原文作者:Lavanya Elluri,Karuna Pande Joshi,Anantaa Kotal
原文标题:Measuring Semantic Similarity across EU GDPR Regulation and Cloud Privacy Policies原文链接:https://ieeexplore.ieee.org/abstract/document/9377864原文来源:2020 IEEE International Conference on Big Data (Big Data)笔记作者:CJRTnT@SecQuan文章小编:cherry@SecQuan
摘要
数据保护机构制定了服务提供商在使用用户个人识别信息(Personally Identifiable Information,PII)进行大数据分析时必须遵守的政策和规则,数据法规和隐私政策通常以HTML和PDF格式的短、非结构化文本进行展示,因此需要一种自动化的方法来确定隐私政策中所指向的具体规则。本文实现了一个基于语义的框架,提取和比较短文本策略的上下文以提取语义相似的关键词,同时创建了一个知识图谱来存储语义相似的比较结果。
提出的方法

图1
A.预处理阶段
首先从GDPR中提取语义相似的关键字,取top100,如图2所示;再将原HTML/PDF格式的隐私政策转换为文本文件后,对其使用tokenization,stemming,lemmatization NLP word processing和stop words进行处理,提取出合适的关键词,见B。

图2
B.从隐私政策中确定相似度得分和关键术语提取
将隐私政策与GDPR作比较,使用文本相似度方法(Doc2Vec)确定其相似度分数(以弧度为单位),分数较小代表该隐私政策更符合GDPR法规。
根据从GDPR中提取出的关键术语,再从隐私政策中提取出与其相关的关键字,如图3所示。
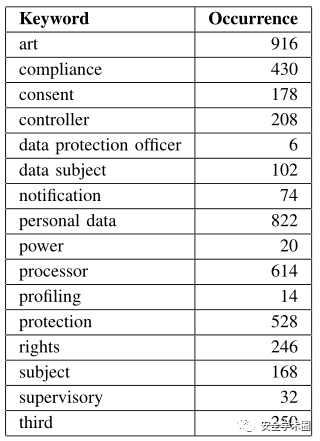
图3
C.Permission & Obligations
本文还提取了某些模式关键字,如“will”、“should”、“could”、“shall”、“must”、“can”等,这些情态动词可以确定这个句子是属于许可(permission)还是义务(obligation)。例如,“could”对应的是“许可”,而“must”对应的是“义务”。
D.Knowledge Graph/Ontology Development
使用Protégé创建知识图谱,对本体的构建如图4所示,该本体捕获了法律法规与隐私政策之间的相似性细节。Regulators代表保护用户数据的法律法规制定者;Consumers代表用户;Providers代表有责任保护消费者隐私的组织。
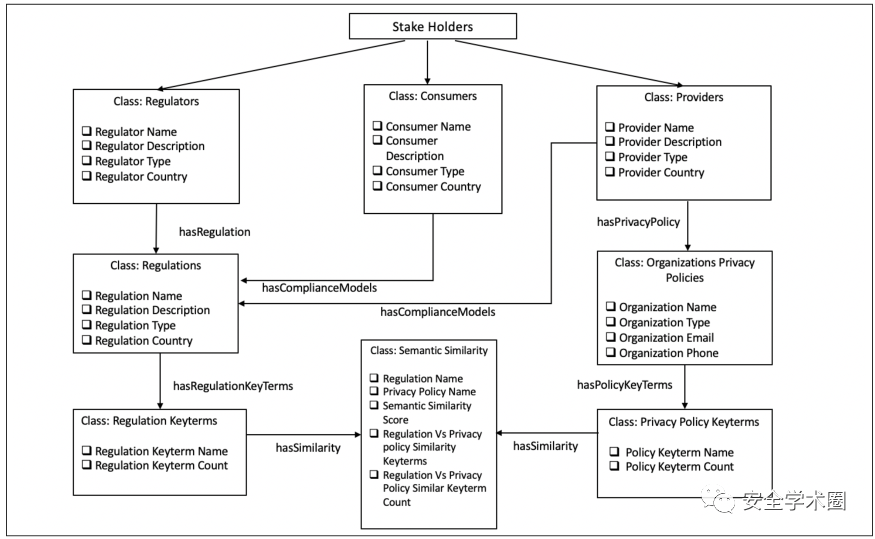
图4
结果
隐私政策中出现类似关键术语的次数与得分成反比——即隐私政策中所含有的语义相似关键字越多,则其相似度得分越低,说明其越符合GDPR法规,如图5所示。这些隐私政策被填充为知识图谱的实例。
通过知识图谱,可以快速检查隐私政策合规性分数,开发者可以据此更新其隐私政策。

图5

声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
