原文作者:Ronak Razavisousan, Karuna P. Joshi
原文标题:Analyzing GDPR compliance in Cloud Services" privacy policies using Textual Fuzzy Interpretive Structural Modeling (TFISM)原文链接:https://ebiquity.umbc.edu/paper/html/id/989/Analyzing-GDPR-compliance-in-Cloud-Services-privacy-policies-using-Textual-Fuzzy-Interpretive-Structural-Modeling-TFISM-原文来源:IEEE International Services Computing Conference (SCC) 2021笔记作者:2rrrr@SecQuan文章小编:ourren
介绍
大多数的服务提供商都会收集一些用户数据,GDPR(通用数据保护法规)就是一项规定了个人隐私数据保护的相关法律。所有服务提供商必须遵守规定,在其服务的隐私政策中加以说明。这些隐私政策一般是公开的,描述提供商如何收集、使用、管理或共享数据,同时隐私政策也使服务提供商更容易与其他公司或第三方合作。然而,这些隐私政策通常难以被机器所解释,对用户来说则是一篇包含了许多复杂法律术语的文本文档。目前需要法律专家进行大量的人工分析,才能确定服务隐私政策对数据保护法规的遵守程度。因此,作者对如何使用机器自动化分析隐私政策文本进行了研究。
方法
