在安全和隐私保护需求的驱动下,网络通信加密化已经成为不可阻挡的趋势。加密网络流量呈现爆炸增长,给流量审计与网络空间治理带来了挑战。尽管机器学习已解决了部分加密流量识别的问题,但仍存在无法自动提取特征等局限。深度学习可以自动提取更本质、更有效的特征,已被用于加密流量识别,并取得了高精度。基于深度学习的加密流量识别的相关研究工作,提出基于深度学习的加密流量识别的框架,并通过数据集、特征构造和模型架构回顾部分研究工作,分析基于深度学习的加密流量识别面临的挑战。
内容目录:
0 引 言
1 加密流量识别的定义
1.1 识别目的
1.1.1 识别加密流量
1.1.2 识别加密协议
1.1.3 识别加密应用
1.1.4 识别恶意加密流量
1.1.5 识别加密流量内容
1.2 识别性能
1.3 加密流量数据集
1.3.1 选择公共数据集
1.3.2 收集原始数据
2 深度学习的加密流量识别框架
2.1 数据预处理
2.1.1 数据包过滤或报头去除
2.1.2 数据包填充与截断
2.1.3 数据归一化
2.2 特征提取
2.2.1 原始数据包数据
2.2.2 流量特征
2.2.3 原始数据和流量特征的组合
2.3 模型架构
2.3.1 多层感知器
2.3.2 卷积神经网络
2.3.3 循环神经网络
2.3.4 自编码器
3 挑战与展望
3.1 现存挑战
3.1.1 新型加密协议的出现
3.1.2 加密流量的标注
3.1.3 加密流量的分布
3.2 未来可能的方向
3.2.1 预训练模型
3.2.2 生成对抗网络
3.2.3 迁移学习
4 结 语
0 引 言
加密流量主要是指在通信过程中所传送的被加密过的实际明文内容。在安全和隐私保护需求的驱动下,网络通信加密化已经成为不可阻挡的趋势。加密网络流量呈现爆炸增长,安全超文本传输协议(Hyper Text Transfer Protocol over Secure,HTTPS)几乎已经基本普及。但是,加密流量也给互联网安全带来了巨大威胁,尤其是加密技术被用于网络违法犯罪,如网络攻击、传播违法违规信息等。因此,对加密流量进行识别与检测是网络恶意行为检测中的关键技术,对维护网络空间安全具有重要意义。
随着流量加密与混淆的手段不断升级,加密流量分类与识别的技术逐步演进,主要分为基于端口、基于有效载荷和基于流的方法。
基于端口的分类方法通过假设大多数应用程序使用默认的传输控制协议(Transmission Control Protocol,TCP)或用户数据报协议(User Datagram Protocol,UDP)端口号来推断服务或应用程序的类型。然而,端口伪装、端口随机和隧道技术等方法使该方法很快失效。基于有效载荷的方法,即深度包解析(Deep Packet Inspection,DPI)技术,需要匹配数据包内容,无法处理加密流量。基于流的方法通常依赖于统计特征或时间序列特征,并采用机器学习算法,如支持向量机、决策树、随机森林等算法进行建模与识别。此外,高斯混合模型等统计模型也被用于识别和分类加密流量。
虽然机器学习方法可以解决许多基于端口和有效载荷的方法无法解决的问题,但仍然存在一些局限:(1)无法自动提取和选择特征,需要依赖领域专家的经验,导致将机器学习应用于加密流量分类时存在很大的不确定性;(2)特征容易失效,需要不断更新。与大多数传统机器学习算法不同,在没有人工干预的情况下,深度学习可以提取更本质、更有效的检测特征。因此,国内外最近的研究工作开始探索深度学习在加密流量检测领域中的应用。
