一、告警载荷分析的困境
在此前关于告警载荷分析的研究中,我们最终选用人类专家所编写的正则表达式等特征模式,从告警载荷中提取关键字段信息,再通过监督学习方法找到这些信息与告警实际危害程度之间的关系(参考:【攻击意图评估】系列文章:【攻击意图评估:总集篇】手把手教你搭建告警筛选系统)。
但当前实验表明,这种做法存在两个比较关键的问题:
1.1关联信息的丢失
考虑以下两段告警载荷片段:
第一个载荷片段是一段无害的JavaScript代码片段:
const result_loader="JSON.parse"; $.ajax(…).success((data)=>{ var hash=$.md5(eval(result_loader)(data)["$_POST"]); … }); |
第二个片段则是某种PHP WebShell的恶意代码片段:
if(md5($_POST["pwd"])=="b38acde3f02a889e5cad5ae33cfe80ef") eval($_POST["script"]); … |
可见,第一个载荷片段是一段无害的JavaScript代码,而第二个片段则是某种PHP WebShell的恶意代码。
当人类专家看到第一个载荷片段时,能够理解代码内容的具体含义,知道eval函数的执行对象是常量字符串“JSON.parse”,是无害的;类似地,看到第二个载荷片段时,也能够理解eval函数的执行对象是POST参数,可以认定为是恶意攻击。
但如果通过特征模式对以上两个载荷进行提取,会得到非常相似的结果(“eval”、“md5”、“$_POST”、…),导致后续模型处理无论如何也无法作出有效区分。追根究底,这种特征提取方法会损失掉特征对象之间的关联信息,例如函数名与实参、关键字与标识符、被赋值变量与表达式、等等。
从这个角度看来,依赖特征模式的告警载荷信息提取方法是远远不够的。
1.2迁移能力差
在使用监督模型对告警进行评估时,训练数据的标注值(也是模型的输出值)通常是“告警的实际危害程度”。然而实践表明,告警的实际危害程度受众多主观和客观因素影响。
不同的专家、在不同的时间、不同的网络环境中、不同的评估背景下,对同一个告警的危害程度评定结果都不尽相同。
例如,在日常运营中,内网蠕虫活动通常是需要关注并处置的;但到了红蓝对抗中,由于先验地认为“攻击方不允许使用蠕虫”,因此往往会暂时忽略蠕虫相关的告警。
这就导致,在一个网络环境中训练完成的模型,拿到另一个网络环境中就很难使用;某位专家标注训练出来的模型,其他专家可能会觉得很差;甚至是在同一个环境中,样本的标注值也会被反复修改。

也许我们从一开始就搞错了方向:模型可能需要先明确告警内在的性质,才能推断出告警对外部的影响?
二、告警载荷特征提取问题的理解和探讨
2.1对问题的理解
上面提出的两个问题,可以更进一步地理解为:
1、如何验证某个特征提取器的有效性(既然特征规则用于特征提取的效果不好,那一个“好”的特征提取器应该是怎样的)?
2、告警载荷中的关键特征应当如何组织和表示(既然“实际危害程度”作为标注值并不妥当,那一个“好”的特征提取器应该输出什么样的结果)?
