在教会AI脑补、理解周围的环境之后,还能往什么方向努力?
“人工智能梦之队”DeepMind给出了非常多的例子。
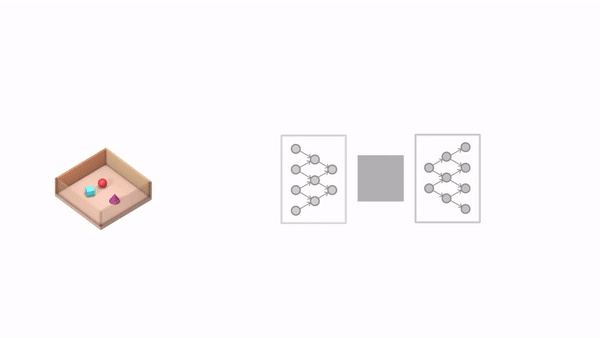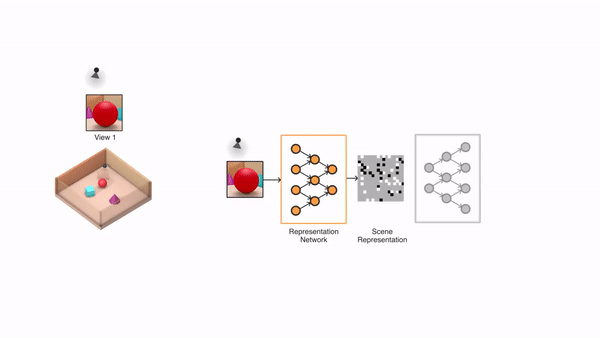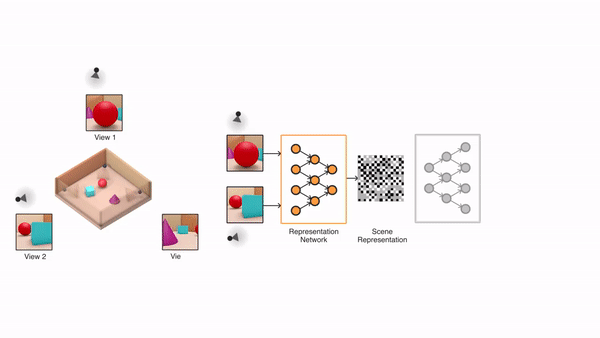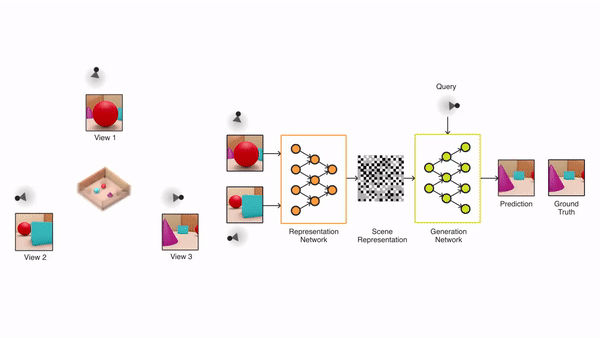
继DeepMind今年6月在Science上发表论文提出GQN(Generative Query Network,生成查询网络)之后,他们相关的研究还在继续。
DeepMind今天在Twitter上公开了GQN的一些新扩展、新应用。
GQN原本的能力,主要表现为基于几张图像,还原出一个3D场景,并生成这个场景任意视角下的渲染图。
当然,作为一项开创性的研究,它所使用的场景,还是比较简单的。
如今的这些新进展,将GQN的能力扩展到了连续视频的生成、在MineCraft这种复杂场景中定位、根据文字描述来生成场景等等,甚至还将GQN的训练方法,搬到了更广泛的回归、分类等任务上。
我们来分别看一看。
用GQN的训练方式搞定其他任务
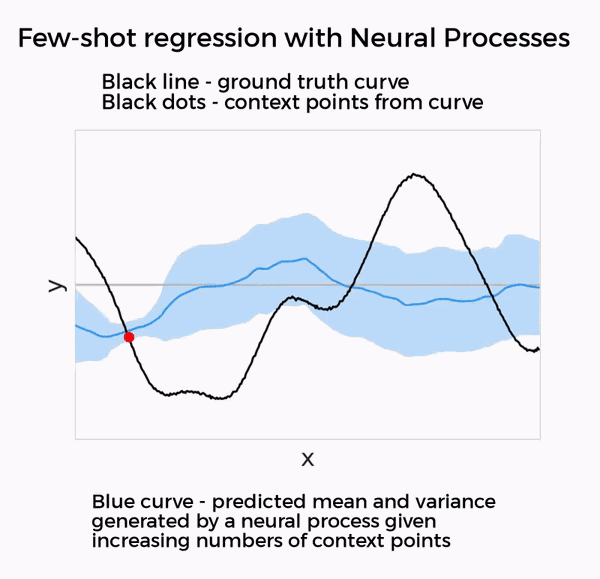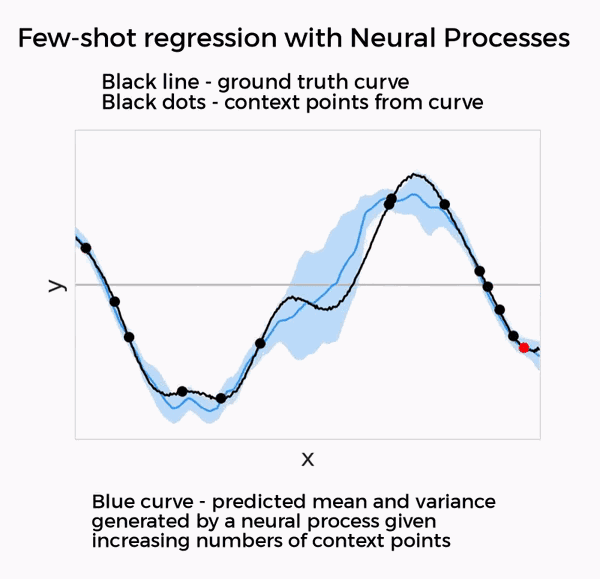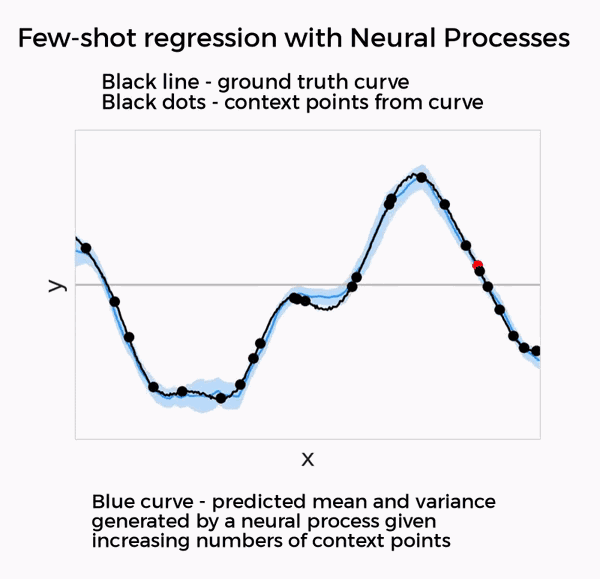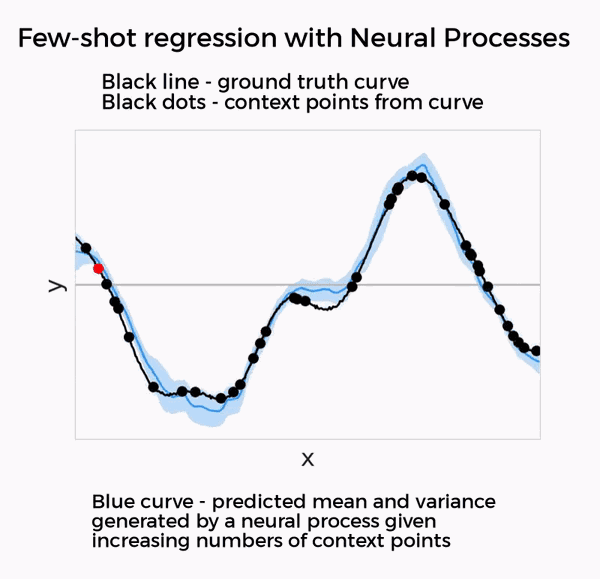
DeepMind认为,GQN创造的训练机制很不错。于是,他们在最新的两项神经过程(Neural Processes)研究中,将这种训练机制泛化到了回归、分类等其他小样本预测任务上。
这方面的成果,是DeepMind在下周召开的机器学习顶会ICML上将要展示的两篇论文:
