安全态势感知模型
随着网络规模和复杂性不断增大,新型高级入侵攻击手段不断涌现,传统的网络安全方案力不从心,单点检测和防护技术很难应对复杂的安全问题,网络安全人员的关注点也从单个安全问题的解决,发展到研究整个网络的安全状态及其变化趋势。
安全态势感知就是获取影响网络安全的诸多要素,进行多维度综合理解、评估,并预测未来的发展趋势,态势感知已经成为网络安全2.0时代安全技术的焦点,对保障网络安全起着非常重要的作用。
安全态势感知的概念由来已久,早在1995年,前美国空军首席科学家Mica R. Endsley就建立了态势感知的经典模型,其核心内容包括:态势要素获取、态势理解和态势预测,如下图所示。
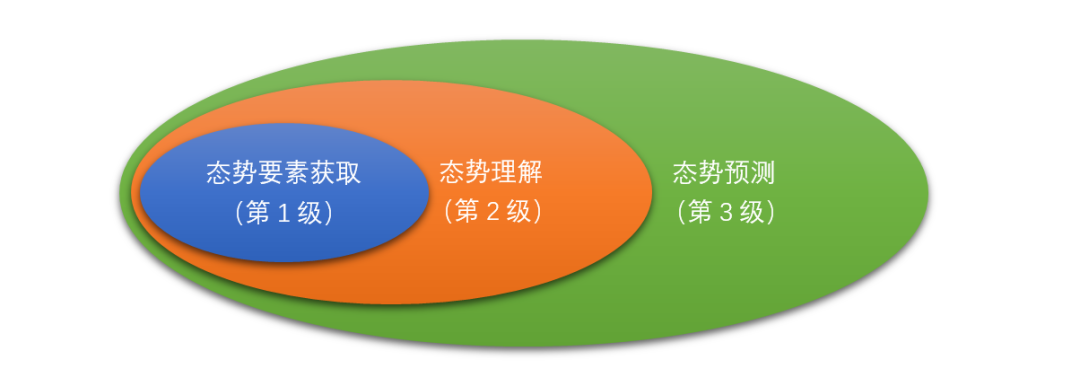
态势要素获取(第1级):提取环境中态势要素的位置和特征等信息;
态势理解(第2级):关注信息融合以及信息与预想目标之间的联系;
态势预测(第3级):主要预测未来的态势演化趋势以及可能发生的安全事件。
根据正在讨论的国标《信息安全技术 网络安全态势感知通用技术要求(征求意见稿)》,安全态势感知系统主要划分为数据汇聚层、数据分析层、态势展示层和监测预警层,具体框图如下所示:
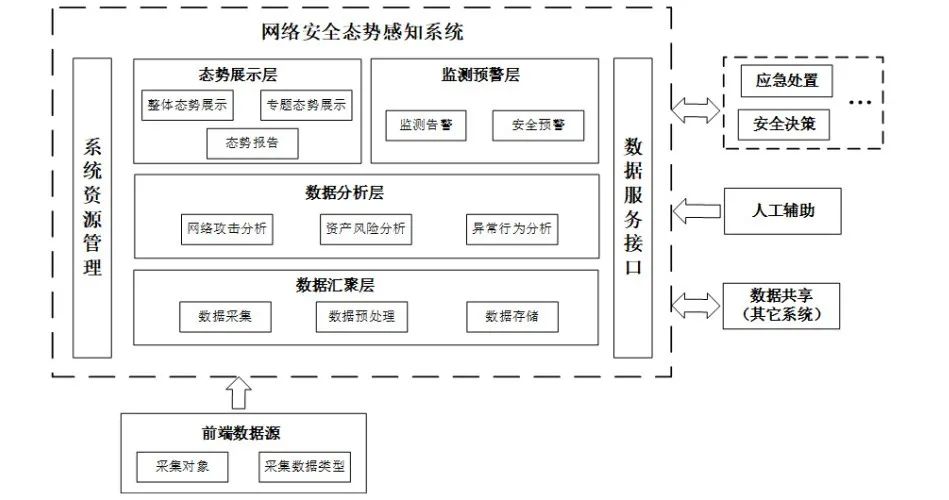
数据汇聚层包括数据采集、数据预处理和数据存储,对应Endsley模型中的态势要素获取。
数据分析层包括网络攻击分析、异常行为分析和资产风险分析,对应Endsley模型中的态势理解。
态势展示层包括整体态势展示、专题态势展示和态势报告,是态势理解的可视化展示。
监测预警层包括监测告警和安全预警,对应Endsley模型中的态势预测。
总体来看,安全态势感知系统本质就是一个大数据分析系统,通过对海量数据的智能分析,理解网络的当前安全状态,预测网络的未来安全状态。数据汇聚层负责采集原始数据并进行预处理和存储,这部分功能决定了数据的质量,也是大数据分析的基础,数据质量决定分析质量,本文主要讨论数据预处理的相关技术。
数据预处理