作者开发了TFISM(文本模糊解释结构模型)的分析方法,以识别文本数据集中的影响因素,确定每个因素的优先级,并确定这些因素之间的联系和层次。该方法扩展了模糊ISM,将文本数据作为输入数据,建立一个不依赖于任何先验知识或人类直觉的决策模型。总体的架构分为4个部分,如下所示。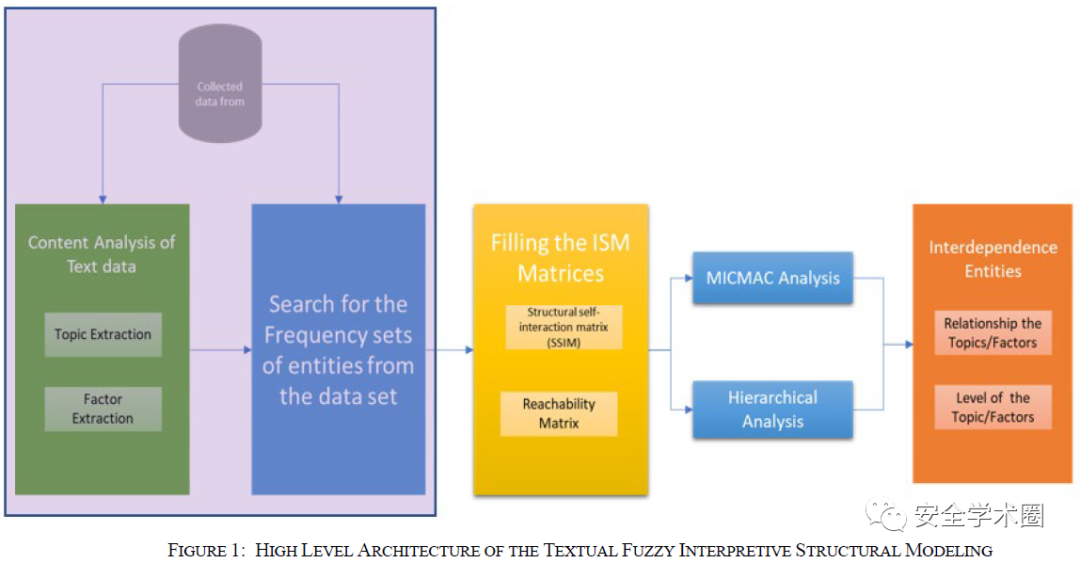
因素确定:第一步需要去确定数据集中各种因素和变量的具有的强度和代表的角色。在因素不易识别的情况下,可以使用领域专家帮助下的主题提取等技术来识别。
填充ISM矩阵:ISM中一个重要的概念是结构自交互矩阵,它表示了变量之间的成对关系,不同类型的关系表示为A、O、V和X;TFISM中,以表示出现频率的数字来代替关系类型。对于识别出的每两组因素,会通过搜素匹配的方式确定在矩阵中的邻接关系。

MICMAC分析和多层次分析:MICMAC用于评估基于驱动力和依赖性的重要因素之间的关系强度,通过在系统的完整视图中可视化变量之间的关系对ISM进行补充。层次分析是ISM方法的一部分,作者将ISM中使用自然数的过程替换为实数来进行优化。
结果解释:分析第三步得到的结果,确定数据集中每个因素的强度水平和因素之间的关系。
实验
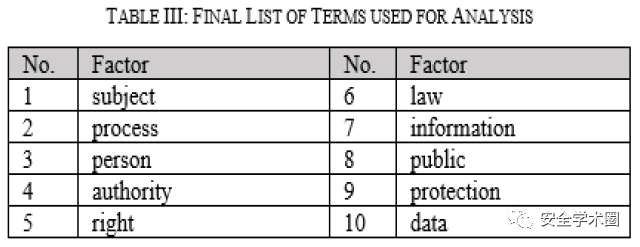
确定隐私政策的相关因素。例如,医疗领域的数据隐私具有不可忽视的作用,是一个相关因素;而对于科学数据集,如天气预报,隐私可能不是一个相关因素。对于同一领域,根据研究的角度的不同,TFISM中考虑的影响因素可能不同。作者从GDPR文档的章节和小节中提取了高频术语和短语,并将LDA应用于文档,提取高频出现的主题关键词,并经过专家筛选后,最终得到10个常用术语。