基于已有研究工作,本文提出了基于深度学习的加密流量分类的通用框架,主要包括数据预处理、特征构造、模型与算法选择。本文其余部分组织如下:第1节介绍加密流量识别的定义;第2节提出基于深度学习的加密流量分类的总体框架;第3节讨论加密流量分类研究中一些值得注意的问题和面临的挑战;第4节总结全文。
1 加密流量识别的定义
1.1 识别目的
加密流量识别的类型是指识别结果的输出形式。通过加密流量识别的应用需求,确定识别的类型。加密流量可以从协议、应用、服务等属性出发,逐步精细化识别,最终实现协议识别、应用识别、异常流量识别及内容本质识别等。
1.1.1 识别加密流量
加密流量识别的首要任务是区分加密与未加密流量。在识别出加密流量后,可以采用不同策略对加密流量进行精细化识别。
1.1.2 识别加密协议
加密协议(如TLS、SSH、IPSec)的识别可以用于网络资源的调度、规划和分配,也可以用于入侵检测以及恶意网络行为检测等。由于各协议定义不同,需要在协议交互过程中挖掘具有强差异性的特征与规律,从而提升加密流量识别的精确性。
1.1.3 识别加密应用
加密应用的识别是指识别加密流量所属的应用类型,如Facebook、Youtube、Skype等。它既可用于网络资源的精准调度,也可用于识别暗网应用(如Tor、Zeronet),从而提升网络空间治理能力。
1.1.4 识别恶意加密流量
恶意加密流量是指使用加密传输的恶意网络流量,如勒索病毒、恶意软件等。识别恶意加密流量可以用于入侵检测、恶意软件检测和僵尸网络检测。
1.1.5 识别加密流量内容
加密流量的内容识别是指从加密流量中识别其承载的内容,如图片、视频、音频、网页以及文件类型等。识别加密流量内容可用于网络空间安全治理。
1.2 识别性能
目前,网络加密流量的识别方法大多采用与准确性相关的指标进行评估,主要为误报率、精确率、召回率以及总体准确率等。
假设加密流量有 N种类型,即 N为分类类别数;定义 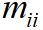 为实际类型为 i的样本被识别为类型 i的样本数;定义
为实际类型为 i的样本被识别为类型 i的样本数;定义 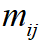 为实际类型为 i的样本被误识别为类型 j的样本数。
为实际类型为 i的样本被误识别为类型 j的样本数。
类型 i的误报率为:
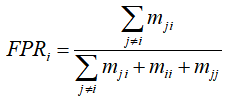 (1)
(1)
类型 i的精确率为:
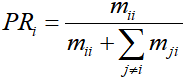 (2)
(2)
类型 i的召回率为:
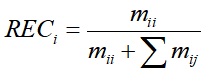 (3)
(3)
总体准确率为:
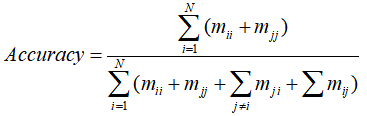 (4)
(4)
1.3 加密流量数据集
使用深度学习对加密流量进行分类时,需要选择规模较大、数据分布均衡且具有代表性的数据集。目前,加密流量数据集主要有公共数据集和原始数据。
1.3.1 选择公共数据集
近年来,大多数加密流量识别的研究工作选择公共数据集,如ISCX2012、Moore、USTC-TFC2016和IMTD17等。但是,公开的加密流量数据集的数量少,且缺少一个能够准确且全面表征所有加密流量类型的数据集。究其原因,主要在于:流量类型多且数量庞大,应用程序更新频繁,没有数据集可以包含所有类型的加密流量;难以覆盖宽带和无线接入、PC和移动设备接入等所有网络场景。