2.2对问题的探讨
经过反复研讨和尝试,我们得出初步结论如下:
1、告警载荷特征提取器的有效性评估应当包括两方面:
a)完整:提取器的输出(经过解析后)能够代替告警载荷,帮助人类专家作出所有必要的判断;
b)准确:在前者的基础上,提取器输出的信息量应当尽可能地小;
时至今日,我们并没有什么自动方法被证明在告警评估上的效果强过人类专家。因此,特征提取器的有效性,目前还是需要通过人类专家进行评判。

2、自然语言是告警载荷特征的良好表示形式之一:
a)大多数告警载荷都是对网络流量或其片段的记录,它们本质上是对网络活动的一种观测。因此,对告警载荷关键特征的表示,等价于对网络活动中关键特征的表示;
b)现代信息系统中的业务包罗万象,网络活动关键特征的内容和结构也因此高度复杂。如果用有限维度的特征去表示这样的信息,是非常局限的;
c)既容易被人类专家所理解和表述,维度又可以扩展的表示形式,大概非自然语言莫属了。
基于以上考虑,告警载荷特征提取器应当将二进制字节流输入转换成自然语言输出。
三、告警载荷摘要生成
我们暂时将这种新型的特征提取器称为“告警载荷摘要生成器”,因为人类专家遵循上述需求给出的标注,看上去大多都很适合作为告警的标题,例如这样的:
告警名称: [中风险]webshell common_webshell_connection |
标注: WebShell代理访问*第二受害者*的22端口SSH服务 |
请求报文(解码后): POST /xiao/shell.jsp HTTP/1.1 Host: *第一受害者*:8080 User-Agent: 1 Content-Length: 135 Content-Type: application/x-www-form-urlencoded Accept-Encoding: gzip Remoteserver=http://127.0.0.1:38964/&SENDDATA={"sa":"127.0.0.1:59854","da":"*第二受害者*:22"} |
响应报文(解码后): HTTP/1.1 200 Set-Cookie: JSESSIONID=*已脱密*; Path=/xiao; HttpOnly Content-Type: text/html;charset=utf-8 Content-Length: 68 Date: *已脱密* {"d":"SSH-2.0-OpenSSH_7.6p1 Ubuntu-4ubuntu0.3"} |
