
针对机器学习分类器的攻击概览
原文:https://elie.net/blog/ai/attacks-against-machine-learning-an-overview
编译:plus评论员 张涛
本文描述针对AI系统的攻击技术和针对AI攻击的防护。总的来说,针对分类器的攻击可以分为三类:对抗输入、数据投毒攻击、模型窃取(model stealing)技术。
对抗输入。对抗输入是为了让分类器的分类结果不可靠来避免被检测的经过特殊构造的输入。对抗输入包括专门用来避免被反病毒软件检测的恶意文档和避免不被垃圾邮件过滤器过滤的邮件。
数据投毒攻击。数据投毒攻击是指给分类器的训练样本中加入对抗数据。最常见的攻击类型是模型倾斜(model skewing),攻击者会尝试污染训练数据,达到改变分类器的分类边界的目的。第二种攻击类型是反馈武器化(feedback weaponization),攻击者会滥用反馈机制来操纵系统使其将善意的内容错误分类为恶意的内容。
模型窃取技术。模型窃取技术是指通过黑盒探测来窃取模型或者恢复训练数据成员,比如窃取股票市场预测模型和垃圾邮件过滤模型,攻击者利用该技术可以针对性地有效地优化攻击模型。
本文将分析这些攻击类型,并提供具体的攻击实例和一些可能的缓解技术。
一、对抗输入
攻击者会经常性地去用新的输入或payload来试探分类器,并尝试避免被检测到。这样的payload叫做对抗性输入,因为这些payload设计的目的就是为了绕过分类器。
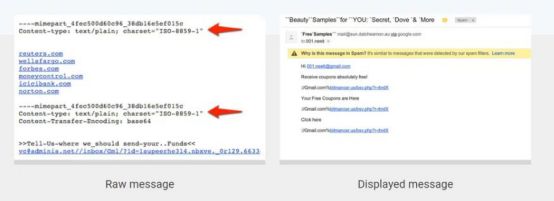
下面以Gmail垃圾邮件分类器对抗性输入为例进行说明:
一个聪明的垃圾邮件发送者会意识到如果同样的多部分附件在一个邮件中多次出现,那么Gmail只会展示最后一个附件(见上图)。研究人员通过增加不可见的第一多部分附件将该知识武器化,第一多部分附件中含有许多声誉(信用)比较好的域名来达到避免检测的目的。该攻击是关键字堆积攻击的一个变种。
总的来说,分类器面临两种类型的对抗输入:mutated input(突变输入)和zero-day input(0 day输入)。Mutated input是一种避免被分类器识别的攻击变种,zero-day input是指之前从未见过的payload。
Mutated input(突变输入)
过去这些年在地下市场有很多向网络犯罪分子提供避免被检测到的payload的服务。这些服务涵盖测试服务和自动化packer,测试服务可以测试payload是否可以通过反病毒软件的检测,自动化packer可以混淆恶意文档使其不被检测到。
因此,开发一个输入的检测系统是非常有必要的,这样的话攻击者再进行payload优化就很难了。下面是3个重要的设计策略:
1、 限制信息泄露

限制信息泄露的目的是确保攻击者在探测系统时获取尽可能少的反馈。因此,尽可能少的反馈信息就很重要,比如避免返回详细的错误代码或值。
2、 限制探测
限制探测的目的是通过限制攻击者的payload探测系统的频率来限制攻击者对系统的探测。通过限制payload探测系统的频率可以减缓攻击者设计出有害payload的速度。

该策略主要是通过对IP、账号等稀缺资源的限制来实现的。一个经典例子就是如果用户频繁发帖就让用户识别并输入一个验证码。
这种速率限制的负面效应是攻击者可能会创建虚假账号、使用被黑的用户计算机来多样化其IP池。速率限制在各行各业的广泛应用也是黑市论坛上账号和IP地址售卖的一个主要驱动力。
3、集成学习(Ensemble learning)
还有一点很重要的就是集成学习,将不同的检测机制融合在一起,这会让攻击者很难绕过整个系统的检测。使用集成学习可以融合AI分类器、检测规则、异常检测等不同类型的检测模型,可以改善系统的鲁棒性,因为攻击者必须设计出可以一次性绕过所有机制的payload,但又很难成功。