1.3.2 收集原始数据
文献[11-12]通过数据包采集工具,收集来自研究实验室网络或运营商的原始流量数据,但大部分原始数据集均未公开。
2 深度学习的加密流量识别框架
本文提供了基于深度学习的加密流量识别通用框架,并简要介绍常用深度学习方法的一些最新论文,总体框架如图1所示,包含数据预处理、特征构造以及深度学习模型架构设计、训练以及识别等流程。
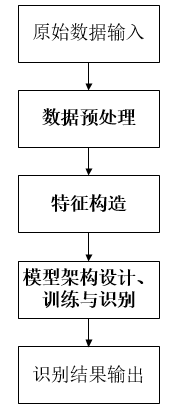
图1 基于深度学习的加密流量识别的通用框架
2.1 数据预处理
加密流量原始数据集可以分为原始数据包数据集、流量pcap文件和已处理过的统计特征3种类型。在对加密流量识别的深度学习框架中,常见的数据预处理操作有数据包过滤或报头去除、数据包填充与截断以及数据归一化。
2.1.1 数据包过滤或报头去除
由于原始数据包数据集中可能包含地址解析协议(Address Resolution Protocol,ARP)、动态主机配置协议(Dynamic Host Configuration Protocol,DHCP)、Internet控制报文协议(Internet Control Message Protocol,ICMP)等流量,同时pcap文件中包含pcap文件头等信息。通常这两类数据需要进行预处理,如数据包过滤、报头去除。
2.1.2 数据包填充与截断
由于深度神经网络(Deep Neural Networks,DNN)总是被馈送固定大小的输入,而数据包的帧长度从54到1 514变化很大,如传输控制协议(Transmission Control Protocol,TCP)协议,因此需要对数据包进行固定长度的零填充和截断。
2.1.3 数据归一化
数据归一化对深度学习的性能至关重要。通过将统计特征数据集中的流量数据归一化为[-1,+1]或[0,1]范围内的值,有助于分类任务在模型训练期间更快收敛。
2.2 特征提取
深度学习模型的输入对模型在训练和测试过程中的性能有很大影响,既能直接影响模型的准确性,又能影响计算复杂度和空间复杂度。在现有研究中,基于深度学习的加密流量分类模型的输入一般可以分为原始数据包数据、流量特征以及原始数据与流量特征组合3种类型。
2.2.1 原始数据包数据
深度学习可以自动提取特征,因此大多数基于深度学习的加密流量分类算法将数据预处理后的原始数据包数据作为模型的输入。
2.2.2 流量特征
加密流量的一般流量特征可以分为包级特征、会话特征和统计特征。其中:包级特征包含源和目的端口、包长度、到达时间间隔、有效载荷字节、TCP窗口大小以及流向等;会话特征包括接收与发送数据包个数、会话持续时间以及会话有效负载等;统计特征有平均数据包长度、平均延误时间间隔以及平均上下行数据比例等。在文献[12]中,数据包级、流级特征和统计特征都被用于模型的输入。文献[15]针对Tor常用的3种流量混淆插件(Obfs3、Obfs4、ScrambleSuit)进行研究,旨在挖掘可用的混淆插件Tor流量识别方法。该文采用的方法为机器学习方法,包括C4.5、SVM、Adaboost以及随机森林,采用的流特征包括数种前向与后向的数据包大小统计特征,如前向总字节数。该实验结果证明,仅仅采用每条流的前10~50个数据包的信息即可实现上述流量的快速检测。同时,有研究表明,第一个数据包的数量对分类器的影响较大,尤其是实时分类性能。第一个数据包收集越多,流量特征越完整和全面。
2.2.3 原始数据和流量特征的组合
