原文作者:Aastha Chowdhary, Madhuparna Bhowmik and Dr. Bhawana Rudra
原文标题:DNS Tunneling Detection using Machine Learning and Cache Miss Properties原文链接:https://ieeexplore.ieee.org/document/9432279/发表会议:2021 5th International Conference on Intelligent Computing and Control Systems (ICICCS)笔记作者:yyp@SecQuan文章小编:cherry@SecQuan
简介
由于DNS是互联网中最关键的基础设施之一,基于其在网络运行中的重要地位,在防护策略中很少过滤DNS数据流量,攻击者可以将信息植入DNS流量中进行通信,而这种通信将很难被检测发现。本文作者提出了两种检测方法:一是使用DNS缓存服务器中的缓存未命中进行判断,二是利用机器学习技术对给定DNS查询进行分类。作者将这两种方法结合起来构建一个DNS隧道攻击检测器,该检测器可以实时通知客户端正在发生的潜在攻击。
方法
作者实现了2种检测器:
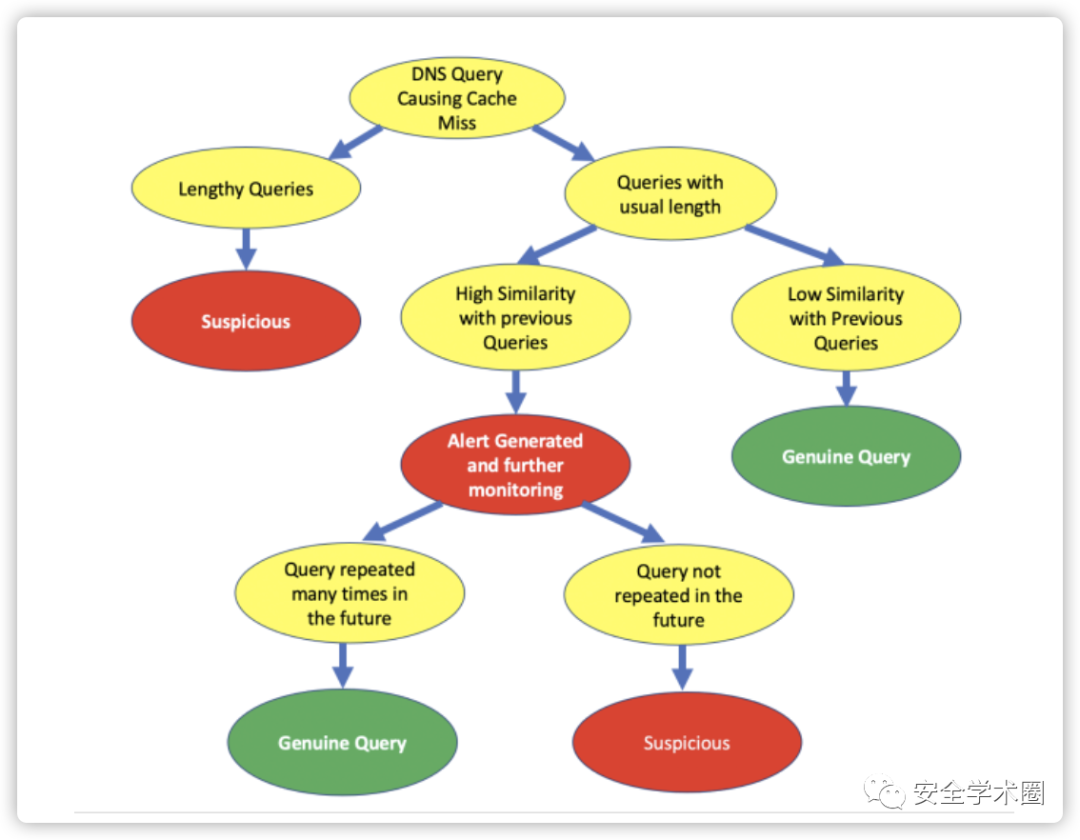
1.基于缓存未命中属性的DNS隧道攻击检测器
攻击者利用DNS隧道进行数据通信,会频繁更改DNS查询中的数据,导致DNS缓存未命中。作者通过此属性来检测潜在的DNS隧道攻击。
2.基于机器学习的DNS隧道攻击检测器