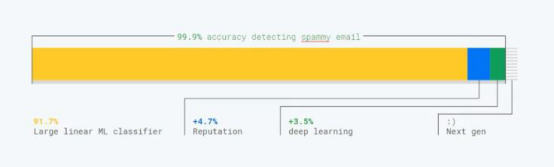
为了确保Gmail分类器对垃圾邮件的分类鲁棒性,Google的研究人员就采用了集成学习的方法,融合了多个分类器和辅助系统,包括信用机制、线性分类器、深度学习分类器和其他的技术。
针对深度神经网络的对抗攻击的例子

还有一个非常活跃的领域就是如何伪造对抗样本来欺骗深度神经网络。如论文Explaining and Harnessing Adversarial Examples中就证明了很容易地就可以创建一些样本来欺骗深度神经网络,如上图所示。
最近的研究表明CNN易受到对抗输入攻击,因为CNN会去学习表层数据规律,而不是学习深层的表示。这类攻击会影响所有的深度神经网络,包括基于增强学习的神经网络。
从防护者的角度来看,这类攻击是非常麻烦的,因为还没有一种有效的方法来预防此类攻击,没有一种有效的方式来了解深度神经网络如何生成善意的输出。
0 day输入
另一种对抗输入就是0 day输入,这对分类器来说说一种全新的攻击方式。新的攻击并不经常发生,但了解如何应对是非常重要的。

新的攻击出现经常会有很多不可预测的原因,比如:
新产品或特征的出现。一般来说,增加了新的功能就开启了新的攻击面,攻击者会很快就会发起探测。这也就是为什么要在新产品发布时提供0 day防护的原因。
激励的增加。这是一个很少被提及的话题,许多新的攻击出现都是因为这个攻击单元变得非常盈利。比如,2017年因为比特币价格的激增,许多攻击者滥用云服务来进行加密货币挖矿。当比特币的价格超过1万美元时,出现了窃取Google云计算资源来进行挖矿的攻击方式。
总的来说,Nassim Taleb的黑天鹅理论可以应用到基于AI的防御中来:迟早一种不可预测的攻击会绕过分类器,并带来一些影响。
下面是一些应对的方向:
1、 开发应急响应流程
首先要做的就是开发和测试应急响应的流程来确保能够第一时间正确地做出反应。这包括但不限于当调试分类器时要有必要的控制措施来延迟或者终止处理过程。Google的SRE(Site Reliability Engineering)手册、NIST的cybersecurity event recovery指南都可以作为参考。
2、 用迁移学习来保护新产品
一个明显的难题是你没有过去的数据来训练分类器。其中一个解决的办法就是使用迁移学习,迁移学习可以从一个域中重用已有的数据并应用到其他领域中。
比如,你在处理图像问题时可以用已有的预训练的模型,那么当你要处理文本时,就可以使用Jigsaw这样的公共数据集。
3、 异常检测
异常检测算法可以被用作防御的第一步,因为新的攻击在利用系统的漏洞时会产生一些从未见出现过的异常。
当比特币的价格2017年疯涨的时候,我们发现一些恶意的攻击者使用免费的Google云服务来进行挖矿。为了使用免费的云服务,攻击者尝试窃取信用卡、黑掉合法云用户的计算机、通过钓鱼等方式劫持云用户的账户等方式来发起攻击。
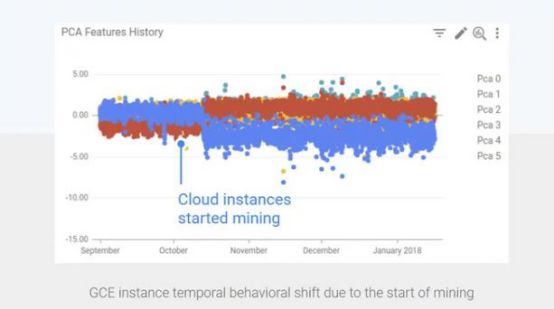
Google的工程师在Google云实例上部署了异常检测系统。上图就是异常检测系统的图示。当攻击者利用云资源进行挖矿时,相关的资源利用率与正常的资源利用率相比变化非常大,异常系统很快就可以检测出这类异常。
二、数据投毒攻击
分类器面临的第二类攻击就是尝试通过污染数据,让系统做出错误的行为。
模型倾斜
第一类数据投毒攻击叫做模型倾斜(model skewing),在攻击中攻击者会尝试污染训练数据,使分类器识别善意的输入和恶意输入的边界发生变化。比如,模型倾斜可以用来污染训练数据来欺骗分配器将特定的恶意文件标记为善意的。
具体实例
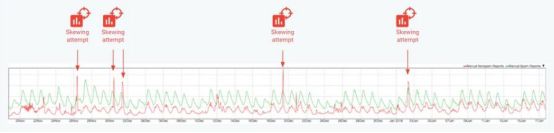