TONG等人将原始数据包数据和从网络流量中提取的特征进行组合,从而对新型加密协议QUIC下的谷歌应用程序进行分类。
2.3 模型架构
2.3.1 多层感知器
由于多层感知器(Multilayer Perceptron,MLP)的复杂性和低准确率,研究者在识别加密流量领域中较少使用MLP。文献[18]基于不同的加密流量数据集,将多种深度学习算法与随机森林算法(Random Forest,RF)进行比较,结果表明大多数深度学习方法优于随机森林算法,但MLP性能低于RF。但文献[18]提出,由于RF、MLP和其余深度学习方法的输入特征不同,不应将该实验结果作为对MLP、RF等方法的综合比较结论。
文献[19]介绍了一种称为DataNet的基于深度学习的加密流量分类方法,其中MLP模型由1个输入层、2个隐藏层和1个输出层组成,用ISCX2012的VPN-nonVPN流量数据集进行实验。实验评估结果表明,它的精确率、召回率均超过92%。
2.3.2 卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)可以通过卷积层来改善MLP无法处理高维输入的限制,利用卷积和池化来减少模型参数,如图2所示。
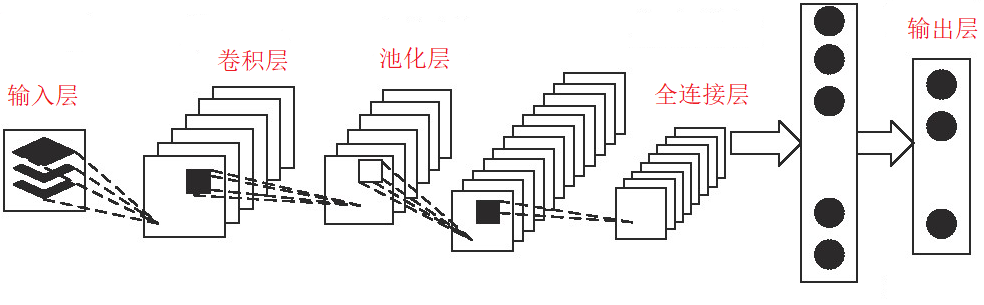
图2 卷积神经网络
文献[14]用一维向量表示每个流或会话,以训练CNN模型。结果表明,该CNN的准确性优于使用时间序列和统计特征的C4.5方法。文献[17]将时间序列数据转换为二维图像,并使用具有2个卷积层、2个池化层和3个全连接层的CNN进行训练。结果表明,文献[14]提出的CNN模型在协议和应用分类方面优于经典机器学习方法和MLP。
2.3.3 循环神经网络
循环神经网络(Recurrent Neural Network,RNN)可以有效处理序列问题,对之前发生的数据序列有一定的记忆力,结构如图3所示。文献[12]提出,在加密流量识别领域中,混合模型会有优于单一的长短期记忆网络(Long Short-Term Memory,LSTM)或CNN模型。文献[12]同时使用CNN和RNN来捕获流的空间特征和时间特征。LIU等人采用基于注意力的双向门限循环单位网络(Attention-Based Bidirectional GRU Networks,BGRUA)进行以HTTPS封装的Web流量的识别。该文采用3个部分的神经网络进行充分的加密流量识别。第1部分为一个双层的BGRU网络,用于从输入的流序列中学习得到序列隐藏状态。第2部分为注意力层,将隐藏状态序列转化为带注意力权重参数的隐藏状态序列,然后通过前向神经网络转化为预测标签。第3部分为迁移学习网络,实现前两部分学习成果的场景扩展。实验结果除了证明模型在性能上的优势外,还证明了迁移学习在加速新场景方面的训练能力。
图3 RNN结构
2.3.4 自编码器
自编码器(Auto-Encoder,AE)是一种无监督的神经网络模型,可以学习到输入数据的隐含特征。文献[21]使用AE重构输入,并将softmax层应用于自编码器的编码内部表示。文献[22]采用有效载荷数据来训练一维CNN和堆叠AE模型,如图4所示。这两种模型显示出高精度,且CNN模型略微优于堆叠AE模型。
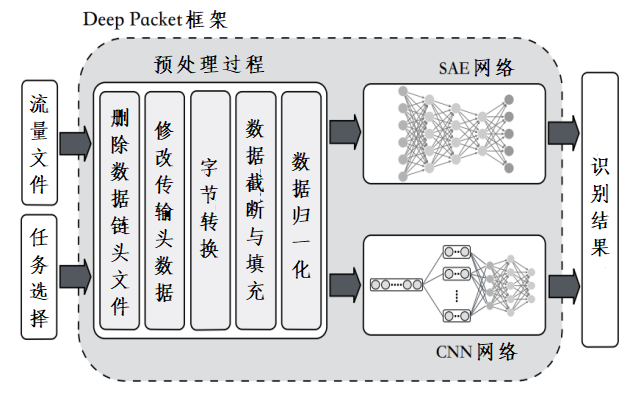
图4 Deep Packet框架
3 挑战与展望
本节对加密流量识别的挑战与未来方向进行了讨论。
3.1 现存挑战
3.1.1 新型加密协议的出现
