书。这样的人将有机会将同一本书的不同版本相关联,但除此之外别无其他。今天的方法的第一个基本缺陷是它忽略了我们在理解恶意软件谱系关系方面的最大优势,我们可以将程序结构推导出反映开发过程的块(函数、对象和循环),并通过代码重用赋予软件谱系。
软件开发已通过经济推动代码重用。重用已经为特定任务开发的部分代码更便宜、更有效。已经开发了整个计算机编程语言来使代码重用更有效。恶意软件的开发也反映了代码重用,与其说是通过对开发过程的有意设计,不如说是因为恶意软件主要是单独开发的,或者是小规模、紧密结合的群体开发的。代码重用确实发生在组之间,但这主要是由于代码被盗。无论哪种情况,代码重用都是软件沿袭的基础;因此,任何映射和关联网络基因组的尝试都应该集中在尝试关联软件重用上。
基于代码重用的软件的可靠关联将建立沿袭;然而,血统本身只有部分价值。在合法软件中使用的代码不仅限于在其他合法软件中重用。恶意软件作者重复使用所有来源的代码,无论合法与否。因此,恶意软件研究中没有上下文的谱系并不严格限于恶意软件,未知软件样本与已知恶意样本的遗传关系也没有暗示恶性。因此,迄今为止恶意软件谱系和关联方法的第二个基本缺陷是它们忽略了上下文。
今天的恶意软件分类方案基于行为,并且在很大程度上忽略了这些行为是如何实现的,除非这些信息对开发检测签名很有价值。行为本身虽然很重要,但在任何试图开发可行的网络血统系统的尝试中几乎都是毫无价值的信息。行为分类根本不是一个可行的分类系统,如果将这样的系统应用于生物学,食蚁兽和许多鸟类将属于同一个“家庭”,因为它们的行为,即吃蚂蚁,是相同的。
3.技术原理
虽然这是一项具有挑战性的工作,但我们计划研究和开发一个全自动的恶意软件分析框架,该框架将产生可与最优秀的逆向工程专家相媲美的结果,并在无需人工干预的快速、可扩展系统中完成分析。在完整的成熟系统中,唯一需要人工参与的将是报告和恶意软件配置文件的可视化。
我们的方法是当今常见的二进制和恶意软件分析的重大转变,需要高技能和高薪工程师的手工劳动。结果缓慢、不可预测、昂贵且无法扩展。工程师需要精通低级汇编代码和操作系统内部结构。结果取决于他们解释和建模复杂程序逻辑和不断变化的计算机状态的能力。最常用的工具是用于静态分析的反汇编器和用于动态分析的交互式调试器。最好的工程师有一个非标准的本地或互联网收集的插件的临时集合。复杂的恶意软件保护机制,例如打包、混淆、加密和反调试技术,提出了进一步的挑战,这些挑战会减慢和阻碍传统的逆向工程技术。