作者选择查询长度和用主机名的熵作为特征,采用了高斯朴素贝叶斯、多项式朴素贝叶斯、伯努利朴素贝叶斯、随机森林、决策树、多层感知器、线性支持向量机、二次支持向量机和K近邻(KNN)等机器学习算法,对比各类算法的性能,并通过组合单独性能最好的模型来尝试多个集成模型。采用最大投票法,通过采用不同模型结果的模式,获得用于制作系综模型的各种模型的组合结果。
数据集
使用的数据集既有正常查询,也有DNS隧道查询。数据集中给出了查询的标签和主机名。训练集有3000个真实查询样本和12000个DNS隧道查询样本,而测试集有11291个真实查询样本和8709个DNS隧道查询样本。由于这些主机名不能直接输入分类器,因此它们被转换为基于主机名中存在的字符计算的熵值。然后将这些熵值存储并作为特征输入到各种分类器中。示例数据集如图2所示,其中0表示真正的查询,1表示DNS隧道查询。通过使用短主机名的真实查询和使用随机值和更长主机名的DNS隧道查询,可以清楚地看到主机名之间的差异。因此,主机名的熵是区分真实查询和DNS隧道查询的一个很好的特性。
数据集地址:https://github.com/netrack/learn/tree/master/dns
工具
作者基于python的scapy包实现了一个可以连续嗅探所有DNS数据包、检测DNS隧道查询并通知用户的工具,并提取查询及其大小等重要字段,计算查询主机名的熵。然后,每个查询通过两个过滤器,基于机器学习的过滤器和基于FQDN相似度的过滤器。如果两个过滤器都将查询分类为可疑查询,立即向用户报告。但是,如果只有一个过滤器将查询标识为可疑查询,那么将其标记为可疑查询,用户可以稍后进行分析。
实验结果
作者采用准确度、 F1-Score、时间3个指标对不同机器算法模型进行了实验评估,结果如下: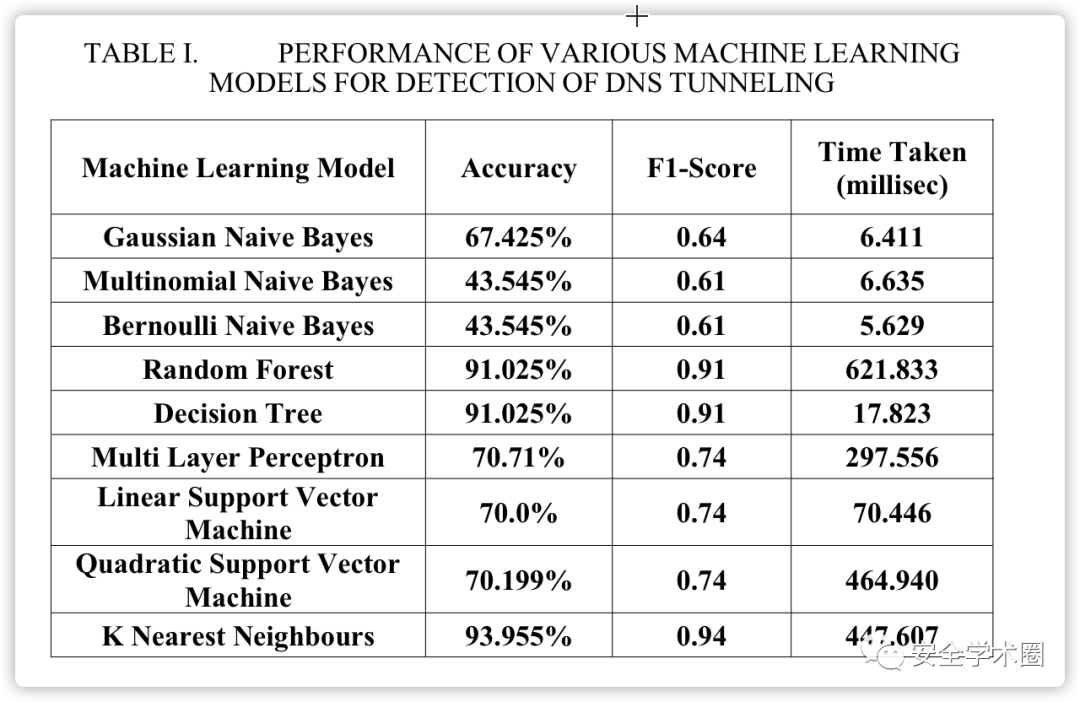