安全态势感知系统通过各种方式、采用多种协议、从多种设备采集到各种数据,采集数据类型包括但不限于网络流量、资产信息、日志、漏洞信息、用户行为、威胁信息等数据。这些多源异构数据必须经过预处理才能进入后续的分析环节。
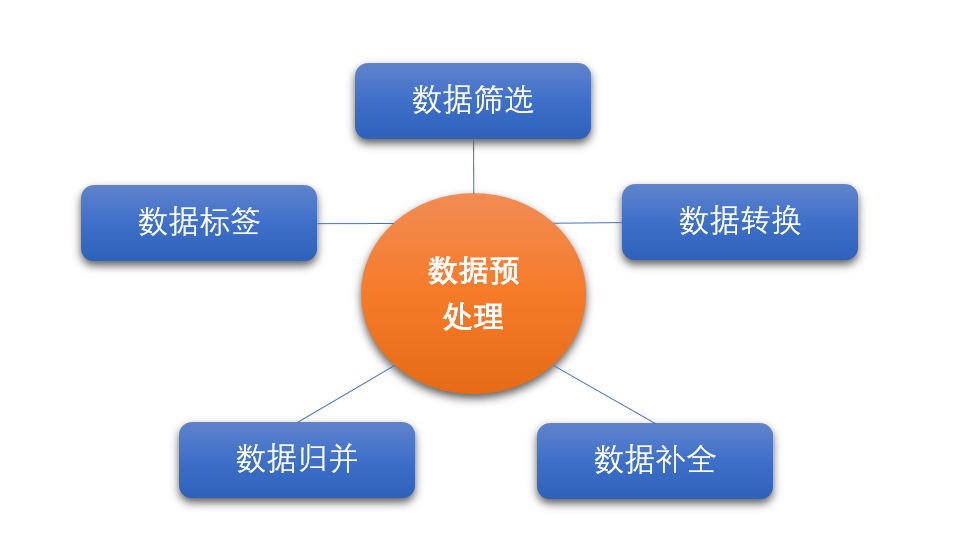
传统的数据预处理的内容一般包括:
数据筛选
即基于既定策略(如必填字段缺失、重要字段格式错误、重复数据等)对采集的原始数据进行筛选,丢弃无效垃圾数据,确保数据质量。
数据转换
即将采集的同一类型、不同格式的原始数据转换为统一的数据格式,且转换时不能造成关键数据项的丢失和损坏,如统一时间格式、统一漏洞名称等。数据转换保证后续处理过程中的数据一致性性和概念一致性。
数据归并
即对采集的原始数据进行同类项合并,如对同一事件的多次告警进行归并,对同一会话的日志进行归并等。数据归并能大幅减少数据量,同时又不影响数据质量。
数据补全
即基于资产库、威胁信息库、地理信息库等对采集的原始数据进行补全,补全的内容可包括资产属性、关联事件、地理位置等。数据补全能提供更完整的数据信息,通过数据冗余的方式,减少关联查询的性能消耗,更有利于后续的数据分析。
数据标签
即根据数据字段对采集的原始数据进行标签化处理,标签内容应基于分析需求进行设置,具体可包括数据可信度、重要程度、数据来源、区域、行业等。数据标签能丰富数据的内容,根据已有的数据知识做初步的判断,并和原始数据绑定在一起,进入后续的数据分析阶段。
经过上述的数据预处理,我们就得到了一个规范、精炼、完整、内容丰富的数据集,这样的数据集可以比较好的支持多个维度的统计分析。
近年来,机器学习技术得到快速发展和应用,在安全态势感知系统中也有丰富的应用案例和场景。对于机器学习来讲,这样的数据集属于原始数据集,还不能直接用于机器学习算法。要在态势感知系统中引入机器学习模型和算法,还需要对这些原始数据进行特殊处理,也就是机器学习领域最重要的特征工程。
特征工程