我们首先意识到恶意软件只是没有源代码的二进制形式的软件。像任何软件一样,恶意软件必须执行才能完成它的工作。要执行它,它必须驻留在物理内存 (RAM) 中并由 CPU 操作。CPU有两个要求:1)二进制的操作指令必须是明文的,2)CPU一次只做一件事。打包或加密的二进制文件必须解包或解加密本身;否则 CPU 将不会对其进行操作。
我们将通过在受控、仪表化和自动运行跟踪系统中运行二进制文件来解决传统逆向工程的问题,该系统将收集 CPU 所做的一切,以顺序方式一次一个操作。所有指令和数据都将按照与它们发生时完全相同的顺序进行收集和存储。重放执行将重现二进制文件的行为,以及有关与其他数字对象交互的上下文信息。物理内存可以被成像并自动重建,从而及时显示内存中的所有数字对象。二进制文件可以从内存映像中提取——通常是解包和未加密的——并与内存映像中包含的上下文信息一起进行静态分析。
我们假设软件和恶意软件可以具有一组有限的可能功能和行为,尽管随着软件的发展,它可能是一个很大的集合。例如,通过网络进行通信、重新启动或写入文件的方法只有这么多。
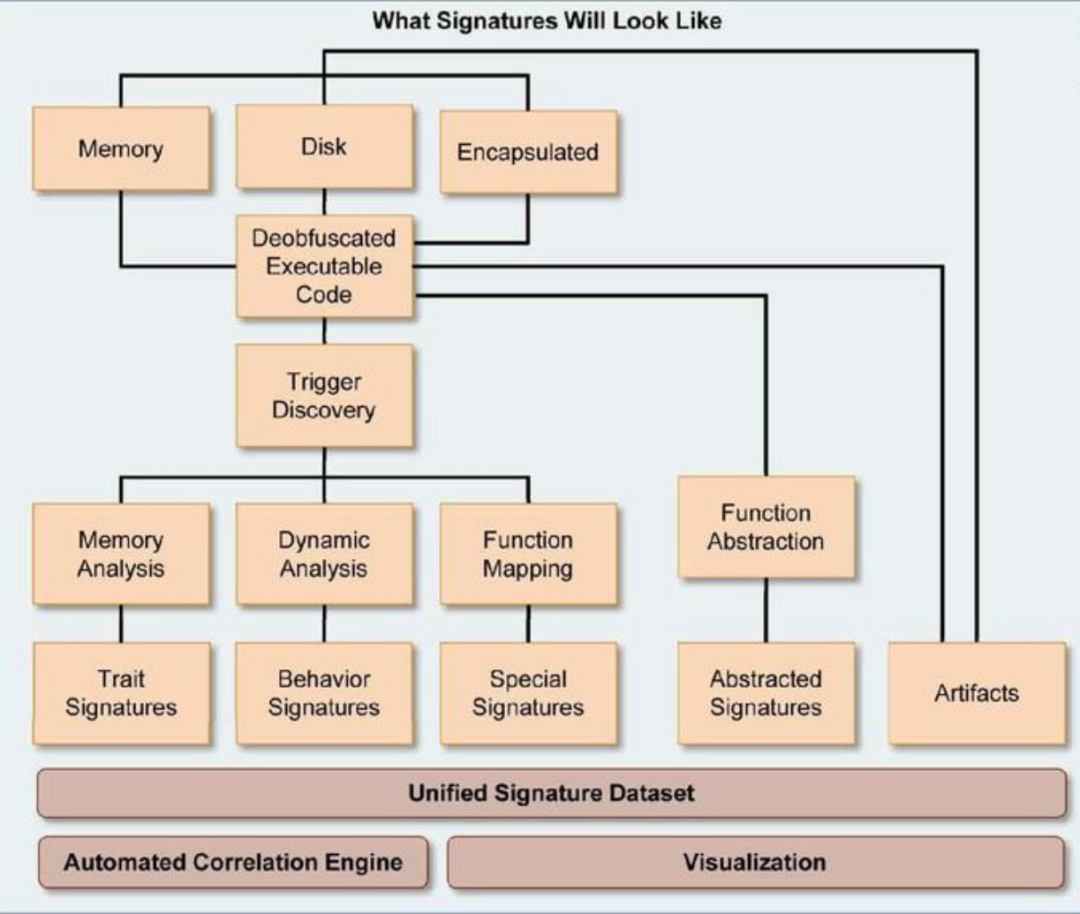
我们将创建一组特征和基因组,以预定义软件和恶意软件的可观察功能和行为。使用一组规则对从二进制运行跟踪和内存重建收集的大量低级数据进行操作,系统将自动确定每个二进制样本中存在哪些特征和基因组。随着时间的推移,这种方法也将能够确定性状和基因组的进化变化。尽管自动化分析已经从细粒度的技术数据转移到更高级别的特征和基因组,但这种级别的信息不足以完整描述二元样本的功能、行为和意图。观察到的特征和基因组将被输入信念推理引擎,该引擎使用先验知识对二进制做出概率决策。
4. 技术方法和建设性计划
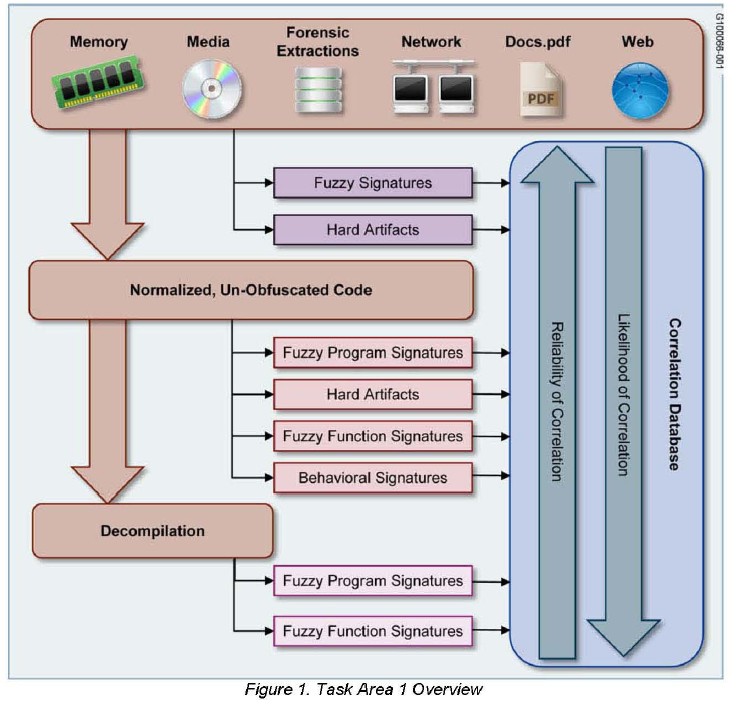
图 1 展示了我们的恶意软件分析框架,该框架将允许用户在完全自动化的系统中快速理解恶意软件的功能、行为和意图。该系统将自动识别特征和基因组,以对二进制文件和恶意软件进行分类。在初始阶段,特征和基因组将手动开发,但最终成熟的系统将在后期阶段根据恶意软件的先验知识自动创建特征和基因组。成熟的系统将依赖人工开发性状和基因组作为例外。将使用迭代静态内存和运行时跟踪方法生成低级数据。三个数据集——恶意软件样本库、特征和基因组库——将通过分析过程不断更新数据,包括生成的恶意软件生理学配置文件。生理学配置文件将包含恶意软件的数学和视觉表示,以及恶意软件整体和更详细的行为、功能和目的的人类可读摘要。