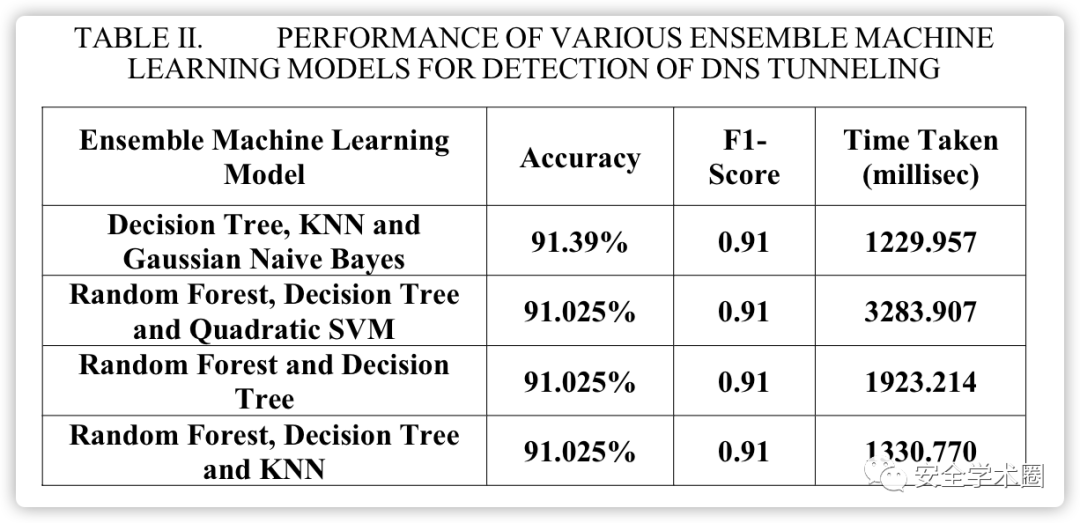 同时,作者还比较了基于机器学习和基于FQDN的过滤器的性能,由于它们使用非常不同的DNS隧道攻击属性,因此它们相互补充非常好,共同显示出非常高的准确性。通过实验发现,基于机器学习的方法适用于具有高度随机性的查询,这通常是由查询中的编码数据引起的,基于FQDN的方法更适合于像正常查询的恶意查询。
同时,作者还比较了基于机器学习和基于FQDN的过滤器的性能,由于它们使用非常不同的DNS隧道攻击属性,因此它们相互补充非常好,共同显示出非常高的准确性。通过实验发现,基于机器学习的方法适用于具有高度随机性的查询,这通常是由查询中的编码数据引起的,基于FQDN的方法更适合于像正常查询的恶意查询。
总结与下步工作
在所有标准的机器学习模型和集成模型中,K近邻模型对DNS隧道数据的分类准确率最高,为93.955%。如果优先考虑模型所花费的时间,则决策树的准确率最高,为91.025%。基于主机名的熵是执行DNS隧道检测的一个很好的功能,这可以根据已实现的精度进行观察。当前方法可以进一步改进,使用更好的数据集覆盖大多数已知的DNS隧道查询模式。此外,使用已知真实查询的预先存在的列表,可以减少检查每个DNS隧道查询的开销。这种已知真实和欺诈查询的列表将有助于缓存未命中方法识别查询中与已知欺诈查询相似的部分。该工具可以通过添加一个功能来报告进行相应查询的进程来进一步改进,这可以帮助用户查找系统中安装的DNS隧道客户端。

声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