Conditional Neural Processes,发表于ICML 2018;
Marta Garnelo, Dan Rosenbaum, Chris J. Maddison, Tiago Ramalho, David Saxton, Murray Shanahan, Yee Whye Teh, Danilo J. Rezende, S. M. Ali Eslamihttps://arxiv.org/abs/1807.01613
Neural Processes,发表于ICML深度生成模型的理论基础与应用Workshop。
Marta Garnelo, Jonathan Schwarz, Dan Rosenbaum, Fabio Viola, Danilo J. Rezende, S.M. Ali Eslami, Yee Whye Tehhttps://arxiv.org/abs/1807.01622
这两篇论文所研究的,都是深度神经网络与高斯过程等贝叶斯方法的结合,只需要提供少量数据,就能在回归、分类、图像修补等任务上实现不错的效果。
在这两项神经过程的研究里,都使用了和GQN相似的元学习方法。因此,DeepMind表示,这两项研究都可以视为GQN在新任务上的泛化。
生成连续场景的CGQN
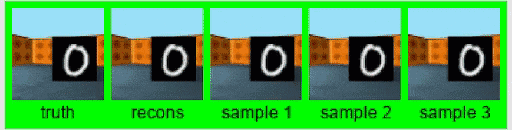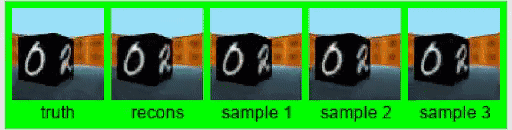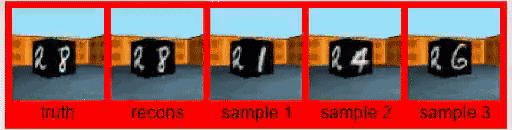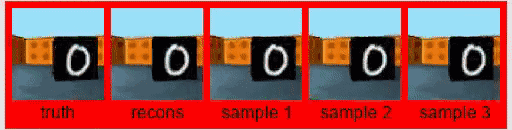
原来的GQN,是根据几张图像来预测3D模型。这种预测能力最邻近的扩展领域,大概就要数视频了。
在一项名为Consistent Generative Query Networks(CGQN)的研究中,DeepMind就基于GQN,实现了输入一串视频,预测一串预测出来的视频续在后边。