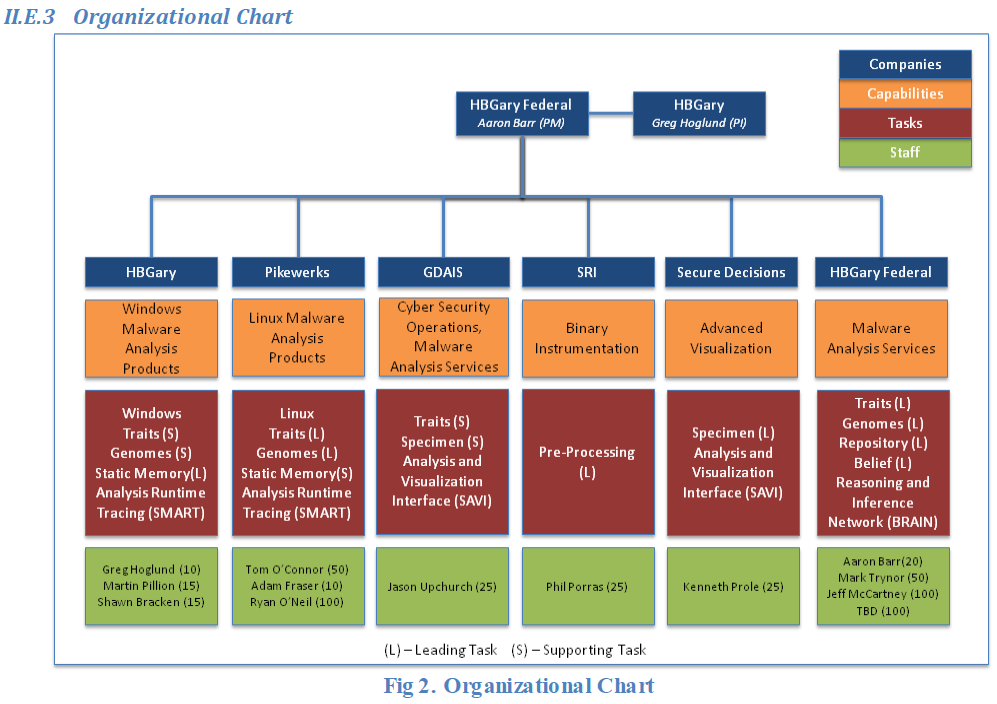
5. 参与厂商和成果
MAAGI
作为 Cyber Genome 计划的一部分,Charles River 开发并正在完善 MAAGI(使用遗传信息的恶意软件分析和归因)。在其当前版本中,MAAGI 结合了来自生物进化、计算机程序逆向工程和语言学的思想和技术,以快速识别新恶意软件攻击的来源和意图。MAAGI 利用了这样一个事实,即恶意软件作者经常在一次攻击中重复使用代码,同时试图通过更改恶意软件的“表面”特征来向防御者隐藏这种重复使用。通过发现从一个恶意软件样本到下一个恶意软件样本保留的恶意软件的基本“遗传”属性,MAAGI 试图确定每个样本的谱系,并使用谱系来帮助表征恶意软件的来源。此外,通过了解恶意软件的进化模式,MAAGI 可用于预测未来恶意软件的发展,预测潜在的攻击,而不是像我们今天所做的那样仅仅对它们做出反应。MAAGI 还使用功能语言学的方法来识别恶意软件的功能特征和潜在意图,即使表面特征发生变化,这些方面也特别有可能被保留。MAAGI 允许分析人员逐个基因地查看恶意软件的演变。
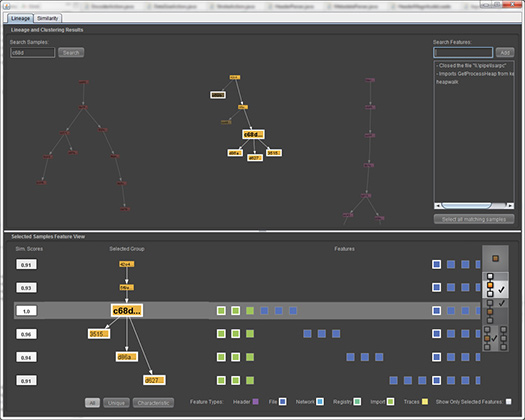
MAAGI 的一些功能包括:
恶意软件沿袭的可视化
集群类似的恶意软件
查看集群的本地沿袭
查看集群内的异同
按类型对功能进行排序(例如,文件、标头属性、导入、dll 调用跟踪等)
选择选项
基于所选恶意软件的相似性显示更新
能够选择多个样本
选择整个谱系聚类显示相似/差异特征
方便的血统视图
查看样本和后代,但不查看祖先
查看祖先,但不查看后代
查看与其他样本相比的本地血统
按组内和组外出现过滤特征
搜索
搜索相似样本
在其他谱系中搜索相似样本
子串搜索
MAAGI 是应对网络基因组挑战的一种创新方法,即表征和预测恶意软件的演变。它支持国防和执法社区的网络攻击检测和归因。
通过识别来自先前攻击的代码和技术,MAAGI 能够加快响应时间以防御网络攻击。MAAGI 的主动性在于它不仅可以评估攻击,还可以预测和预测未来攻击的属性。最后,MAAGI 使恶意软件作者更难更改表面特征和重用其代码,从而改变了恶意软件的经济性。
DECODE