随着新型加密协议的出现与普及,如TLS1.3协议,数据包中只有少数字段未加密,证书和域名信息都将加密。基于TLS1.2握手期间,部分明文字段的加密流量识别算法都将失效。
3.1.2 加密流量的标注
深度学习在训练过程中需要大量标记数据。但是,由于隐私保护和流量标注工具如深度包解析工具无法处理加密流量,难以在短时间和低成本的条件下合法收集,并准确标注加密流量数据集。
3.1.3 加密流量的分布
在真实网络环境下,类不平衡也是加密流量分类的重要问题,会直接影响分类精度。
3.2 未来可能的方向
3.2.1 预训练模型
未标记的流量数据数据量大且比较容易获取,因此一些研究人员开始探索如何利用容易获得的未标记流量数据结合少量标记流量数据进行准确的流量分类。通过它可以使用大量未标记的交通数据预训练模型,然后将其转移到新架构,并使用深度学习重新训练模型。此外,预训练可以用于降维,使模型变得轻量级。
3.2.2 生成对抗网络
生成模型可用于处理网络流量分类中的数据集不平衡问题。不平衡问题是指每个类的样本数量差异很大的场景,而处理不平衡数据集的最常见和最简单的方法是通过复制少类的样本进行过采样,或者通过从多类中删除一些样本进行欠采样。文献[24]中,生成对抗网络(Generative Adversarial Network,GAN)用于生成合成样本以处理不平衡问题,通过使用辅助分类器生成对抗网络(Auxiliary Classifier Generative Adversarial Network,AC-GAN)来生成两类网络,使用具有2个类(SSH和非SSH)和22个输入统计特征的公共数据集。
3.2.3 迁移学习
迁移学习假设源任务和目标任务的输入分布是相似的,允许在源任务上训练的模型用于不同的目标任务。由于模型已训练,再训练过程需要的标记数据和训练时间将明显减少。在网络加密流量识别的场景中,可用公开的加密数据集来预训练模型,在进一步调整模型后,以用于具有较少标记样本的另一个加密流量分类任务。文献[23]使用这种方法,将预先训练的CNN模型的权重转移到一个新模型,训练对Google应用程序进行分类。论文还表明,在不相关的公共数据集上,预训练的模型仍然可以用于迁移学习。
4 结 语
网络流量是网络通信的必然产物,而流量蕴含了通信过程中双方的各种关键信息,因此加密流量分析是网络态势感知的一个重要方面。多种研究和实践已经证明,加密流量中蕴含的信息可以在一定程度上被有效挖掘,为网络管理操作决策提供高质量的依据支撑。因此,加密流量分析是提升网络态势感知能力的关键因素之一,具有极高的科研、应用、民生以及安全意义。
本文提出了基于深度学习的加密流量分类的通用框架,并根据分类任务定义、数据准备、特征构造、模型输入设计和模型架构回顾了最新的现有工作。此外,本文对加密流量识别的现存问题和未来可能的识别技术进行了讨论。
引用本文:郭宇斌,李航,丁建伟.基于深度学习的加密流量识别研究综述及展望[J].通信技术,2021,54(9):2074-2079.
作者简介
郭宇斌(1987—),男,硕士,工程师,主要研究方向为信息安全;
李航(1995—),女,硕士,助理工程师,主要研究方向为数据挖掘与机器学习;
丁建伟(1986—),男,博士,高级工程师,主要研究方向为大数据与信息安全。
选自《通信技术》2021年第9期(为便于排版,已省去原文参考文献)
声明:本文来自信息安全与通信保密杂志社,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
