北京邮电大学 张沛 黄小红 马严
互联网域名系统国家工程研究中心 张绍峰 池慧斌 马迪
今天是2021年10月10日,距离Facebook严重的路由中断事件已经过去一周时间,各监测平台(CloudFlare,ThousandEyes,Downdetector)对事件起因都做了详尽分析,Facebook官方也对事件起因做了详细说明,即更新BGP路由器导致DNS权威服务器离线进而造成长达7个小时之久的中断事故。此次事故导致Facebook旗下多个平台和服务,包括Facebook、Instagram、Messenger和WhatsApp等,相继出现严重服务中断,经济损失无法估量。
本文通过对事件当天的路由报文进行回溯分析,简单还原整个事件发生的过程,并从互联网基础设施分布的均衡性和冗余性方面对路由维护、监测与防御、域名系统冗余设计提出一些建议。
我们基于RIPE RIS 的RRC00路由采集器采集路由报文进行回溯分析。RIPE RIS 利用在世界各地部署路由收集器(Remote Route Collectors,RRCs),收集并存储网络中的路由报文数据。目前已经与全球上百个自治域建立了BGP 会话连接,利用这些收集器的路由报文数据,可以较好地还原整个路由中断事件发生的过程。
UTC时间2021年10月4日15:42分,本次路由中断事件主角Facebook主要的自治域AS32934相关前缀路由报文更新发生了剧烈变化,见下图。
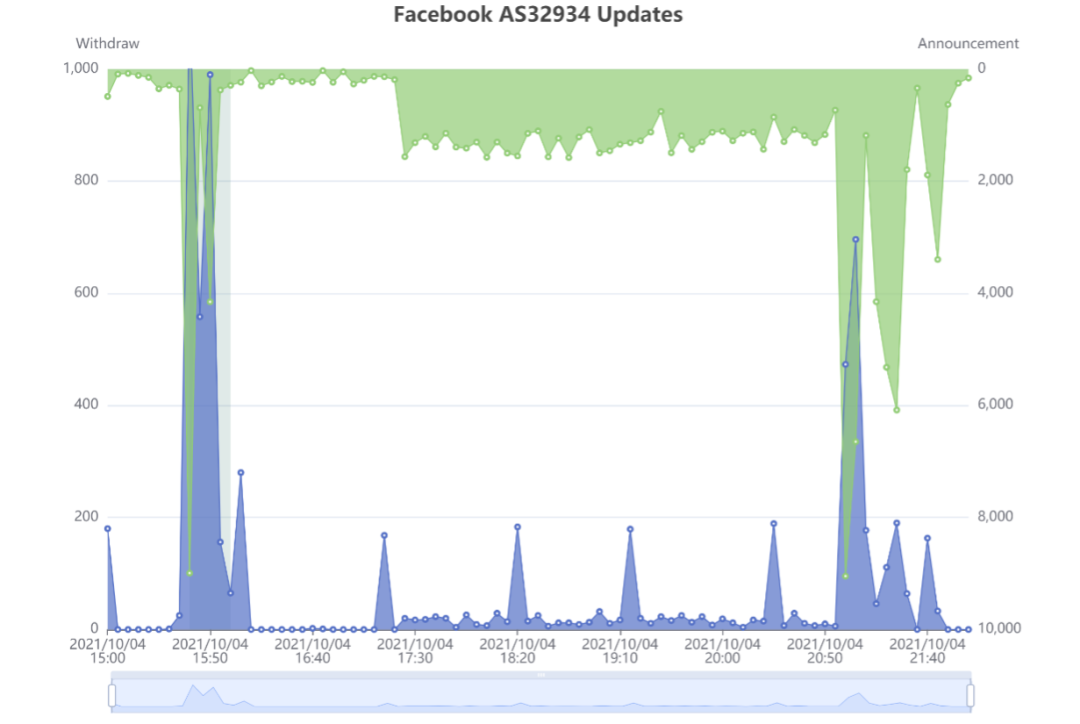
通过分析路由收集器的路由更新报文,发现该自治域的回撤了一些路由前缀,回撤报文总共持续了20分钟左右,相关前缀彻底从互联网消失,而这些前缀正是Facebook DNS权威服务器所在的地址前缀,如下图所示。
