工作来源
MALWARE 2018
工作背景
C&C 框架的隐蔽性越来越强且随着框架代码的开源,检测 C&C 框架变得越来越困难。Shodan 的 Malware Hunter 旨在发现在野 C&C 服务器,但侧重于已知端口的子集、只能构建可能无法触发精确响应的通用探测器,并且只能识别已经可以指纹识别的恶意软件。
端点侧的检测会存在可见性问题,流量侧的检测则更为通用。过往对恶意流量的研究较多,但对 RAT 流量的研究较少。深入理解 C&C 框架使用的常见技术,可以用来帮助设计识别检测系统。
分析主要针对三个流行的开源 C&C 框架:Metasploit、Empire 和 Pupy:
Metasploit 是一个综合的网络渗透测试工具。Metasploit 的 Meterpreter 是一个多功能 RAT,可以在大多数平台上运行,并通过许多动态模块保证灵活性。
Empire 是一个用 Python 和 Powershell 编写的 RAT,用户可以自由选择传输协议和 Payload。Empire 主要使用 HTTPS 进行通信,并通过 Dropbox 或 OneDrive 等公开服务作为 C&C 信道。所有的 Empire 消息都使用 AES 加密,并预先添加一个字段以保存有关会话的元数据,字段使用由指定用户的 SHA 哈希组成的密钥进行 RC4 加密。
Pupy 是一个基于 Python 的跨平台 RAT,擅长混淆 C&C 通信。Pupy 支持用户从包含 11 种协议的列表中选择一种传输协议,再使用预先计算的密钥进行加密。用户可以将其嵌套使用以进一步增加混淆程度。
通过对轮询等 C&C 框架的通用行为进行分析,再针对 Metasploit、Empire 和 Pupy 三种典型的 C&C 框架进行适应性调整。依赖被动监测和半主动扫描,期望构建对 RAT 行为的检测模型。其中半主动扫描分为两类,一类是非介入扫描,与可疑服务器尝试建立连接。另一类是介入性扫描,在活动会话中修改数据包查看响应行为。
工作设计
明文
许多 Payload 只是通过通信通道发送纯文本命令。实现了一个执行简单模式匹配的检测器,并在数据包数据的前 32 个字节中搜索常用命令,例如 ls、cd 和 dir,以及众所周知的恶意软件关键字,例如 remoteControl。
异或编码
当未使用 TLS 加密时,Meterpreter Payload 使用自定义协议进行通信,该协议的每个数据字段使用类型长度值 (TLV) 格式定义。通过使用随机的四字节掩码 Payload 数据进行异或编码,然后将掩码添加到 Payload 之前,可以对这些数据进行混淆。完整的数据包格式如下所示:
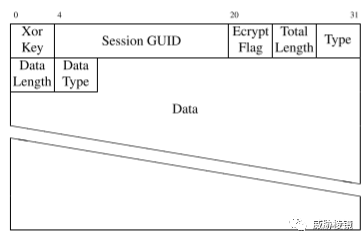
可以使用数据包 Payload 中的前四个字节来解码数据包的前 32 个字节,以尝试识别“大小”字段、“类型”字段和会话标识符。在 Meterpreter 使用 HTTP 的情况下,只需要检查头中的长度是否与数据包的长度相对应。TCP 则更复杂,因为某些 Meterpreter 消息可能比 MTU 大,并且会跨越多个 TCP 数据包。在这种情况下,算法会缓冲所有可能的 Meterpreter 数据包,直到一条消息完整,即缓冲消息的长度等于缓冲数据包的总长度。
HTTP
通用特征:
传输数据时,传输内容是 base64 编码的,但内容类型仍然是
text/html。GET 请求总是类似的,但服务器以可变的 Payload 作为响应,这会导致对同一个 URI 的两个请求产生不同的响应。
大多数情况下,对于给定的会话来说,请求的 URI 不会变。该 URI 要么是固定的,要么是在一组 URI 中随机选择的。而正常流量则经常访问不同的页面,区别很大。
使用的请求头通常是有限的,但正常流量需要更多额外的功能就会使用更多高级特性,如会话控制或高级安全性。
独有特征:
Metasploit 的 GET 请求通常包含特定的请求头,如
Accept-Encoding: identity和Content-Type: application/octet-streamEmpire 的 HTTP 模块使用 Cookie 来发送有关客户端的加密信息,相对于正常流量来说其 Cookie 是动态的。另外,Empire 的 HTTP-COM 模块也使用 CR-RAY 标头传输客户端信息,如果 CR-RAY 值与有效的 Cloudflare 服务器哈希不对应,就可以认为这是 Empire 的 HTTP 请求