论文传送门:
https://t.co/wnKpMjnClx
GQN与注意力的结合

除了原来的3D模型,刚刚提到的回归、分类、视频生成等等,GQN还能用在视觉定位问题上。
在新论文Learning models for visual 3D localization with implicit mapping中,DeepMind探索了两个问题,一是将GQN用在视觉上更复杂的环境中,二是将它用于定位问题。
于是,他们用连续注意力机制对GQN进行了强化,然后用到了Minecraft环境中的定位问题上。
论文传送门:
https://t.co/spkisH866H
根据文字生成场景
只在视觉领域里摸爬滚打还不够,在一篇新论文中,DeepMind把GQN和对自然语言的理解结合了起来,提出了空间语言综合模型(Spatial Language Integrating Model,简称SLIM)。
SLIM能够根据文字描述,在空间中摆放物体,生成一个场景的不同视角。

在上图所示的例子中,SLIM根据描述,生成一个红色球体摆放在蓝色圆锥后边的场景,还能够旋转着展示这个场景在不同角度、不同距离看起来的样子。
论文传送门:
Encoding Spatial Relations from Natural Language
Tiago Ramalho, Tomáš Kočiský, Frederic Besse, S. M. Ali Eslami, Gábor Melis, Fabio Viola, Phil Blunsom, Karl Moritz Hermannhttps://arxiv.org/abs/1807.01670
声明:本文来自量子位,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