或者这样的:
告警名称: [高风险]路径穿越 xml_resource_scan |
标注: 读取HP打印机功能列表XML |
请求报文(解码后): GET /DevMgmt/DiscoveryTree.xml HTTP/1.1 Accept-Encoding: gzip, deflate Host: *已脱密*:8080 Connection: Keep-Alive |
响应报文(解码后): TTP/1.1 200 OK Content-Type: text/xml Server: Mrvl-R1_0 Cache-Control: no-cache Connection: keep-alive Transfer-Encoding: chunked …(后面还有很长,此处省略)… |
摘要生成是NLP领域的一项经典任务,相关技术已有众多成熟实现可供参考,其算法大致可以分为抽取式和生成式两种[1]。
理想的告警载荷摘要生成,应当一并完成抽象归纳和翻译,并非单纯地在原始告警载荷中选择子序列,因此抽取式方法在此场景中并不合适,暂时排除。
四、摘要生成算法可行性分析
具体何种生成算法实现告警载荷摘要生成任务的效果最佳,目前的研究仍在进行中。本文仅以Seq2Seq为例进行可行性分析。
严格来说,Seq2Seq泛指一大类输入输出均为序列的方案,而不是某个具体的模型实现[2]。经典的Seq2Seq以各种递归单元(LSTM、GRU等)为核心,将输入序列的信息不断叠加,最终编码为固定长度的向量;而解码过程刚好相反,同样使用递归单元将这个固定长度的向量不断提取成为输出序列[3]:
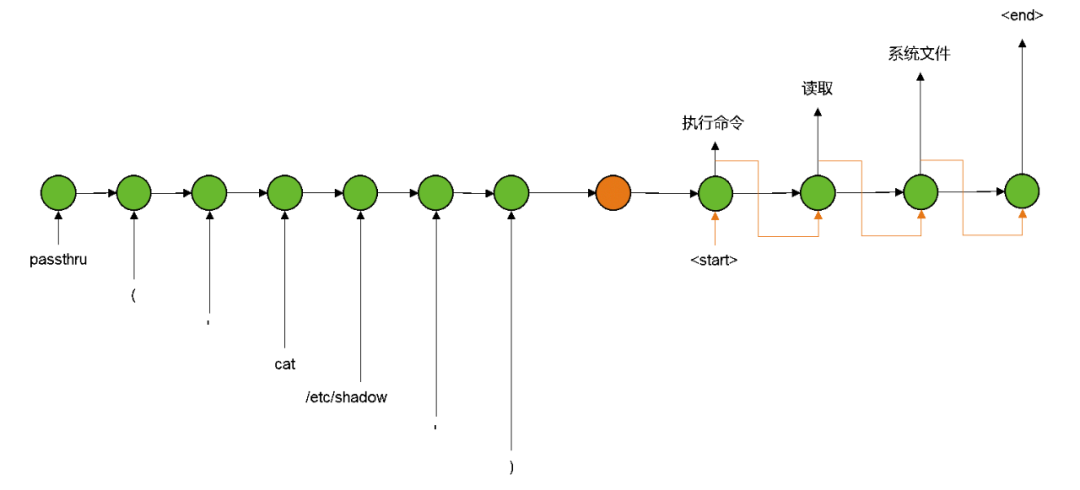
(Seq2Seq在告警载荷摘要生成任务上的应用示例)
这种模型的优势在于,它可以用恒定数量的模型参数,处理不定长度的输入/输出。但由于整个输入序列的信息都要被编码到固定维度的中间向量上,当输入序列很长时,就难免会损失一些信息[4]。
因此就有了带“注意力”机制的改良版本[3]。即在编码器递归过程中,保留每一步的状态值;随后在解码器递归的每一步中,寻找相关状态值并加权得到“注意力向量”;随后将“注意力向量”叠加/拼接到原本的解码器输入中。如下图所示:
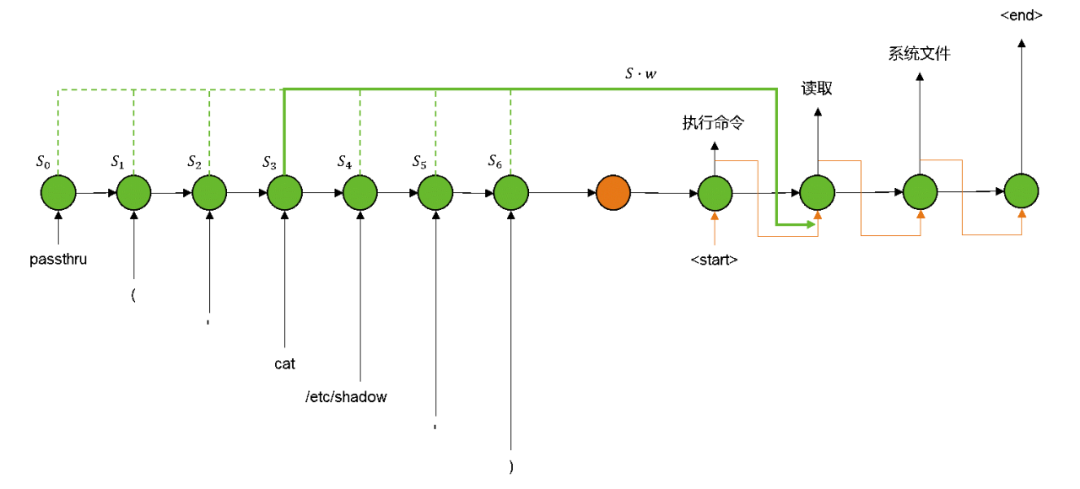