Coming up with features is difficult,time-consuming,requires expert knowledge. “Applied machine learning” is basicallyfeature engineering. ——Andrew Ng(吴恩达)
吴恩达认为:“应用机器学习”本质上就是在做特征工程(Feature Engineering)。特征工程是机器学习的必备过程,需要大量专业知识,而不是简单地把数据扔给机器就可以学习了。数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
数据预处理、特征工程以及机器学习的逻辑关系如下图所示。
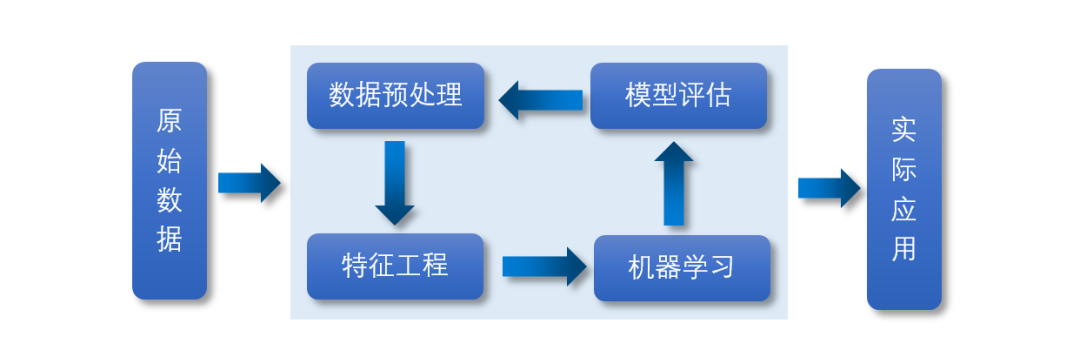
特征工程,顾名思义就是最大限度地从原始数据中构建事务的特征以供算法和模型使用的一项工程活动。构造特征是一个严重依赖经验的过程,需要对业务有深入的理解。对业务理解的越深入,越能抓住数据的重点构建合适的特征,越能帮助机器学习算法进行更有效的学习和判断。
特征越好,数据分析的灵活性越强,机器学习就可以选择相对简单的模型,运行速度更快,也更容易理解和维护,不需要花大量时间调参和优化就可以取得很好的效果。
下面举两个实际的例子来说明特征构建。
问题一,根据一个人的身高和体重,判断此人是否肥胖。身高和体重是2个主要的原始数据,但是直接根据这两个数据很难判断胖瘦。针对这个问题,一个非常经典的特征工程是,构建BMI指数作为特征,BMI=体重/(身高^2),其中体重使用公斤为单位,身高使用米为单位。这样,通过BMI指数,就能非常显然地帮助我们,刻画一个人身材如何。甚至,你可以抛弃原始的体重和身高数据。
问题二,根据用户登录信息,判断是否异常登录。一般登录信息包括用户名、登录时间、登录IP、登录结果(成功/失败),这些维度的数据可以用来识别一些常见的异常登录,比如多次登录失败。如果对安全登录有更深的理解,就可能构造一些其他特征,比如:是否工作时间登录、登录失败时间间隔、连续失败次数、登录IP地域信息等,这样就能从更多的维度描述登录过程,能更有效的识别异常登录。