恶意软件取证分析师面临着我们最大的国土安全挑战之一 - 不断涌现的新恶意软件变种由适应性强的对手在网络空间寻找新目标、利用新技术并绕过现有安全机制而发布。对新样本进行逆向工程,了解它们的能力并确定出处是耗时的,并且需要相当多的人类专业知识。Raytheon BBN Technologies(雷神)展示了 DECODE,这是在 DARPA 的 Cyber Genome 计划下开发的原型恶意软件取证分析系统。DECODE 通过快速将新恶意软件样本识别为其他恶意软件样本的变体,而不依赖预先存在的防病毒签名,从而增加了可从收集的恶意软件的大型存储库中得出的可操作取证。DECODE 还通过快速识别其他样本中已经发现的恶意软件部分并表征新的和不同的功能来加速逆向工程工作。DECODE 还可以重建恶意软件变体随时间的演变。DECODE 应用系统发育分析来提供这些优势。系统发育分析是研究程序结构的异同,以发现软件程序组内的关系,提供有关基于签名的恶意软件检测无法获得的新恶意软件变体的见解。
此外还有MalLET (来自洛克希德马丁公司先进技术实验室)和MATCH(来自森塔公司Sentar, Inc.)等都参与了该计划。
消息来源:
1.https://www.militaryaerospace.com/defense-executive/article/16723442/cyber-genome-program-launched-to-bolster-dod-information-intelligence-and-cyber-defense-capabilities
2.https://publicintelligence.net/hbgary-general-dynamics-darpa-cyber-genome-program-proposal/
3.https://publicintelligence.net/hbgary-darpa-cyber-genome-technical-management-proposal/
4.https://cra.com/projects/maagi/
5.https://ieeexplore.ieee.org/document/7225311/
6.https://www.sentar.com/technologies-overview/
声明:本文来自网络安全风云榜,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