(带注意力机制的Seq2Seq,其中权重的计算方法本文不详细讨论)
2017年Google团队发表了一个名为“Transformer”的经典机器翻译模型[5],该模型随后于2019年成为BERT模型的一个关键构成单元[6]。后者及其各种改良版本目前广泛应用于各类NLP任务,并取得了良好的效果。
与经典Seq2Seq方法不同,Transformer中彻底抛弃了递归单元,使用“位置编码”+“多头注意力层”的方法构造编码器和解码器[5],完全依靠注意力机制实现输入到输出的转换。
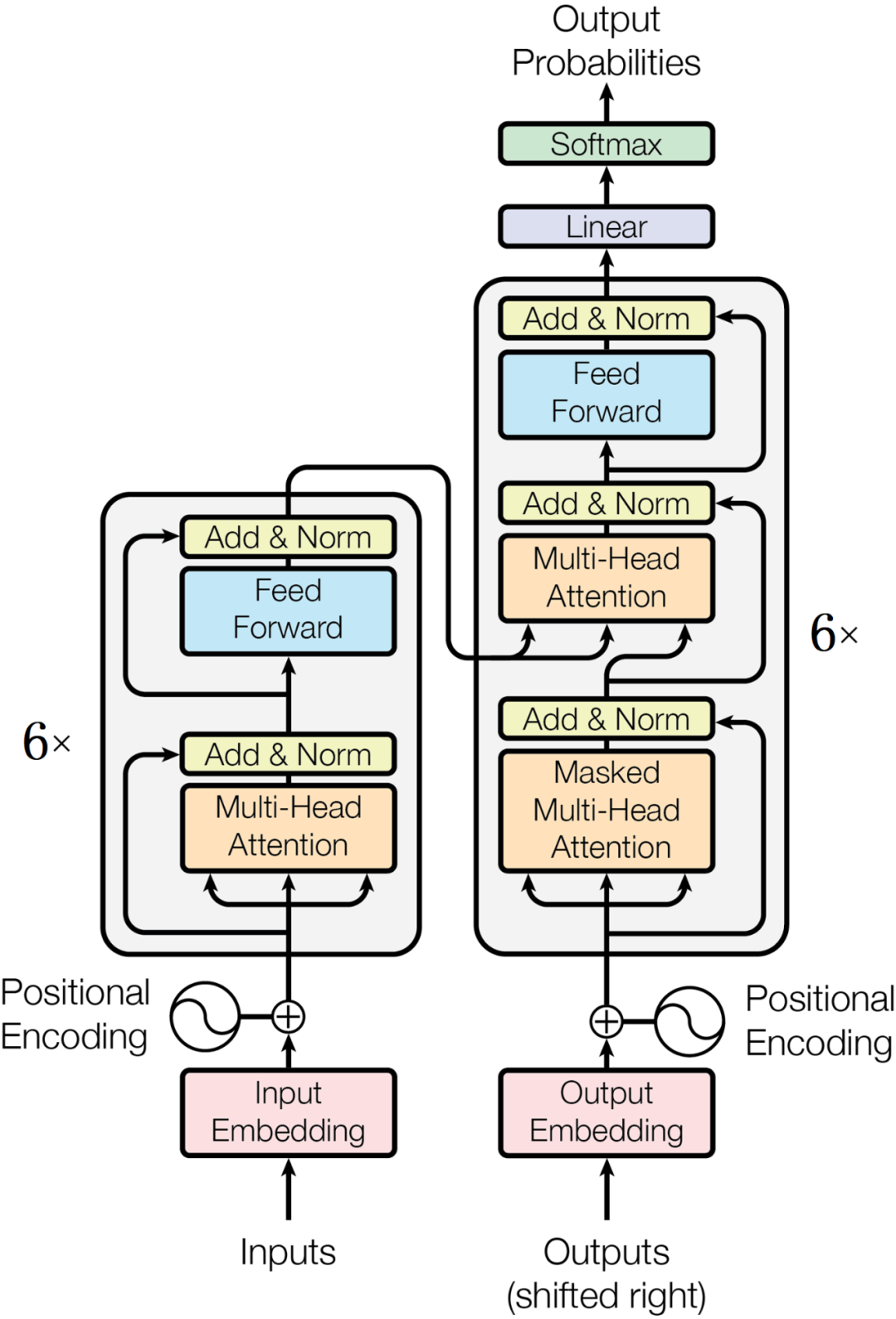
(Transformer模型的整体结构[5])
现有实验表明,注意力机制不仅能够捕捉到距离较远的相关信息,大幅提高模型的性能,还能提供额外的解释性[7]:
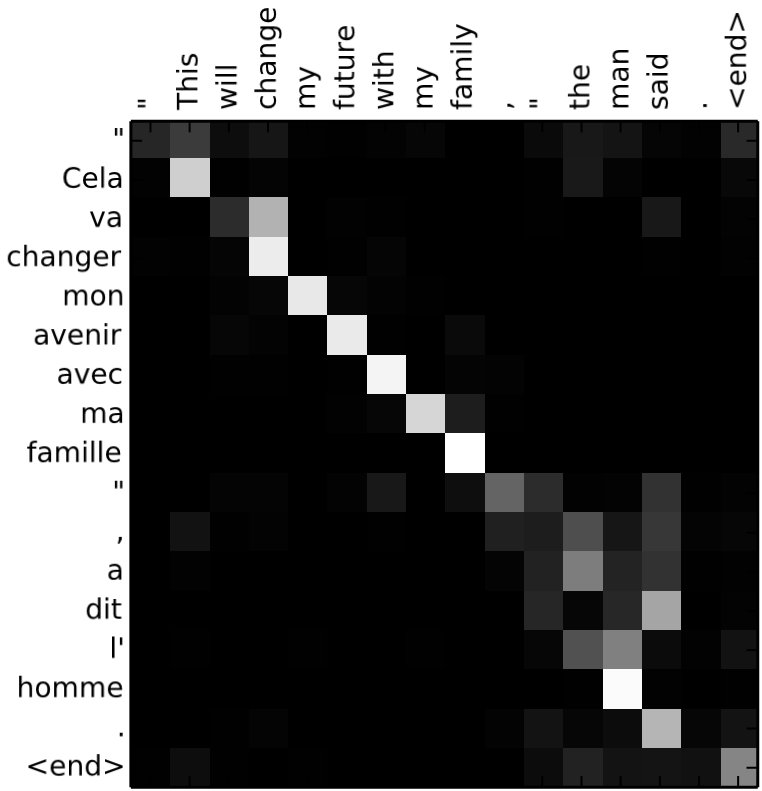
(机器翻译任务中,注意力机制的可解释性[7])
这种可解释性对于信息安全领域来说至关重要。如果模型作出误判,依靠注意力机制的可解释性,我们就能确定是告警载荷中的哪些部分导致了误判,从而针对性地补充训练样本或调整模型。
受限于主题和篇幅,本文不详细介绍更多模型实现细节。
五、后记
由此看来,告警载荷摘要生成任务,从原理上应该是可行的。人类专家显然能够完成这项任务;机器学习领域也已经有非常成熟的算法模型来解决非常相似的问题,也具有充分的可解释性以应对信息安全工作中的决策需要。
不过如果具体到告警评估场景中,目前还有包括词嵌入、序列嵌入、性能优化、标注规范制订等很多问题需要解决。要真正地在实时告警评估工作中使用它,依然还有漫长的路要走。
更多前沿资讯,还请继续关注绿盟科技研究通讯。
如果您发现文中描述有不当之处,还请留言指出。在此致以真诚的感谢~
参考文献
[1] Louis Teo. Report is too long toread? Use NLP to create a summary[EB/OL]. [2020-10-29].https://towardsdatascience.com/report-is-too-long-to-read-use-nlp-to-create-a-summary-6f5f7801d355.
[2] Wikipedia.Seq2seq[EB/OL]. [2021-03-27]. https://en.wikipedia.org/wiki/Seq2seq.
[3] ChristianVersloot. From vanilla RNNs to Transformers: a history of Seq2Seqlearning[EB/OL]. [2020-12-29].https://www.machinecurve.com/index.php/2020/12/21/from-vanilla-rnns-to-transformers-a-history-of-seq2seq-learning/.
[4] 白裳. 完全解析RNN, Seq2Seq, Attention注意力机制[EB/OL].[2018-12-12]. https://zhuanlan.zhihu.com/p/51383402?edition=yidianzixun.
[5]Vaswani, Ashish, Shazeer N, et al.Attention Is All You Need[J]. Proceedings of the 31st International Conferenceon Neural Information Processing Systems, 2017, 30:5998-6008.
[6] Devlin, Jacob, Chang M, et al. BERT:Pre-Training of Deep Bidirectional Transformers for Language Understanding.[J].In Proceedings of the 2019 Conference of the North American Chapter of theAssociation for Computational Linguistics: Human Language Technologies, 2018,1.
[7] Bahdanau D , Cho K , Bengio Y . Neural MachineTranslation by Jointly Learning to Align and Translate[J]. Computer Science,2014.
声明:本文来自绿盟科技研究通讯,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
