研究现状简介
目前,数据脱敏的效果评估技术主要可分为三类:基于人工抽查的定性判定方法、基于模型参数的评估技术和通用的评估技术。其中,基于人工抽查的定性判定方法,指的是按照标准流程和表格进行专家检查和判定,然而,这种方法成本十分昂贵;基于模型参数的评估通常为隐私保护模型,包括K-匿名 (K-Anonymity)、L-多样性 (L-Diversity)和 -差分隐私 (Differential Privacy)等模型,比如在K-匿名模型中,链接攻击或重识别的最高攻击风险1/K,然而这种指标的刻画能力十分有限,无法充分和全面反映处理后数据的隐私风险分布。通用的风险评估技术与数据脱敏方法与模型无关,在学术上通常称为重识别/重标识攻击(re-identification attack)风险的度量。对于重识别攻击风险问题,最为简单的评估一般使用唯一性 (uniqueness) 指标进行度量,单个属性或者多个属性组合的值在表中是唯一的,那么很可能被攻击唯一识别目标个人信息主体的身份。
据权威机构统计,在美国,使用邮编、性别、出生日期信息,有81%的概率可以唯一识别出对应的美国公民。对于大规模数据集的唯一性度量问题, Google学者Chia等人在2019年的IEEE Symposium on Security and Privacy会议上提出了适应大规模数据集(PB级别)场景的重识别评估算法——KHyperLogLog,他们将重识别问题定义了两种评估指标:Re-identifiability和Joinability,其主要思想是基于Hash、KMV和HLL算法,对结果的近似分析与估计,其在准确率和效率可取得良好的效果。在2019年的Nature communications期刊上,Rocherd等人对于发布的数据集重识别评估问题,提出重识别评估的近似模型——Gaussian copulas模型,成功刻画了去标识化/假名化数据集被重识别的成功率,证明即使是不完整的数据集 (比如社会人口调查采样的数据集),某些个人数据属性的组合仍然存在较高的重识别风险。
重识别攻击场景
在重识别风险评估领域,多个学者进行一系列的指标与评估算法的研究,其中较为著名的要数加拿大学者El Emam,他进行了深入的研究,提出了三种常见的攻击场景以及一系列的评估指标,并将研究成果进行了转化,创立一家科技公司——Privacy Analytics,主要面向医疗隐私数据,并对去标识化结果进行风险评估与检测,帮助数据处理企业合规美国医疗HIPAA法案,同时获得最大的数据价值,比如将评估合规的脱敏医疗数据出售给保险、药企和科研结构等第三方。
El Emam根据攻击者的目的和攻击能力定义了三类常见的隐私攻击场景——并形象化地被称为检察官攻击 (Prosecutor attack)、记者攻击 (Journalist attack)和营销者攻击 (Marketer attack)。其中检察官攻击具有背景知识,了解攻击目标一定在公开数据集中,比如攻击者了解自己的朋友在发布展示的数据集中,他的目的是挑选出他的朋友,并获得敏感属性信息(比如财产消费、医疗健康等信息);记者攻击场景是达到曝光的目的,他需要尽量寻找公开数据库(比如选举身份登记表),进行匹配关联,通过多次向媒体炫耀,证明重新识别个体,使得涉及企业名誉扫地和难堪;营销者攻击目的是营销,即企业对自己的用户进行多维度的关联与画像,只需保持较高识别概率的匹配关联即可,无需证明是唯一识别出脱敏数据集对应的数据主体。
表1重标识攻击场景与举例
攻击场景 | 描述 | 潜在攻击者 | 举例 |