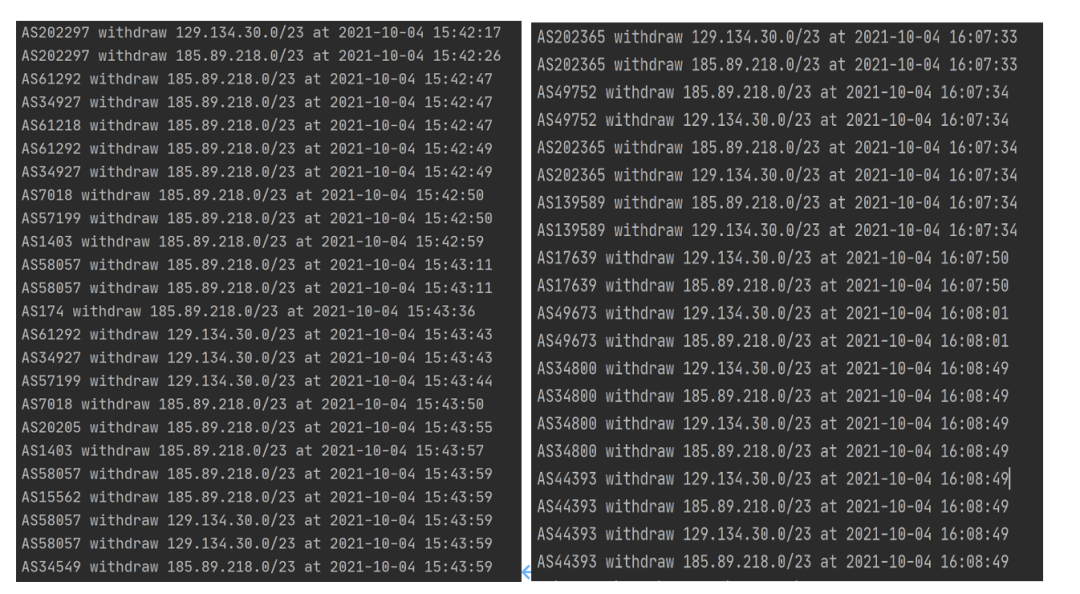
后果可想而知,Facebook重要服务的域名解析失效了,导致大量的Facebook应用服务访问不可达,另外一个严重的问题是Facebook AS32934相互依赖的服务中间件和审核软件开始失效,从而导致整个数据中心的网络崩溃,最后不得己以物理的暴力方式进入机房恢复设备。由此可见,此次事件的主角是BGP和DNS偶发性事故联动造成的重大事件。BGP和DNS作为网络空间的基础设施,是网络空间的命门所在,犹如人体的动静脉,联动性的故障必然造成规模性失血,历史也告诉我们,持续时间长且极具破坏性的中断通常可以归咎于控制平面的某些问题。
然而,这只是开始,通过进一步分析,我们发现了更为严重的事情。从互联网码号资源分配看,Facebook主要有三个自治域,从地址前缀分布可以看出,AS32934是Facebook的主力AS,我们通过分析FDNS日志,发现该自治域集中了Facebook大部分的应用服务,令人费解的是,Facebook所有的DNS权威服务器全部位于AS32934中,这相当于把所有鸡蛋都放进了一个篮子中,一旦出现问题,后果非常严重。
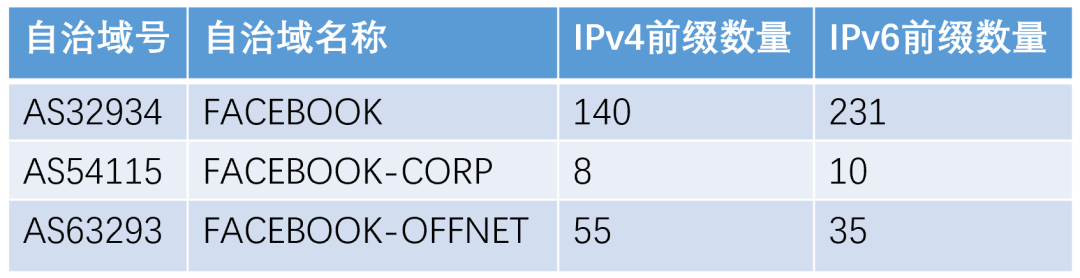
那么我们有一个疑问,与全球重量级的服务提供商Facebook比,其他服务商会是怎样的情况呢?我们基于Alexa网站排名从全球6个测量点对全球Top1000网站的权威服务器分布进行了测量,发现了以下现象:
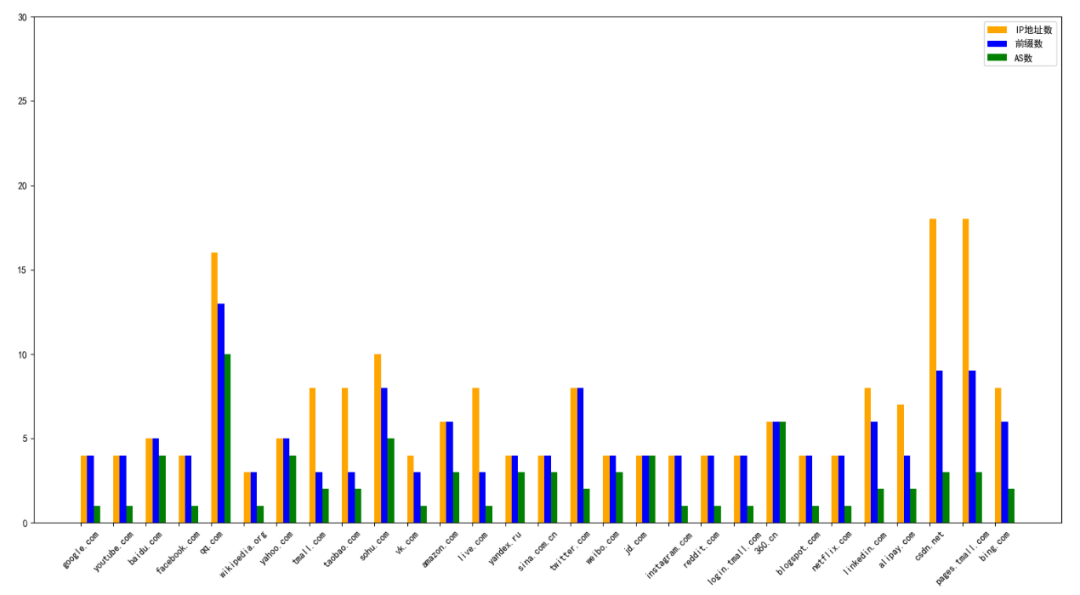