在实践中,研究人员经常会发现一些高级的垃圾邮件发送群组尝试通过将一些垃圾邮件报告(反馈)为非垃圾邮件来让Gmail过滤器不再记录该垃圾邮件。如图所示,2017年11月到2018年初,至少有4次针对分类器的大规模攻击。
这样,在设计基于AI的防御机制时,需要考虑如下问题:攻击者会尝试去改变分类器通过学习建立的分类边界。
缓解措施
为了预防攻击者倾斜模型,可以使用下面的三种方法:
使用敏感的数据样本。要确保一小部分的实体(包括用户和IP)不会引起模型训练数据太大比例的变化。尤其是要注意用户反馈的假阳性和假阴性的数据。
比较新训练的分类器和之前的分类器,估计变化的多少。比如,在系统的流量下比较2个模型的输出,或者对流量进行AB测试。
建立黄金数据集,来确保分类器可以精确地预测。理想的数据集应该是策划的攻击内容和正常内容的集合。该过程可以确保当武器化的攻击对模型产生明显变化的时候可以在对用户造成负面影响前检测到。
反馈武器化
数据投毒攻击的另一种方式是将用户的反馈武器化来攻击合法的用户和内容。一旦攻击者意识到你在使用用户反馈,那么他们也会尝试利用用户反馈发起攻击。
示例
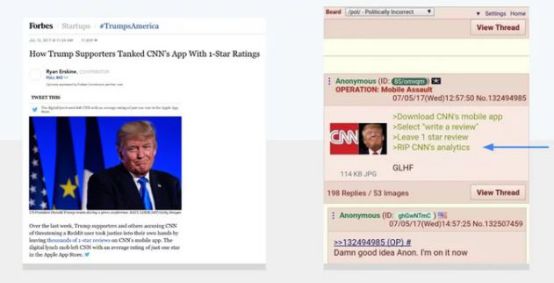
将反馈武器化的一个例子是2017年有组织通过上千个1星评价让CNN应用在苹果应用商店和谷歌官方应用商店中的排名降低。
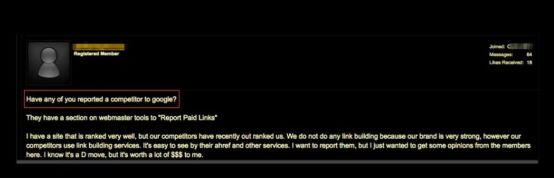
攻击者使用反馈武器化有很多的原因,比如减小竞争、报复等等。上图是黑市上讨论如何利用Google来踢出竞争者。
因此,在建立系统时要有一个假设:所有的反馈机制都可能会被武器化来攻击合法用户和内容。
缓解措施
下面是缓解反馈武器化的2个措施:
不要在反馈机制和惩罚机制之间建立直接关系。确保反馈评价的真实性,并与其他信息结合起来做出最终的决定。
不要假设内容的所有者会从中受益。比如,用户不会因为一张照片有上百个虚假的喜欢就去购买。在现实中,很有时候攻击者会用合法的内容去掩盖踪迹或尝试以此来使一些无辜的人受到处罚。
三、模型窃取(Model-stealing)攻击
最后一种针对机器学习的攻击就是模型窃取攻击,模型窃取攻击时指尝试恢复模型或训练中使用的数据的信息。这样的攻击是一个很重要的顾虑,因为模型是一种非常有价值的知识产权资产,是用公司中最有价值的数据去训练的,比如金融交易、医疗信息、用户交易信息等等。
确保使用用户隐私数据进行训练的模型的安全性是非常重要的,因为这些模型可能会被滥用造成用户敏感信息的泄漏。
攻击
模型窃取攻击主要有两种形式:模型重建和成员泄漏。
模型创建。模型重建的关键是攻击者能够通过探测公有API和限制自己的模型来重建一个模型。论文Stealing Machine Learning Models via Prediction APIs中证明了此类攻击对包含SVM、随机森林、深度神经网络在内的大多数AI算法都是有效的。
成员泄漏。黑客可以通过建立影子模型的方式来决定用哪些记录来训练模型。这样的攻击虽然不需要恢复模型,但会泄漏敏感信息。
防御
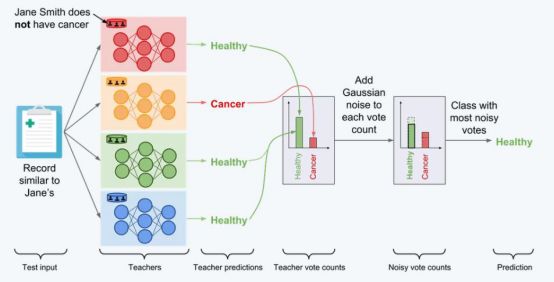
针对模型窃取攻击,最好的防御措施就是PATE,这是Ian Goodfellow等人提出的一种隐私框架,详见论文Scalable Private Learning with PATE。如上图所示,PATE的关键思想就是将数据分区并训练多个模型,最后根据多个模型的结果去作决策。最后的决策也可能会被其他差分隐私系统这样的噪声所欺骗。
四、结论
AI是建立保护机制和对抗复杂攻击的关键因素。目前,有很多的AI框架都很成熟,这正是应该将AI应用到防御系统的最佳时刻。
声明:本文来自学术plus,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