检察官攻击 | 攻击者知道某个特定人员在公开的数据集(背景知识),且了解特定人员的身份属性信息(攻击能力),由于好奇特定人员的其他敏感属性(攻击意图)发起针对特定目标的攻击 | 1、朋友 2、同学 3、邻居等 | 某个人了解他的同学是某次受访的调查对象,他在公开网站的去标识化数据集去查找他的同学属于哪一行记录 |
记者攻击 | 攻击者拥有私有的或者可访问公开的身份数据库(攻击能力),但他并不知道数据库的人员是否在公开的去标识数据集中,他通过多次炫耀式攻击证明某人可以被重新标识,使得公开数据库的组织感到难堪或者名誉扫地(攻击意图) | 1、公众人士 2、研究人员 3、竞争对手等 | 研究人员将去标识化的医疗患者信息数据集与公开的州选民的登记表进行关联,恢复和确认大部分患者信息的身份 |
营销者攻击 | 攻击者拥有私有的或者可访问公开的身份数据库(攻击能力),他将其与去标识化数据集进行关联,实现对身份数据库的人进行扩展更多维度的画像(攻击意 图),无需证明重标识结果的正确性,仅需保证较高概率的关联性 | 1、大数据企业 2、广告商 3、掌握黑灰产数据库的黑客 | 大数据企业从网络搜集用户各类数据集,进行同一实体识别,进行维度扩展和精确画像 |
重识别风险评估指标
重标识攻击场景下的风险评估,可从攻击的可能性维度进行评估,其定义的指标与计算由表2给出。其中,检察官攻击、记者攻击均用最大重标识概率、平均重标识概率、高重标识记录占比3个指标刻画;营销者攻击在两种情况分别用两者其一的平均重标识概率刻画。这8个指标的数值范围均为 [0,1],1表示最高重标识风险,0表示几乎最低重标识风险。在业务场景中,可根据实际情况,选择合适的指标集进行评估。
表2 重标识攻击场景的可能性度量
攻击场景 | 风险评估指标 | 指标的意义 | 符号含义 |
检察官攻击 |
| 刻画重标识概率大于的数据集记录占总体的比例; 刻画数据集所有记录中最大的重标识概率; 刻画平均重标识概率 | ①—数据集记录的数量; ②—数据集的等价组的集合; ③—数据集的等价组数量; ④—数据集等价组为的数量; ⑤—阈值; ⑥—当输入为真,输出为1,否则为0; ⑦—身份数据集记录 (可访问或拥有的)的数量; ⑧—身份数据集 (可访问或拥有的)等价组为的数量 |
记者攻击 |
| 刻画重标识概率大于的数据集记录占总体的比例; 刻画数据集所有记录中最大的重标识概率; 刻画平均重标识概率 | |
营销者攻击 |
| 分别刻画在情况1和2下的平均重标识概率; 情况1:身份数据集和发布数据集的个人信息主体完全相同; 情况2:发布数据集是身份数据集的个人信息主体的一部分 |
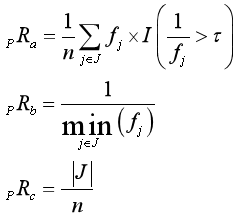
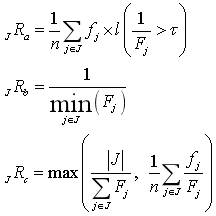

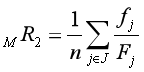
安全建议
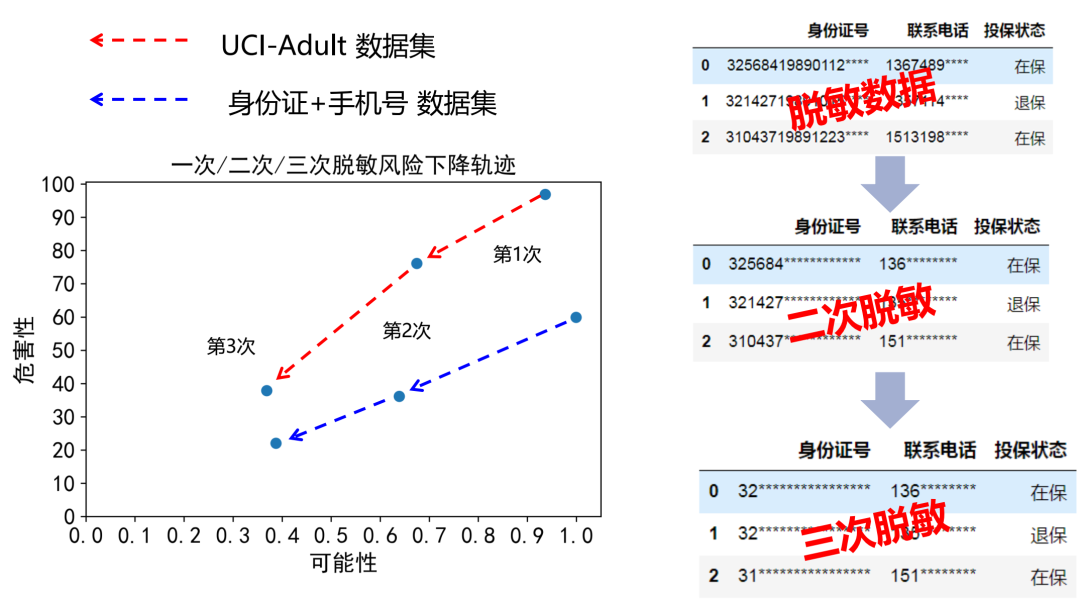
数据经过数据脱敏后,对脱敏结果和使用技术进行风险评估,最终得到风险值,根据预置场景:内部使用、与第三方共享、对外交易的、对外公开发布的阈值进行比较,若不满足分析原因,实施二次脱敏,直到脱敏的残余风险在可控范围。如上图所示,对身份证号和手机号的数据集进行三次“脱敏-评估”循环,直至风险的可能性和危害性落入可接收范围内。
(本文作者:绿盟科技集团股份有限公司 陈磊 施岭)
声明:本文来自CCIA数据安全工作委员会,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