服务提供商的选择。作者收集了包括具有网上业务的零售公司、具有在线服务的娱乐公司、互联网和网络服务公司以及政府服务公司的隐私政策,收集众多公司的隐私政策能够同一领域下的公司进行研究和对比。最终作者收集到了224个不同服务提供商的隐私政策文档建立语料库。
数据源的对比。除了隐私政策文档外,作者将GDPR文件作为事实参考,通过两种方式设计实验:1)将224个隐私政策文档合并,与GDPR文件进行对比;2)将每个隐私政策文档单独分析,与GDPR文件对比,论文中作者以亚马逊和沃尔玛为例进行实验。
合并的隐私政策和GDPR对比
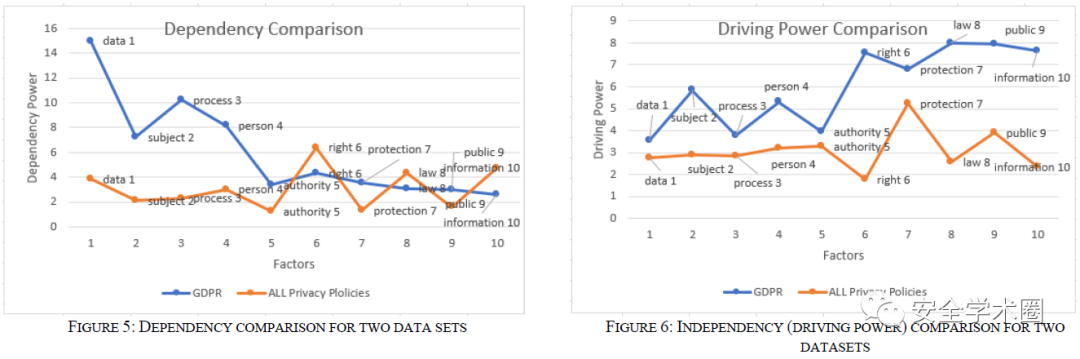
亚马逊与沃尔玛的隐私政策和GDPR对比
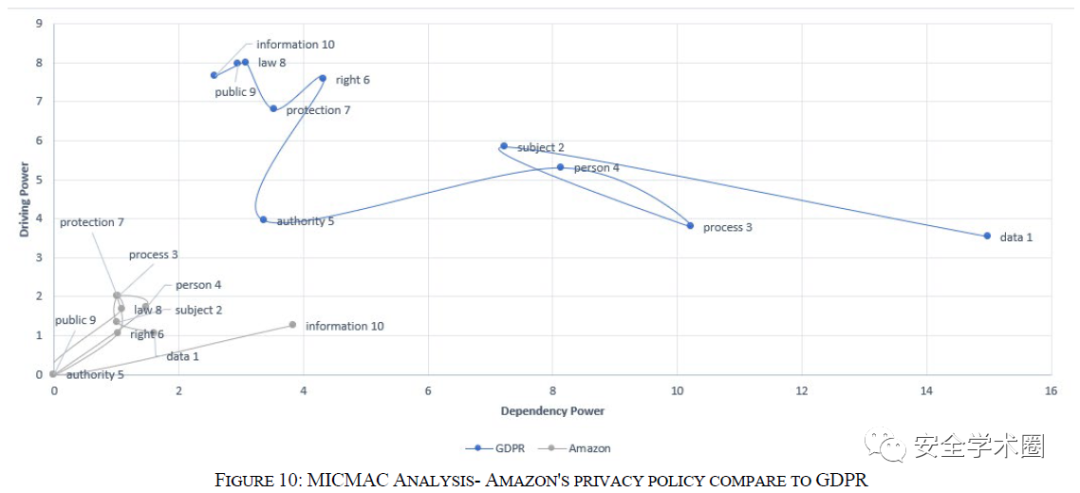
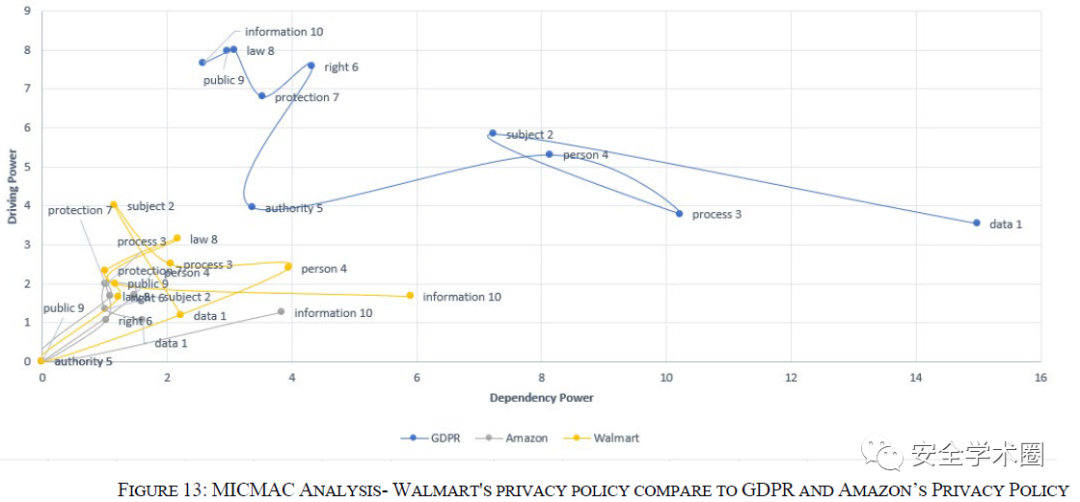
从实验结果可以看到,合并的隐私政策分析结果相比于两家公司的单独分析结果,与GDPR有着更高的相似性,这可能是因为所选择的224份隐私政策来自不同领域的公司,因此它们能够涵盖隐私政策的不同方面。可以得出结论,公司的所属行业领域对于隐私政策的覆盖和评估GDPR与隐私政策之间的相似性有着很大影响,因此公司自身如果存在细分的多个领域则可能会改善隐私政策的覆盖范围。
安全学术圈招募队友-ing, 有兴趣加入学术圈的请联系secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