我们挑选了Top30网站,从权威DNS地址分布、前缀聚合分布、AS聚合分布进行数据分析,发现国外网站如谷歌,维基百科,Youtube,vk.com,live.com,Instagram.com,reddit.com,netflix.com这些大站都存在类似Facebook的问题,这里amazon.com例外,它的权威分布冗余度较高,这可能与2018年亚马逊权威DNS遭遇BGP劫持教训有关。国内的主流网站防护比较好,基本都有冗余备份。
我们把数据扩展到Top100网站,Top1000网站,整体冗余情况也很不乐观,Top100网站中有超过50%的网站DNS权威冗余度较低,Top1000网站中有接近70%的网站权威服务器集中在单一自治域中。(分析结果如下图,图中横坐标分别代表权威DNS IP地址数量、聚合后路由前缀数量、聚合后AS数量的分布,纵坐标代表网站数量)
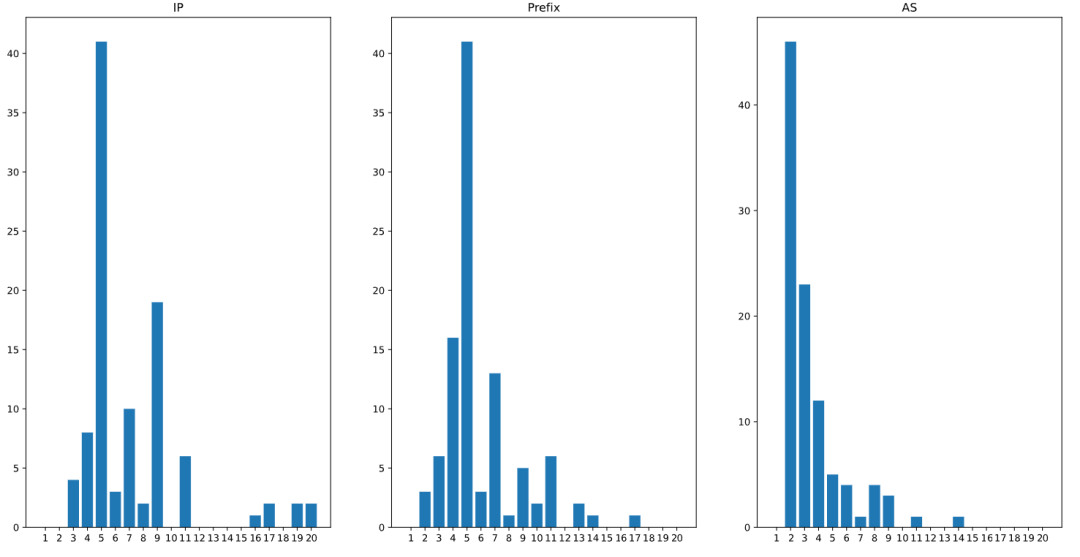
Top100网站
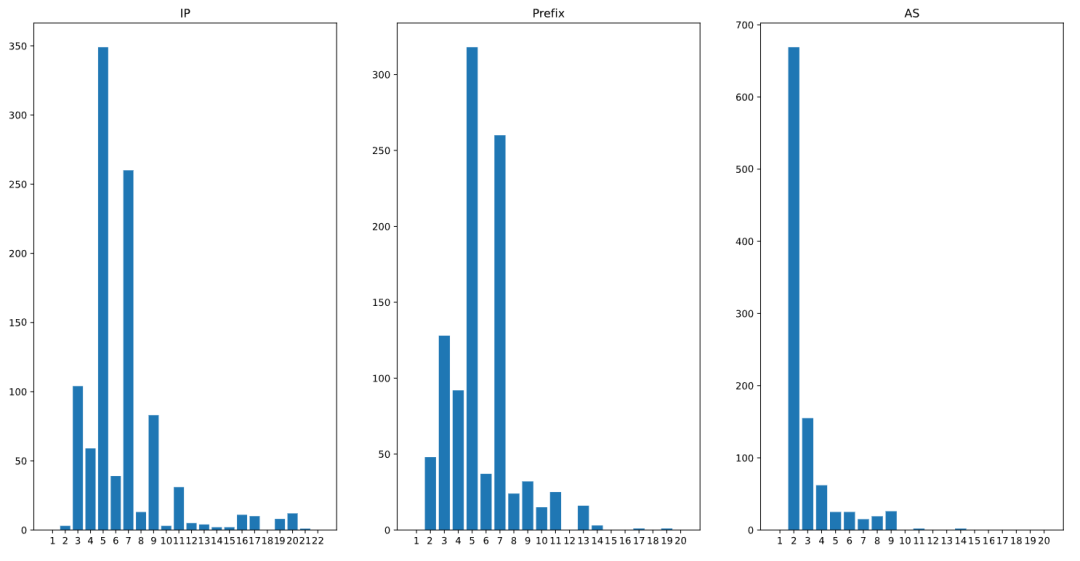
Top1000网站
通过事件的回溯分析,我们发现BGP和DNS的一系列巧合操作造成了此次事件的严重后果,因此可以看到BGP和DNS误操作的“网络核弹”威力。通过上述回溯分析,我们在路由维护、事件监测防御以及DNS冗余度方面,有如下建议:
1、路由维护
BGP路由作为网间互联互通的基本协议,简单而不简约。任何自动化的操作,如果没有全局的知识库作为路由过滤的支撑,比较容易发生错误的配置,需要对危害性的命令有“特别严格”地警示和确认。
2、路由监测与防御
目前著名的路由监测平台如BGPStream、ThousandEyes、Downdectcor都可以检测出事件的发生,然而大部分系统关注的是事件的漏报率和误报率,忽视了事件所涉及前缀的敏感度以及前缀的归属责任人,事件检测出是一方面,事件的敏感程度以及如何快速通知前缀的技术管理人是更加迫切的事情,需要建立敏感前缀管理人的台账机制,能在事件发生的第一时间通知管理人,这是路由安全防御的有效防范手段。