Pupy 在所有 GET 请求中都使用相同的 User-Agent:
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, Gecko) Chrome/41.0.2228.0 Safari/537.36。此外,Pupy 还会生成一个随机主机名作为 Host 字段的值
一共提炼 25 个特征:User-Agent;Host 字段的熵值;Host 字段的辅音元音比例;变化的会话 Cookie 的比例;TOP3 URI 比例;GET/POST 请求的长度、比例、完整度(请求头字段的数量加上 cookie 的数量);Server;URI 熵值;URI 长度极值;URI 的辅音元音比例;Meterpreter HTTP 过滤器;Empire HTTP 过滤器;包数;text/html 类型的加密内容。
TLS/SSL
攻击工具很多采用自签名的证书,在证书中包含很多可识别的信息。
通用特征:
由于 C&C 服务器的存续时间通常较短,因此相关证书通常具有更临近时期的有效开始时间。
攻击工具通常使用许多不同的 TLS 连接,每个连接都向同一服务器发送少量请求。
独有特征:
Meterpreter 的默认证书是自签名的,并且包含可预测的组织机构名称,这些名称是从预置的列表中随机选择的
Pupy 使用的组织机构名称中包含 CLIENT 和 CONTROL
一共提炼了 11 个特征:TLS 版本;自签发证书;流平均长度;TCP 数据包数;证书扩展字段数量;证书链长度;证书 subject 字段;证书科目成绩;Meterpreter 证书过滤器;Pupy 证书过滤器;过期时间;有效时间。
轮询
轮询通常会包含三个特征:
失陷主机发送常规探针从 C&C 服务器检索信息
TCP 连接中断后会尝试定期发起新的 TCP 握手
攻击者未发送命令时,失陷主机发送 TCP keep-alive ACK 保活
各个工具的特点如下所示:

构建两个检测器,这两个检测器都依赖于双向、TCP 感知时间解析器(TCP-aware time parser),该解析器在不同的网络环境中提供一致的正规化数据包时间。往返时间 (RTT) 可以使用前人的方法进行校准。
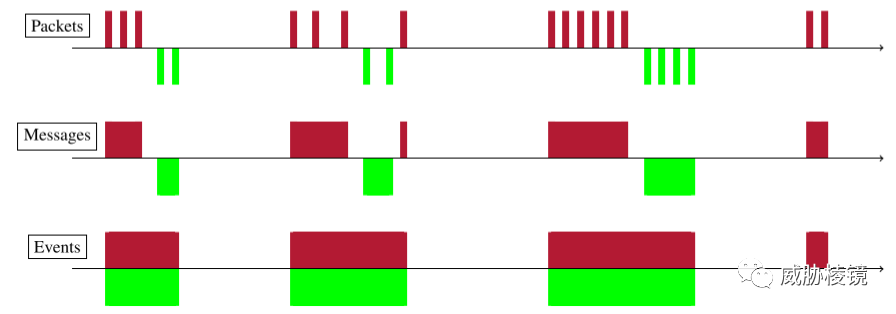
首先使用 TCP 感知时间解析器处理数据包的时间并将数据包合并为消息(应用程序套接字写入的数据包集合),再将消息聚合到事件(一组反映事务的消息,即 GET 请求和后续响应或 TLS 握手)中。下图描述了这个过程:
第一个轮询检测器
第一个检测器用于检测指数退避轮询,拟合为:
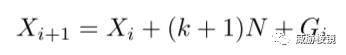
其中 N、k 和 Xi 分别表示基本延迟、未应答包数和事件开始时间。该算法首先查看长度为 6 的窗口内的固定段,并计算 N、k 和 σ 的经验值。然后通过验证 N 和 k 都是正数并且具有合理的标准差来检查这些参数是否一致。如果检查失败,算法会将窗口向右移动一个。然后算法循环下一组时间值,如果新计算的参数仍然一致并且它们落在以下范围内,则将这些值附加到序列中:
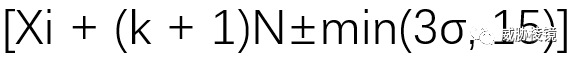
其中,参数 15 可以防止小于 15ms 的微小变化影响检测。最后,在可能的情况下合并轮询范围。
第二个轮询检测器
第二个检测器用于检测均匀分布抖动 ∈ [0, 1] 的恒定延迟轮询,拟合为:
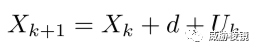
用 N,d 和 Xk 分别表示基本延迟、平均等待时间和事件开始时间的序列。获取数据点并使用 Box-Muller 变换将它们转换为高斯样本,然后使用 Shapiro-Wilk 检验测试拟合的质量。
第三个轮询检测器
第三种与轮询相关的检测方法是检查事件长度,它基于与轮询相关的事件具有相似的长度的假设。该算法计算基于事件的长度的直方图,如果直方图偏向一小组长度,则将事件序列标记为潜在的轮询行为。
非介入扫描
能够确定恶意流量与特定的工具实现有关时,可以发送特制的数据包触发响应行为进行进一步确认。例如,一个请求带有数据中捕获的会话 Cookie,一个为随机生成的 Cookie,确定是否部署 Empire。