所以特征构建的主要目的是基于原始数据集,构造适合机器学习的特征数据,并且这些数据要和业务需求紧密相关。
那么什么样的数据适合机器学习?答案是标准化和归一化的数据。
比如前面例子中的登录时间,如果是具体的时间,最常用的就是精确到秒的时间,这些数据的差别可能非常大,但是如果转换为是否工作时间,那就是0或者1,极大的简化了时间特征,这种属于定量特征二值化的处理方法。
归一化方法即把大范围的数据转换为同一量纲,把数据映射到[0,1]或者[a,b],这样所有的数据都位于一个区间范围,更具有可比性。归一化方法是特征工程常用的一种处理方法。
其他还有很多特征数据处理方法,这些常用的处理方法都已经在Python的sklearn.preprocessing库中有完整的实现,可以直接使用。
经过特征工程处理后的数据,就应该是标准化和归一化的数据,这些数据一般可以使用矩阵向量(或矢量)表示,也称为特征向量(或矢量),方便计算机的算法处理。
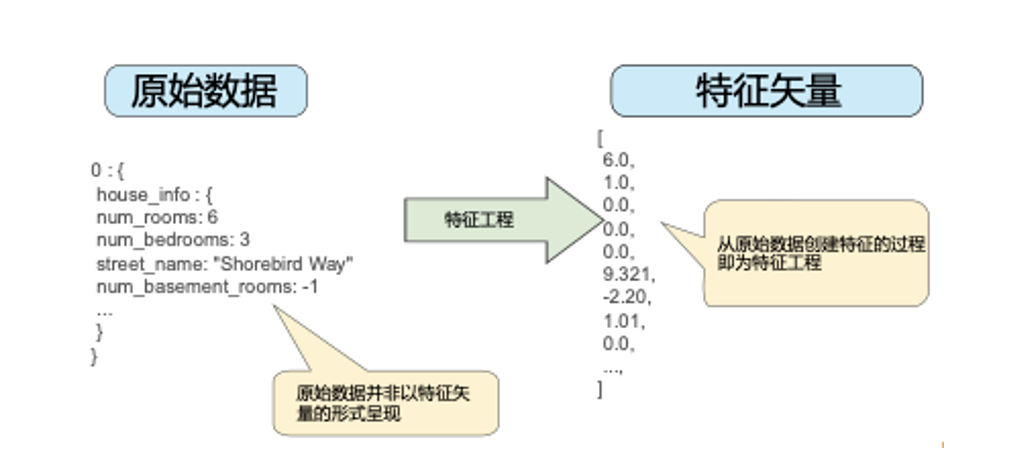
下面我们再回到本文的主题,看看在安全态势感知领域,特征工程主要涉及哪些内容。
网络安全特征集
分析网络安全,最重要的数据就是原始流量报文,所有的网络扫描、渗透和攻击,都必然要通过网络报文来实现。所以,流量报文数据就是我们的原始数据集。
网络安全涉及的范围非常宽泛,针对不同的问题,需要做不同的特征选择和处理。比如,研究网络层的攻击,就需要针对TCP/IP的头部信息、分片信息等进行细粒度的分析处理,建立特征;研究HTTP应用层攻击,就需要针对HTTP的头部信息、内容信息等进行细粒度的分析处理,建立特征;研究工控系统的网络攻击,就需要针对工控协议进行深度解析,对命令码、参数变量等进行细粒度的分析处理,建立特征。
针对通用的网络入侵攻击,业界早已出现标准的数据集和其特征集。