3、域名系统冗余设计
DNS系统的本质是一个分布式的数据库,这种结构允许对整体数据库的各个部分进行本地控制且互相关联。如下图所示,亚马逊amazon.com的权威域授权体系在多元化层面要优于facebook.com,所以它的抗风险能力肯定要强于Facebook。
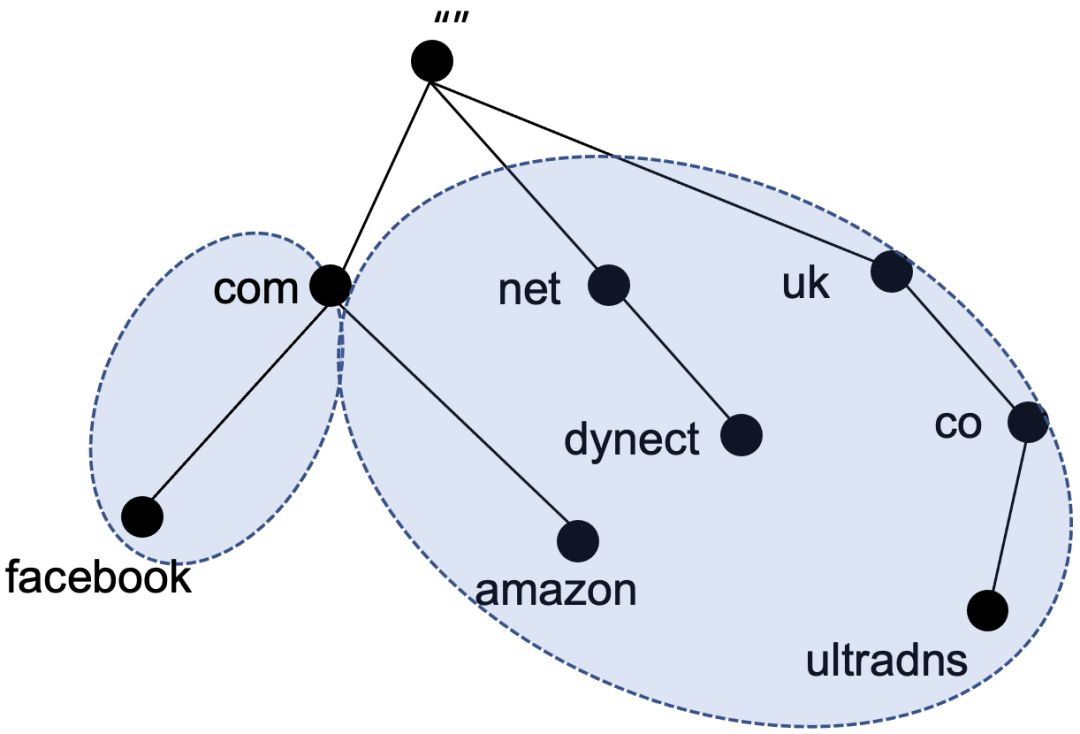

另外,DNS系统在架构设计和技术路线选择时要尽量避免采用单一化架构和技术,应从部署形式和部署位置等层面考虑技术多元性。在部署形式的设计上可选择将DNS服务器节点全部放在SLB(应用负载)后方,或采用OSPFAnycast架构等部署形式,提高DNS系统的可靠性。要考虑DNS在域内和域外均衡部署的可能性,在部署位置的设计上可选择数据中心自建集群+公有云SaaS服务混合异构部署,利用云的分布式优势进一步增强DNS系统的健壮性,同时提升DNS系统在遭受DDoS攻击时的抵御能力。
4、域名体系管理“顶层设计”
从互联网上披露的信息来看,事发期间Facebook除了面向互联网公开的业务受到影响,其面向内部的业务(会议系统、认证系统等)貌似也受到影响,从而可以推断其DNS系统不但承载外部业务域名,还承载了大量面向内网的域名解析,进而加剧了故障修复时间。这提醒我们域名体系的管理必须要从顶层设计开始。基于业务面向的对象、重要性、所属安全隔离域等因素规范域名空间及资源的划分和使用,如:对外业务域名、对内业务域名、核心业务域名;在域名系统设计时要考虑其扩展性、隔离性、安全性,并借助IT系统支撑其生命周期的管理。
5、域名体系风险控制