不能够确定恶意流量与特定的工具实现有关时,基于深度包检测获取响应时间、响应大小和各个处理器生成的特征。例如字节分析处理器用来查看固定窗口的熵值和字节分布,以区分正文中的代码、文本和随机值。缓冲区溢出漏洞的攻击数据包中通常包含 NOP 填充。使用不同索引位置的子串计算香农信息熵作为特征:
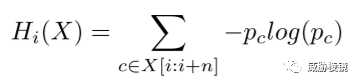
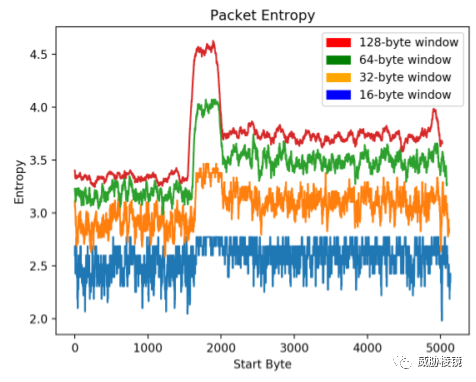
下图显示了 EDB40869 漏洞利用在不同窗口大小下的熵特征,并为前 5000 个字节中的每个字节提供了起始索引。
介入扫描
识别 C&C 服务器的最有效但最具侵入性的方法是干扰活动连接。重点介绍 Empire 的情况,对 RC4 加密头中的 session identifier、language、meta、extra flags 与 length 进行比特翻转测试。Empire 的数据会通过 HTTP 请求头发送,例如,在 Cookie 或 CF-RAY 中或直接在 HTTP 的正文中。
Empire 的数据格式:

Empire 的 RC4 加密头:

各字段含义:
Session ID 是标识 C&C 会话的唯一标识符
Lang 标识 Payload 使用的语言,可以指定 PowerShell、Python 或 None
Meta 描述数据包所处的阶段,Stage 0 (S0)、Stage 1 (S1)、Stage 2 (S2)、Tasking Request (TR)、Result Post (RP)、Server Response (SR) 或无(不适用)
Extra 是保留字段
Length 是 AES 加密数据的长度
Payload Stager 首先向 C&C 服务器发送一个 HTTP GET 请求,并将 Meta 设置为 S0,以检索下一个阶段的命令。接下来发送 HTTP POST 请求,其中包含有关操作系统的信息,并将 Meta 设置为 S1 和 S2。在正常的运行期间,会轮询发送 HTTP GET 请求,并将 Meta 设置为 TR。如果服务器有命令,将响应 200 并将 Meta 设置为 SR 发送命令。接着,客户端将发送带有 SR 标记并包含加密响应内容的 HTTP POST 请求。如果服务器没有命令,服务器将响应 404,返回 file not found 的 HTML 页面。
客户端通常处于 TR 状态下,这也就是说更改 Lang 或者 Extra 不会改变行为,但将 Meta 与 RP 进行异或将会把 TR 变为 S0,这也就强制服务器重新回到第一阶段,而将 Meta 与其他值异或将会导致服务器的解析错误。
工作准备
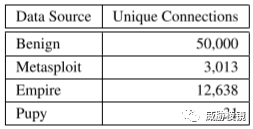
从企业网络中获取真实良性流量,并通过实验环境来获取真实的 RAT 流量,实验环境由一个 Kali Linux 组成作为 C&C 服务器,以及未打补丁的 Windows 10、Windows 7、Windows XP SP2、Ubuntu 14.04 和 Ubuntu 15.10 共计五台主机。
在不同的环境和不同的设置下测试了 Metasploit、Empire 和 Pupy。攻击流量绝大多数是 TCP,对所有 UDP 流量丢弃处理。良性数据集是从具有大约 3000 个端点的企业网络中收集的,同样只保留 TCP 流量。按客户端切分流量,并随机均匀采样 5 分钟的时间窗口,以避免在训练分类器时出现严重的分类不平衡。
其中一些算法对单个双向流进行检测,而其他算法对双向流或元流(一组源 IP 相同、目的 IP 相同和目的端口相同的流)的集合进行检测。所有机器学习分类器都使用标准的随机森林,其中包含 1000 棵树。
工作评估
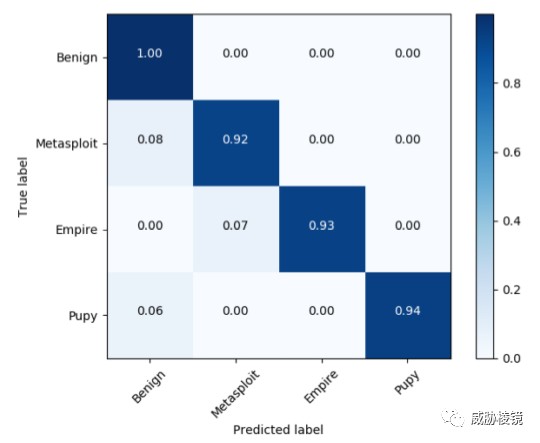
通用分类器的结果如下所示,能够以 92% 的准确率识别攻击工具,合并准确率为 98.5% 且误报率低于 0.01%。
工作思考
尽管思科的这个工作比较早,过去了好几年有些特征实际已经有了很大的变化,但整体对 RAT 流量的研究方法还是值得学习的。而且,这个实验数据中的噪音太少,和实际环境中的情况还是存在较大差别的。相关的特征也都广泛应用在了威胁狩猎和各种利用机器学习进行流量分析的方案中,尝试挖掘检测效果更好的特征也是防御者持续研究的核心。
声明:本文来自威胁棱镜,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