KDD99数据集是最早最出名的网络安全数据集,是由MIT利用TCPdump收集了9周时间的网络连接和系统审计数据,仿真各种用户类型、各种不同的网络流量和攻击手段形成的数据样本。这些样本分别被标记为正常(normal)或异常(attack),被广泛用来测试各种入侵检测以及类型算法的验证实验集。哥伦比亚大学的Sal Stolfo 教授和来自北卡罗莱纳州立大学的 Wenke Lee 教授采用数据挖掘等技术对以上的数据集进行数据预处理和特征分析,形成了一个新的数据集即特征集。
KDD99数据集获取方式:https://www.ll.mit.edu/ideval/data/1999data.html
下面我们来分析一下这些经过处理后的特征集,特征集共分为4大类41个特征,这些特征的具体说明详见下列各表:
表 1基于独立TCP连接基础的特征集
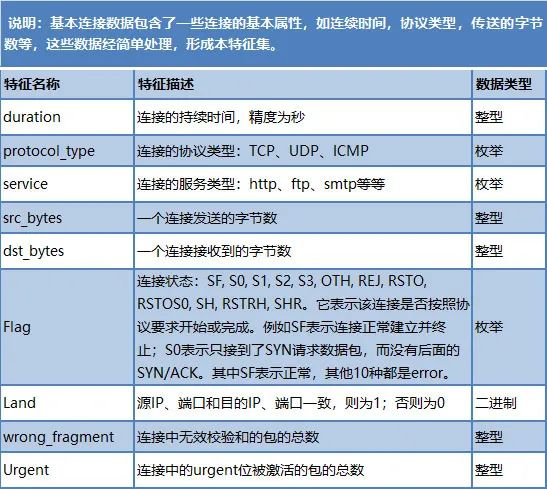
表 2基于安全专业知识的特征集
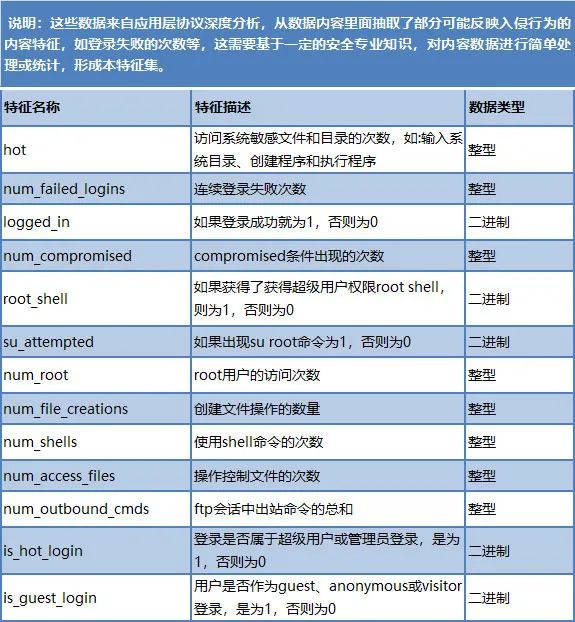
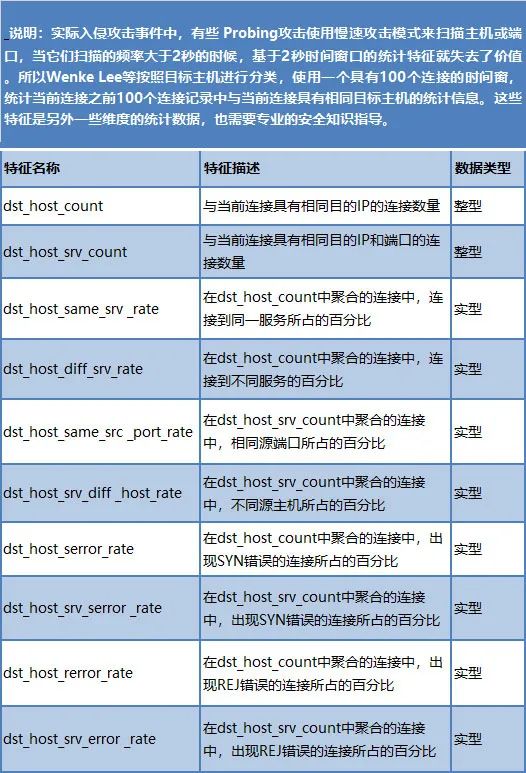
表 3基于2秒时间窗口的统计特征集
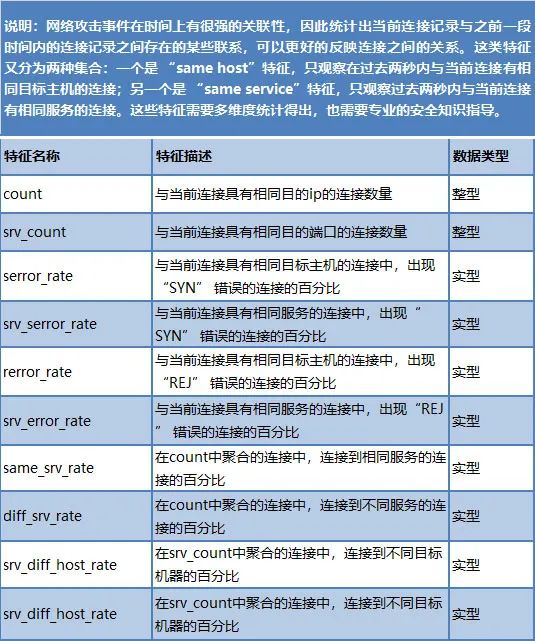
表 4基于100个连接窗口的统计特征集
通过上述分析,可以看到网络安全相关的特征工程,主要从几个方面入手:
1、网络层连接的基本属性,包括连接时长、IP端口、Flag标志等,除了KDD99特征集中的特征,还可以考虑报文长度、滑动窗口尺寸、分片数量、分片大小等诸多维度的特征,并进一步基于这些特征做方差、均值等计算,得到一些新的特征。
2、应用层和安全相关的属性,这要结合具体的业务应用和应用层协议进行具体分析,KDD99特征集主要对远程登录相关的数据抽取特征,如果你的应用涉及其他业务,应该从你的业务出发构建特征,比如要识别SQL注入,就需要解析到SQL语句,对字符串中的information_schema、information_schema.table、select、from、where等关键词进行特征抽取;要识别XSS攻击,就需要解析HTTP协议,对提交的内容中的javascript、alert、onerror=等特征进行抽取。对工业控制系统的特征构建,需要针对工控协议中的每个指令码建立特征,尤其是那些高危指令,需要专门进行统计建立统计特征。