本次Facebook出现如此严重的故障,在运维管理层面也有值得反思之处。如域名的TTL值大小设置,这个值在应用层面决定着能切换和调度的速度,应用侧一定希望越短越好,而从DNS系统运维层面看到是时间越短,那么因为递归DNS的缓存时间也会越短,一旦权威DNS出现问题,域名整体服务的容错能力会大幅降低。
另外,互联网域名服务体系解析逻辑严谨,想要完成从客户端到服务端的业务访问和交互,需经过多层查询,查询由终端到递归DNS、递归DNS从根、顶级域到二级域,再到权威DNS。想要完成整个业务接入访问,任何一个环节出现问题都会导致业务不可用。基于上述情况,企业除了应重视自身权威系统的管理外还应加强域名体系各层级(根、顶级域、注册商、递归DNS)的状态监测和感知,如:响应延迟、递归可用性、注册商NS指向状态,降低因外部故障对业务造成的影响。
本文起草团队介绍:
北京邮电大学计算机学院(国家示范性软件学院)信息网络中心路由安全研究团队,长期从事网络空间测量、路由监测、互联网基础资源测绘工作,承担了若干面向网络空间安全的国家重点研发计划课题、国家自然基金重点基金等项目,在路由安全监测有深厚的技术积累。
互联网域名系统国家工程研究中心(ZDNS)是中科院孵化的高新技术企业,专注于互联网域名和IP地址服务体系的技术研究和创新,运行全球互联网域名根(镜像)服务器,构建亚洲第一大(注册量)新顶级域名服务平台,连续五年在中国DDI(DNS、DHCP、IPAM)商用设备领域市场占有率第一*,牵头制定多项IETF RFC国际标准,近20项国内通信行业标准,拥有软件著作及专利百余项,在网络根基领域掌握自主核心技术。(*根据IDC研究报告《中国DDI市场份额》2015-2019)
声明:本文来自域名国家工程研究中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