3、基于时间窗口的统计特征,这部分可以参考KDD99的2秒时间窗统计特征集,也需要结合具体的网络业务做进一步的分析,比如要识别CC攻击,就需要对连接的特殊URL进行统计建立特征。
4、时间窗口的特征无法准确表达慢连接攻击或者APT攻击,KDD99中使用最近的100个连接进行统计分析,我们在实际应用中,还可以进一步细分,比如针对同一目的IP、针对同一源IP分别进行统计建立特征集。
另外,CICIDS2017数据集则是目前较新的网络安全数据集,由Canadian Institute for Cybersecurity采集发布,格式类似于kdd99,其特征集包含81个特征,具有更丰富的特征数据,可能检测识别更多类型的异常情况,有兴趣的同学可以自行进行研究。
CICIDS2017数据集获取方式:http://www.unb.ca/cic/datasets/ids-2017.html
总 结
网络安全态势感知系统,本质是一个大数据分析系统。近年来随着机器学习的广泛应用,越来越多的安全态势感知系统开始使用机器学习进行数据分析和态势预测。应用机器学习的重要环节就是特征工程,特征工程做不好,机器学习学不好。
特征工程是数据分析中最耗时间和精力的一部分工作,它不像算法和模型那样是确定的步骤,更多是工程上的经验和权衡,也没有统一的方法。
要做好特征工程,首先需要找到该领域懂业务的专家,或者借鉴领域专家的经验继续优化。安全态势感知系统在使用机器学习前,必须依靠安全专家结合各自领域的具体业务,对数据进行特征提取和构建,只有贴合业务的特征才能起到更好的表达效果,才能更好地利用机器学习理解态势、预测态势。
声明:本文来自威努特工控安全,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
